




大家好,目标检测是计算机视觉中的基本任务,在高层次上,它涉及预测图像中物体的位置和类别。像You-Only-Look-Once(YOLO)系列中的最先进(SOTA)深度学习模型已经达到了令人瞩目的准确度,然而目标检测的一个难点是小物体检测。本文将介绍使用切片辅助的超级推断(SAHI)来检测数据集中的小物体。
1.检测小物体的难点
检测小物体很困难,物体越小,检测模型可用的信息就越少。如果汽车在远处,它可能只占据图像中的几个像素。与人类难以辨认远处物体的情况类似,在没有视觉可辨识特征(如车轮和车牌)的情况下更难识别汽车。
用相关数据进行训练的模型准确率才能得到保障,大多数标准的目标检测数据集和基准都专注于中大型物体,这意味着大多数现成的目标检测模型未经优化用于小物体检测。
目标检测模型通常采用固定尺寸的输入。例如,YOLOv8 是在最大边长为 640 像素的图像上训练的,这意味着将一张大小为 1920x1080 的图像输入时,模型会将图像缩小到 640x360 然后进行预测,降低了小物体的分辨率并丢弃了重要信息。
2. SAHI的工作原理

理论上可以在较大的图像上训练模型以提高小物体的检测能力,然而这将需要更多的内存、更多的计算能力和更加费时费力的数据集创建。与之相反的方法是利用现有的目标检测,将模型应用于图像中固定大小的块或切片,然后将结果拼接在一起。
SAHI 将图像分成完全覆盖它的切片,并对每个切片使用指定的检测模型进行推断。然后将所有这些切片的预测结果合并在一起,生成整个图像上的一个检测列表。SAHI 中的“超级”来自于 SAHI 的输出不是模型推断的结果,而是涉及多个模型推断的计算结果。SAHI 切片允许重叠(如上面的 GIF 所示),这可以确保至少有一个切片中包含足够多的对象以进行检测。
3.SAHI应用于数据集
为了说明如何使用 SAHI 检测小物体,使用中国天津大学机器学习与数据挖掘实验室的AISKYEYE 团队的 VisDrone 检测数据集。该数据集包含 8,629 张图像,边长从 360 像素到 2,000 像素不等,使其成为 SAHI 的理想测试平台。Ultralytics 的 YOLOv8l 将作为基本目标检测模型,使用以下库:
-
fiftyone 用于数据集管理和可视化
-
huggingface_hub 用于从 Hugging Face Hub 加载 VisDrone 数据集
-
ultralytics 用于使用 YOLOv8 进行推断
-
sahi 用于在图像切片上运行推断
如果尚未安装,请安装这些库的最新版本,需要 fiftyone>=0.23.8 来从 Hugging Face Hub 加载 VisDrone:
pip install -U fiftyone sahi ultralytics huggingface_hub --quiet现在在 Python 进程中,导入将用于查询和管理数据的 FiftyOne 模块:
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.utils.huggingface as fouh
from fiftyone import ViewField as F使用 FiftyOne 的 Hugging Face 工具中的 load_from_hub() 函数直接从 Hugging Face Hub 通过 repo_id 加载 VisDrone 数据集的部分。为了演示并保持代码执行尽可能快,只取数据集的前 100 张图像,将正在创建的新数据集命名为 ”sahi-test“:
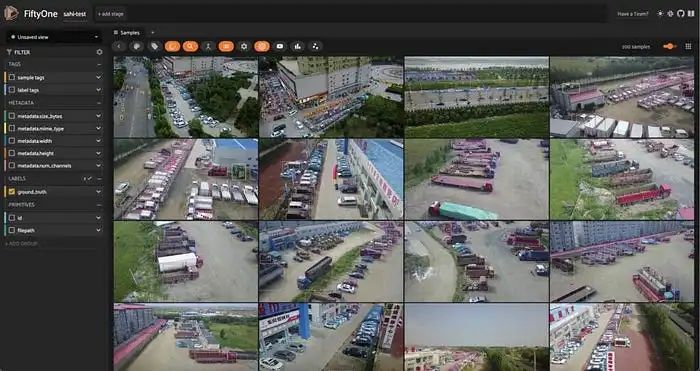
4.使用YOLOv8进行推理
使用SAHI对数据进行超级推理,在引入SAHI之前,使用Ultralytics的大型YOLOv8模型进行标准目标检测推理。首先创建一个ultralytics.YOLO模型实例,如果需要的话会下载模型检查点。将这个模型应用到数据集上,并将结果存储在样本的“base_model”字段中:
from ultralytics import YOLO
ckpt_path = "yolov8l.pt"
model = YOLO(ckpt_path)
dataset.apply_model(model, label_field="base_model")
session.view = dataset.view()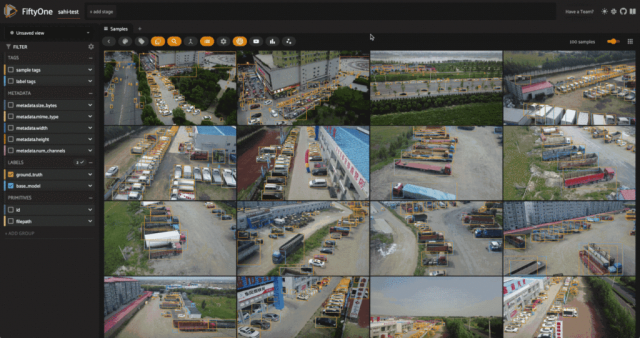
通过观察模型的预测和ground truth标签,我们可以看到一些情况。YOLOv8l模型检测到的类与V
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











