



摘要
本文面向中国开发者,特别是AI应用开发者,详细介绍了AI应用开发的全流程,包括环境搭建、模型训练、系统架构设计、部署与优化。文章通过实践案例,结合Python代码示例、架构图、流程图、思维导图等多种形式,帮助读者快速掌握AI应用开发的关键技术和最佳实践。文章还提供了常见问题的解答和扩展阅读资源,助力开发者提升技术水平。
正文
第一章:AI应用开发基础
1.1 环境搭建
在开始AI应用开发之前,我们需要搭建一个适合的开发环境。推荐使用Python语言,因为它拥有丰富的机器学习和深度学习库。
对于AI应用开发,建议使用以下技术栈:
- Python 3.8+
- TensorFlow/PyTorch(深度学习框架)
- scikit-learn(传统机器学习)
- pandas/numpy(数据处理)
- matplotlib/seaborn(数据可视化)
- Flask/FastAPI(Web服务)
实践示例:
import sys
import subprocess
import platform
def check_python_version():
"""
检查Python版本是否符合AI开发要求
"""
version = sys.version_info
print(f"当前Python版本: {version.major}.{version.minor}.{version.micro}")
if version.major >= 3 and version.minor >= 8:
print("✅ Python版本符合AI开发要求")
return True
else:
print("❌ Python版本过低,建议升级到3.8以上")
return False
def install_ai_libraries():
"""
安装AI开发常用库
"""
# 需要安装的AI库列表
ai_packages = [
"numpy",
"pandas",
"matplotlib",
"seaborn",
"scikit-learn",
"tensorflow",
"torch", # PyTorch
"flask",
"fastapi"
]
print("正在安装AI开发常用库...")
for package in ai_packages:
try:
print(f" 安装 {package}...")
subprocess.run([sys.executable, "-m", "pip", "install", package],
check=True, stdout=subprocess.DEVNULL)
print(f" ✅ {package} 安装成功")
except subprocess.CalledProcessError:
print(f" ❌ {package} 安装失败")
except Exception as e:
print(f" ❌ 安装 {package} 时发生错误: {e}")
print("AI库安装完成")
def setup_virtual_environment(env_name="ai_dev_env"):
"""
设置AI开发虚拟环境
:param env_name: 虚拟环境名称
"""
try:
print(f"正在创建虚拟环境: {env_name}")
subprocess.run([sys.executable, "-m", "venv", env_name], check=True)
print(f"✅ 虚拟环境 {env_name} 创建成功")
# 获取pip路径
if platform.system() == "Windows":
pip_path = f"{env_name}\\Scripts\\pip"
else:
pip_path = f"{env_name}/bin/pip"
# 升级pip
print("正在升级pip...")
subprocess.run([pip_path, "install", "--upgrade", "pip"], check=True)
print("✅ pip升级完成")
print(f"\n使用以下命令激活虚拟环境:")
if platform.system() == "Windows":
print(f"{env_name}\\Scripts\\activate")
else:
print(f"source {env_name}/bin/activate")
except subprocess.CalledProcessError as e:
print(f"❌ 创建虚拟环境时发生错误: {e}")
except Exception as e:
print(f"💥 设置虚拟环境时发生未知错误: {e}")
# 检查Python版本
if __name__ == "__main__":
check_python_version()
# 安装AI库 (取消注释以运行)
# install_ai_libraries()
# 创建虚拟环境 (取消注释以运行)
# setup_virtual_environment()
1.2 数据预处理
数据是AI应用的核心。在开始模型训练之前,需要对数据进行清洗、标准化和分割。
实践示例:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.impute import SimpleImputer
import warnings
warnings.filterwarnings('ignore')
class DataPreprocessor:
"""
数据预处理类
"""
def __init__(self):
self.scaler = StandardScaler()
self.label_encoders = {}
self.imputer = SimpleImputer(strategy='mean')
def load_and_clean_data(self, file_path):
"""
加载并清洗数据
:param file_path: 数据文件路径
:return: 清洗后的数据
"""
try:
# 加载数据
data = pd.read_csv(file_path)
print(f"✅ 数据加载成功,形状: {data.shape}")
# 显示基本信息
print("\n数据基本信息:")
print(data.info())
# 检查缺失值
missing_values = data.isnull().sum()
print("\n缺失值统计:")
print(missing_values[missing_values > 0])
# 删除完全重复的行
initial_shape = data.shape
data = data.drop_duplicates()
final_shape = data.shape
print(f"\n删除重复行: {initial_shape[0] - final_shape[0]} 行")
return data
except FileNotFoundError:
print(f"❌ 找不到文件: {file_path}")
# 创建示例数据
print("正在创建示例数据...")
return self._create_sample_data()
except Exception as e:
print(f"💥 数据加载过程中发生错误: {e}")
return None
def _create_sample_data(self):
"""
创建示例数据用于演示
"""
np.random.seed(42)
n_samples = 1000
data = pd.DataFrame({
'feature1': np.random.normal(0, 1, n_samples),
'feature2': np.random.normal(5, 2, n_samples),
'feature3': np.random.exponential(2, n_samples),
'category': np.random.choice(['A', 'B', 'C'], n_samples),
'target': np.random.randint(0, 2, n_samples)
})
# 添加一些缺失值
missing_indices = np.random.choice(n_samples, size=50, replace=False)
data.loc[missing_indices[:25], 'feature1'] = np.nan
data.loc[missing_indices[25:], 'feature2'] = np.nan
# 添加一些异常值
outlier_indices = np.random.choice(n_samples, size=10, replace=False)
data.loc[outlier_indices, 'feature1'] = data.loc[outlier_indices, 'feature1'] * 10
print("✅ 示例数据创建完成")
return data
def handle_missing_values(self, data):
"""
处理缺失值
:param data: 原始数据
:return: 处理缺失值后的数据
"""
print("\n正在处理缺失值...")
# 数值型特征使用均值填充
numeric_columns = data.select_dtypes(include=[np.number]).columns
numeric_columns = numeric_columns.drop('target', errors='ignore')
for column in numeric_columns:
if data[column].isnull().sum() > 0:
imputer = SimpleImputer(strategy='mean')
data[column] = imputer.fit_transform(data[[column]]).ravel()
print(f" {column}: 使用均值填充 {data[column].isnull().sum()} 个缺失值")
# 分类特征使用众数填充
categorical_columns = data.select_dtypes(include=['object']).columns
for column in categorical_columns:
if data[column].isnull().sum() > 0:
mode_value = data[column].mode()[0] if not data[column].mode().empty else 'Unknown'
data[column].fillna(mode_value, inplace=True)
print(f" {column}: 使用众数 '{mode_value}' 填充 {data[column].isnull().sum()} 个缺失值")
print("✅ 缺失值处理完成")
return data
def encode_categorical_features(self, data):
"""
编码分类特征
:param data: 数据
:return: 编码后的数据
"""
print("\n正在编码分类特征...")
categorical_columns = data.select_dtypes(include=['object']).columns
for column in categorical_columns:
if column != 'target': # 假设target列已经是数值型
le = LabelEncoder()
data[column] = le.fit_transform(data[column])
self.label_encoders[column] = le
print(f" {column}: 已编码为数值")
print("✅ 分类特征编码完成")
return data
def scale_features(self, data, fit=True):
"""
标准化特征
:param data: 数据
:param fit: 是否重新拟合scaler
:return: 标准化后的数据
"""
print("\n正在标准化特征...")
# 选择数值型特征进行标准化
numeric_columns = data.select_dtypes(include=[np.number]).columns
numeric_columns = numeric_columns.drop('target', errors='ignore')
if fit:
data[numeric_columns] = self.scaler.fit_transform(data[numeric_columns])
print(" 已重新拟合标准化器")
else:
data[numeric_columns] = self.scaler.transform(data[numeric_columns])
print(" 使用已拟合的标准化器")
print("✅ 特征标准化完成")
return data
def split_data(self, data, target_column='target', test_size=0.2, random_state=42):
"""
分割数据集
:param data: 数据
:param target_column: 目标列名
:param test_size: 测试集比例
:param random_state: 随机种子
:return: 训练集和测试集
"""
try:
# 分离特征和目标
X = data.drop(columns=[target_column])
y = data[target_column]
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state, stratify=y
)
print(f"\n✅ 数据分割完成")
print(f" 训练集: {X_train.shape[0]} 样本")
print(f" 测试集: {X_test.shape[0]} 样本")
print(f" 特征数: {X_train.shape[1]}")
return X_train, X_test, y_train, y_test
except Exception as e:
print(f"💥 数据分割时发生错误: {e}")
return None, None, None, None
# 使用示例
if __name__ == "__main__":
# 创建数据预处理器
preprocessor = DataPreprocessor()
# 加载数据
data = preprocessor.load_and_clean_data('data.csv')
if data is not None:
# 处理缺失值
data = preprocessor.handle_missing_values(data)
# 编码分类特征
data = preprocessor.encode_categorical_features(data)
# 标准化特征
data = preprocessor.scale_features(data)
# 分割数据
X_train, X_test, y_train, y_test = preprocessor.split_data(data)
第二章:模型训练与评估
2.1 模型选择
根据问题类型选择合适的模型。对于分类问题,可以使用逻辑回归、决策树或深度学习模型。
实践示例:
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
class ModelTrainer:
"""
模型训练器类
"""
def __init__(self):
self.models = {}
self.trained_models = {}
self.results = {}
def initialize_models(self):
"""
初始化常用模型
"""
print("正在初始化模型...")
self.models = {
'LogisticRegression': LogisticRegression(random_state=42, max_iter=1000),
'RandomForest': RandomForestClassifier(n_estimators=100, random_state=42),
'SVM': SVC(random_state=42, probability=True)
}
print("✅ 模型初始化完成:")
for name in self.models.keys():
print(f" - {name}")
def train_models(self, X_train, y_train):
"""
训练所有模型
:param X_train: 训练特征
:param y_train: 训练标签
"""
print("\n开始训练模型...")
for name, model in self.models.items():
try:
print(f" 训练 {name}...")
model.fit(X_train, y_train)
self.trained_models[name] = model
print(f" ✅ {name} 训练完成")
except Exception as e:
print(f" ❌ {name} 训练失败: {e}")
print("模型训练完成")
def evaluate_models(self, X_test, y_test):
"""
评估所有训练好的模型
:param X_test: 测试特征
:param y_test: 测试标签
"""
print("\n开始评估模型...")
for name, model in self.trained_models.items():
try:
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
# 交叉验证
cv_scores = cross_val_score(model, X_test, y_test, cv=5)
# 保存结果
self.results[name] = {
'accuracy': accuracy,
'cv_mean': cv_scores.mean(),
'cv_std': cv_scores.std(),
'predictions': y_pred
}
print(f" {name}:")
print(f" 准确率: {accuracy:.4f}")
print(f" 交叉验证: {cv_scores.mean():.4f} (+/- {cv_scores.std() * 2:.4f})")
except Exception as e:
print(f" ❌ {name} 评估失败: {e}")
print("模型评估完成")
def get_best_model(self):
"""
获取最佳模型
:return: 最佳模型名称和模型对象
"""
if not self.results:
print("❌ 没有评估结果")
return None, None
# 根据准确率选择最佳模型
best_model_name = max(self.results.keys(),
key=lambda x: self.results[x]['accuracy'])
best_model = self.trained_models[best_model_name]
print(f"\n🏆 最佳模型: {best_model_name}")
print(f" 准确率: {self.results[best_model_name]['accuracy']:.4f}")
return best_model_name, best_model
def plot_model_comparison(self):
"""
绘制模型比较图
"""
if not self.results:
print("❌ 没有评估结果可绘制")
return
# 准备数据
model_names = list(self.results.keys())
accuracies = [self.results[name]['accuracy'] for name in model_names]
cv_means = [self.results[name]['cv_mean'] for name in model_names]
cv_stds = [self.results[name]['cv_std'] for name in model_names]
# 创建图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 准确率比较
bars = ax1.bar(model_names, accuracies, color=['skyblue', 'lightgreen', 'lightcoral'])
ax1.set_title('模型准确率比较')
ax1.set_ylabel('准确率')
ax1.set_ylim(0, 1)
# 添加数值标签
for bar, acc in zip(bars, accuracies):
ax1.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{acc:.3f}', ha='center', va='bottom')
# 交叉验证结果
x_pos = np.arange(len(model_names))
ax2.bar(x_pos, cv_means, yerr=cv_stds, capsize=5,
color=['skyblue', 'lightgreen', 'lightcoral'])
ax2.set_title('交叉验证结果比较')
ax2.set_ylabel('准确率')
ax2.set_xticks(x_pos)
ax2.set_xticklabels(model_names)
ax2.set_ylim(0, 1)
# 添加数值标签
for i, (mean, std) in enumerate(zip(cv_means, cv_stds)):
ax2.text(i, mean + std + 0.01, f'{mean:.3f}', ha='center', va='bottom')
plt.tight_layout()
plt.show()
def print_detailed_report(self, model_name, X_test, y_test):
"""
打印详细评估报告
:param model_name: 模型名称
:param X_test: 测试特征
:param y_test: 测试标签
"""
if model_name not in self.trained_models:
print(f"❌ 模型 {model_name} 未找到")
return
model = self.trained_models[model_name]
y_pred = model.predict(X_test)
print(f"\n{model_name} 详细评估报告:")
print("="*50)
print("分类报告:")
print(classification_report(y_test, y_pred))
print("\n混淆矩阵:")
cm = confusion_matrix(y_test, y_pred)
print(cm)
# 绘制混淆矩阵热力图
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title(f'{model_name} 混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
# 使用示例
if __name__ == "__main__":
# 创建示例数据
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型训练器
trainer = ModelTrainer()
# 初始化模型
trainer.initialize_models()
# 训练模型
trainer.train_models(X_train, y_train)
# 评估模型
trainer.evaluate_models(X_test, y_test)
# 获取最佳模型
best_name, best_model = trainer.get_best_model()
# 显示详细报告
if best_name:
trainer.print_detailed_report(best_name, X_test, y_test)
2.2 深度学习模型
对于复杂的任务,深度学习模型通常表现更好。以下是一个简单的神经网络示例。
实践示例:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, classification_report
import warnings
warnings.filterwarnings('ignore')
class DeepLearningModel:
"""
深度学习模型类
"""
def __init__(self, input_dim, num_classes=2):
"""
初始化深度学习模型
:param input_dim: 输入特征维度
:param num_classes: 分类数
"""
self.input_dim = input_dim
self.num_classes = num_classes
self.model = None
self.history = None
def build_model(self, architecture='default'):
"""
构建神经网络模型
:param architecture: 模型架构类型
"""
print("正在构建神经网络模型...")
self.model = Sequential()
if architecture == 'default':
# 默认架构
self.model.add(Dense(128, activation='relu', input_shape=(self.input_dim,)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(64, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(32, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.2))
elif architecture == 'deep':
# 深层架构
self.model.add(Dense(256, activation='relu', input_shape=(self.input_dim,)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.4))
self.model.add(Dense(128, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(64, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(32, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.2))
# 输出层
if self.num_classes == 2:
self.model.add(Dense(1, activation='sigmoid'))
self.model.compile(
optimizer=Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy']
)
else:
self.model.add(Dense(self.num_classes, activation='softmax'))
self.model.compile(
optimizer=Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
print("✅ 神经网络模型构建完成")
print("\n模型架构:")
self.model.summary()
def train(self, X_train, y_train, X_val=None, y_val=None,
epochs=100, batch_size=32, verbose=1):
"""
训练模型
:param X_train: 训练特征
:param y_train: 训练标签
:param X_val: 验证特征
:param y_val: 验证标签
:param epochs: 训练轮数
:param batch_size: 批次大小
:param verbose: 日志详细程度
"""
if self.model is None:
print("❌ 模型未构建,请先调用 build_model 方法")
return
print("\n开始训练神经网络模型...")
# 定义回调函数
callbacks = [
EarlyStopping(
monitor='val_loss' if X_val is not None else 'loss',
patience=10,
restore_best_weights=True
),
ReduceLROnPlateau(
monitor='val_loss' if X_val is not None else 'loss',
factor=0.5,
patience=5,
min_lr=1e-7
)
]
# 准备验证数据
validation_data = (X_val, y_val) if X_val is not None and y_val is not None else None
# 训练模型
self.history = self.model.fit(
X_train, y_train,
validation_data=validation_data,
epochs=epochs,
batch_size=batch_size,
callbacks=callbacks,
verbose=verbose
)
print("✅ 模型训练完成")
def evaluate(self, X_test, y_test):
"""
评估模型
:param X_test: 测试特征
:param y_test: 测试标签
"""
if self.model is None:
print("❌ 模型未构建")
return
print("\n正在评估模型...")
# 预测
y_pred_prob = self.model.predict(X_test)
if self.num_classes == 2:
y_pred = (y_pred_prob > 0.5).astype(int).flatten()
else:
y_pred = np.argmax(y_pred_prob, axis=1)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"测试准确率: {accuracy:.4f}")
# 分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred))
return accuracy, y_pred
def plot_training_history(self):
"""
绘制训练历史
"""
if self.history is None:
print("❌ 没有训练历史可绘制")
return
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 损失曲线
ax1.plot(self.history.history['loss'], label='训练损失')
if 'val_loss' in self.history.history:
ax1.plot(self.history.history['val_loss'], label='验证损失')
ax1.set_title('模型损失')
ax1.set_xlabel('轮数')
ax1.set_ylabel('损失')
ax1.legend()
ax1.grid(True)
# 准确率曲线
ax2.plot(self.history.history['accuracy'], label='训练准确率')
if 'val_accuracy' in self.history.history:
ax2.plot(self.history.history['val_accuracy'], label='验证准确率')
ax2.set_title('模型准确率')
ax2.set_xlabel('轮数')
ax2.set_ylabel('准确率')
ax2.legend()
ax2.grid(True)
plt.tight_layout()
plt.show()
def save_model(self, filepath):
"""
保存模型
:param filepath: 保存路径
"""
if self.model is None:
print("❌ 模型未构建")
return
try:
self.model.save(filepath)
print(f"✅ 模型已保存到 {filepath}")
except Exception as e:
print(f"❌ 保存模型时发生错误: {e}")
def load_model(self, filepath):
"""
加载模型
:param filepath: 模型路径
"""
try:
self.model = tf.keras.models.load_model(filepath)
print(f"✅ 模型已从 {filepath} 加载")
except Exception as e:
print(f"❌ 加载模型时发生错误: {e}")
# 使用示例
if __name__ == "__main__":
# 创建示例数据
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=2000, n_features=20, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化数据
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建深度学习模型
dl_model = DeepLearningModel(input_dim=X_train.shape[1], num_classes=2)
# 构建模型
dl_model.build_model(architecture='default')
# 训练模型
dl_model.train(X_train, y_train, X_test, y_test, epochs=50, batch_size=32)
# 评估模型
accuracy, predictions = dl_model.evaluate(X_test, y_test)
# 绘制训练历史
dl_model.plot_training_history()
第三章:系统架构设计
3.1 架构图
使用Mermaid绘制系统架构图,展示AI应用的组件关系。
3.2 关键业务流程
使用流程图展示AI应用的关键业务流程。
第四章:部署与优化
4.1 模型部署
将训练好的模型部署到生产环境中,可以使用Flask框架搭建API接口。
实践示例:
from flask import Flask, request, jsonify
import numpy as np
import tensorflow as tf
import joblib
import traceback
import logging
from functools import wraps
import time
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class AIModelAPI:
"""
AI模型API服务类
"""
def __init__(self, model_path=None, scaler_path=None):
"""
初始化API服务
:param model_path: 模型文件路径
:param scaler_path: 标准化器文件路径
"""
self.app = Flask(__name__)
self.model = None
self.scaler = None
self.setup_routes()
# 加载模型和预处理器
if model_path:
self.load_model(model_path)
if scaler_path:
self.load_scaler(scaler_path)
def load_model(self, model_path):
"""
加载模型
:param model_path: 模型路径
"""
try:
self.model = tf.keras.models.load_model(model_path)
logger.info(f"✅ 模型加载成功: {model_path}")
except Exception as e:
logger.error(f"❌ 模型加载失败: {e}")
self.model = None
def load_scaler(self, scaler_path):
"""
加载标准化器
:param scaler_path: 标准化器路径
"""
try:
self.scaler = joblib.load(scaler_path)
logger.info(f"✅ 标准化器加载成功: {scaler_path}")
except Exception as e:
logger.error(f"❌ 标准化器加载失败: {e}")
self.scaler = None
def setup_routes(self):
"""
设置API路由
"""
# 健康检查端点
self.app.add_url_rule('/health', 'health', self.health_check, methods=['GET'])
# 预测端点
self.app.add_url_rule('/predict', 'predict', self.predict, methods=['POST'])
# 模型信息端点
self.app.add_url_rule('/model/info', 'model_info', self.model_info, methods=['GET'])
def health_check(self):
"""
健康检查端点
"""
return jsonify({
'status': 'healthy',
'timestamp': time.time(),
'model_loaded': self.model is not None
})
def model_info(self):
"""
获取模型信息
"""
if self.model is None:
return jsonify({'error': '模型未加载'}), 400
return jsonify({
'model_type': 'Neural Network',
'input_shape': self.model.input_shape,
'output_shape': self.model.output_shape,
'num_layers': len(self.model.layers),
'loaded': True
})
def preprocess_data(self, data):
"""
预处理输入数据
:param data: 原始数据
:return: 预处理后的数据
"""
try:
# 转换为numpy数组
if isinstance(data, list):
features = np.array(data)
else:
features = np.array([data])
# 确保数据形状正确
if len(features.shape) == 1:
features = features.reshape(1, -1)
# 应用标准化(如果可用)
if self.scaler is not None:
features = self.scaler.transform(features)
logger.info("✅ 数据标准化完成")
else:
logger.warning("⚠️ 未加载标准化器,使用原始数据")
return features
except Exception as e:
logger.error(f"❌ 数据预处理失败: {e}")
raise
def predict(self):
"""
预测端点
"""
try:
# 记录请求开始时间
start_time = time.time()
# 检查模型是否已加载
if self.model is None:
return jsonify({'error': '模型未加载'}), 500
# 获取请求数据
request_data = request.get_json()
if not request_data:
return jsonify({'error': '无效的请求数据'}), 400
# 检查必需字段
if 'features' not in request_data:
return jsonify({'error': '缺少features字段'}), 400
features = request_data['features']
logger.info(f"收到预测请求,特征数量: {len(features) if isinstance(features, list) else 1}")
# 预处理数据
processed_features = self.preprocess_data(features)
# 执行预测
predictions = self.model.predict(processed_features)
# 处理预测结果
if predictions.shape[1] == 1:
# 二分类
probabilities = predictions.flatten()
predicted_classes = (probabilities > 0.5).astype(int)
else:
# 多分类
probabilities = predictions[0]
predicted_classes = np.argmax(probabilities)
# 计算处理时间
processing_time = time.time() - start_time
# 返回结果
return jsonify({
'predictions': predicted_classes.tolist(),
'probabilities': probabilities.tolist(),
'processing_time': processing_time,
'timestamp': time.time()
})
except Exception as e:
logger.error(f"预测过程中发生错误: {e}")
logger.error(traceback.format_exc())
return jsonify({'error': str(e)}), 500
def run(self, host='0.0.0.0', port=5000, debug=False):
"""
启动API服务
:param host: 主机地址
:param port: 端口号
:param debug: 调试模式
"""
logger.info(f"启动AI模型API服务: http://{host}:{port}")
self.app.run(host=host, port=port, debug=debug)
# 创建示例模型(用于演示)
def create_sample_model():
"""
创建示例模型用于演示
"""
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(10,)),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 创建示例数据并训练
X_sample = np.random.random((100, 10))
y_sample = np.random.randint(0, 2, (100,))
model.fit(X_sample, y_sample, epochs=1, verbose=0)
# 保存模型
model.save('sample_model.h5')
print("✅ 示例模型已保存为 sample_model.h5")
# 使用示例
if __name__ == '__main__':
# 创建示例模型(首次运行时取消注释)
# create_sample_model()
# 创建API服务
api = AIModelAPI(model_path='sample_model.h5')
# 启动服务
# api.run(debug=True)
4.2 性能优化
优化模型性能,可以使用TensorFlow的优化器和量化工具。
实践示例:
import tensorflow as tf
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import time
class ModelOptimizer:
"""
模型优化器类
"""
def __init__(self, model):
"""
初始化优化器
:param model: TensorFlow模型
"""
self.model = model
self.optimized_model = None
self.tflite_model = None
def quantize_model(self, X_sample):
"""
量化模型以减小体积并提高推理速度
:param X_sample: 样本数据用于校准
"""
print("正在量化模型...")
try:
# 转换为TensorFlow Lite模型
converter = tf.lite.TFLiteConverter.from_keras_model(self.model)
# 启用优化
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 如果提供了样本数据,进行全整数量化
if X_sample is not None:
def representative_dataset():
for i in range(100):
yield [X_sample[i:i+1].astype(np.float32)]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
# 执行转换
self.tflite_model = converter.convert()
print("✅ 模型量化完成")
print(f"原始模型大小: {len(self.model.get_weights()[0].tobytes()) / 1024:.2f} KB")
print(f"量化模型大小: {len(self.tflite_model) / 1024:.2f} KB")
print(f"压缩率: {(1 - len(self.tflite_model) / len(self.model.get_weights()[0].tobytes())) * 100:.2f}%")
except Exception as e:
print(f"❌ 模型量化失败: {e}")
def save_quantized_model(self, filepath):
"""
保存量化模型
:param filepath: 保存路径
"""
if self.tflite_model is None:
print("❌ 未量化模型")
return
try:
with open(filepath, 'wb') as f:
f.write(self.tflite_model)
print(f"✅ 量化模型已保存到 {filepath}")
except Exception as e:
print(f"❌ 保存量化模型时发生错误: {e}")
def benchmark_models(self, X_test, y_test, num_runs=100):
"""
基准测试原始模型和优化模型
:param X_test: 测试数据
:param y_test: 测试标签
:param num_runs: 运行次数
"""
print("\n正在进行基准测试...")
# 测试原始模型
start_time = time.time()
for _ in range(num_runs):
_ = self.model.predict(X_test[:1])
original_time = (time.time() - start_time) / num_runs
print(f"原始模型平均推理时间: {original_time*1000:.2f} ms")
# 测试量化模型(如果存在)
if self.tflite_model is not None:
try:
# 加载TFLite模型
interpreter = tf.lite.Interpreter(model_content=self.tflite_model)
interpreter.allocate_tensors()
# 获取输入和输出张量
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# 测试推理时间
start_time = time.time()
for _ in range(num_runs):
interpreter.set_tensor(input_details[0]['index'], X_test[:1].astype(np.float32))
interpreter.invoke()
_ = interpreter.get_tensor(output_details[0]['index'])
quantized_time = (time.time() - start_time) / num_runs
print(f"量化模型平均推理时间: {quantized_time*1000:.2f} ms")
print(f"性能提升: {((original_time - quantized_time) / original_time) * 100:.2f}%")
except Exception as e:
print(f"❌ 量化模型基准测试失败: {e}")
# 准确率比较
original_accuracy = self.model.evaluate(X_test, y_test, verbose=0)[1]
print(f"原始模型准确率: {original_accuracy:.4f}")
if self.tflite_model is not None:
try:
# 量化模型准确率测试
interpreter = tf.lite.Interpreter(model_content=self.tflite_model)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
predictions = []
for i in range(len(X_test)):
interpreter.set_tensor(input_details[0]['index'], X_test[i:i+1].astype(np.float32))
interpreter.invoke()
pred = interpreter.get_tensor(output_details[0]['index'])
predictions.append(pred[0][0])
quantized_predictions = (np.array(predictions) > 0.5).astype(int)
quantized_accuracy = np.mean(quantized_predictions == y_test)
print(f"量化模型准确率: {quantized_accuracy:.4f}")
print(f"准确率差异: {abs(original_accuracy - quantized_accuracy):.4f}")
except Exception as e:
print(f"❌ 量化模型准确率测试失败: {e}")
# 使用示例
if __name__ == "__main__":
# 创建示例数据
X, y = make_classification(n_samples=2000, n_features=10, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化数据
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建和训练模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(10,)),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2, verbose=0)
# 创建优化器
optimizer = ModelOptimizer(model)
# 量化模型
optimizer.quantize_model(X_train[:100])
# 基准测试
optimizer.benchmark_models(X_test, y_test)
# 保存量化模型
optimizer.save_quantized_model('optimized_model.tflite')
第五章:实践案例与常见问题
5.1 实践案例
结合实际应用场景,展示一个完整的AI应用开发案例。
案例:
假设我们需要开发一个图像分类应用,用于识别手写数字。以下是完整的开发流程:
- 数据准备:使用MNIST数据集。
- 模型训练:使用卷积神经网络(CNN)。
- 模型部署:将模型部署到Web应用中。
代码示例:
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import classification_report, confusion_matrix
import warnings
warnings.filterwarnings('ignore')
class MNISTClassifier:
"""
MNIST手写数字分类器
"""
def __init__(self):
self.model = None
self.history = None
self.class_names = [str(i) for i in range(10)]
def load_and_preprocess_data(self):
"""
加载并预处理MNIST数据
"""
print("正在加载MNIST数据集...")
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")
print(f"标签范围: {np.min(y_train)} - {np.max(y_train)}")
# 数据预处理
# 1. 归一化像素值到0-1范围
X_train = X_train.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0
# 2. 重塑数据以添加通道维度
X_train = X_train.reshape(-1, 28, 28, 1)
X_test = X_test.reshape(-1, 28, 28, 1)
# 3. 对标签进行one-hot编码
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
print("✅ 数据预处理完成")
return (X_train, y_train), (X_test, y_test)
def build_cnn_model(self):
"""
构建CNN模型
"""
print("正在构建CNN模型...")
self.model = models.Sequential([
# 第一个卷积块
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.BatchNormalization(),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Dropout(0.25),
# 第二个卷积块
layers.Conv2D(64, (3, 3), activation='relu'),
layers.BatchNormalization(),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Dropout(0.25),
# 全连接层
layers.Flatten(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(0.5),
layers.Dense(10, activation='softmax')
])
# 编译模型
self.model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
print("✅ CNN模型构建完成")
print("\n模型架构:")
self.model.summary()
def train_model(self, X_train, y_train, X_test, y_test, epochs=10, batch_size=128):
"""
训练模型
:param X_train: 训练特征
:param y_train: 训练标签
:param X_test: 测试特征
:param y_test: 测试标签
:param epochs: 训练轮数
:param batch_size: 批次大小
"""
if self.model is None:
print("❌ 模型未构建")
return
print("\n开始训练模型...")
# 定义回调函数
callbacks = [
tf.keras.callbacks.EarlyStopping(
monitor='val_accuracy',
patience=3,
restore_best_weights=True
),
tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.2,
patience=2,
min_lr=0.0001
)
]
# 训练模型
self.history = self.model.fit(
X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
callbacks=callbacks,
verbose=1
)
print("✅ 模型训练完成")
def evaluate_model(self, X_test, y_test):
"""
评估模型
:param X_test: 测试特征
:param y_test: 测试标签(one-hot编码)
"""
if self.model is None:
print("❌ 模型未构建")
return
print("\n正在评估模型...")
# 评估模型
test_loss, test_accuracy = self.model.evaluate(X_test, y_test, verbose=0)
print(f"测试损失: {test_loss:.4f}")
print(f"测试准确率: {test_accuracy:.4f}")
# 预测
y_pred_prob = self.model.predict(X_test)
y_pred = np.argmax(y_pred_prob, axis=1)
y_true = np.argmax(y_test, axis=1)
# 分类报告
print("\n分类报告:")
print(classification_report(y_true, y_pred, target_names=self.class_names))
return test_accuracy, y_pred, y_true
def plot_training_history(self):
"""
绘制训练历史
"""
if self.history is None:
print("❌ 没有训练历史可绘制")
return
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 准确率曲线
ax1.plot(self.history.history['accuracy'], label='训练准确率')
ax1.plot(self.history.history['val_accuracy'], label='验证准确率')
ax1.set_title('模型准确率')
ax1.set_xlabel('轮数')
ax1.set_ylabel('准确率')
ax1.legend()
ax1.grid(True)
# 损失曲线
ax2.plot(self.history.history['loss'], label='训练损失')
ax2.plot(self.history.history['val_loss'], label='验证损失')
ax2.set_title('模型损失')
ax2.set_xlabel('轮数')
ax2.set_ylabel('损失')
ax2.legend()
ax2.grid(True)
plt.tight_layout()
plt.show()
def plot_confusion_matrix(self, y_true, y_pred):
"""
绘制混淆矩阵
:param y_true: 真实标签
:param y_pred: 预测标签
"""
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=self.class_names, yticklabels=self.class_names)
plt.title('混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.show()
def visualize_predictions(self, X_test, y_true, y_pred, num_samples=10):
"""
可视化预测结果
:param X_test: 测试数据
:param y_true: 真实标签
:param y_pred: 预测标签
:param num_samples: 样本数量
"""
# 随机选择样本
indices = np.random.choice(len(X_test), num_samples, replace=False)
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
axes = axes.ravel()
for i, idx in enumerate(indices):
# 显示图像
axes[i].imshow(X_test[idx].reshape(28, 28), cmap='gray')
axes[i].set_title(f'真实: {y_true[idx]}, 预测: {y_pred[idx]}')
axes[i].axis('off')
# 如果预测错误,用红色标题
if y_true[idx] != y_pred[idx]:
axes[i].set_title(f'真实: {y_true[idx]}, 预测: {y_pred[idx]}', color='red')
plt.tight_layout()
plt.show()
def save_model(self, filepath):
"""
保存模型
:param filepath: 保存路径
"""
if self.model is None:
print("❌ 模型未构建")
return
try:
self.model.save(filepath)
print(f"✅ 模型已保存到 {filepath}")
except Exception as e:
print(f"❌ 保存模型时发生错误: {e}")
# 完整的MNIST分类流程
def main():
"""
主函数:执行完整的MNIST分类流程
"""
# 创建分类器
classifier = MNISTClassifier()
# 加载和预处理数据
(X_train, y_train), (X_test, y_test) = classifier.load_and_preprocess_data()
# 构建模型
classifier.build_cnn_model()
# 训练模型
classifier.train_model(X_train, y_train, X_test, y_test, epochs=15, batch_size=128)
# 评估模型
accuracy, y_pred, y_true = classifier.evaluate_model(X_test, y_test)
# 绘制训练历史
classifier.plot_training_history()
# 绘制混淆矩阵
classifier.plot_confusion_matrix(y_true, y_pred)
# 可视化预测结果
classifier.visualize_predictions(X_test, y_true, y_pred)
# 保存模型
classifier.save_model('mnist_cnn_model.h5')
print(f"\n🎉 MNIST分类器训练完成!")
print(f" 最终测试准确率: {accuracy:.4f}")
print(f" 模型已保存为: mnist_cnn_model.h5")
# 运行示例
if __name__ == "__main__":
main()
5.2 常见问题
解答开发者在AI应用开发过程中常见的问题。
Q1: 如何选择合适的模型?
- 根据问题类型和数据特点选择模型。对于简单的线性问题,可以使用线性模型;对于复杂的非线性问题,可以使用深度学习模型。
Q2: 如何优化模型性能?
- 使用正则化、早停、数据增强等技术优化模型性能。同时,可以使用TensorFlow Lite等工具进行模型量化。
Q3: 如何处理过拟合问题?
- 使用Dropout、L1/L2正则化、数据增强、早停等技术防止过拟合。
Q4: 如何提高模型推理速度?
- 使用模型量化、剪枝、知识蒸馏等技术优化模型。
第六章:最佳实践与扩展阅读
6.1 最佳实践
提供AI应用开发的最佳实践建议。
建议:
- 数据质量:确保数据的准确性和完整性。
- 模型选择:根据问题类型选择合适的模型。
- 代码风格:遵循PEP8规范,编写清晰、可读性强的代码。
- 错误处理:在代码中添加错误处理机制,确保系统的健壮性。
- 版本控制:使用Git管理代码和模型版本。
- 文档编写:为代码和模型编写清晰的文档。
import logging
import os
from datetime import datetime
class AIDevelopmentBestPractices:
"""
AI开发最佳实践示例
"""
def __init__(self):
# 配置日志
self.setup_logging()
def setup_logging(self):
"""
设置日志配置
"""
# 创建logs目录
if not os.path.exists('logs'):
os.makedirs('logs')
# 配置日志格式
log_format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
logging.basicConfig(
level=logging.INFO,
format=log_format,
handlers=[
logging.FileHandler(f'logs/ai_app_{datetime.now().strftime("%Y%m%d")}.log'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
self.logger.info("日志系统初始化完成")
def data_validation(self, data):
"""
数据验证最佳实践
:param data: 输入数据
:return: 验证结果
"""
self.logger.info("开始数据验证")
try:
# 检查数据类型
if not isinstance(data, (list, np.ndarray)):
raise TypeError("数据必须是列表或numpy数组")
# 转换为numpy数组
data_array = np.array(data)
# 检查维度
if len(data_array.shape) not in [1, 2]:
raise ValueError("数据必须是一维或二维数组")
# 检查数值范围
if np.isnan(data_array).any():
raise ValueError("数据包含NaN值")
if np.isinf(data_array).any():
raise ValueError("数据包含无穷大值")
self.logger.info(f"数据验证通过,形状: {data_array.shape}")
return True, data_array
except Exception as e:
self.logger.error(f"数据验证失败: {e}")
return False, None
def model_versioning(self, model, version):
"""
模型版本控制最佳实践
:param model: 模型对象
:param version: 版本号
"""
try:
# 创建模型目录
model_dir = f"models/v{version}"
if not os.path.exists(model_dir):
os.makedirs(model_dir)
# 保存模型
model_path = f"{model_dir}/model.h5"
model.save(model_path)
# 保存模型元数据
metadata = {
'version': version,
'created_at': datetime.now().isoformat(),
'model_type': str(type(model)),
'input_shape': getattr(model, 'input_shape', 'Unknown')
}
import json
with open(f"{model_dir}/metadata.json", 'w') as f:
json.dump(metadata, f, indent=2)
self.logger.info(f"模型版本 {version} 已保存到 {model_dir}")
except Exception as e:
self.logger.error(f"模型版本控制失败: {e}")
def error_handling_example(self):
"""
错误处理最佳实践示例
"""
try:
# 模拟可能出错的操作
result = 10 / 0
except ZeroDivisionError as e:
self.logger.error(f"除零错误: {e}")
return None
except Exception as e:
self.logger.error(f"未预期的错误: {e}")
return None
else:
self.logger.info("操作成功完成")
return result
finally:
self.logger.info("错误处理示例完成")
# 使用示例
if __name__ == "__main__":
# 创建最佳实践示例
practices = AIDevelopmentBestPractices()
# 数据验证示例
valid_data = [1, 2, 3, 4, 5]
is_valid, processed_data = practices.data_validation(valid_data)
# 错误处理示例
practices.error_handling_example()
6.2 扩展阅读
提供深入学习资源,帮助开发者进一步提升技术水平。
推荐资源:
总结
本文详细介绍了AI应用开发的全流程,从环境搭建到模型部署与优化。通过实践案例和代码示例,读者可以快速掌握AI应用开发的关键技术和最佳实践。希望本文能帮助开发者提升技术水平,顺利开展AI应用开发工作。
关键要点总结:
- 环境搭建:选择合适的Python版本和AI库,使用虚拟环境管理依赖
- 数据预处理:清洗数据、处理缺失值、标准化特征、分割数据集
- 模型选择与训练:根据问题类型选择合适的模型,使用交叉验证评估性能
- 深度学习应用:构建CNN等神经网络模型,使用回调函数优化训练过程
- 系统架构设计:设计清晰的系统架构,考虑可扩展性和可维护性
- 模型部署:使用Flask等框架构建API服务,实现模型的在线预测
- 性能优化:量化模型、基准测试、监控性能指标
- 最佳实践:遵循代码规范、添加日志记录、实现错误处理
AI应用开发是一个持续迭代的过程,需要不断地实验、优化和改进。希望本文提供的知识和实践示例能够帮助读者在AI开发的道路上走得更远。
参考资料
图表展示
系统架构图
关键业务流程
知识体系思维导图
mindmap
root((AI应用开发))
环境搭建
数据处理
模型训练
模型部署
性能优化
最佳实践
环境搭建 --> Python安装
环境搭建 --> 虚拟环境
环境搭建 --> 依赖管理
数据处理 --> 数据清洗
数据处理 --> 特征工程
数据处理 --> 数据分割
模型训练 --> 传统机器学习
模型训练 --> 深度学习
模型训练 --> 模型评估
模型部署 --> API开发
模型部署 --> 容器化
模型部署 --> 云部署
性能优化 --> 模型量化
性能优化 --> 推理加速
性能优化 --> 资源监控
最佳实践 --> 代码规范
最佳实践 --> 错误处理
最佳实践 --> 版本控制
项目实施计划
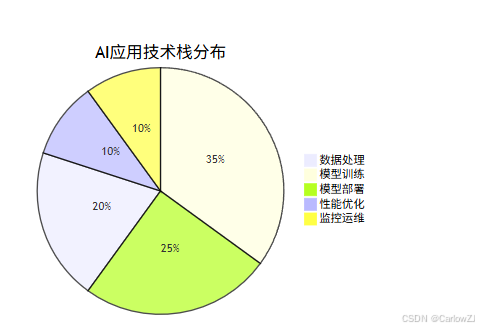
技术栈分布





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











