



关于大模型,对于非技术人员来说,大家可能或多或少的听过什么是大模型,以及现在各大厂商的一些大模型产品。对于技术人员来说,大模型那可太熟悉了,日常工作开发离不开,平时遇到问题分析解决问题离不开,生活中有不懂的或者想知道的也是第一个去咨询大模型。那么说了这么多,到底什么是大模型呢?
关于大模型
大模型是人工智能发展历程中的重要里程碑。在对大模型进行深入了解之前,我们先来了解一些人工智能的重要概念,这不仅可以让我们了解大模型是如何被塑造的,更能帮助我们全面地理解大模型的原理和潜能。
人工智能(AI)是一门使机器模拟人类智能过程的学科,其中具体包括学习、推理、自我修正、感知和处理语言等功能。人工智能涉及计算机科学、数据分析、统计学、机器工程、语言学神经科学、哲学和心理学等多个学科的领域,旨在研究、设计、构建具备智能、学习、推理和行动能力的计算机和机器。
人工智能按照技术实现的不同可被划分为多个子领域,包括:人工智能(Artificial Intelligence,Al) 、机器学习(Machine Learning,ML)、深度学习(Deep Learning,DL)、生成式人工智能(Generative Al)等,各个子领域之间往往相互关联和影响。
再说回到大模型,大模型是一类具有大量参数(通常在十亿以上),能在极为广泛的数据上进行训练,并适用于多种任务和应用的预训练深度学习模型。
我们所熟知的ChatGPT正是一种先进的人工智能语言模型,专为对话交互而设计,具有强大的自然语言理解和生成能力,可以完成撰写论文、邮件、脚本、文案、翻译、代码等任务。ChatGPT的发布标志着AI大模型在语言理解与生成能力上的重大突破,对全球AI产业产生了深远影响,开启了人工智能大模型应用的新篇章。
大模型的训练
大模型的训练整体上分为三个阶段:预训练、SFT(监督微调)以及RLHF(基于人类反馈的强化学习)

预训练(Pre-training):预训练的过程类似于从婴儿成长为中学生的阶段,在这个阶段我们会学习各种各样的知识,我们的语言习惯、知识体系等重要部分都会形成;对于大模型来说,在这个阶段它会学习各种不同种类的语料,学习到语言的统计规律和一般知识。但是大模型在这个阶段只是学会了补全句子,却没有学会怎么样去领会人类的意图,假设我们向预训练的模型提问:“埃菲尔铁塔在哪个国家?”模型有可能不会回答“法国”,而是根据它看到过的语料进行输出:“东方明珠在哪个城市?”这显然不是一个好的答案,因此我们需要让它能够去遵循人类的指示进行回答,这个步骤就是SFT(监督微调)。
监督微调(SFT,Supervised Fine Tuning):SFT的过程类似于从中学生成长为大学生的阶段,在这个阶段我们会学习到专业知识,比如金融、法律等领域,我们的头脑会更专注于特定领域。对于大模型来说,在这个阶段它可以学习各种人类的对话语料,甚至是非常专业的垂直领域知识,在监督微调过程之后,它可以按照人类的意图去回答专业领域的问题。这时候我们向经过SFT的模型提问:“埃菲尔铁塔在哪个国家?”模型大概率会回答“法国”,而不是去补全后边的句子。这时候的模型已经可以按照人类的意图去完成基本的对话功能了,但是模型的回答有时候可能并不符合人类的偏好,它可能会输出一些涉黄、涉政、涉暴或者种族歧视等言论,这时候我们就需要对模型进行RLHF(基于人类反馈的强化学习)。
基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback):RLHF的过程类似于从大学生步入职场的阶段,在这个阶段我们会开始进行工作,但是我们的工作可能会受到领导和客户的表扬,也有可能会受到批评,我们会根据反馈调整自己的工作方法,争取在职场获得更多的正面反馈。对于大模型来说,在这个阶段它会针对同一问题进行多次回答,人类会对这些回答打分,大模型会在此阶段学习到如何输出分数最高的回答,使得回答更符合人类的偏好。
大模型的特点
大模型有四个比较明显的特点:
规模和参数量大:大模型通过其庞大的规模(拥有从数亿到数千亿级别的参数数量)来捕获复杂的数据模式,使得它们能够理解和生成极其丰富的信息。
适应性和灵活性强:模型具有很强的适应性和灵活性,能够通过微调(fine-tune)或少样本学习高效地迁移到各种下游任务,有很强的跨域能力。
广泛数据集的预训练:大模型使用大量多样化的数据进行预训练,以学习广泛的知识表示,能够掌握语言、图像等数据的通用特征。
计算资源需求大:巨大的模型规模带来了高昂的计算和资源需求,包括但不限于数据存储、训练时间、能量消耗和硬件设施。
大模型的分类
按照现在大家经常接触的大模型来说,大概可以分为两类:
大语言模型(LLM):主要在自然语言处理(NLP)领域,旨在处理语言、文章、对话等自然语言文本。它们通常基于深度学习架构(如Transformer模型),经过大规模文本数据集训练而成,能够捕捉语言的复杂性,包括语法、语义、语境以及蕴含的文化和社会知识。语言大模型典型应用包括文本生成、问答系统、文本分类、机器翻译、对话系统等。
多模态模型:多模态大模型能够同时处理和理解来自不同感知通道(如文本、图像、音频、视频等)的数据,并在这些模态之间建立关联和交互。它们能够整合不同类型的输入信息,进行跨模态推理、生成和理解任务。多模态大模型的应用涵盖视觉问答、图像描述生成、跨模态检索、多媒体内容理解等领域。
视觉+文本:包括VQA视觉问答,图像字幕,图文检索、文生图等应用。
音频+文本:包括语音生成、语音摘要、语音识别等应用。
音频+视觉:包括音生图、演讲人脸生成等应用。
大模型的应用
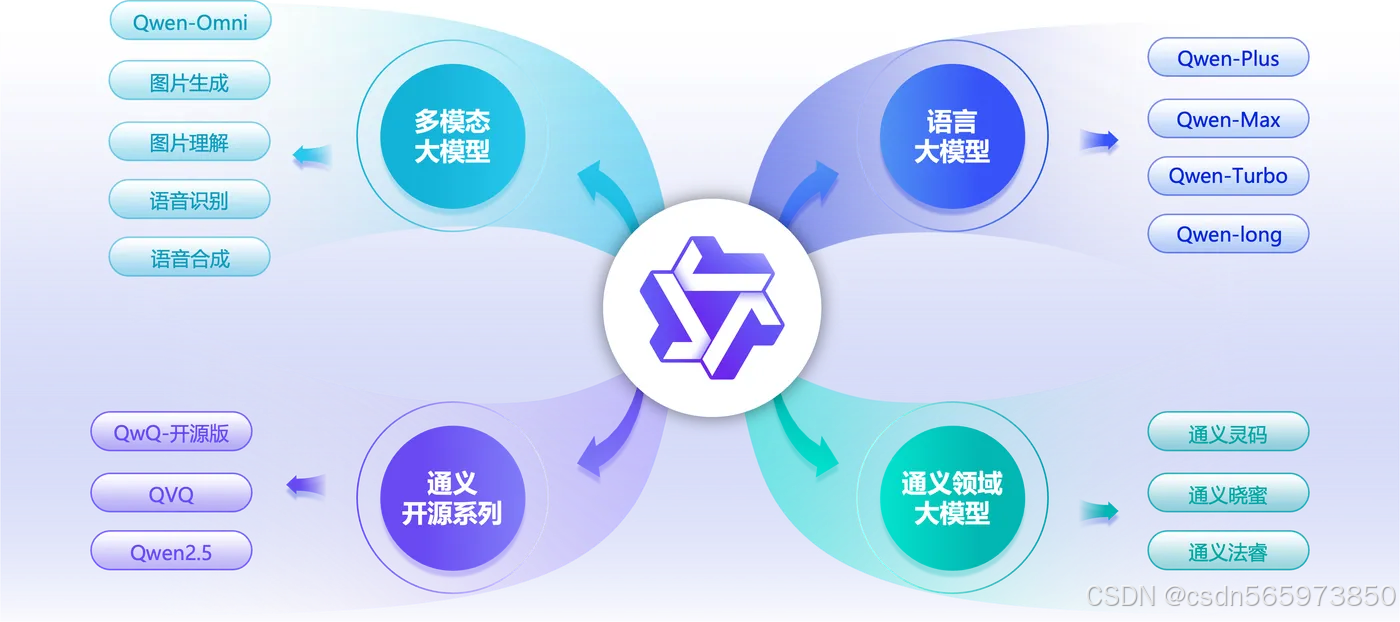
阿里巴巴通义系列产品,是涵盖多领域、覆盖200多个服务场景的先进人工智能大模型体系。该系列产品矩阵涵盖金融、法律、科研、医疗、教育等专业领域,以及日常生活中的诸多需求,真正体现了“通情,达义”的设计理念,致力于成为人们工作、学习、生活中的全能助手。 此外,阿里云秉持开放姿态,将其核心模型开源开放给全球开发者,以此促进AI技术的共享与进步。
通义千问是阿里云自主研发的超大规模的语言模型,在复杂指令理解、文学创作、通用数学、代码理解生成、知识记忆等能力上均达到领先水平。它支持多种语言,还能处理多种分辨率和规格的图像,实现多语言多模态理解。
通义万相是阿里云自主研发多模态图像和视频生成模型,可提供AI艺术创作,可支持文生图、图生图、图生视频、虚拟模特、个人写真等多场景的图片和视频创作能力。
通义千问和通义万相是阿里巴巴通义系列产品中的基础模型
最后总结
大模型,作为人工智能领域划时代的突破,已成为当前技术发展的核心驱动力。它本质上是一种参数量极其庞大(通常在十亿甚至千亿级别)、在超大规模多样化数据集上预训练而成的深度学习模型。这种“大”赋予了它强大的能力:能够捕捉复杂的数据模式,具备出色的通用性和适应性,能够通过微调或少量样本学习快速迁移到各种下游任务(跨域能力),理解和生成极其丰富的信息(语言、图像、音频等)。
大模型的“成长”通常经历预训练、监督微调(SFT)和基于人类反馈的强化学习(RLHF) 三个阶段,如同一个人从广泛学习基础知识,到接受专业训练,再到在反馈中优化行为模式的过程。这确保了模型不仅能掌握语言规律和世界知识,更能遵循人类意图、生成符合人类偏好的安全输出。
根据处理信息的类型,大模型主要分为专注于文本理解与生成的大语言模型(LLM),以及能整合处理文本、图像、音频、视频等多种模态信息并进行跨模态推理与生成的多模态模型。后者代表了更前沿的方向,能够完成视觉问答、图像描述、文生图、语音合成等复杂任务。
以阿里巴巴的“通义”系列为代表,大模型的应用已深度融入专业领域(金融、法律、医疗、科研)和日常生活,提供从智能问答、内容创作、代码生成到图像/视频生成等广泛服务,显著提升了工作效率和生活便利性。“通义千问”(超大规模语言模型)和“通义万相”(多模态生成模型)等基础模型的开放共享,更是推动了整个AI生态的创新与进步。
总而言之,大模型以其前所未有的规模、强大的泛化能力、广泛的应用场景以及深远的社会影响,正在深刻重塑我们与信息交互的方式,并持续引领人工智能技术进入一个能力更强、应用更广的新纪元。它不仅是技术人员的得力工具,也正逐渐成为每个人触手可及的智能助手。


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











