



摘要
随着人工智能技术的迅猛发展,越来越多的开发者需要在本地或服务器上部署复杂的AI应用。Docker Compose作为一种简单高效的多容器应用管理工具,为AI应用的部署提供了极大的便利。本文将通过一个完整的AI应用案例,详细介绍如何使用Docker Compose配置、启动和管理多个服务,包括API服务、数据库、缓存、向量数据库等核心组件。文章将涵盖系统架构设计、服务部署、日志管理、常见问题排查等关键环节,并提供详细的代码示例和多种可视化图表。目标读者为中国开发者,特别是AI应用开发者,帮助他们快速掌握Docker Compose的使用方法和最佳实践。
正文
第一章:引言与背景
在当今的软件开发领域,人工智能技术正以前所未有的速度融入各类应用中。从自然语言处理到计算机视觉,从推荐系统到智能客服,AI功能已成为许多应用的核心竞争力。然而,如何高效地部署这些复杂的AI应用,确保它们在不同环境中稳定运行,成为了开发者面临的重要挑战。
传统的应用部署方式往往需要手动配置多个服务,管理复杂的依赖关系,这不仅耗时耗力,还容易出错。Docker Compose的出现为这一问题提供了优雅的解决方案。通过一个简单的YAML配置文件,开发者可以定义和运行多容器Docker应用,大大简化了部署流程。
1.1 为什么选择Docker Compose?
Docker Compose具有以下显著优势:
- 简化配置:通过单一YAML文件管理多个服务
- 环境一致性:确保开发、测试、生产环境的一致性
- 快速部署:一条命令即可启动整个应用栈
- 资源隔离:每个服务运行在独立的容器中
- 易于扩展:支持水平扩展和负载均衡
1.2 AI应用的特殊需求
AI应用相比传统应用具有以下特点:
- 组件复杂:通常包含模型服务、数据库、缓存等多个组件
- 资源密集:对CPU、内存、GPU等资源需求较高
- 数据敏感:需要安全的数据存储和传输机制
- 实时性要求:对响应时间有较高要求
第二章:AI应用系统架构设计
在开始部署之前,我们需要设计一个合理的系统架构。一个典型的AI应用系统通常包含以下核心组件:
2.1 核心组件介绍
2.2 各组件功能说明
- API服务:提供RESTful API接口,处理业务逻辑
- 数据库服务:存储应用数据,如用户信息、配置等
- 缓存服务:提供高速缓存,提升系统性能
- 向量数据库:存储和检索向量数据,支持语义搜索
- 插件守护进程:管理外部插件的加载和执行
- 沙箱环境:提供安全的代码执行环境
- Worker服务:处理异步任务和后台作业
- Worker Beat:处理定时任务和周期性作业
- Web前端:提供用户界面
- Nginx反向代理:处理请求路由和负载均衡
- SSRF代理:防止服务器端请求伪造攻击
第三章:Docker Compose配置详解
Docker Compose使用docker-compose.yml文件来定义服务、网络和卷。以下是一个完整的AI应用部署配置示例:
# docker-compose.yml
version: '3.8'
# 定义网络
networks:
ai_network:
driver: bridge
ipam:
config:
- subnet: 172.20.0.0/16
# 定义卷
volumes:
postgres_data:
driver: local
redis_data:
driver: local
weaviate_data:
driver: local
# 定义服务
services:
# API服务
api:
image: langgenius/dify-api:1.7.2
container_name: ai_api
restart: always
ports:
- "5001:5001"
environment:
- DIFY_BIND_ADDRESS=0.0.0.0
- DB_HOST=db
- DB_PORT=5432
- DB_NAME=dify
- DB_USER=postgres
- DB_PASSWORD=postgres
- REDIS_HOST=redis
- REDIS_PORT=6379
- WEAVIATE_ENDPOINT=http://weaviate:8080
- PLUGIN_DAEMON_HOST=plugin_daemon
- PLUGIN_DAEMON_PORT=5003
# 设置区域环境变量,解决setlocale问题
- LANG=en_US.UTF-8
- LANGUAGE=en_US:en
- LC_ALL=en_US.UTF-8
depends_on:
- db
- redis
- weaviate
- plugin_daemon
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5001/health"]
interval: 30s
timeout: 10s
retries: 3
# 数据库服务
db:
image: postgres:15-alpine
container_name: ai_postgres
restart: always
ports:
- "5432:5432"
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=dify
volumes:
- postgres_data:/var/lib/postgresql/data
- ./init-scripts:/docker-entrypoint-initdb.d
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
# Redis缓存服务
redis:
image: redis:6-alpine
container_name: ai_redis
restart: always
ports:
- "6379:6379"
volumes:
- redis_data:/data
networks:
- ai_network
command: redis-server --appendonly yes
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# Weaviate向量数据库
weaviate:
image: semitechnologies/weaviate:1.19.0
container_name: ai_weaviate
restart: always
ports:
- "8080:8080"
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
CLUSTER_HOSTNAME: 'node1'
volumes:
- weaviate_data:/var/lib/weaviate
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
# Nginx反向代理
nginx:
image: nginx:latest
container_name: ai_nginx
restart: always
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
- ./ssl:/etc/nginx/ssl:ro
depends_on:
- api
- web
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# 插件守护进程
plugin_daemon:
image: langgenius/dify-plugin-daemon:0.2.0-local
container_name: ai_plugin_daemon
restart: always
ports:
- "5003:5003"
environment:
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
volumes:
- ./plugins:/app/plugins
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# 安全沙箱
sandbox:
image: langgenius/dify-sandbox:0.2.12
container_name: ai_sandbox
restart: always
ports:
- "8194:8194"
environment:
- SANDBOX_PORT=8194
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# SSRF代理
ssrf_proxy:
image: ubuntu/squid:latest
container_name: ai_squid
restart: always
ports:
- "3128:3128"
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# Web前端
web:
image: langgenius/dify-web:1.7.2
container_name: ai_web
restart: always
ports:
- "3000:3000"
environment:
- API_BASE_URL=http://api:5001
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
depends_on:
- api
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# Worker服务
worker:
image: langgenius/dify-api:1.7.2
container_name: ai_worker
restart: always
environment:
- DIFY_BIND_ADDRESS=0.0.0.0
- DB_HOST=db
- DB_PORT=5432
- DB_NAME=dify
- DB_USER=postgres
- DB_PASSWORD=postgres
- REDIS_HOST=redis
- REDIS_PORT=6379
- WEAVIATE_ENDPOINT=http://weaviate:8080
- PLUGIN_DAEMON_HOST=plugin_daemon
- PLUGIN_DAEMON_PORT=5003
- EXECUTOR_TYPE=worker
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
depends_on:
- db
- redis
- weaviate
- plugin_daemon
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
command: celery -A app.celery worker -P gevent -c 10 -Q dataset,generation,mail
# Worker Beat服务
worker_beat:
image: langgenius/dify-api:1.7.2
container_name: ai_worker_beat
restart: always
environment:
- DIFY_BIND_ADDRESS=0.0.0.0
- DB_HOST=db
- DB_PORT=5432
- DB_NAME=dify
- DB_USER=postgres
- DB_PASSWORD=postgres
- REDIS_HOST=redis
- REDIS_PORT=6379
- WEAVIATE_ENDPOINT=http://weaviate:8080
- EXECUTOR_TYPE=worker-beat
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
depends_on:
- db
- redis
- weaviate
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
command: celery -A app.celery beat
# 配置卷
volumes:
postgres_data:
redis_data:
weaviate_data:
第四章:服务部署与管理
使用Docker Compose部署服务非常简单,但需要掌握一些关键命令和技巧。
4.1 初始化项目
在开始部署之前,需要创建项目目录结构:
ai-project/
├── docker-compose.yml # Docker Compose配置文件
├── nginx.conf # Nginx配置文件
├── init-scripts/ # 数据库初始化脚本
├── plugins/ # 插件目录
├── ssl/ # SSL证书目录
└── logs/ # 日志目录
4.2 启动服务
运行以下命令启动所有服务:
# 启动所有服务(后台运行)
docker-compose up -d
# 启动指定服务
docker-compose up -d api db redis
# 查看服务状态
docker-compose ps
# 查看服务日志
docker-compose logs
# 查看特定服务日志
docker-compose logs api
4.3 管理服务
# 停止所有服务
docker-compose down
# 停止特定服务
docker-compose stop api
# 重启服务
docker-compose restart api
# 扩展服务实例
docker-compose up -d --scale worker=3
4.4 进入容器
# 进入API服务容器
docker-compose exec api /bin/bash
# 进入数据库容器
docker-compose exec db psql -U postgres -d dify
第五章:实践案例 - 部署AI模型服务
假设我们需要部署一个简单的AI模型服务,提供RESTful API接口供前端调用。以下是完整的实现步骤:
5.1 创建AI模型服务
首先创建一个Python Flask应用,提供模型预测接口:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
AI模型服务
提供机器学习模型的预测接口
"""
import os
import json
import logging
from flask import Flask, request, jsonify
from flask_cors import CORS
import joblib
import numpy as np
from typing import Dict, Any, List
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class AIModelService:
"""AI模型服务类"""
def __init__(self, model_path: str = 'model.pkl'):
"""
初始化AI模型服务
Args:
model_path: 模型文件路径
"""
self.model_path = model_path
self.model = None
self.load_model()
def load_model(self) -> bool:
"""
加载模型
Returns:
是否加载成功
"""
try:
if os.path.exists(self.model_path):
self.model = joblib.load(self.model_path)
logger.info(f"模型加载成功: {self.model_path}")
return True
else:
logger.warning(f"模型文件不存在: {self.model_path}")
# 创建一个简单的示例模型
self._create_sample_model()
return True
except Exception as e:
logger.error(f"模型加载失败: {e}")
return False
def _create_sample_model(self) -> None:
"""创建示例模型"""
# 这里创建一个简单的线性回归模型作为示例
from sklearn.linear_model import LinearRegression
import numpy as np
# 创建示例数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 训练模型
self.model = LinearRegression()
self.model.fit(X, y)
# 保存模型
joblib.dump(self.model, self.model_path)
logger.info("示例模型创建并保存成功")
def predict(self, features: List[float]) -> Dict[str, Any]:
"""
执行预测
Args:
features: 特征数据
Returns:
预测结果
"""
try:
if self.model is None:
return {
'success': False,
'error': '模型未加载'
}
# 转换输入数据
X = np.array(features).reshape(1, -1)
# 执行预测
prediction = self.model.predict(X)
return {
'success': True,
'prediction': prediction.tolist(),
'features': features
}
except Exception as e:
logger.error(f"预测执行失败: {e}")
return {
'success': False,
'error': str(e)
}
def get_model_info(self) -> Dict[str, Any]:
"""
获取模型信息
Returns:
模型信息
"""
try:
if self.model is None:
return {
'success': False,
'error': '模型未加载'
}
return {
'success': True,
'model_type': type(self.model).__name__,
'model_path': self.model_path,
'created_at': os.path.getctime(self.model_path) if os.path.exists(self.model_path) else None
}
except Exception as e:
logger.error(f"获取模型信息失败: {e}")
return {
'success': False,
'error': str(e)
}
# 创建Flask应用
app = Flask(__name__)
CORS(app) # 启用跨域支持
# 初始化AI模型服务
model_service = AIModelService()
@app.route('/')
def index():
"""首页"""
return jsonify({
'message': 'AI模型服务已启动',
'status': 'running'
})
@app.route('/health')
def health_check():
"""健康检查"""
return jsonify({
'status': 'healthy',
'service': 'ai-model-service'
})
@app.route('/predict', methods=['POST'])
def predict():
"""执行预测"""
try:
# 获取请求数据
data = request.get_json()
if not data:
return jsonify({
'success': False,
'error': '缺少请求数据'
}), 400
# 检查必需字段
if 'features' not in data:
return jsonify({
'success': False,
'error': '缺少features字段'
}), 400
features = data['features']
# 验证特征数据
if not isinstance(features, list):
return jsonify({
'success': False,
'error': 'features必须是数组'
}), 400
# 执行预测
result = model_service.predict(features)
if result['success']:
return jsonify(result)
else:
return jsonify(result), 400
except Exception as e:
logger.error(f"预测接口出错: {e}")
return jsonify({
'success': False,
'error': '服务器内部错误'
}), 500
@app.route('/model/info', methods=['GET'])
def model_info():
"""获取模型信息"""
result = model_service.get_model_info()
if result['success']:
return jsonify(result)
else:
return jsonify(result), 400
@app.route('/model/reload', methods=['POST'])
def reload_model():
"""重新加载模型"""
try:
success = model_service.load_model()
if success:
return jsonify({
'success': True,
'message': '模型重新加载成功'
})
else:
return jsonify({
'success': False,
'error': '模型重新加载失败'
}), 500
except Exception as e:
logger.error(f"重新加载模型出错: {e}")
return jsonify({
'success': False,
'error': '服务器内部错误'
}), 500
def main():
"""主函数"""
host = os.environ.get('HOST', '0.0.0.0')
port = int(os.environ.get('PORT', 5001))
logger.info(f"AI模型服务启动中,监听 {host}:{port}")
app.run(host=host, port=port, debug=True)
if __name__ == '__main__':
main()
5.2 创建Dockerfile
为Flask应用创建Dockerfile:
# Dockerfile
FROM python:3.9-slim
# 设置工作目录
WORKDIR /app
# 设置环境变量,解决locale问题
ENV LANG=en_US.UTF-8
ENV LANGUAGE=en_US:en
ENV LC_ALL=en_US.UTF-8
# 安装系统依赖和区域设置
RUN apt-get update && \
apt-get install -y locales && \
rm -rf /var/lib/apt/lists/* && \
locale-gen en_US.UTF-8
# 复制依赖文件
COPY requirements.txt .
# 安装Python依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 创建模型目录
RUN mkdir -p models
# 暴露端口
EXPOSE 5001
# 启动应用
CMD ["python", "app.py"]
创建requirements.txt文件:
Flask==2.0.1
Flask-CORS==3.0.10
joblib==1.1.0
scikit-learn==1.0.2
numpy==1.21.0
5.3 更新docker-compose.yml
将AI模型服务添加到docker-compose.yml文件中:
# 在services部分添加以下内容
# AI模型服务
ai_model:
build:
context: ./ai_model
dockerfile: Dockerfile
container_name: ai_model_service
restart: always
ports:
- "5001:5001"
environment:
- HOST=0.0.0.0
- PORT=5001
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
volumes:
- ./ai_model/models:/app/models
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5001/health"]
interval: 30s
timeout: 10s
retries: 3
5.4 启动服务
运行以下命令启动服务:
# 构建并启动所有服务
docker-compose up -d --build
# 查看服务状态
docker-compose ps
# 查看AI模型服务日志
docker-compose logs ai_model
第六章:日志管理与监控
日志管理是系统运维的重要环节。Docker Compose提供了简单的日志查看功能,但生产环境中通常需要更强大的日志管理工具。
6.1 Docker Compose日志管理
# 查看所有服务日志
docker-compose logs
# 查看最近100行日志
docker-compose logs --tail=100
# 实时查看日志
docker-compose logs -f
# 查看特定服务日志
docker-compose logs api
# 查看特定服务的最近50行日志
docker-compose logs --tail=50 api
6.2 配置日志驱动
可以在docker-compose.yml文件中配置日志驱动,将日志发送到外部日志服务:
services:
api:
# ... 其他配置
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
6.3 集成ELK Stack
为了更好地管理和分析日志,可以集成ELK Stack(Elasticsearch、Logstash、Kibana):
# 在docker-compose.yml中添加以下服务
# Elasticsearch
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.0
container_name: ai_elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms1g -Xmx1g
ports:
- "9200:9200"
- "9300:9300"
volumes:
- es_data:/usr/share/elasticsearch/data
networks:
- ai_network
# Logstash
logstash:
image: docker.elastic.co/logstash/logstash:7.17.0
container_name: ai_logstash
ports:
- "5044:5044"
- "9600:9600"
volumes:
- ./logstash/pipeline:/usr/share/logstash/pipeline:ro
depends_on:
- elasticsearch
networks:
- ai_network
# Kibana
kibana:
image: docker.elastic.co/kibana/kibana:7.17.0
container_name: ai_kibana
ports:
- "5601:5601"
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
networks:
- ai_network
# 添加卷
volumes:
es_data:
第七章:常见问题排查与解决方案
在部署和运行过程中,可能会遇到各种问题。以下是一些常见问题及其解决方法:
7.1 服务无法访问
问题现象:
服务启动成功,但无法通过浏览器或API访问
排查步骤:
- 检查端口映射:
docker-compose ps
- 检查服务状态:
docker-compose logs api
- 检查防火墙规则:
# Ubuntu/Debian
sudo ufw status
# CentOS/RHEL
sudo firewall-cmd --list-all
解决方案:
- 确保端口映射配置正确
- 检查服务是否正常启动
- 确保防火墙允许访问相关端口
7.2 setlocale警告
问题现象:
bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8)
解决方案:
在Dockerfile中安装相关依赖并配置环境变量:
# 安装区域设置支持
RUN apt-get update && \
apt-get install -y locales && \
rm -rf /var/lib/apt/lists/* && \
locale-gen en_US.UTF-8
# 设置环境变量
ENV LANG=en_US.UTF-8
ENV LANGUAGE=en_US:en
ENV LC_ALL=en_US.UTF-8
7.3 数据库连接失败
问题现象:
API服务无法连接到数据库
排查步骤:
- 检查数据库服务状态:
docker-compose ps db
- 检查数据库配置:
docker-compose exec db psql -U postgres -d dify -c "SELECT version();"
- 检查网络连接:
docker-compose exec api ping db
解决方案:
- 确保数据库服务已启动
- 检查数据库连接参数配置
- 确保服务在同一网络中
7.4 插件加载失败
问题现象:
插件守护进程无法加载插件
排查步骤:
- 检查插件目录:
docker-compose exec plugin_daemon ls -la /app/plugins
- 检查插件日志:
docker-compose logs plugin_daemon
解决方案:
- 确保插件文件存在且权限正确
- 检查插件配置文件格式
- 确保插件依赖已安装
第八章:性能优化与最佳实践
8.1 资源限制配置
services:
api:
# ... 其他配置
deploy:
resources:
limits:
cpus: '1.0'
memory: 1G
reservations:
cpus: '0.5'
memory: 512M
8.2 健康检查配置
services:
api:
# ... 其他配置
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5001/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
8.3 多阶段构建优化
# 多阶段构建Dockerfile
# 构建阶段
FROM python:3.9-slim as builder
WORKDIR /app
COPY requirements.txt .
RUN pip install --user -r requirements.txt
# 运行阶段
FROM python:3.9-alpine
WORKDIR /app
COPY --from=builder /root/.local /root/.local
COPY . .
ENV PATH=/root/.local/bin:$PATH
EXPOSE 5001
CMD ["python", "app.py"]
第九章:项目实施计划
第十章:数据分布与性能分析
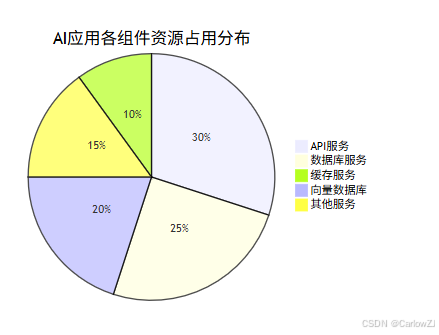
总结
本文详细介绍了如何使用Docker Compose部署一个完整的AI应用系统。通过实践案例,我们展示了系统架构设计、服务部署、日志管理、常见问题排查等关键环节,并提供了详细的代码示例和多种可视化图表。
核心要点回顾
- 系统架构设计:合理设计包含API服务、数据库、缓存、向量数据库等组件的系统架构
- Docker Compose配置:通过YAML文件定义和管理多容器应用
- 服务部署管理:掌握Docker Compose的基本命令和操作技巧
- 日志管理监控:配置日志驱动,集成专业日志管理工具
- 问题排查解决:针对常见问题提供详细的排查步骤和解决方案
- 性能优化实践:通过资源配置、健康检查、多阶段构建等方式优化系统性能
实践建议
- 循序渐进:从简单的服务开始,逐步增加复杂性
- 环境一致性:确保开发、测试、生产环境的一致性
- 监控告警:建立完善的监控和告警机制
- 安全防护:重视数据安全和访问控制
- 文档完善:编写详细的部署和运维文档
未来展望
随着AI技术的不断发展,Docker Compose在AI应用部署中将发挥更加重要的作用:
- GPU支持:更好地支持GPU资源分配和管理
- 云原生集成:与Kubernetes等云原生技术栈深度集成
- 自动化运维:实现更智能的自动化部署和运维
- 边缘计算:支持边缘设备上的AI应用部署
通过本文的学习和实践,开发者可以快速掌握使用Docker Compose部署AI应用的技能,为构建稳定、高效的AI应用系统奠定坚实基础。




















 1502
1502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











