



阿里云 Milvus 轻松实现文搜图&图搜图
在开始部署之前,先来介绍一下什么是阿里云Milvus?
阿里云Milvus
Milvus是一款云原生开源向量检索引擎,基于Faiss、Annoy、HNSW等知名库构建,并进行了优化,实现了高可用、高性能、易扩展的特性,适于处理海量向量数据的实时召回。它包含了数据分区分片、持久化、增量摄取、混合查询等高级功能,同时支持time travel操作,提供了直观的API和多语言SDK,适用于推荐系统、图像检索、视频分析、自然语言处理等多个AI领域。
阿里云向量检索服务Milvus版是一款全托管向量检索引擎,并确保与开源Milvus的完全兼容性,支持无缝迁移。它在开源版本的基础上增强了可扩展性,能提供大规模AI向量数据的相似性检索服务。凭借其开箱即用的特性、灵活的扩展能力和全链路监控告警,Milvus云服务成为多样化AI应用场景的理想选择,包括多模态搜索、检索增强生成(RAG)、搜索推荐、内容风险识别等。您还可以利用开源的Attu工具进行可视化操作,进一步促进应用的快速开发和部署。
阿里云 Milvus 轻松实现文搜图&图搜图
这里提供了一个基于阿里云 Milvus 轻松实现文搜图&图搜图 的方案部署,通过Milvus 解决多模态数据检索难题。
方案背景
高性能检索能力“断层”:
非专业向量数据库产品在应对多模态、高维度、大规模特征向量的相似性检索任务时,存在检索性能弱、索引构建慢及并发能力差等短板,难以满足智能检索场景的高性能与扩展性要求。
传统向量检索方案“性价比失衡”:
传统向量检索系统多依赖 Faiss + Redis 拼装或集成向量插件,架构耦合高、扩展困难,海量数据下同步与更新频繁,运维压力大,难撑业务快速迭代与高并发场景。
Milvus 让多模态搜索更高效:
Milvus 赋能高效多模态搜索,内置高性能、可扩展的向量检索能力,原生支持图像、文本、音频等多模态数据的一体化管理与实时检索,为智能推荐、内容理解等场景提供强力支撑。
方案介绍
本方案基于阿里云向量检索服务 Milvus 版,结合阿里云百炼模型服务的多模态语义理解能力,构建高效、灵活的搜索系统,轻松支持文搜图、图搜图、跨模态检索等典型应用。通过 Serverless AI 应用开发平台 Function AI 部署至函数计算,可将模型服务一键部署至函数计算,实现快速上线、自动扩缩容与全托管运维,显著降低部署与运营成本,助力企业聚焦核心业务创新。
方案架构图如下:
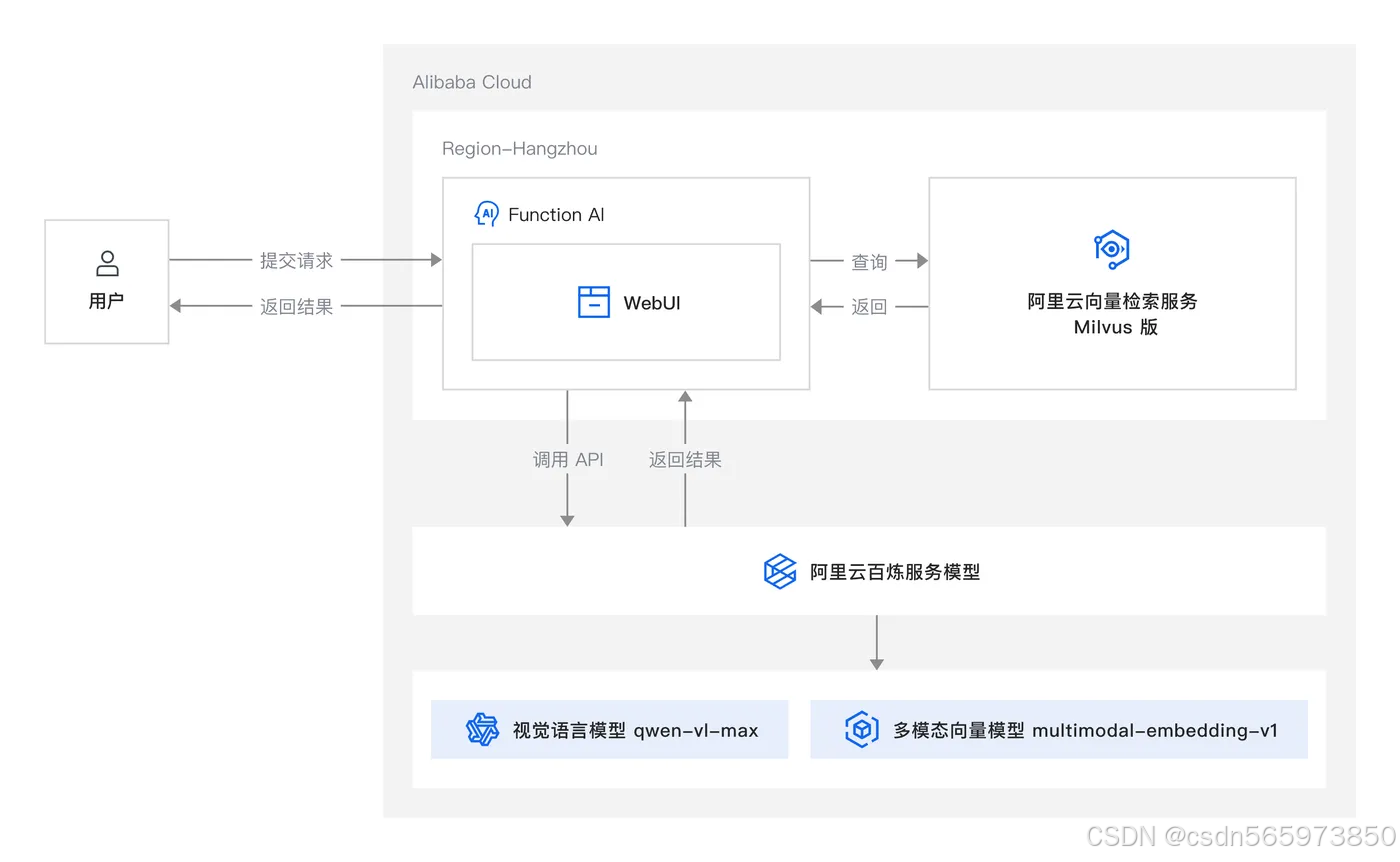
应用场景
既然解决方案是文搜图&图搜图方向,那么主要的应用场景就是图像相似性检索系统,支持以图搜图、视频审核、医学影像辅助诊断等;以及对海量文本进行向量存储与语义检索,应用于智能问答、法律文书匹配、舆情分析等场景,提升搜索效率与理解能力;同时也可以广泛用于电商、视频平台和内容社区,提升转化率与用户体验。

部署操作
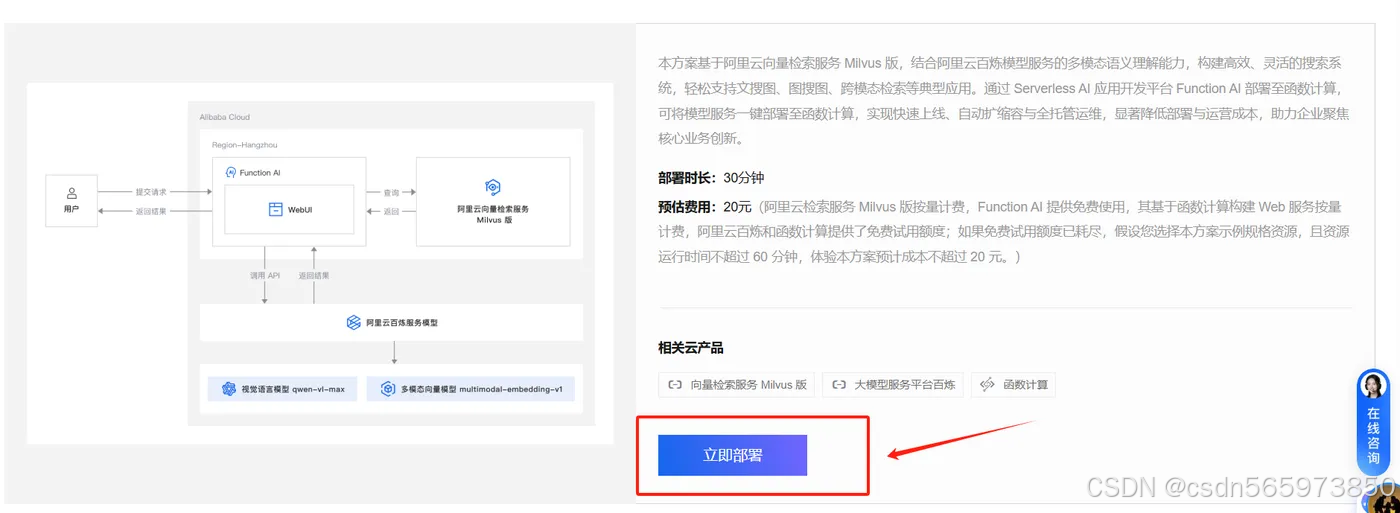
下面我们可以直接点击部署方案:https://www.aliyun.com/solution/tech-solution/milvus-ai 页面的【立即部署】进入部署操作页面
资源准备
在开始部署前,需要先开通好需要的资源。
登录 阿里云百炼大模型服务平台 ,根据页面提示签署阿里云百炼服务协议,然后单击页面 顶部 的 【立即开通】 按钮,并按照提示进行开通。
登录 函数计算服务控制台,根据页面提示完成开通,开通后,需要完成阿里云服务授权。
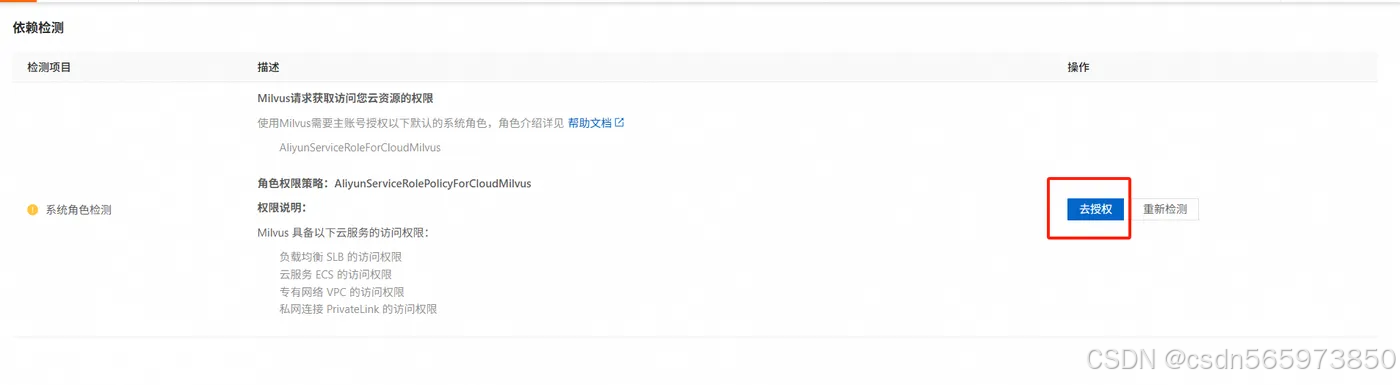
如果是首次访问阿里云 Milvus 管理控制台,则需先完成相关依赖权限的授权。登录 阿里云 Milvus 管理控制台,根据页面提示完成授权。
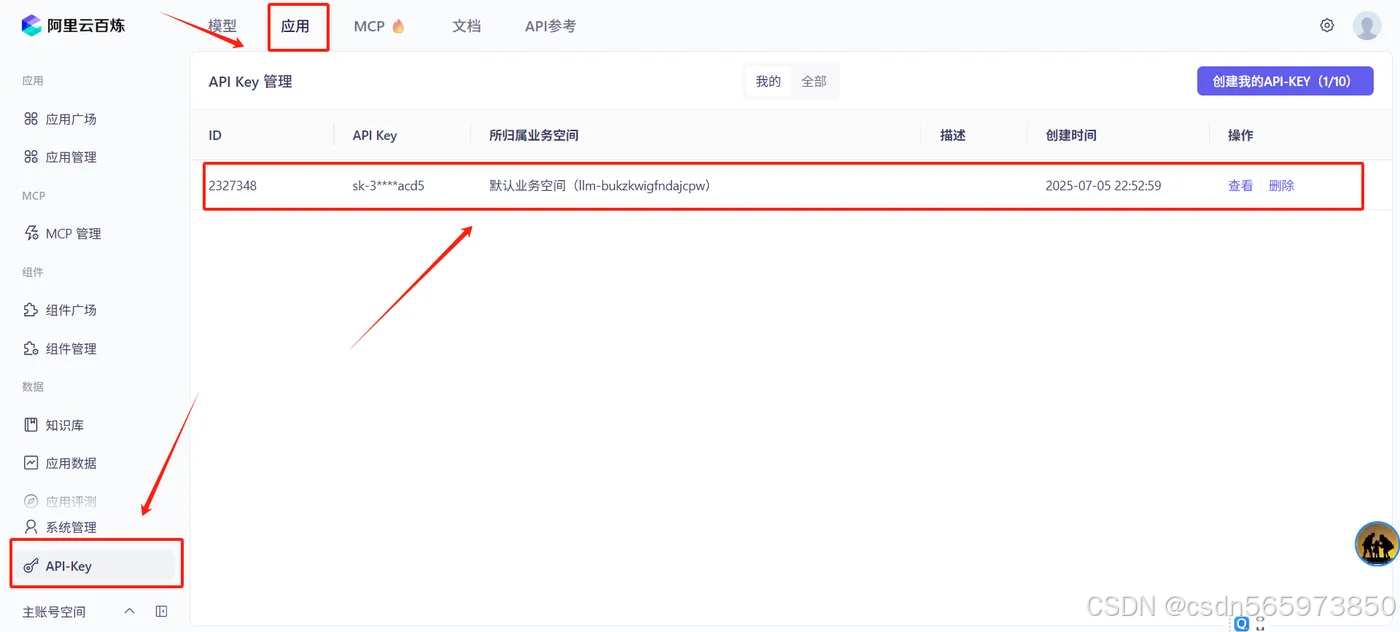
获取百炼API-KEY
登录 阿里云百炼大模型服务平台 ,点击顶部的【应用】切换菜单到【API-Key】创建并复制API-KEY 备用
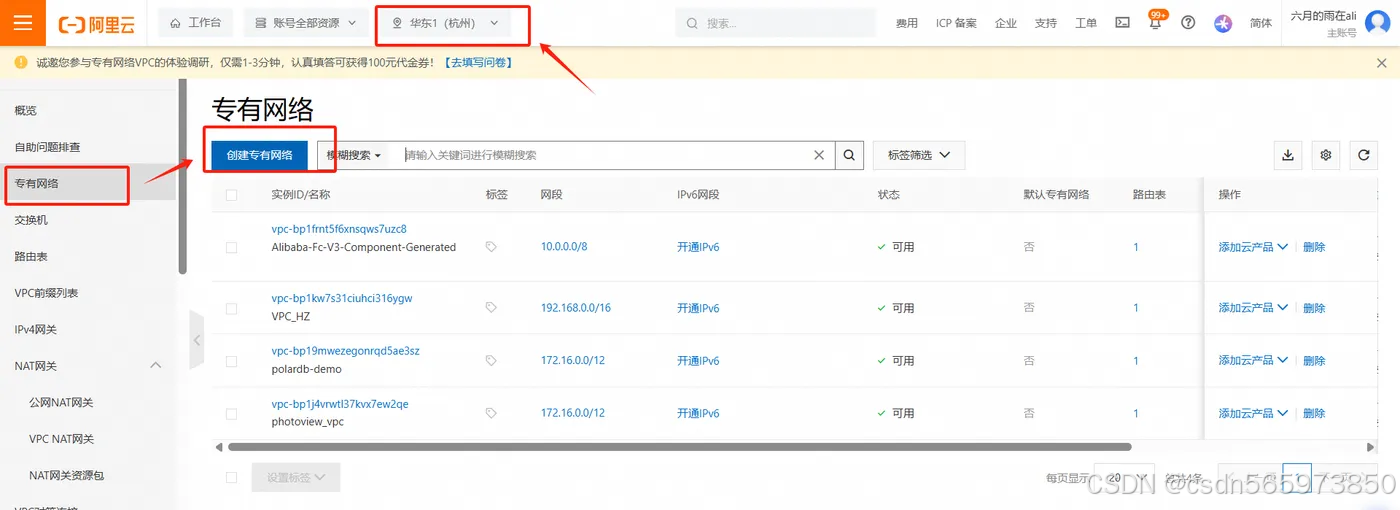
创建专有网络VPC和交换机
登录专有网络管理控制台。在左侧导航栏,单击【专有网络】。在顶部菜单栏,选择【华东1(杭州)】地域。在专有网络页面,单击【创建专有网络】。
在创建专有网络页面,配置1个专有网络和1台交换机。在配置交换机时,请确保其所在的可用区内的相关资源均处于可用状态,以保证后续操作的顺利进行。
创建阿里云Milvus实例
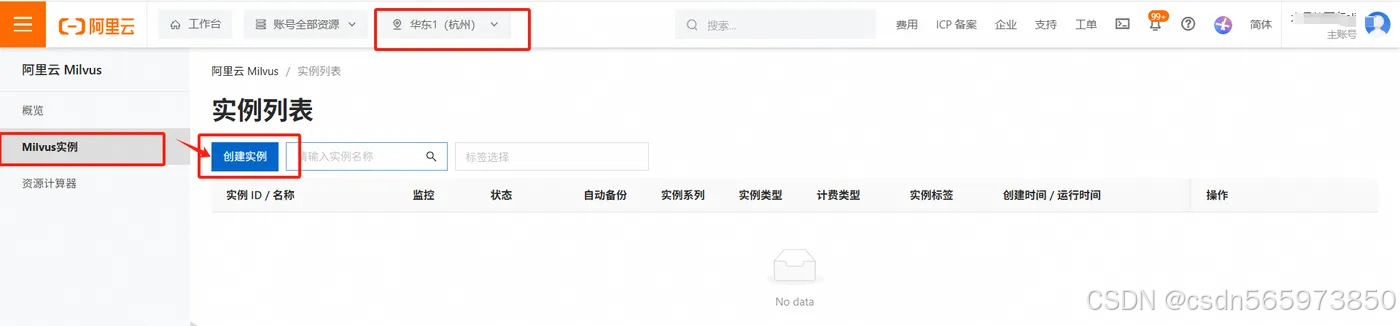
登录阿里云 Milvus 管理控制台。创建阿里云向量检索服务 Milvus 版实例。在左侧导航栏,选择 【Milvus 实例】。在顶部菜单栏,选择【华东1(杭州)】地域。在实例列表页面,单击【创建实例】,
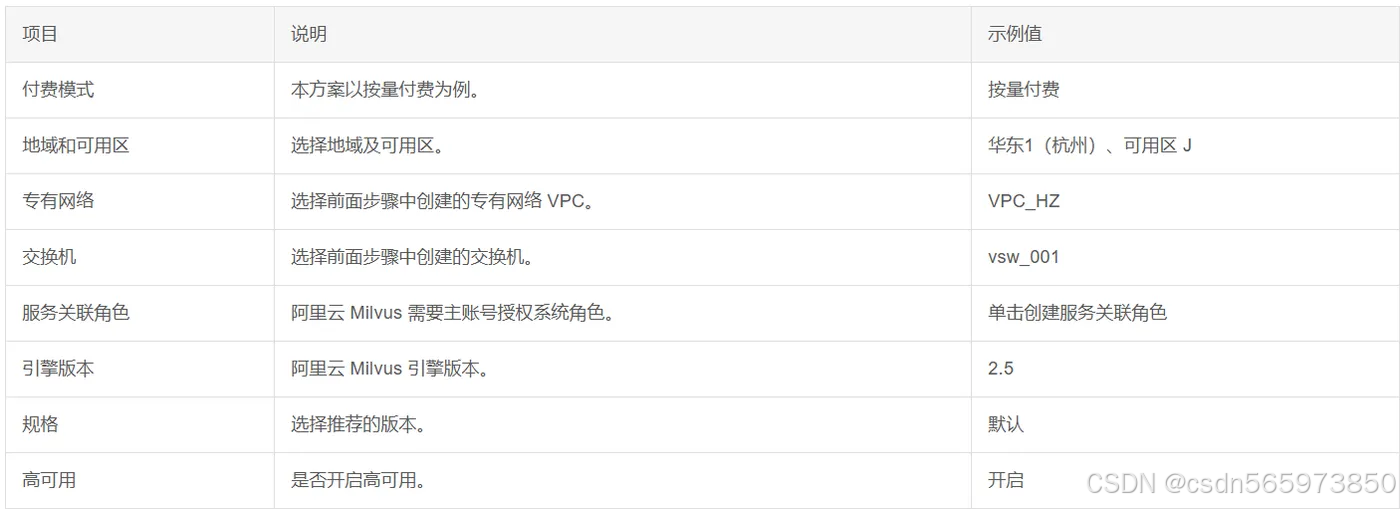
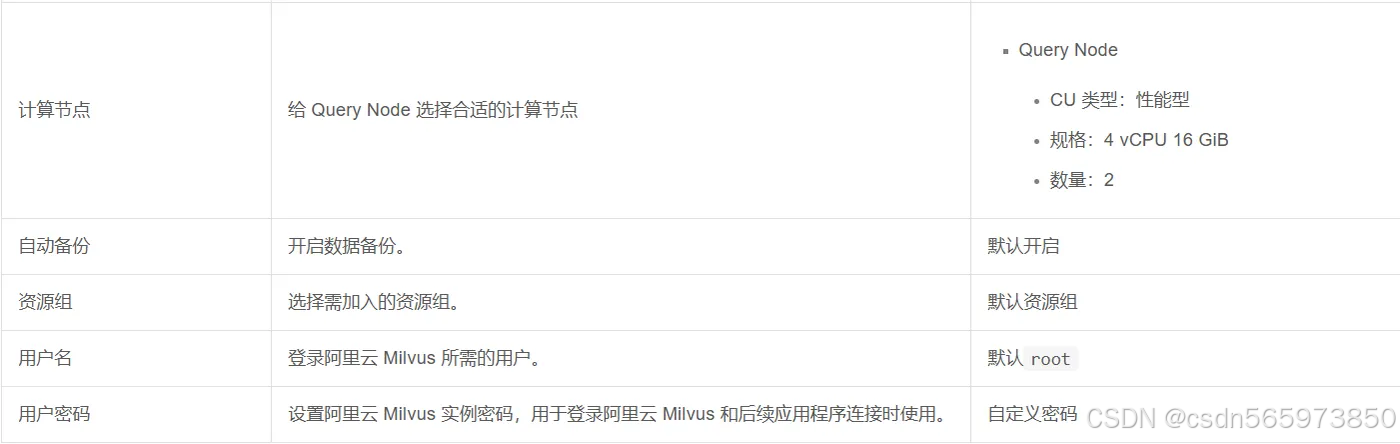
在购买页面按照以下配置完成实例创建。未提及配置使用默认值即可

在页面右下角,单击【立即购买】,然后进入确认订单页面,接着单击【立即开通】以完成购买。
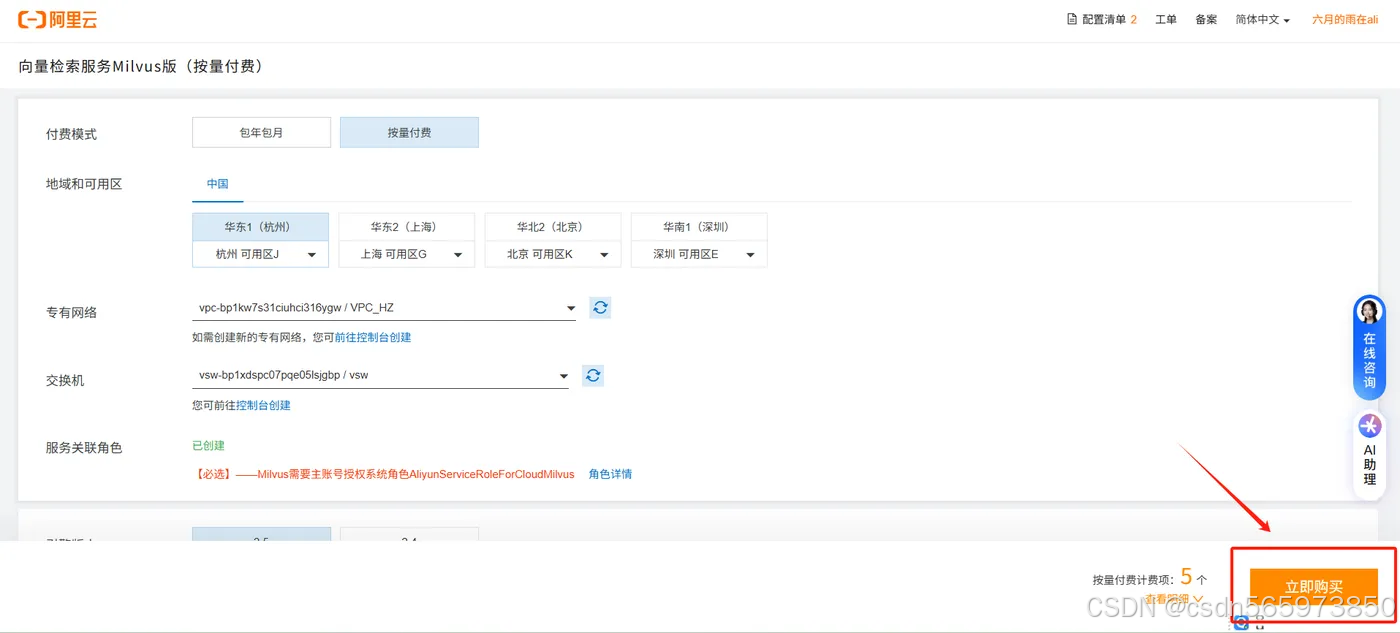
到这里,阿里云 Milvus 实例创建成功。下面继续创建数据库。
在阿里云Milvus 控制台 单击 【Milvus 实例】。在Milvus 实例页面找到本次创建的目标实例,待实例状态变为运行中后,
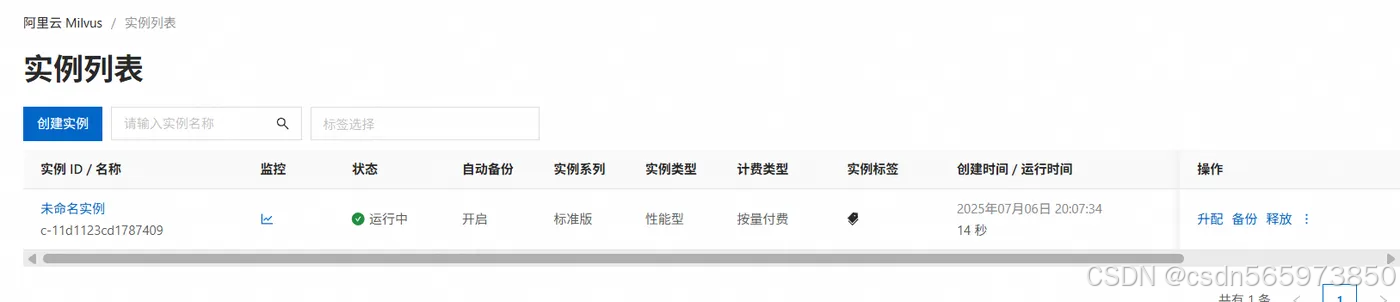
单击【实例 ID/名称】,进入实例详情页面。在实例详情页面,单击安全配置页签,单击【开启公网】,在弹出的窗口中配置公网访问名单。
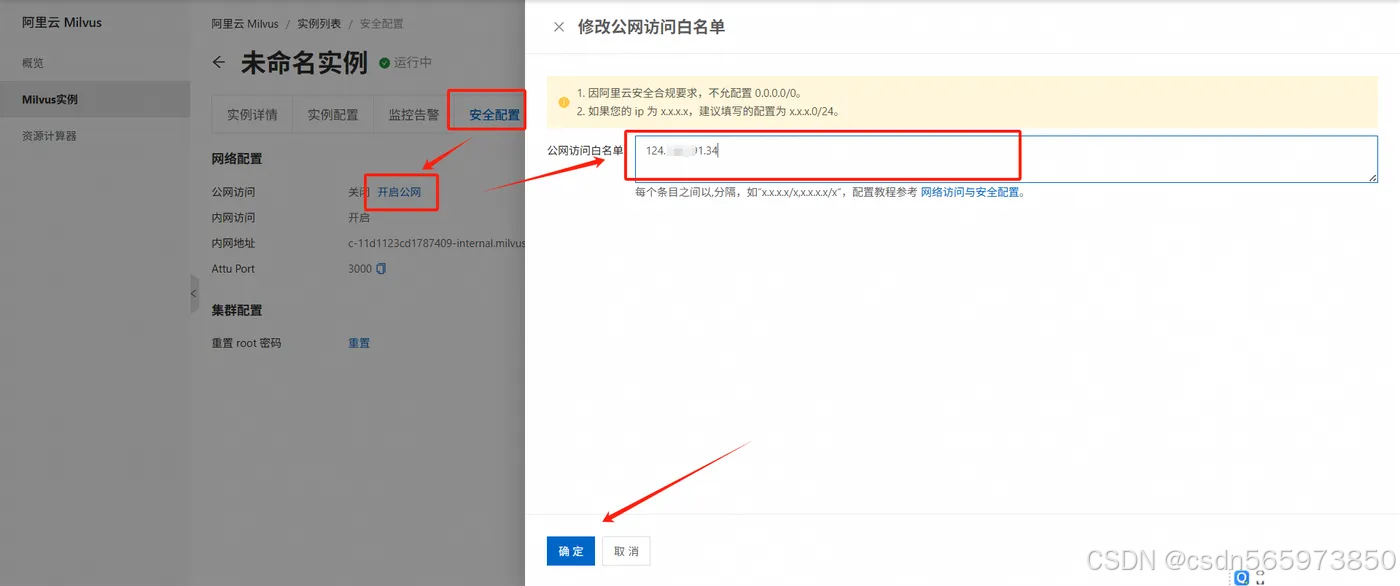
在配置完成符合要求的公网访问白名单之后,等待系统进行升级。升级成功之后,即可单击右上角【Attu Manager】按钮进入 Attu 登录页面。

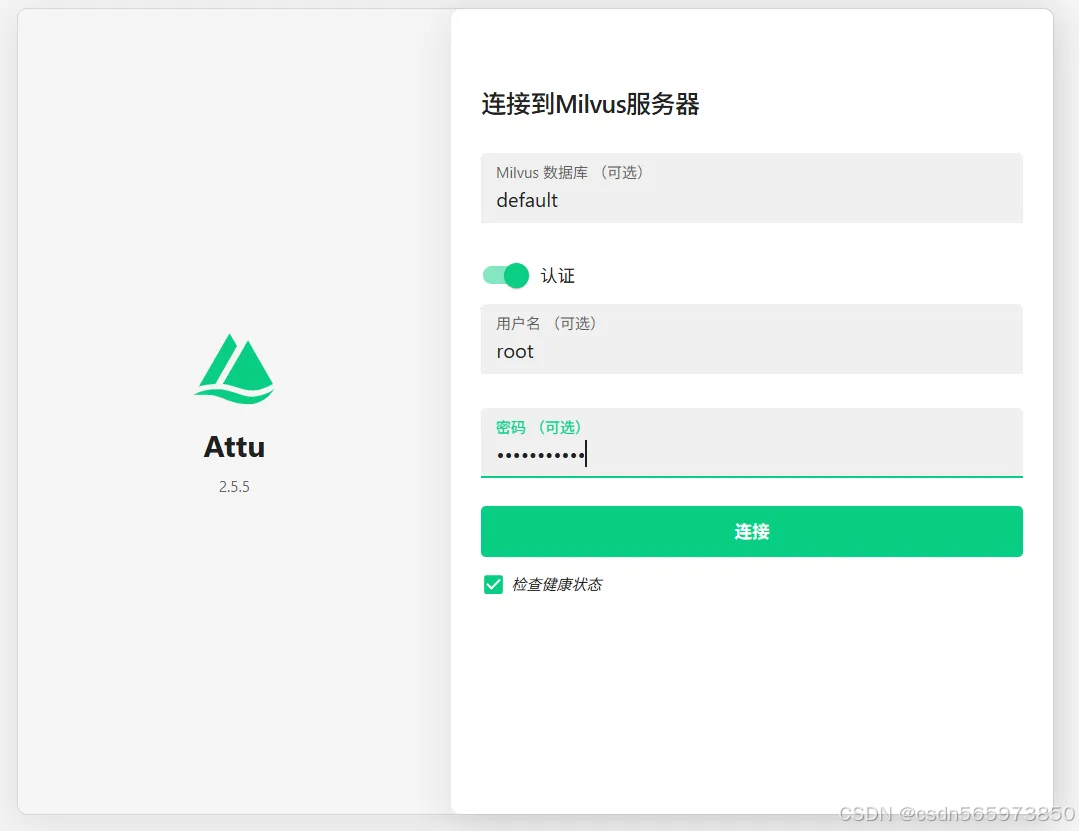
在 Attu 登录页面,打开认证开关,输入 用户名 和 密码,单击 【连接按钮】 即可登录至 Attu 管理页面
在 Attu 管理页面,单击左侧的 图标,进入数据库管理页面,单击【+创建数据库】,在弹出的对话框中,输入数据库名称 test_db,单击 【创建】
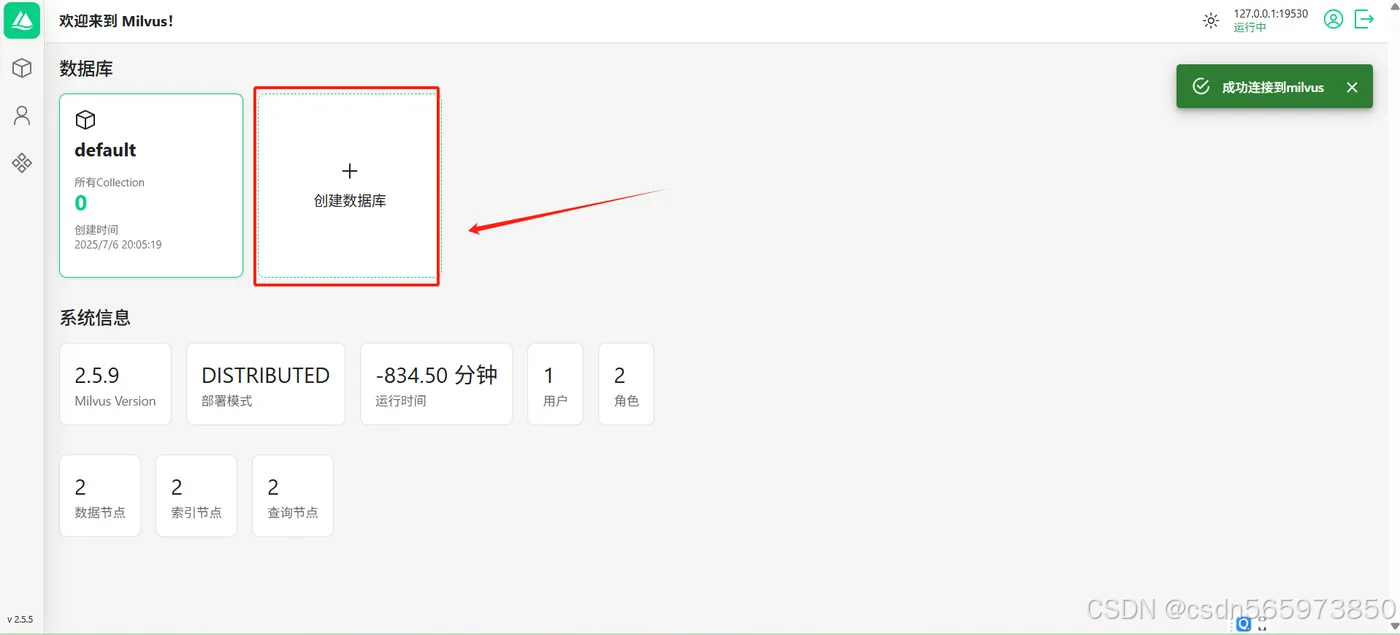
数据库创建完成后如图
部署应用
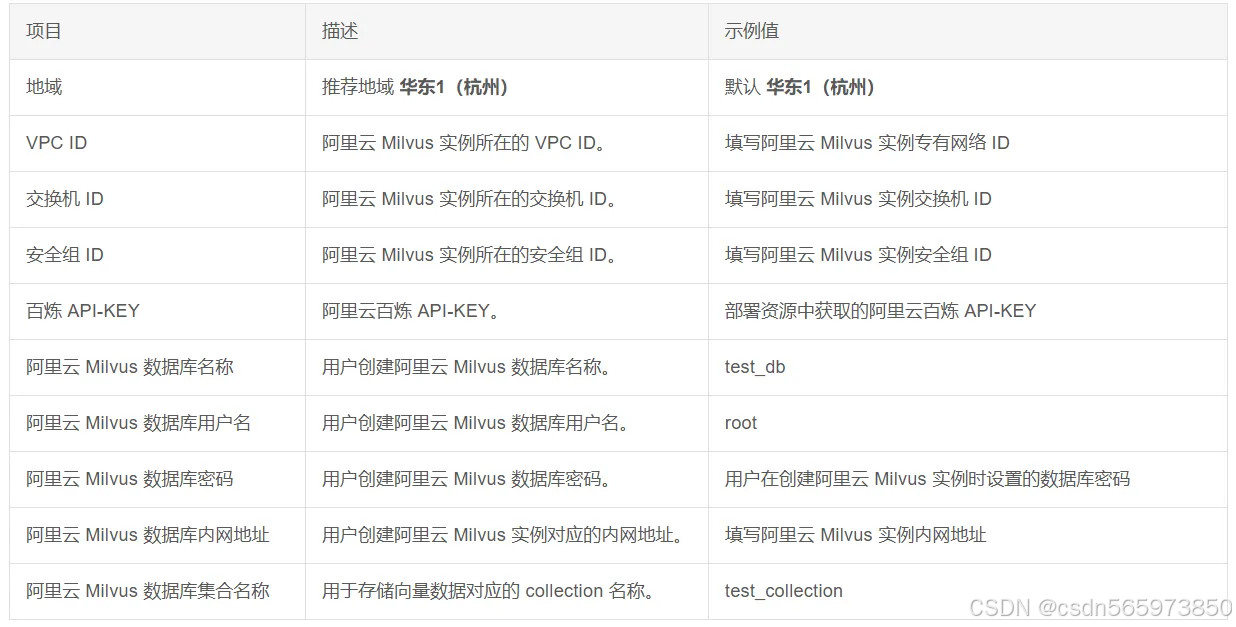
请点击 前往部署 打开已经提供的函数计算应用模板,参考下表进行参数配置,其他参数选择默认配置,然后单击部署项目,最后在弹出面板中单击确认部署,部署预计等待 3~5 分钟
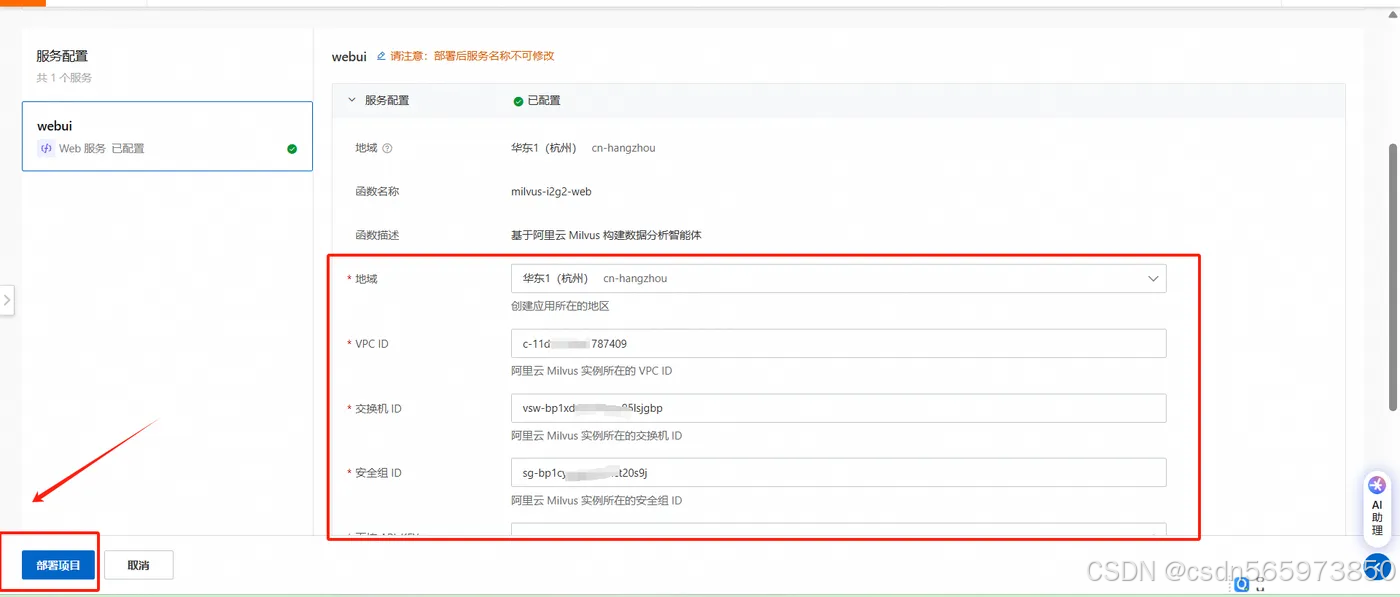
完成部署操作。
方案验证
进入项目部署详情页,按照下图找到访问地址,点击访问地址,即可打开示例应用
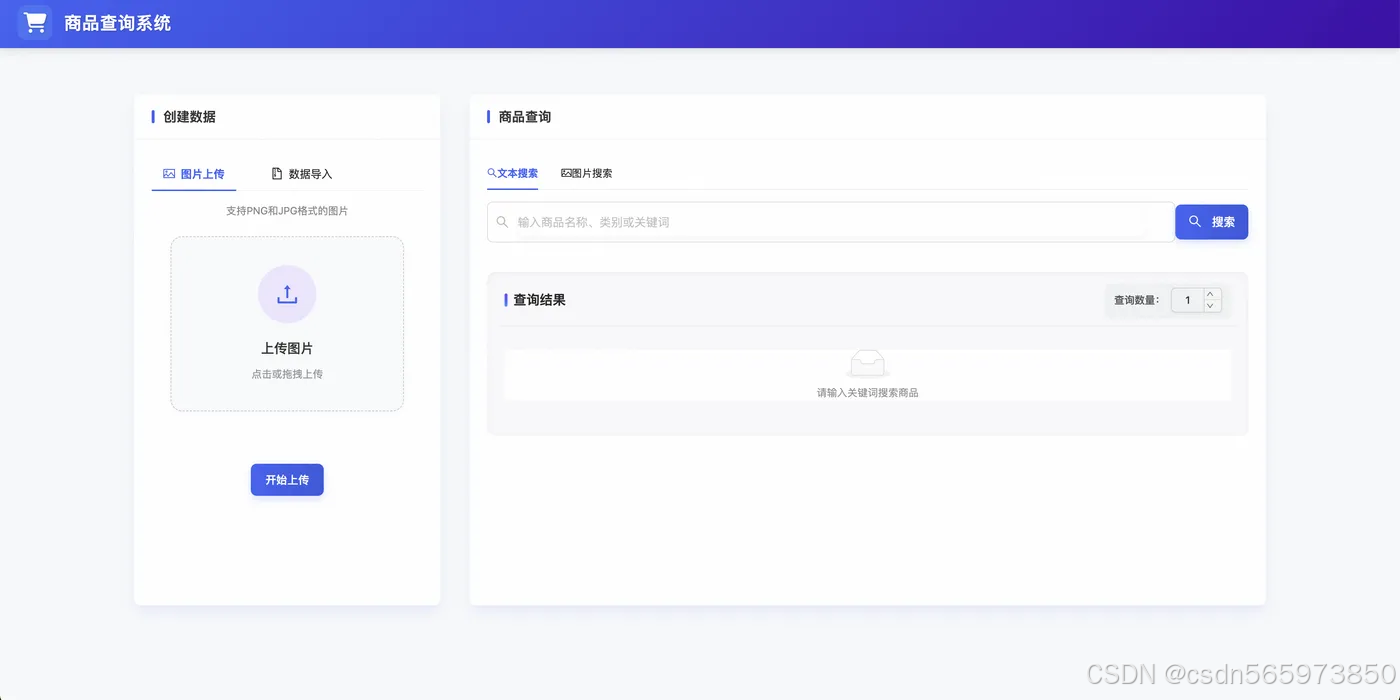
在左侧【创建数据】模块中,选择【数据导入】页签,上传提前准备好的测试数据。
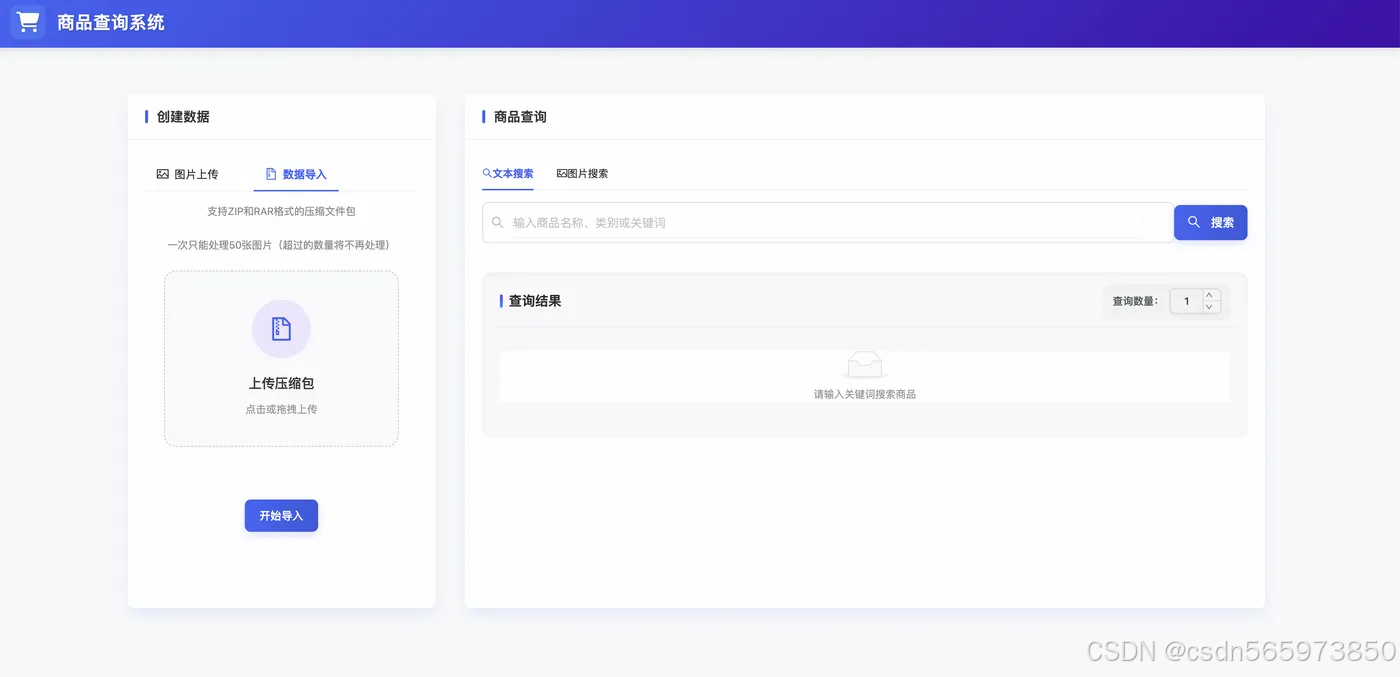
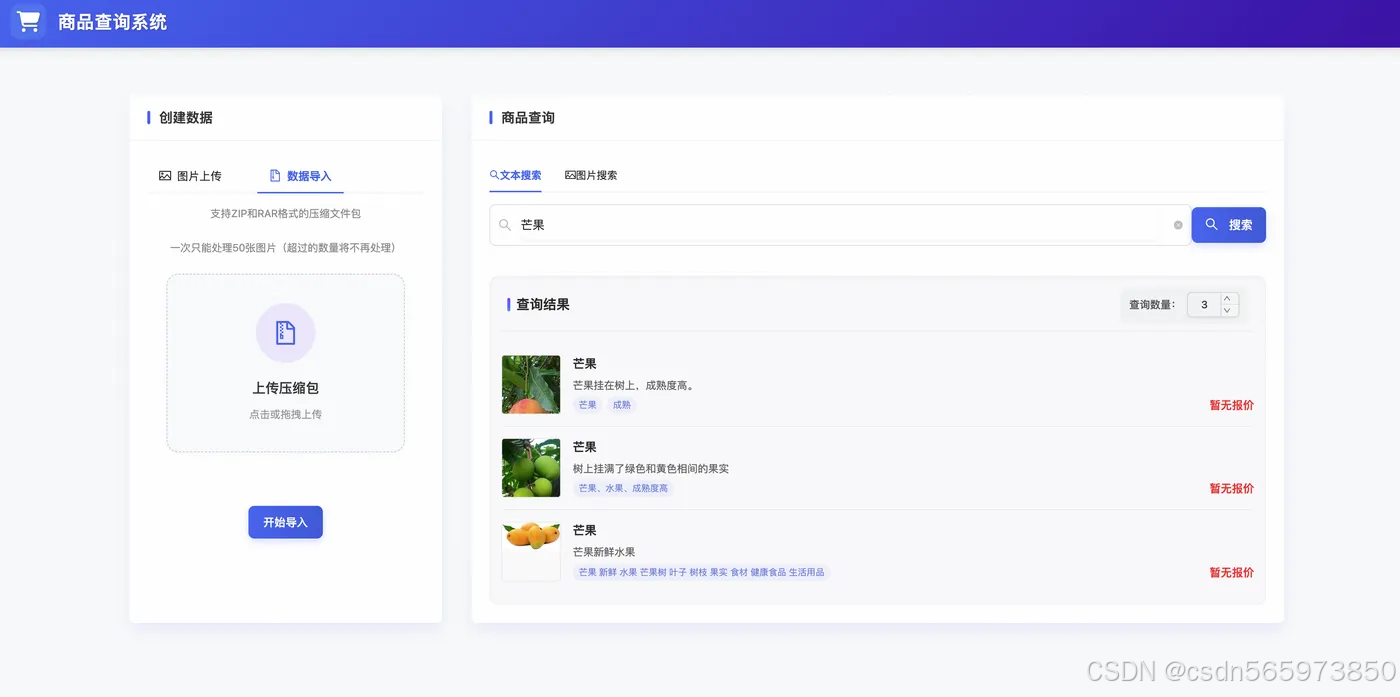
选择【文本搜索】页签,在文本框中输入 芒果 并将查询数量改为3,随后点击【搜索】按钮进行查询
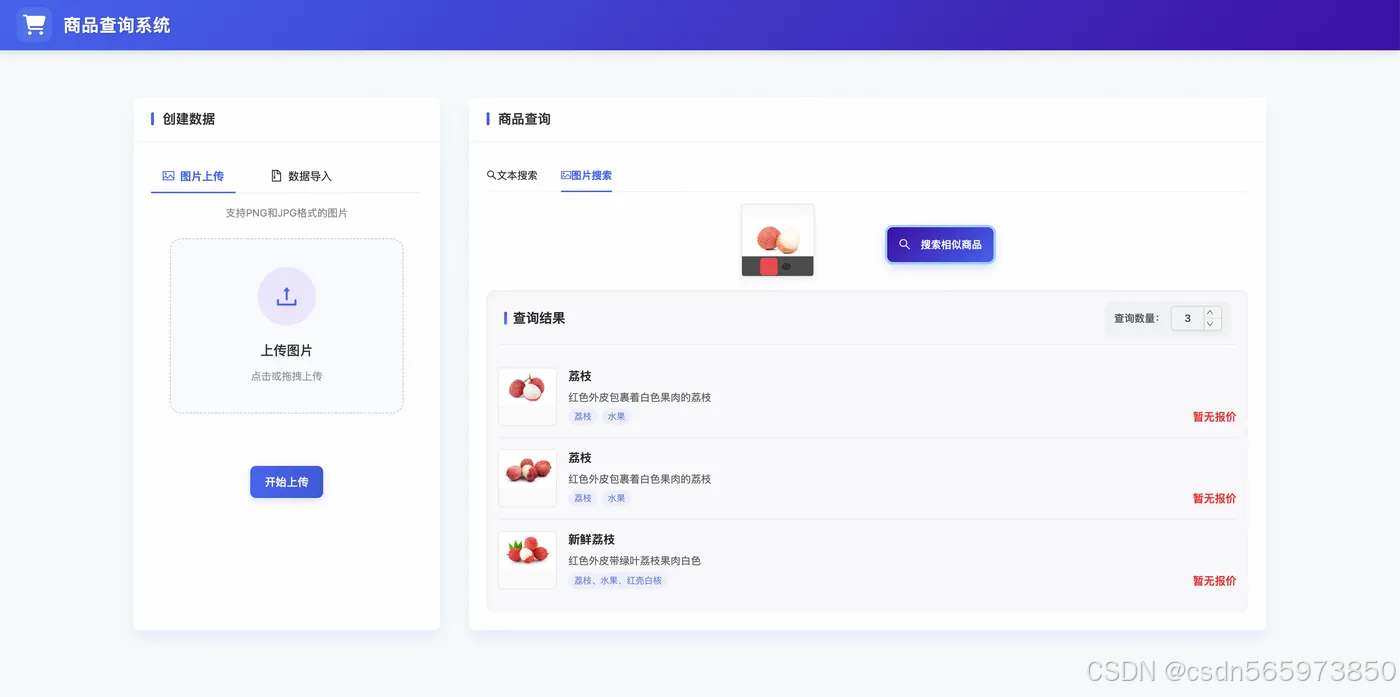
选择【图片搜索】页签,在上传区域上传 Lichi.jpg 并将查询数量改为3,随后点击【搜索相似商品】
方案总结
到这里,整个基于 阿里云 Milvus 轻松实现文搜图&图搜图 的方案部署就算完成了,整个部署过程按照解决方案的步骤逐步操作即可,操作过程中不会有太大的难度,小白新手也可以轻松部署实现。这里需要注意的是,整个部署操作过程步骤比较多,操作时需要仔细按照文档进行,不要忽略一些认为不重要的步骤。在解决方案部署完成验证后,对于不再使用的情况,可以选择释放资源以节省资源损耗和持续的扣费。
对于文搜图&图搜图的应用场景还是很广的,生活中每天都要接触的就是电商场景了。Milvus以其高效处理多模态数据(如图像、文本等)的能力,支持从海量数据中迅速找到与用户兴趣匹配的内容,让Milvus真正化身为你平台上的“AI读心术大师”。“AI读心术大师”可能有些夸张,但是针对非结构化数据检索中存在的检索性能弱、扩展能力有限等问题,阿里云 Milvus 作为专业向量数据检索引擎,专注于高效管理与检索图像、文本、音频、视频等多模态特征向量,结合百炼提供从数据嵌入到相似性搜索的全栈能力,这点是毋庸置疑的。


















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











