



目录
一、消息队列简介
什么是消息队列:字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
-
消息队列:存储和管理消息,也被称为消息代理(Message Broker)
-
生产者:发送消息到消息队列
-
消费者:从消息队列获取消息并处理消息
使用队列的好处在于 解耦:所谓解耦,举一个生活中的例子就是:快递员(生产者)把快递放到快递柜里边(Message Queue)去,我们(消费者)从快递柜里边去拿东西,这就是一个异步,如果耦合,那么这个快递员相当于直接把快递交给你,这事固然好,但是万一你不在家,那么快递员就会一直等你,这就浪费了快递员的时间,所以这种思想在我们日常开发中,是非常有必要的。
二、Redis能用作消息队列的原因
简单轻量:Redis是一个内存中的数据存储系统,具有轻量级和简单的特点。相比较专门的消息队列系统,使用Redis作为消息队列不需要引入额外的组件和依赖,可以减少系统的复杂性。
速度快:由于Redis存储在内存中,它具有非常高的读写性能。这对于需要低延迟的应用程序非常有优势。
多种数据结构支持:Redis提供了丰富的数据结构,如列表、发布/订阅、有序集合等。这使得Redis在处理不同类型的消息和任务时更加灵活。
数据持久化:Redis可以通过将数据持久化到磁盘来提供数据的持久性。这意味着即使Redis重启,之前的消息也不会丢失。
广泛的应用场景:Redis不仅可以用作消息队列,还可以用作缓存、数据库、分布式锁等多种用途。如果你的应用程序已经使用了Redis,那么使用Redis作为消息队列可以减少技术栈的复杂性。
三、Redis有哪些结构适合做消息队列?
1.基于List结构模拟消息队列(一对一)
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。 不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

基于List的消息队列有哪些优缺点? 优点:
-
利用Redis存储,不受限于JVM内存上限
-
基于Redis的持久化机制,数据安全性有保证
-
可以满足消息有序性
缺点:
-
无法避免消息丢失
-
只支持单消费者
示例代码如下:
生产者使用LPUSH发送消息:
127.0.0.1:6379> LPUSH queue msg1
(integer) 1
127.0.0.1:6379> LPUSH queue msg2
(integer) 2
消费者这一方就使用RPOP获取消息:
127.0.0.1:6379> RPOP queue
"msg1"
127.0.0.1:6379> RPOP queue
"msg2"
但是有个问题出现了:消费者POP完之后消息就没了,也就是这些消息只能被消费一次,功能还是很局限的。
127.0.0.1:6379> RPOP queue
(nil) // 没消息了
2.基于PubSub的消息队列(一对多)(多对多)
为了解决基于list的消息队列功能局限,只能给单消费者消费等问题,Redis还提供了基于PubSub的消息队列,这个消息队列就可以实现一对多的关系。
Pub:Publish,意为发布消息
Sub:Subscribe,意为订阅消息
基于PubSub的消息队列有哪些优缺点? 优点:
-
采用发布订阅模型,支持多生产、多消费
缺点:
-
不支持数据持久化
-
无法避免消息丢失
-
消息堆积有上限,超出时数据丢失
示例代码如下:
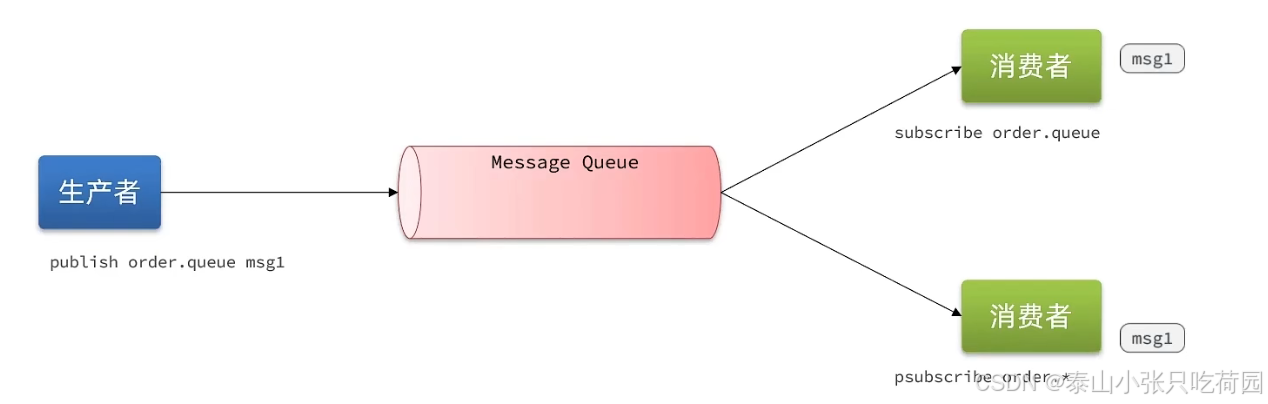
首先,使用 SUBSCRIBE 命令,启动 2 个消费者,并「订阅」同一个队列。
// 2个消费者 都订阅一个队列
127.0.0.1:6379> SUBSCRIBE queue
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "queue"
3) (integer) 1
此时,2 个消费者都会被阻塞住,等待新消息的到来。
之后,再启动一个生产者,发布一条消息。
127.0.0.1:6379> PUBLISH queue msg1
(integer) 1
这时,2 个消费者就会解除阻塞,收到生产者发来的新消息。
127.0.0.1:6379> SUBSCRIBE queue
// 收到新消息
1) "message"
2) "queue"
3) "msg1"
这里的消费者,订阅了 queue.* 相关的队列消息。
之后,生产者分别向 queue.p1 和 queue.p2 发布消息
127.0.0.1:6379> PUBLISH queue.p1 msg1
(integer) 1
127.0.0.1:6379> PUBLISH queue.p2 msg2
(integer) 1
这时再看消费者,它就可以接收到这 2 个生产者的消息了。
127.0.0.1:6379> PSUBSCRIBE queue.*
Reading messages... (press Ctrl-C to quit)
...
// 来自queue.p1的消息
1) "pmessage"
2) "queue.*"
3) "queue.p1"
4) "msg1"
// 来自queue.p2的消息
1) "pmessage"
2) "queue.*"
3) "queue.p2"
4) "msg2"
但是基于PubSub的消息队列还有些缺点:
-
不支持数据持久化
-
无法避免消息丢失
-
消息堆积有上限,超出时数据丢失
如果在对数据丢失容忍度较高的场景,想选择轻量级的消息队列,就可以考虑使用redis中的PubSub模型。
3.基于Stream的消息队列(较为成熟)
我们来看 Stream 是如何解决上面这些问题的。
我们依旧从简单到复杂,依次来看 Stream 在做消息队列时,是如何处理的?
首先,Stream 通过 XADD 和 XREAD 完成最简单的生产、消费模型:
- XADD:发布消息
- XREAD:读取消息
生产者发布 2 条消息:
// *表示让Redis自动生成消息ID
127.0.0.1:6379> XADD queue * name zhangsan
"1618469123380-0"
127.0.0.1:6379> XADD queue * name lisi
"1618469127777-0"
使用 XADD 命令发布消息,其中的「*」表示让 Redis 自动生成唯一的消息 ID。
这个消息 ID 的格式是「时间戳-自增序号」。
消费者拉取消息:
// 从开头读取5条消息,0-0表示从开头读取
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 0-0
1) 1) "queue"
2) 1) 1) "1618469123380-0"
2) 1) "name"
2) "zhangsan"
2) 1) "1618469127777-0"
2) 1) "name"
2) "lisi"
如果想继续拉取消息,需要传入上一条消息的 ID:
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 1618469127777-0
(nil)
没有消息,Redis 会返回 NULL。
以上就是 Stream 最简单的生产、消费。
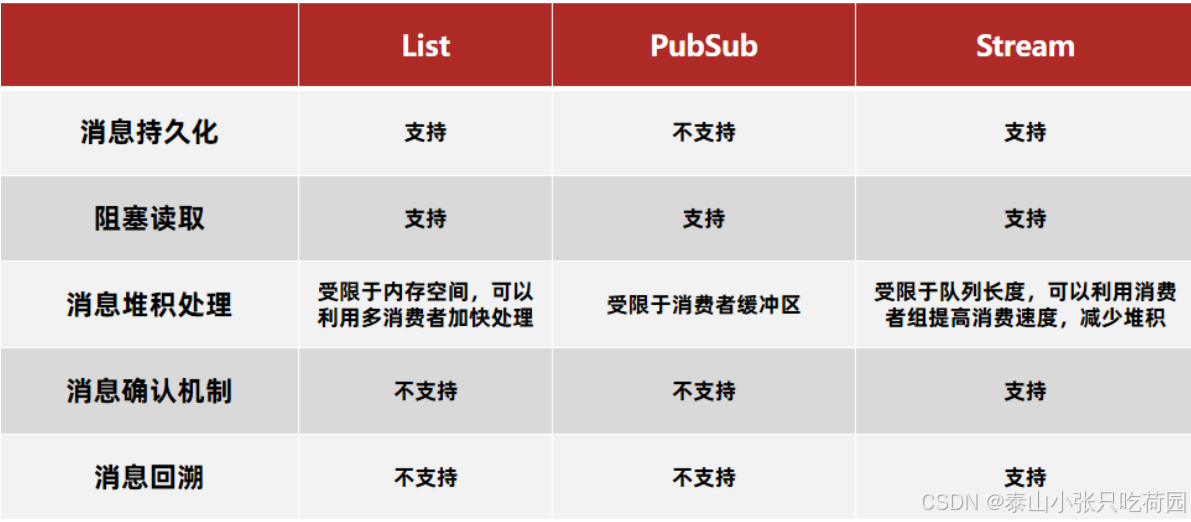
3.三种队列的对比
四、总结
总体来说,使用Redis中的Stream作为消息队列还是相当靠谱的,主要场景应用在消息量少的轻量级服务,但同时也缺少一些高级特性:相对于专门的消息队列系统,Redis在消息队列方面的功能可能相对简单。例如,它可能缺乏一些高级消息传递功能,如消息重试、消息路由、持久化消息等。Redis的主要设计目标是提供高性能和低延迟,而不是强一致性和高可靠性。在某些情况下,Redis可能会丢失消息,或者在出现故障时可能无法提供持久性保证。
因此Redis适用于简单的中小型项目 如果功能简单,访问量并不大可以考虑。
如果你的应用程序对可靠性和高级功能有严格要求,并且需要处理大量的消息和复杂的消息路由,那么使用专门的消息队列系统可能更合适。

















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









