



-
模拟post提交表单,获取Cookie
使用火狐浏览器打开学校教务系统,F12打开开发者模式

点击网络,持续记录数据包,发现login.action是提交的表单信息
 查看表单数据,发现前端对params进行了加密
查看表单数据,发现前端对params进行了加密
 继续通过抓包分析发现前端对表单进行了hex_md5加密,对此方面了解不多,所以换一种方法获取cookie
继续通过抓包分析发现前端对表单进行了hex_md5加密,对此方面了解不多,所以换一种方法获取cookie -
通过selenium获取cookie
通过模拟登录操作来获取cookie
方案如下:
1)通过浏览器自动化,定位表单元素
通过定位元素发现每个input都是两个叠加显示的,只有第一个input被点击才能定位到真正input,否则会找不到指定元素

2)自动键入预定的数值,登录获取cookie
附上代码
browser.get(url)
# # 用户名
username_tag1 = browser.find_element_by_id('username1')
username_tag = browser.find_element_by_id('username')
# 密码
pwd_tag1 = browser.find_element_by_id('password1')
pwd_tag = browser.find_element_by_id('password')
# 登录按钮
login_tag = browser.find_element_by_id('login')
username_tag1.click()
username_tag.send_keys(username)
pwd_tag1.click()
pwd_tag.send_keys(password)
login_tag.click()
登陆成功,获取browser中存储的cookie
# 获取cookies
co = {}
cookie = browser.get_cookies()
browser.quit()
for item in cookie:
co[item['name']] = item['value']
- 获取成绩
打开成绩获取页面,通过抓包分析找到URL ,和提交的data
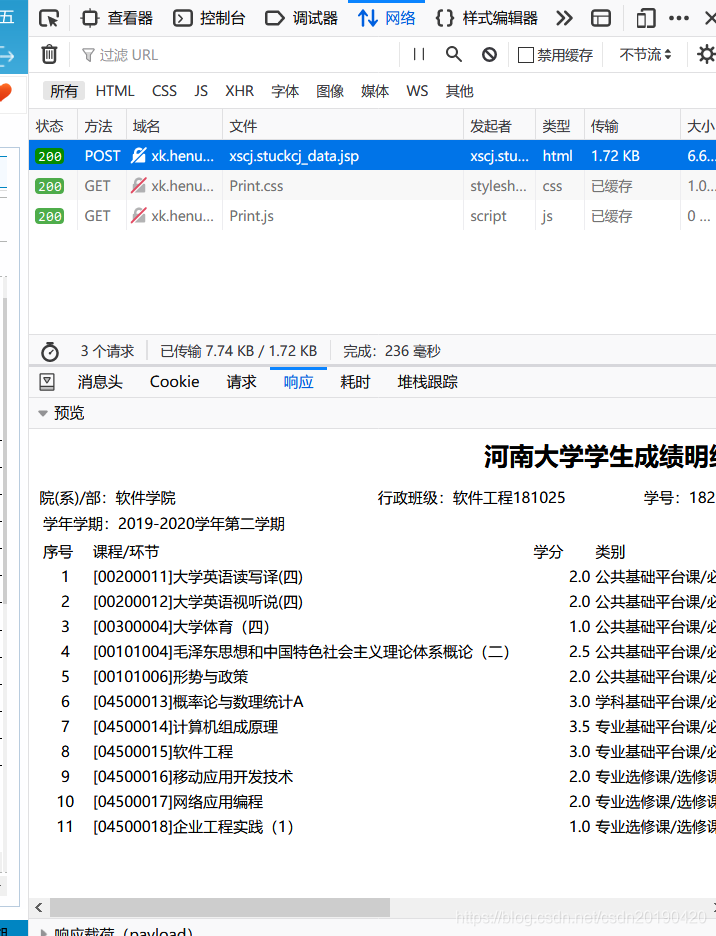
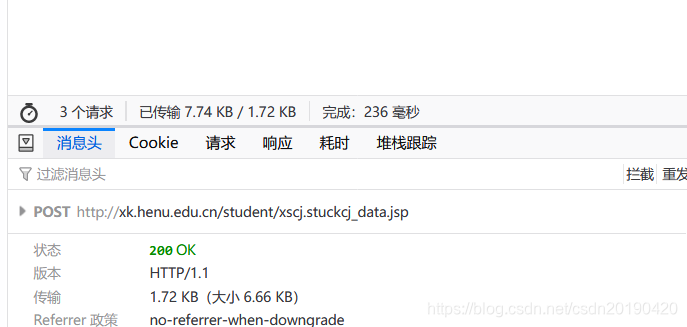
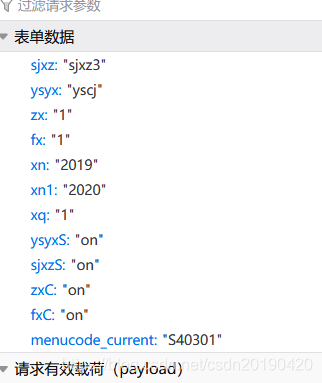
发现xn,xn1是学年,xq是学期
通过requests模块发送post,xpath对返回的页面数据进行处理
# 得到数据
def getData(cookie, url, xq, xn1, xn2, dit, list):
headers = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64 ; x64; rv: 78.0) Gecko / 20100101 Firefox / 78.0"
}
data = {
'sjxz': 'sjxz3',
'ysyx': 'yscj',
'zx': '1',
'fx': '1',
'xn': str(xn1),
'xn1': str(xn2),
'xq': str(xq),
'ysyxS': 'on',
'sjxzS': 'on',
'zxC': 'on',
'fxC': 'on'
}
html_text = requests.post(url=url, headers=headers, data=data, cookies=cookie)
# print(html_text.text)
tree = etree.HTML(html_text.text)
try:
dit['姓名:'] = str(tree.xpath('//div[3]/div[4]/text()')[0])[3:]
dit['学号:'] = str(tree.xpath('//div[3]/div[3]/text()')[0])[3:]
dit['院(系)/部:'] = str(tree.xpath('//div[3]/div[1]/text()')[0])[7:]
dit['学年学期:'] = str(tree.xpath('//table[1]//td/text()')[0])[5:]
for i in range(2, 9):
list.append(tree.xpath('//table[2]//tr/td[%d]/text()' % i))
except:
return 404
return 200
- 持久化存储,以Excel为例
把爬取到的数据持久化存储到xls表格中
# Excel持久化存储
def saveDataByExcel(dit, list, path, state_code):
workbook = xlwt.Workbook(encoding='utf-8') # 创建workbook对象
worksheet = workbook.add_sheet('sheet1') # 创建表
worksheet.col(0).width = 256 * 50
if state_code == 404 or state_code == '404':
worksheet.write(0, 0, '没有检索到记录!')
workbook.save(path) # 保存数据表
return
worksheet.col(1).width = 256 * 20
worksheet.col(2).width = 256 * 15
index = 0
for key, value in dit.items():
worksheet.write(index, 0, key)
worksheet.write(index, 1, value)
index += 1
c = 0
for i in list:
r = index
for j in i:
worksheet.write(r, c, j)
r += 1
c += 1
workbook.save(path) # 保存数据表
查看保存的数据
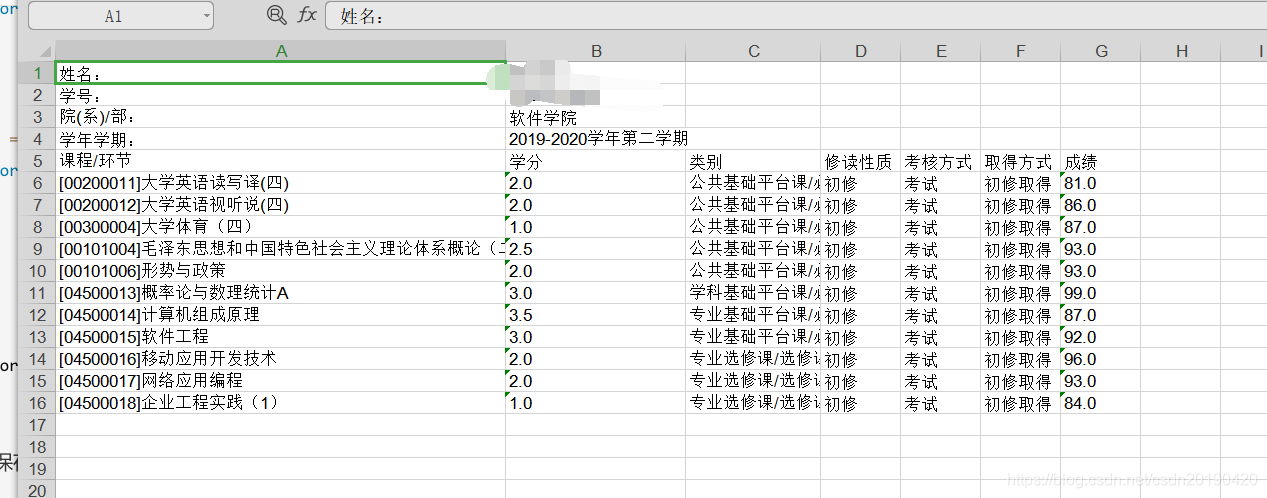
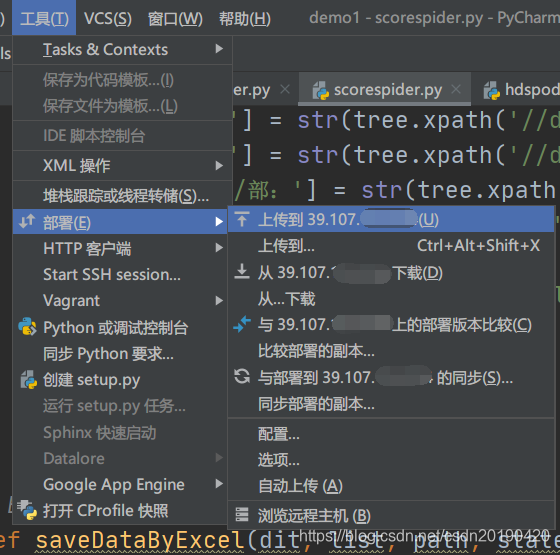
通过pycharm部署到linux服务器上

















 2337
2337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









