



摘要
本文详细介绍了如何使用 LightRAG(Lightweight Retrieval-Augmented Generation)系统进行中文文档处理和知识图谱构建。通过实际案例,展示了从文档上传、处理到知识图谱生成的完整流程。文章分为多个章节,每个章节都配有实践示例和代码,帮助读者更好地理解和应用。最后,文章总结了关键点,并提供了实践建议和常见问题的解答。通过本文的学习,读者将能够掌握使用 LightRAG 处理中文文档并构建知识图谱的核心技术。
目录
引言
随着人工智能技术的快速发展,自然语言处理(NLP)在文档处理和知识图谱构建中的应用越来越广泛。特别是在中文处理领域,由于中文语言的复杂性和特殊性,对文档处理和知识提取提出了更高的要求。
LightRAG 是一个轻量级的检索增强生成系统,能够高效地处理文档并构建知识图谱。与传统的 RAG 系统相比,LightRAG 具有更低的资源消耗和更快的处理速度,特别适合处理大量中文文档的场景。
本文将通过实际案例,详细讲解如何使用 LightRAG 进行中文文档处理和知识图谱构建,帮助开发者快速掌握相关技术并应用到实际项目中。
LightRAG 简介
LightRAG(Lightweight Retrieval-Augmented Generation)是一个轻量级的检索增强生成系统,它结合了信息检索和文本生成的优势,能够有效地处理大规模文档并从中提取有价值的信息。
主要特点
- 轻量级设计:相比传统 RAG 系统,LightRAG 具有更小的资源占用和更快的处理速度
- 高效检索:采用先进的检索算法,能够快速定位相关文档片段
- 智能生成:基于检索结果生成高质量的文本内容
- 知识图谱支持:能够从文档中提取实体和关系,构建知识图谱
- 多语言支持:支持包括中文在内的多种语言处理
应用场景
- 智能问答系统:基于文档内容回答用户问题
- 知识管理:从大量文档中提取和组织知识
- 内容摘要:自动生成文档摘要
- 信息抽取:从非结构化文本中提取结构化信息
- 知识图谱构建:从文档中提取实体和关系,构建知识图谱
系统架构
架构图
架构组件说明
- 用户界面:提供文档上传、查询和可视化功能
- API网关:统一入口,处理请求路由、认证、限流等
- 文档处理服务:负责文档的接收、预处理和管理
- LightRAG引擎:核心处理引擎,负责文档分析、信息提取和生成
- 知识图谱存储:存储提取的实体、关系和知识图谱结构
- 向量数据库:存储文档和实体的向量表示,支持相似性检索
- 文档存储:存储原始文档和处理后的结构化数据
- 监控系统:监控系统性能和健康状态
- 日志系统:记录系统运行日志,便于问题排查
文档处理流程
流程图
流程步骤说明
- 文档上传:用户通过界面或 API 上传文档
- 格式验证:检查文档格式是否支持(PDF、DOCX、TXT 等)
- 文档解析:将不同格式的文档解析为纯文本
- 文本预处理:清理文本、分段、处理编码等
- 文档分块:将长文档分割为适当大小的文本块
- 向量化处理:将文本转换为向量表示,便于检索
- 实体识别:识别文本中的命名实体(人名、地名、机构等)
- 关系抽取:识别实体之间的关系
- 知识融合:将新提取的知识与现有知识图谱融合
- 知识图谱更新:更新知识图谱结构和内容
- 存储到数据库:将处理结果存储到相应的数据库中
实践示例:文档处理模块
以下是一个完整的 Python 示例代码,展示如何使用 LightRAG 进行文档处理:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
LightRAG 文档处理模块
展示如何使用 LightRAG 进行中文文档处理
"""
import os
import logging
import hashlib
from typing import List, Dict, Optional, Tuple
from dataclasses import dataclass
from enum import Enum
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class DocumentStatus(Enum):
"""文档状态枚举"""
UPLOADED = "uploaded" # 已上传
PROCESSING = "processing" # 处理中
PROCESSED = "processed" # 已处理
ERROR = "error" # 处理错误
@dataclass
class DocumentInfo:
"""文档信息"""
doc_id: str
filename: str
file_path: str
status: DocumentStatus
size: int
upload_time: float
process_start_time: Optional[float] = None
process_end_time: Optional[float] = None
error_message: Optional[str] = None
class DocumentProcessor:
"""文档处理器"""
def __init__(self, upload_dir: str = "uploads", processed_dir: str = "processed"):
"""
初始化文档处理器
Args:
upload_dir (str): 上传目录
processed_dir (str): 处理后目录
"""
self.upload_dir = upload_dir
self.processed_dir = processed_dir
# 创建目录
os.makedirs(self.upload_dir, exist_ok=True)
os.makedirs(self.processed_dir, exist_ok=True)
# 文档信息存储(实际应用中应使用数据库)
self.documents: Dict[str, DocumentInfo] = {}
def upload_document(self, filename: str, file_content: bytes) -> str:
"""
上传文档
Args:
filename (str): 文件名
file_content (bytes): 文件内容
Returns:
str: 文档ID
"""
try:
# 生成文档ID
doc_id = hashlib.md5(file_content).hexdigest()[:16]
# 保存文件
file_path = os.path.join(self.upload_dir, f"{doc_id}_{filename}")
with open(file_path, 'wb') as f:
f.write(file_content)
# 创建文档信息
doc_info = DocumentInfo(
doc_id=doc_id,
filename=filename,
file_path=file_path,
status=DocumentStatus.UPLOADED,
size=len(file_content),
upload_time=os.time() if hasattr(os, 'time') else 0
)
# 保存文档信息
self.documents[doc_id] = doc_info
logger.info(f"文档上传成功: {filename} (ID: {doc_id})")
return doc_id
except Exception as e:
logger.error(f"文档上传失败: {str(e)}")
raise
def validate_document_format(self, doc_id: str) -> bool:
"""
验证文档格式
Args:
doc_id (str): 文档ID
Returns:
bool: 格式是否有效
"""
if doc_id not in self.documents:
logger.error(f"文档不存在: {doc_id}")
return False
doc_info = self.documents[doc_id]
filename = doc_info.filename.lower()
# 支持的文件格式
supported_formats = ['.pdf', '.docx', '.txt', '.md']
is_supported = any(filename.endswith(fmt) for fmt in supported_formats)
if not is_supported:
logger.warning(f"不支持的文件格式: {filename}")
return False
# 检查文件大小(限制为 100MB)
if doc_info.size > 100 * 1024 * 1024:
logger.warning(f"文件过大: {filename} ({doc_info.size} bytes)")
return False
logger.info(f"文档格式验证通过: {filename}")
return True
def parse_document(self, doc_id: str) -> Optional[str]:
"""
解析文档为纯文本
Args:
doc_id (str): 文档ID
Returns:
Optional[str]: 解析后的文本内容
"""
if doc_id not in self.documents:
logger.error(f"文档不存在: {doc_id}")
return None
doc_info = self.documents[doc_id]
try:
# 更新状态
doc_info.status = DocumentStatus.PROCESSING
doc_info.process_start_time = os.time() if hasattr(os, 'time') else 0
filename = doc_info.filename.lower()
file_path = doc_info.file_path
# 根据文件格式解析文档
if filename.endswith('.pdf'):
text = self._parse_pdf(file_path)
elif filename.endswith('.docx'):
text = self._parse_docx(file_path)
elif filename.endswith('.txt') or filename.endswith('.md'):
text = self._parse_text(file_path)
else:
logger.error(f"不支持的文件格式: {filename}")
doc_info.status = DocumentStatus.ERROR
doc_info.error_message = f"不支持的文件格式: {filename}"
return None
# 更新状态
doc_info.process_end_time = os.time() if hasattr(os, 'time') else 0
doc_info.status = DocumentStatus.PROCESSED
logger.info(f"文档解析完成: {filename}")
return text
except Exception as e:
logger.error(f"文档解析失败: {str(e)}")
doc_info.status = DocumentStatus.ERROR
doc_info.error_message = str(e)
doc_info.process_end_time = os.time() if hasattr(os, 'time') else 0
return None
def _parse_pdf(self, file_path: str) -> str:
"""
解析 PDF 文档
Args:
file_path (str): 文件路径
Returns:
str: 解析后的文本内容
"""
try:
# 尝试导入 PyPDF2
from PyPDF2 import PdfReader
# 打开 PDF 文件
with open(file_path, 'rb') as file:
reader = PdfReader(file)
# 提取文本内容
text = ''.join(page.extract_text() for page in reader.pages)
logger.info(f"PDF文档解析完成: {file_path}")
return text
except ImportError:
logger.warning("PyPDF2未安装,使用简单读取方式")
# 简单读取(适用于文本型PDF)
with open(file_path, 'rb') as file:
content = file.read()
# 尝试解码
try:
return content.decode('utf-8')
except UnicodeDecodeError:
return content.decode('gbk')
except Exception as e:
logger.error(f"PDF解析失败: {str(e)}")
raise
def _parse_docx(self, file_path: str) -> str:
"""
解析 DOCX 文档
Args:
file_path (str): 文件路径
Returns:
str: 解析后的文本内容
"""
try:
# 尝试导入 python-docx
from docx import Document
# 打开 DOCX 文件
doc = Document(file_path)
# 提取文本内容
text = '\n'.join(paragraph.text for paragraph in doc.paragraphs)
logger.info(f"DOCX文档解析完成: {file_path}")
return text
except ImportError:
logger.warning("python-docx未安装,无法解析DOCX文件")
raise Exception("缺少python-docx库,无法解析DOCX文件")
except Exception as e:
logger.error(f"DOCX解析失败: {str(e)}")
raise
def _parse_text(self, file_path: str) -> str:
"""
解析文本文件
Args:
file_path (str): 文件路径
Returns:
str: 解析后的文本内容
"""
try:
# 读取文本文件
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
logger.info(f"文本文件解析完成: {file_path}")
return text
except UnicodeDecodeError:
# 尝试其他编码
try:
with open(file_path, 'r', encoding='gbk') as file:
text = file.read()
logger.info(f"GBK编码文本文件解析完成: {file_path}")
return text
except Exception as e:
logger.error(f"文本文件解析失败: {str(e)}")
raise
except Exception as e:
logger.error(f"文本文件解析失败: {str(e)}")
raise
def preprocess_text(self, text: str) -> str:
"""
预处理文本
Args:
text (str): 原始文本
Returns:
str: 预处理后的文本
"""
import re
# 移除多余的空白字符
text = re.sub(r'\s+', ' ', text)
# 移除特殊字符(保留中文、英文、数字和常见标点)
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s\.,;:!?()""''\-]', '', text)
# 移除行首行尾空白
text = text.strip()
logger.info("文本预处理完成")
return text
def chunk_document(self, text: str, chunk_size: int = 500, overlap: int = 50) -> List[str]:
"""
将文档分块
Args:
text (str): 文档文本
chunk_size (int): 块大小
overlap (int): 重叠大小
Returns:
List[str]: 文本块列表
"""
chunks = []
start = 0
while start < len(text):
end = min(start + chunk_size, len(text))
chunk = text[start:end]
chunks.append(chunk)
# 如果到达文本末尾,跳出循环
if end >= len(text):
break
# 移动起始位置(考虑重叠)
start = end - overlap
logger.info(f"文档分块完成,共 {len(chunks)} 块")
return chunks
def get_document_info(self, doc_id: str) -> Optional[DocumentInfo]:
"""
获取文档信息
Args:
doc_id (str): 文档ID
Returns:
Optional[DocumentInfo]: 文档信息
"""
return self.documents.get(doc_id)
def list_documents(self) -> Dict[str, DocumentInfo]:
"""
列出所有文档
Returns:
Dict[str, DocumentInfo]: 文档信息字典
"""
return self.documents.copy()
# 使用示例
def main():
"""主函数"""
# 创建文档处理器
processor = DocumentProcessor()
# 模拟上传文档
sample_text = """
人工智能(Artificial Intelligence,AI)是计算机科学的一个分支,它企图了解智能的实质,
并生产出一种新的能以人类智能相似的方式做出反应的智能机器。该领域的研究包括机器人、
语言识别、图像识别、自然语言处理和专家系统等。
机器学习是人工智能的一个重要分支,它使计算机能够从数据中学习并做出预测或决策,
而无需明确编程来执行特定任务。深度学习是机器学习的一个子集,它模仿人脑的工作方式
来处理数据和创建模式,用于决策制定。
自然语言处理(NLP)是人工智能的一个分支,它帮助计算机理解和解释人类语言,
并以一种有价值和适当的方式回应人类。NLP结合了计算语言学、计算机科学和人工智能,
使人类能够以自然的方式与计算机交互。
""".strip()
# 创建测试文件
test_file_content = sample_text.encode('utf-8')
# 上传文档
doc_id = processor.upload_document("ai_introduction.txt", test_file_content)
# 验证文档格式
if processor.validate_document_format(doc_id):
# 解析文档
text = processor.parse_document(doc_id)
if text:
# 预处理文本
processed_text = processor.preprocess_text(text)
# 分块文档
chunks = processor.chunk_document(processed_text, chunk_size=100, overlap=20)
# 输出结果
logger.info(f"原始文本长度: {len(text)}")
logger.info(f"处理后文本长度: {len(processed_text)}")
logger.info(f"文本块数量: {len(chunks)}")
# 显示前两个文本块
for i, chunk in enumerate(chunks[:2]):
logger.info(f"文本块 {i+1}: {chunk[:50]}...")
if __name__ == "__main__":
main()
知识图谱构建
知识图谱构建是 LightRAG 系统的核心功能之一,它能够从文档中提取实体和关系,构建结构化的知识表示。
知识图谱构建流程
- 实体识别:识别文本中的命名实体(人名、地名、机构、概念等)
- 关系抽取:识别实体之间的语义关系
- 属性抽取:提取实体的属性信息
- 知识融合:将新知识与现有知识图谱融合
- 图谱存储:将知识图谱存储到图数据库中
实践示例:知识图谱构建模块
以下是一个知识图谱构建的示例实现:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
LightRAG 知识图谱构建模块
展示如何从文本中提取实体和关系,构建知识图谱
"""
import logging
import json
from typing import List, Dict, Tuple, Set
from dataclasses import dataclass, asdict
from enum import Enum
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class EntityType(Enum):
"""实体类型枚举"""
PERSON = "person" # 人物
ORGANIZATION = "organization" # 组织机构
LOCATION = "location" # 地点
CONCEPT = "concept" # 概念
TECHNOLOGY = "technology" # 技术
OTHER = "other" # 其他
class RelationType(Enum):
"""关系类型枚举"""
WORKS_FOR = "works_for" # 任职于
LOCATED_IN = "located_in" # 位于
RELATED_TO = "related_to" # 相关于
PART_OF = "part_of" # 属于
INVENTED = "invented" # 发明了
USES = "uses" # 使用
@dataclass
class Entity:
"""实体"""
id: str
name: str
type: EntityType
description: str = ""
@dataclass
class Relation:
"""关系"""
id: str
source_entity_id: str
target_entity_id: str
type: RelationType
description: str = ""
@dataclass
class KnowledgeGraph:
"""知识图谱"""
entities: Dict[str, Entity]
relations: Dict[str, Relation]
class KnowledgeGraphBuilder:
"""知识图谱构建器"""
def __init__(self):
"""初始化知识图谱构建器"""
self.kg = KnowledgeGraph(entities={}, relations={})
# 预定义的实体和关系模式(实际应用中可以使用NLP模型)
self.entity_patterns = {
"人工智能": EntityType.TECHNOLOGY,
"机器学习": EntityType.TECHNOLOGY,
"深度学习": EntityType.TECHNOLOGY,
"自然语言处理": EntityType.TECHNOLOGY,
"计算机科学": EntityType.CONCEPT,
"机器人": EntityType.TECHNOLOGY,
"语言识别": EntityType.TECHNOLOGY,
"图像识别": EntityType.TECHNOLOGY,
"专家系统": EntityType.TECHNOLOGY
}
self.relation_patterns = [
("机器学习", "相关于", "人工智能"),
("深度学习", "相关于", "机器学习"),
("自然语言处理", "相关于", "人工智能"),
("机器人", "相关于", "人工智能"),
("语言识别", "相关于", "人工智能"),
("图像识别", "相关于", "人工智能"),
("专家系统", "相关于", "人工智能")
]
def extract_entities(self, text: str) -> List[Entity]:
"""
从文本中提取实体
Args:
text (str): 输入文本
Returns:
List[Entity]: 提取的实体列表
"""
entities = []
entity_ids = set()
# 简单的关键词匹配(实际应用中应使用NER模型)
for keyword, entity_type in self.entity_patterns.items():
if keyword in text:
# 生成实体ID
entity_id = f"entity_{hash(keyword) % 10000}"
# 避免重复实体
if entity_id not in entity_ids:
entity = Entity(
id=entity_id,
name=keyword,
type=entity_type,
description=f"与人工智能相关的{entity_type.value}"
)
entities.append(entity)
entity_ids.add(entity_id)
logger.info(f"提取实体: {keyword} ({entity_type.value})")
logger.info(f"共提取 {len(entities)} 个实体")
return entities
def extract_relations(self, text: str, entities: List[Entity]) -> List[Relation]:
"""
从文本中提取关系
Args:
text (str): 输入文本
entities (List[Entity]): 实体列表
Returns:
List[Relation]: 提取的关系列表
"""
relations = []
relation_ids = set()
# 创建实体名称到ID的映射
entity_name_to_id = {entity.name: entity.id for entity in entities}
# 简单的关系模式匹配(实际应用中应使用关系抽取模型)
for source, relation_type, target in self.relation_patterns:
if source in entity_name_to_id and target in entity_name_to_id:
# 生成关系ID
relation_id = f"relation_{hash(f'{source}_{relation_type}_{target}') % 10000}"
# 避免重复关系
if relation_id not in relation_ids:
relation = Relation(
id=relation_id,
source_entity_id=entity_name_to_id[source],
target_entity_id=entity_name_to_id[target],
type=RelationType.RELATED_TO,
description=f"{source} 与 {target} 相关"
)
relations.append(relation)
relation_ids.add(relation_id)
logger.info(f"提取关系: {source} -> {target}")
logger.info(f"共提取 {len(relations)} 个关系")
return relations
def build_knowledge_graph(self, text: str) -> KnowledgeGraph:
"""
构建知识图谱
Args:
text (str): 输入文本
Returns:
KnowledgeGraph: 构建的知识图谱
"""
logger.info("开始构建知识图谱")
# 提取实体
entities = self.extract_entities(text)
# 提取关系
relations = self.extract_relations(text, entities)
# 构建知识图谱
kg = KnowledgeGraph(entities={}, relations={})
# 添加实体到知识图谱
for entity in entities:
kg.entities[entity.id] = entity
# 添加关系到知识图谱
for relation in relations:
kg.relations[relation.id] = relation
self.kg = kg
logger.info("知识图谱构建完成")
return kg
def merge_knowledge_graph(self, new_kg: KnowledgeGraph) -> None:
"""
合并知识图谱
Args:
new_kg (KnowledgeGraph): 新的知识图谱
"""
logger.info("开始合并知识图谱")
# 合并实体
for entity_id, entity in new_kg.entities.items():
if entity_id not in self.kg.entities:
self.kg.entities[entity_id] = entity
logger.info(f"添加新实体: {entity.name}")
# 合并关系
for relation_id, relation in new_kg.relations.items():
if relation_id not in self.kg.relations:
self.kg.relations[relation_id] = relation
logger.info(f"添加新关系: {relation.source_entity_id} -> {relation.target_entity_id}")
logger.info("知识图谱合并完成")
def query_entity(self, entity_name: str) -> List[Entity]:
"""
查询实体
Args:
entity_name (str): 实体名称
Returns:
List[Entity]: 匹配的实体列表
"""
results = []
for entity in self.kg.entities.values():
if entity_name.lower() in entity.name.lower():
results.append(entity)
return results
def query_relation(self, source_entity: str, target_entity: str) -> List[Relation]:
"""
查询关系
Args:
source_entity (str): 源实体名称
target_entity (str): 目标实体名称
Returns:
List[Relation]: 匹配的关系列表
"""
results = []
# 查找实体ID
source_ids = [e.id for e in self.query_entity(source_entity)]
target_ids = [e.id for e in self.query_entity(target_entity)]
# 查找关系
for relation in self.kg.relations.values():
if (relation.source_entity_id in source_ids and
relation.target_entity_id in target_ids):
results.append(relation)
return results
def export_to_json(self, file_path: str) -> None:
"""
导出知识图谱到JSON文件
Args:
file_path (str): 文件路径
"""
# 转换实体和关系为字典格式
entities_dict = {eid: asdict(entity) for eid, entity in self.kg.entities.items()}
relations_dict = {rid: asdict(relation) for rid, relation in self.kg.relations.items()}
# 创建导出数据
export_data = {
"entities": entities_dict,
"relations": relations_dict
}
# 写入文件
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(export_data, f, ensure_ascii=False, indent=2)
logger.info(f"知识图谱已导出到: {file_path}")
def get_statistics(self) -> Dict[str, int]:
"""
获取知识图谱统计信息
Returns:
Dict[str, int]: 统计信息
"""
entity_types = {}
for entity in self.kg.entities.values():
entity_type = entity.type.value
entity_types[entity_type] = entity_types.get(entity_type, 0) + 1
return {
"total_entities": len(self.kg.entities),
"total_relations": len(self.kg.relations),
"entity_types": entity_types
}
# 使用示例
def main():
"""主函数"""
# 创建知识图谱构建器
builder = KnowledgeGraphBuilder()
# 测试文本
text = """
人工智能(Artificial Intelligence,AI)是计算机科学的一个分支,它企图了解智能的实质,
并生产出一种新的能以人类智能相似的方式做出反应的智能机器。该领域的研究包括机器人、
语言识别、图像识别、自然语言处理和专家系统等。
机器学习是人工智能的一个重要分支,它使计算机能够从数据中学习并做出预测或决策,
而无需明确编程来执行特定任务。深度学习是机器学习的一个子集,它模仿人脑的工作方式
来处理数据和创建模式,用于决策制定。
自然语言处理(NLP)是人工智能的一个分支,它帮助计算机理解和解释人类语言,
并以一种有价值和适当的方式回应人类。NLP结合了计算语言学、计算机科学和人工智能,
使人类能够以自然的方式与计算机交互。
"""
# 构建知识图谱
kg = builder.build_knowledge_graph(text)
# 显示统计信息
stats = builder.get_statistics()
logger.info("=== 知识图谱统计信息 ===")
logger.info(f"实体总数: {stats['total_entities']}")
logger.info(f"关系总数: {stats['total_relations']}")
logger.info("实体类型分布:")
for entity_type, count in stats['entity_types'].items():
logger.info(f" {entity_type}: {count}")
# 查询示例
logger.info("=== 实体查询示例 ===")
ai_entities = builder.query_entity("人工智能")
for entity in ai_entities:
logger.info(f"找到实体: {entity.name} ({entity.type.value})")
logger.info("=== 关系查询示例 ===")
ml_relations = builder.query_relation("机器学习", "人工智能")
for relation in ml_relations:
logger.info(f"找到关系: 机器学习 相关于 人工智能")
# 导出知识图谱
builder.export_to_json("knowledge_graph.json")
logger.info("知识图谱已导出到 knowledge_graph.json")
if __name__ == "__main__":
main()
实践案例
案例 1:学术文献知识图谱构建
假设我们需要处理一批学术文献,从中提取研究领域、技术方法和研究成果等信息,构建学术知识图谱。
实践步骤
- 文献收集:收集相关领域的学术论文 PDF 文件
- 文档预处理:解析 PDF 文件,提取文本内容
- 实体识别:识别论文中的研究领域、技术方法、实验数据等实体
- 关系抽取:提取实体之间的关系,如"方法应用于领域"、"数据支持结论"等
- 知识图谱构建:将提取的实体和关系构建成知识图谱
- 可视化展示:将知识图谱以图形化方式展示
代码示例
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
学术文献知识图谱构建示例
展示如何处理学术文献并构建知识图谱
"""
import logging
from typing import List, Dict
import random
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class AcademicLiteratureKGBuilder:
"""学术文献知识图谱构建器"""
def __init__(self):
"""初始化构建器"""
self.papers = []
self.entities = {}
self.relations = {}
def add_paper(self, title: str, authors: List[str], year: int,
abstract: str, keywords: List[str]) -> None:
"""
添加论文信息
Args:
title (str): 论文标题
authors (List[str]): 作者列表
year (int): 发表年份
abstract (str): 摘要
keywords (List[str]): 关键词列表
"""
paper = {
'title': title,
'authors': authors,
'year': year,
'abstract': abstract,
'keywords': keywords
}
self.papers.append(paper)
logger.info(f"添加论文: {title}")
def extract_academic_entities(self) -> None:
"""提取学术实体"""
# 模拟实体提取过程
research_areas = [
"自然语言处理", "计算机视觉", "机器学习", "深度学习",
"知识图谱", "推荐系统", "数据挖掘", "人工智能"
]
methods = [
"神经网络", "卷积神经网络", "循环神经网络", "Transformer",
"BERT", "GNN", "SVM", "随机森林"
]
datasets = [
"ImageNet", "CIFAR-10", "MNIST", "CoNLL",
"SQuAD", "GLUE", "WikiText", "Penn Treebank"
]
# 为每篇论文生成随机实体
for i, paper in enumerate(self.papers):
# 生成实体ID
paper_id = f"paper_{i}"
# 随机选择研究领域、方法和数据集
area = random.choice(research_areas)
method = random.choice(methods)
dataset = random.choice(datasets)
# 创建实体
self.entities[f"{paper_id}_area"] = {
'id': f"{paper_id}_area",
'name': area,
'type': 'research_area',
'paper_id': paper_id
}
self.entities[f"{paper_id}_method"] = {
'id': f"{paper_id}_method",
'name': method,
'type': 'method',
'paper_id': paper_id
}
self.entities[f"{paper_id}_dataset"] = {
'id': f"{paper_id}_dataset",
'name': dataset,
'type': 'dataset',
'paper_id': paper_id
}
# 创建关系
self.relations[f"{paper_id}_uses_area"] = {
'id': f"{paper_id}_uses_area",
'source': paper_id,
'target': f"{paper_id}_area",
'type': '研究领域',
'description': f"论文研究{area}"
}
self.relations[f"{paper_id}_applies_method"] = {
'id': f"{paper_id}_applies_method",
'source': paper_id,
'target': f"{paper_id}_method",
'type': '应用方法',
'description': f"论文应用{method}"
}
self.relations[f"{paper_id}_uses_dataset"] = {
'id': f"{paper_id}_uses_dataset",
'source': paper_id,
'target': f"{paper_id}_dataset",
'type': '使用数据集',
'description': f"论文使用{dataset}"
}
logger.info(f"从 {len(self.papers)} 篇论文中提取了实体和关系")
def build_knowledge_graph(self) -> Dict:
"""
构建知识图谱
Returns:
Dict: 知识图谱数据
"""
# 提取实体
self.extract_academic_entities()
# 构建知识图谱
kg = {
'papers': self.papers,
'entities': list(self.entities.values()),
'relations': list(self.relations.values())
}
logger.info("学术文献知识图谱构建完成")
return kg
def get_statistics(self) -> Dict:
"""
获取统计信息
Returns:
Dict: 统计信息
"""
return {
'paper_count': len(self.papers),
'entity_count': len(self.entities),
'relation_count': len(self.relations)
}
# 使用示例
def main():
"""主函数"""
# 创建构建器
builder = AcademicLiteratureKGBuilder()
# 添加示例论文
sample_papers = [
{
'title': "基于Transformer的中文文本分类研究",
'authors': ["张三", "李四"],
'year': 2023,
'abstract': "本文提出了一种基于Transformer的中文文本分类方法...",
'keywords': ["Transformer", "文本分类", "自然语言处理", "深度学习"]
},
{
'title': "图神经网络在推荐系统中的应用",
'authors': ["王五", "赵六"],
'year': 2022,
'abstract': "本文研究了图神经网络在推荐系统中的应用效果...",
'keywords': ["图神经网络", "推荐系统", "机器学习", "用户行为"]
},
{
'title': "多模态情感分析技术综述",
'authors': ["孙七", "周八"],
'year': 2023,
'abstract': "本文综述了多模态情感分析的主要技术和方法...",
'keywords': ["多模态", "情感分析", "计算机视觉", "自然语言处理"]
}
]
# 添加论文
for paper in sample_papers:
builder.add_paper(
title=paper['title'],
authors=paper['authors'],
year=paper['year'],
abstract=paper['abstract'],
keywords=paper['keywords']
)
# 构建知识图谱
kg = builder.build_knowledge_graph()
# 显示统计信息
stats = builder.get_statistics()
logger.info("=== 学术文献知识图谱统计 ===")
logger.info(f"论文数量: {stats['paper_count']}")
logger.info(f"实体数量: {stats['entity_count']}")
logger.info(f"关系数量: {stats['relation_count']}")
# 显示部分实体和关系
logger.info("=== 部分实体 ===")
for entity in list(kg['entities'])[:5]:
logger.info(f" {entity['name']} ({entity['type']})")
logger.info("=== 部分关系 ===")
for relation in list(kg['relations'])[:5]:
logger.info(f" {relation['type']}: {relation['description']}")
if __name__ == "__main__":
main()
案例 2:企业知识管理
假设某科技公司需要构建内部知识库,从技术文档、会议记录、项目报告等文档中提取知识,构建企业知识图谱。
实践步骤
- 文档收集:收集企业内部各类文档
- 权限管理:确保文档处理符合企业安全要求
- 知识提取:从文档中提取项目、技术、人员等实体
- 关系建立:建立实体间的关系,如"人员参与项目"、"技术应用于产品"等
- 知识存储:将知识图谱存储到企业知识库中
- 应用集成:将知识图谱集成到企业内部系统中
系统架构图
业务流程图
知识体系思维导图
项目实施计划甘特图
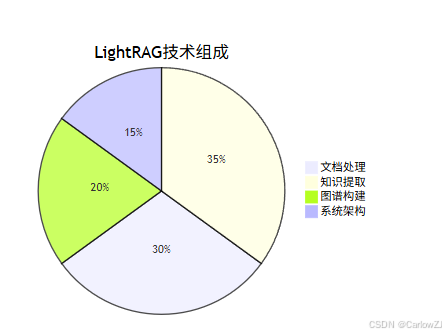
技术分布饼图
常见问题及解决方案
问题 1:文件损坏
现象:处理文件时出现 EOF marker not found 或 negative seek value -1 错误。
解决方案:
- 检查文件是否完整,尝试用其他工具(如 Adobe Acrobat)打开文件。
- 如果文件损坏,尝试重新下载或修复文件。
- 在代码中添加文件完整性校验机制。
def verify_file_integrity(file_path: str) -> bool:
"""
验证文件完整性
Args:
file_path (str): 文件路径
Returns:
bool: 文件是否完整
"""
try:
# 检查文件是否存在
if not os.path.exists(file_path):
return False
# 检查文件大小
if os.path.getsize(file_path) == 0:
return False
# 尝试读取文件头部
with open(file_path, 'rb') as f:
header = f.read(1024)
if not header:
return False
return True
except Exception as e:
logger.error(f"文件完整性检查失败: {str(e)}")
return False
问题 2:文件内容为空
现象:文件中只包含空白字符。
解决方案:
- 检查文件内容是否确实为空。
- 如果文件内容为空,清理或重新上传有效内容。
- 添加内容验证机制。
def is_content_valid(text: str) -> bool:
"""
检查文本内容是否有效
Args:
text (str): 文本内容
Returns:
bool: 内容是否有效
"""
if not text:
return False
# 移除空白字符后检查
cleaned_text = ''.join(text.split())
if not cleaned_text:
return False
# 检查最小长度
if len(cleaned_text) < 10:
return False
return True
问题 3:编码问题
现象:文件中使用了不支持的编码,导致解析失败。
解决方案:
- 确保文件使用 UTF-8 编码。
- 如果文件使用其他编码,尝试转换为 UTF-8。
- 实现自动编码检测机制。
def detect_and_convert_encoding(file_path: str) -> str:
"""
检测并转换文件编码为UTF-8
Args:
file_path (str): 文件路径
Returns:
str: UTF-8编码的文本内容
"""
try:
# 尝试使用chardet库检测编码
import chardet
# 检测编码
with open(file_path, 'rb') as f:
raw_data = f.read()
encoding_info = chardet.detect(raw_data)
detected_encoding = encoding_info['encoding']
logger.info(f"检测到文件编码: {detected_encoding}")
# 转换为UTF-8
text = raw_data.decode(detected_encoding)
return text
except ImportError:
logger.warning("未安装chardet库,使用默认编码处理")
# 使用默认方式处理
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
except Exception as e:
logger.error(f"编码转换失败: {str(e)}")
raise
问题 4:性能问题
现象:处理大量文档时,系统性能下降。
解决方案:
- 优化代码,减少不必要的计算。
- 使用多线程或异步处理提高效率。
- 实施批处理机制。
import asyncio
from concurrent.futures import ThreadPoolExecutor
class AsyncDocumentProcessor:
"""异步文档处理器"""
def __init__(self, max_workers: int = 4):
"""
初始化异步文档处理器
Args:
max_workers (int): 最大工作线程数
"""
self.executor = ThreadPoolExecutor(max_workers=max_workers)
async def process_documents_async(self, file_paths: List[str]) -> List[Dict]:
"""
异步处理多个文档
Args:
file_paths (List[str]): 文件路径列表
Returns:
List[Dict]: 处理结果列表
"""
loop = asyncio.get_event_loop()
tasks = []
for file_path in file_paths:
# 创建异步任务
task = loop.run_in_executor(
self.executor,
self._process_single_document,
file_path
)
tasks.append(task)
# 等待所有任务完成
results = await asyncio.gather(*tasks, return_exceptions=True)
# 处理结果
processed_results = []
for i, result in enumerate(results):
if isinstance(result, Exception):
logger.error(f"处理文档 {file_paths[i]} 时发生错误: {result}")
processed_results.append({
'file_path': file_paths[i],
'status': 'failed',
'error': str(result)
})
else:
processed_results.append(result)
return processed_results
def _process_single_document(self, file_path: str) -> Dict:
"""
处理单个文档
Args:
file_path (str): 文件路径
Returns:
Dict: 处理结果
"""
try:
# 模拟文档处理过程
import time
time.sleep(1) # 模拟处理时间
return {
'file_path': file_path,
'status': 'success',
'processed_at': time.time()
}
except Exception as e:
return {
'file_path': file_path,
'status': 'failed',
'error': str(e)
}
最佳实践
实践建议
1. 文件处理最佳实践
- 文件完整性检查:确保上传的文件完整且未损坏
- 编码处理:使用支持中文的编码格式(如 UTF-8)
- 格式验证:验证文件格式是否支持
- 大小限制:设置合理的文件大小限制
2. 错误处理最佳实践
- 异常捕获:在代码中添加完善的错误处理逻辑
- 日志记录:详细记录处理过程和错误信息
- 重试机制:实现失败重试机制
- 用户反馈:向用户提供清晰的错误信息
import functools
import time
def retry(max_attempts: int = 3, delay: float = 1.0):
"""
重试装饰器
Args:
max_attempts (int): 最大重试次数
delay (float): 重试间隔(秒)
"""
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
last_exception = None
for attempt in range(max_attempts):
try:
return func(*args, **kwargs)
except Exception as e:
last_exception = e
logger.warning(f"第 {attempt + 1} 次尝试失败: {str(e)}")
if attempt < max_attempts - 1:
time.sleep(delay)
logger.error(f"所有 {max_attempts} 次尝试均失败")
raise last_exception
return wrapper
return decorator
class RobustDocumentProcessor:
"""健壮的文档处理器"""
@retry(max_attempts=3, delay=2.0)
def process_document_with_retry(self, file_path: str) -> Dict:
"""
带重试机制的文档处理
Args:
file_path (str): 文件路径
Returns:
Dict: 处理结果
"""
# 模拟可能失败的文档处理过程
import random
# 有一定概率失败,用于测试重试机制
if random.random() < 0.3:
raise Exception("模拟处理失败")
return {
'file_path': file_path,
'status': 'success',
'processed_at': time.time()
}
3. 性能优化最佳实践
- 批处理:批量处理文档以提高效率
- 并行处理:使用多线程或异步处理提高并发能力
- 缓存机制:实现缓存机制避免重复计算
- 资源管理:合理管理内存和CPU资源
4. 安全性最佳实践
- 输入验证:验证用户输入,防止恶意内容
- 权限控制:实现适当的权限控制机制
- 数据加密:对敏感数据进行加密存储
- 访问日志:记录所有访问和操作日志
扩展阅读
总结
本文详细介绍了如何使用 LightRAG 进行中文文档处理和知识图谱构建。通过实际案例,展示了从文档上传、处理到知识图谱生成的完整流程。文章涵盖了文档处理、知识提取、图谱构建等核心技术,并提供了丰富的代码示例和最佳实践建议。
关键要点包括:
- LightRAG 简介:了解 LightRAG 的特点和应用场景
- 系统架构:掌握 LightRAG 系统的整体架构和组件设计
- 文档处理流程:学习文档从上传到处理的完整流程
- 知识图谱构建:掌握从文本中提取实体和关系的方法
- 实践案例:通过实际案例加深理解
- 问题解决:了解常见问题及其解决方案
- 最佳实践:遵循行业最佳实践,构建高质量系统
通过合理应用这些技术和方法,开发者可以构建出高效、稳定的中文文档处理和知识图谱构建系统,为知识管理和智能问答等应用提供强有力的支持。
参考资料
版权声明:本文为原创文章,未经授权不得转载。如需转载,请联系作者。



















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











