




大家好,数据可视化是探索性数据分析的重要组成部分,因为它有助于分析和可视化数据,以获得对数据分布、变量之间的关系和潜在异常值的启示性见解。Python具有丰富的库,可以快速高效地创建可视化。
在Python中,通常使用以下几种类型的可视化进行探索性数据分析:柱状图(用于显示不同类别之间的比较)、折线图(用于显示随时间或不同类别的趋势)、饼图(用于显示不同类别的比例或百分比)、直方图(用于显示单个变量的分布)、热图(用于显示不同变量之间的相关性)、散点图(用于显示两个连续变量之间的关系)、箱线图(用于显示变量的分布并识别异常值)。
1. 理解业务问题
心血管疾病是全球死亡的主要原因。根据世界卫生组织的数据,每年约有1,790万人死于心脏病。其中85%的死亡是由心脏病发作和中风引起的。本文中将探索来自Kaggle的心脏病数据集,并使用Python创建用于探索性数据分析的数据可视化。
该数据集包含有关患者的数据,包括年龄、性别、血压、胆固醇水平以及是否患有心脏病发作等各种变量。该数据集的目标是根据患者的医疗属性预测其是否有心脏病发作的风险。
2.导入必要的库
# import libraries
import pandas as pd
import numpy as np
# data visualization
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots3. 加载数据集
将数据加载到一个Pandas DataFrame中,并开始探索它。
heart = pd.read_csv('heart.csv')现在已经加载数据,看一下DataFrame的前几行,以了解数据的大致情况。
heart.head()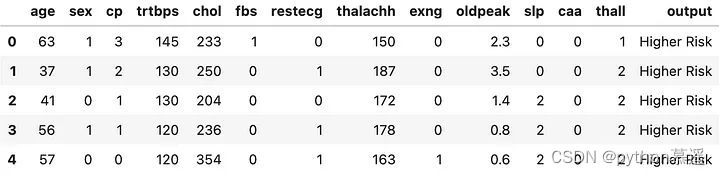
可以看到数据集包含14列,包括目标列(输出),该列指示患者是否患有心脏病发作,现在开始创建可视化图表。
4. 数据清理和预处理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8200
8200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











