



摘要
随着人工智能技术的快速发展,AI 应用已成为现代软件开发的重要组成部分。本文将为您提供一份完整的 AI 应用开发与部署实践指南,涵盖从环境搭建、数据处理、模型训练到应用部署、监控运维的全流程。通过丰富的实践案例和详细的代码示例,帮助中国开发者特别是 AI 应用开发者掌握从概念到生产环境的完整技术栈。文章包含系统架构图、业务流程图、思维导图、甘特图和饼图等可视化内容,以及最佳实践建议和常见问题解答,是一份实用的 AI 应用开发参考手册。
正文
1. 引言
人工智能正在深刻改变我们的生活和工作方式。从智能客服到图像识别,从自然语言处理到推荐系统,AI 应用已经渗透到各行各业。然而,许多开发者在将 AI 技术应用到实际项目时,常常面临从模型训练到生产部署的挑战。
本文旨在为开发者提供一套完整的 AI 应用开发与部署解决方案,涵盖从环境搭建、数据处理、模型训练到应用部署、监控运维的全流程。无论您是刚刚接触 AI 开发的新手,还是希望提升技能的经验丰富的开发者,都能从本文中获得有价值的知识和实践经验。
2. 环境搭建与配置
2.1 开发环境准备
在开始 AI 应用开发之前,我们需要搭建合适的开发环境。推荐使用 Anaconda 或 Miniconda 来管理 Python 环境,这样可以避免不同项目之间的依赖冲突。
# 下载并安装 Miniconda(以 Linux 为例)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# 创建专门的 AI 开发环境
conda create -n ai-dev python=3.9
conda activate ai-dev
2.2 核心依赖库安装
AI 应用开发需要安装一系列核心库,包括数据处理、机器学习和深度学习相关的工具:
# 安装核心科学计算库
pip install numpy pandas matplotlib seaborn
# 安装机器学习库
pip install scikit-learn
# 安装深度学习框架
pip install tensorflow torch
# 安装 Web 框架用于部署
pip install flask fastapi
# 安装数据可视化和部署相关工具
pip install plotly dash streamlit
2.3 开发工具配置
选择合适的集成开发环境(IDE)对于提高开发效率至关重要:
# 推荐的开发工具配置
tools = {
"IDE": ["PyCharm", "VS Code", "Jupyter Notebook"],
"版本控制": "Git",
"包管理": "pip/conda",
"虚拟环境": "conda/virtualenv",
"文档工具": "Sphinx",
"测试框架": "pytest"
}
print("推荐的 Python AI 开发工具配置:")
for category, tool in tools.items():
print(f"{category}: {tool}")
3. 数据准备与处理
3.1 数据收集
数据是 AI 应用的基础。我们可以从多种来源获取数据:
import pandas as pd
import numpy as np
import requests
from io import StringIO
def load_data_from_csv(file_path):
"""
从 CSV 文件加载数据
Args:
file_path (str): CSV 文件路径
Returns:
pandas.DataFrame: 加载的数据
"""
try:
data = pd.read_csv(file_path)
print(f"成功加载数据,共 {len(data)} 行,{len(data.columns)} 列")
return data
except Exception as e:
print(f"加载数据时出错: {e}")
return None
def load_data_from_api(url):
"""
从 API 接口加载数据
Args:
url (str): API 接口地址
Returns:
pandas.DataFrame: 加载的数据
"""
try:
response = requests.get(url)
if response.status_code == 200:
data = pd.read_json(StringIO(response.text))
print(f"成功从 API 加载数据,共 {len(data)} 行")
return data
else:
print(f"API 请求失败,状态码: {response.status_code}")
return None
except Exception as e:
print(f"从 API 加载数据时出错: {e}")
return None
# 示例:加载数据
# data = load_data_from_csv('data/sample_data.csv')
# api_data = load_data_from_api('https://api.example.com/data')
3.2 数据清洗与预处理
原始数据往往包含缺失值、异常值等问题,需要进行清洗和预处理:
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
def clean_and_preprocess_data(data):
"""
清洗和预处理数据
Args:
data (pandas.DataFrame): 原始数据
Returns:
tuple: (清洗后的特征数据, 标签数据, 特征名称列表)
"""
print("开始数据清洗和预处理...")
# 查看数据基本信息
print("数据基本信息:")
print(data.info())
print("\n数据统计摘要:")
print(data.describe())
# 处理缺失值
print("\n处理缺失值...")
missing_values = data.isnull().sum()
print("各列缺失值情况:")
print(missing_values[missing_values > 0])
# 删除缺失值过多的列(缺失值超过50%)
threshold = len(data) * 0.5
data_cleaned = data.dropna(thresh=threshold, axis=1)
# 对数值型列用均值填充缺失值
numeric_columns = data_cleaned.select_dtypes(include=[np.number]).columns
data_cleaned[numeric_columns] = data_cleaned[numeric_columns].fillna(
data_cleaned[numeric_columns].mean()
)
# 对分类变量列用众数填充缺失值
categorical_columns = data_cleaned.select_dtypes(include=['object']).columns
for col in categorical_columns:
data_cleaned[col] = data_cleaned[col].fillna(
data_cleaned[col].mode()[0] if not data_cleaned[col].mode().empty else 'Unknown'
)
print(f"清洗后数据形状: {data_cleaned.shape}")
return data_cleaned
def encode_categorical_features(data, categorical_columns):
"""
对分类特征进行编码
Args:
data (pandas.DataFrame): 数据
categorical_columns (list): 分类特征列名列表
Returns:
pandas.DataFrame: 编码后的数据
"""
data_encoded = data.copy()
label_encoders = {}
for col in categorical_columns:
if col in data_encoded.columns:
le = LabelEncoder()
data_encoded[col] = le.fit_transform(data_encoded[col].astype(str))
label_encoders[col] = le
print(f"已完成 {col} 列的标签编码")
return data_encoded, label_encoders
def scale_numerical_features(data, numerical_columns):
"""
对数值特征进行标准化
Args:
data (pandas.DataFrame): 数据
numerical_columns (list): 数值特征列名列表
Returns:
tuple: (标准化后的数据, 标准化器)
"""
scaler = StandardScaler()
data_scaled = data.copy()
# 确保数值列存在
existing_numerical_columns = [col for col in numerical_columns if col in data_scaled.columns]
if existing_numerical_columns:
data_scaled[existing_numerical_columns] = scaler.fit_transform(
data_scaled[existing_numerical_columns]
)
print(f"已完成 {len(existing_numerical_columns)} 个数值特征的标准化")
return data_scaled, scaler
# 示例使用
# cleaned_data = clean_and_preprocess_data(raw_data)
4. 模型训练与评估
4.1 机器学习模型
我们先从传统的机器学习模型开始,使用 scikit-learn 构建分类模型:
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
class MLModelTrainer:
"""
机器学习模型训练器
"""
def __init__(self):
"""
初始化模型训练器
"""
self.models = {
'random_forest': RandomForestClassifier(n_estimators=100, random_state=42),
'logistic_regression': LogisticRegression(random_state=42, max_iter=1000),
'svm': SVC(random_state=42)
}
self.trained_models = {}
self.best_model = None
self.best_score = 0
def train_models(self, X_train, y_train, X_test, y_test):
"""
训练多个模型并比较性能
Args:
X_train (array-like): 训练特征数据
y_train (array-like): 训练标签数据
X_test (array-like): 测试特征数据
y_test (array-like): 测试标签数据
Returns:
dict: 各模型的性能指标
"""
results = {}
print("开始训练模型...")
for name, model in self.models.items():
print(f"\n训练 {name} 模型...")
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
results[name] = {
'model': model,
'accuracy': accuracy,
'predictions': y_pred
}
print(f"{name} 准确率: {accuracy:.4f}")
# 保存最佳模型
if accuracy > self.best_score:
self.best_score = accuracy
self.best_model = model
self.best_model_name = name
self.trained_models = results
print(f"\n最佳模型: {self.best_model_name} (准确率: {self.best_score:.4f})")
return results
def evaluate_model(self, model_name, X_test, y_test):
"""
详细评估指定模型
Args:
model_name (str): 模型名称
X_test (array-like): 测试特征数据
y_test (array-like): 测试标签数据
"""
if model_name not in self.trained_models:
print(f"模型 {model_name} 尚未训练")
return
model = self.trained_models[model_name]['model']
y_pred = model.predict(X_test)
print(f"\n{model_name} 模型详细评估报告:")
print("=" * 50)
print("分类报告:")
print(classification_report(y_test, y_pred))
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title(f'{model_name} 混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.show()
def get_feature_importance(self, model_name, feature_names):
"""
获取特征重要性
Args:
model_name (str): 模型名称
feature_names (list): 特征名称列表
"""
if model_name not in self.trained_models:
print(f"模型 {model_name} 尚未训练")
return
model = self.trained_models[model_name]['model']
# 只有部分模型支持特征重要性
if hasattr(model, 'feature_importances_'):
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
print(f"\n{model_name} 特征重要性排序:")
print("=" * 30)
for i in range(min(10, len(feature_names))): # 显示前10个重要特征
print(f"{i+1}. {feature_names[indices[i]]}: {importances[indices[i]]:.4f}")
else:
print(f"模型 {model_name} 不支持特征重要性分析")
# 使用示例
# trainer = MLModelTrainer()
# results = trainer.train_models(X_train, y_train, X_test, y_test)
# trainer.evaluate_model('random_forest', X_test, y_test)
4.2 深度学习模型
接下来我们使用 TensorFlow/Keras 构建深度学习模型:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
import matplotlib.pyplot as plt
class DeepLearningModel:
"""
深度学习模型构建器
"""
def __init__(self, input_dim, num_classes):
"""
初始化深度学习模型
Args:
input_dim (int): 输入特征维度
num_classes (int): 分类数量
"""
self.input_dim = input_dim
self.num_classes = num_classes
self.model = None
self.history = None
def build_model(self, architecture='default'):
"""
构建神经网络模型
Args:
architecture (str): 模型架构类型
"""
self.model = Sequential()
if architecture == 'default':
# 默认架构
self.model.add(Dense(128, activation='relu', input_shape=(self.input_dim,)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(64, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(32, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.2))
elif architecture == 'deep':
# 更深的架构
self.model.add(Dense(256, activation='relu', input_shape=(self.input_dim,)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.4))
self.model.add(Dense(128, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(64, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.3))
self.model.add(Dense(32, activation='relu'))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.2))
# 输出层
if self.num_classes == 2:
# 二分类
self.model.add(Dense(1, activation='sigmoid'))
self.model.compile(
optimizer=Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy']
)
else:
# 多分类
self.model.add(Dense(self.num_classes, activation='softmax'))
self.model.compile(
optimizer=Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
print("模型架构:")
self.model.summary()
def train(self, X_train, y_train, X_val, y_val, epochs=100, batch_size=32):
"""
训练模型
Args:
X_train (array-like): 训练特征数据
y_train (array-like): 训练标签数据
X_val (array-like): 验证特征数据
y_val (array-like): 验证标签数据
epochs (int): 训练轮数
batch_size (int): 批次大小
"""
# 定义回调函数
callbacks = [
EarlyStopping(patience=10, restore_best_weights=True),
ReduceLROnPlateau(factor=0.5, patience=5)
]
print("开始训练深度学习模型...")
self.history = self.model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=epochs,
batch_size=batch_size,
callbacks=callbacks,
verbose=1
)
return self.history
def evaluate(self, X_test, y_test):
"""
评估模型性能
Args:
X_test (array-like): 测试特征数据
y_test (array-like): 测试标签数据
"""
if self.model is None:
print("模型尚未构建")
return
loss, accuracy = self.model.evaluate(X_test, y_test, verbose=0)
print(f"测试集性能 - Loss: {loss:.4f}, Accuracy: {accuracy:.4f}")
return loss, accuracy
def plot_training_history(self):
"""
绘制训练历史曲线
"""
if self.history is None:
print("尚未训练模型")
return
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
# 绘制损失曲线
ax1.plot(self.history.history['loss'], label='训练损失')
ax1.plot(self.history.history['val_loss'], label='验证损失')
ax1.set_title('模型损失')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.legend()
# 绘制准确率曲线
ax2.plot(self.history.history['accuracy'], label='训练准确率')
ax2.plot(self.history.history['val_accuracy'], label='验证准确率')
ax2.set_title('模型准确率')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy')
ax2.legend()
plt.tight_layout()
plt.show()
def predict(self, X):
"""
进行预测
Args:
X (array-like): 特征数据
Returns:
array: 预测结果
"""
if self.model is None:
print("模型尚未构建")
return None
return self.model.predict(X)
# 使用示例
# dl_model = DeepLearningModel(input_dim=X_train.shape[1], num_classes=len(np.unique(y_train)))
# dl_model.build_model(architecture='default')
# history = dl_model.train(X_train, y_train, X_val, y_val, epochs=50)
# dl_model.plot_training_history()
5. 应用部署
5.1 构建 RESTful API
使用 Flask 构建 RESTful API,将训练好的模型部署为服务:
from flask import Flask, request, jsonify
import pickle
import numpy as np
import pandas as pd
from flask_cors import CORS
class ModelAPIService:
"""
模型 API 服务类
"""
def __init__(self, model_path, scaler_path=None, label_encoder_path=None):
"""
初始化 API 服务
Args:
model_path (str): 模型文件路径
scaler_path (str): 标准化器文件路径(可选)
label_encoder_path (str): 标签编码器文件路径(可选)
"""
# 加载模型
with open(model_path, 'rb') as f:
self.model = pickle.load(f)
# 加载标准化器(如果存在)
self.scaler = None
if scaler_path and os.path.exists(scaler_path):
with open(scaler_path, 'rb') as f:
self.scaler = pickle.load(f)
# 加载标签编码器(如果存在)
self.label_encoder = None
if label_encoder_path and os.path.exists(label_encoder_path):
with open(label_encoder_path, 'rb') as f:
self.label_encoder = pickle.load(f)
# 初始化 Flask 应用
self.app = Flask(__name__)
CORS(self.app) # 允许跨域请求
self._setup_routes()
def _setup_routes(self):
"""
设置 API 路由
"""
@self.app.route('/health', methods=['GET'])
def health_check():
"""健康检查端点"""
return jsonify({
'status': 'healthy',
'message': 'Model API service is running'
})
@self.app.route('/predict', methods=['POST'])
def predict():
"""预测端点"""
try:
# 获取请求数据
data = request.get_json()
if not data:
return jsonify({'error': 'No data provided'}), 400
# 转换为 DataFrame
if isinstance(data, list):
df = pd.DataFrame(data)
else:
df = pd.DataFrame([data])
# 数据预处理
if self.scaler:
processed_data = self.scaler.transform(df)
else:
processed_data = df.values
# 进行预测
predictions = self.model.predict(processed_data)
# 如果有标签编码器,进行反编码
if self.label_encoder:
predictions = self.label_encoder.inverse_transform(predictions)
# 处理预测概率(如果模型支持)
probabilities = None
if hasattr(self.model, 'predict_proba'):
probabilities = self.model.predict_proba(processed_data)
# 取前5个最高概率的类别
top_indices = np.argsort(probabilities, axis=1)[:, -5:][:, ::-1]
top_probs = np.take_along_axis(probabilities, top_indices, axis=1)
prob_results = []
for i in range(len(top_indices)):
probs = []
for j, idx in enumerate(top_indices[i]):
class_label = idx
if self.label_encoder:
class_label = self.label_encoder.inverse_transform([idx])[0]
probs.append({
'class': str(class_label),
'probability': float(top_probs[i][j])
})
prob_results.append(probs)
# 构造响应
response = {
'predictions': [str(pred) for pred in predictions],
'count': len(predictions)
}
if probabilities is not None:
response['probabilities'] = prob_results
return jsonify(response)
except Exception as e:
return jsonify({'error': str(e)}), 500
@self.app.route('/model/info', methods=['GET'])
def model_info():
"""模型信息端点"""
info = {
'model_type': type(self.model).__name__,
'has_scaler': self.scaler is not None,
'has_label_encoder': self.label_encoder is not None
}
# 如果是 sklearn 模型,获取更多详细信息
if hasattr(self.model, 'get_params'):
info['parameters'] = self.model.get_params()
return jsonify(info)
def run(self, host='0.0.0.0', port=5000, debug=False):
"""
启动 API 服务
Args:
host (str): 主机地址
port (int): 端口号
debug (bool): 是否启用调试模式
"""
self.app.run(host=host, port=port, debug=debug)
# 创建 Flask 应用实例
def create_app():
"""
创建 Flask 应用
"""
app = Flask(__name__)
CORS(app)
# 模拟加载模型(实际应用中应从文件加载)
# model = load_model('model.pkl')
@app.route('/health')
def health():
return jsonify({'status': 'ok', 'message': 'AI Service is running'})
@app.route('/predict', methods=['POST'])
def predict():
try:
data = request.get_json()
# 这里应该进行实际的预测逻辑
# prediction = model.predict(data)
return jsonify({
'prediction': 'sample_prediction',
'confidence': 0.95
})
except Exception as e:
return jsonify({'error': str(e)}), 500
return app
# 如果直接运行此文件,则启动服务
if __name__ == '__main__':
app = create_app()
app.run(host='0.0.0.0', port=5000, debug=True)
5.2 构建 Web 前端界面
使用 Streamlit 创建简单的 Web 界面:
import streamlit as st
import pandas as pd
import numpy as np
import requests
import json
def main():
"""
主应用函数
"""
st.set_page_config(
page_title="AI 应用演示平台",
page_icon="🤖",
layout="wide"
)
# 页面标题
st.title("🤖 AI 应用演示平台")
st.markdown("---")
# 侧边栏
st.sidebar.header("应用导航")
app_mode = st.sidebar.selectbox(
"选择应用模式",
["首页", "数据预测", "模型信息"]
)
if app_mode == "首页":
show_home_page()
elif app_mode == "数据预测":
show_prediction_page()
elif app_mode == "模型信息":
show_model_info_page()
def show_home_page():
"""
显示首页内容
"""
st.header("欢迎使用 AI 应用演示平台")
st.markdown("""
这是一个基于 Python 的 AI 应用演示平台,展示了如何将机器学习模型部署为 Web 服务。
## 🚀 功能特性
- **实时预测**: 通过简单的表单输入数据,获取模型预测结果
- **模型信息**: 查看当前部署模型的基本信息
- **API 接口**: 提供标准的 RESTful API 接口
## 📊 技术栈
- **后端**: Python + Flask
- **前端**: Streamlit
- **机器学习**: Scikit-learn / TensorFlow
- **部署**: Docker 容器化
## 🎯 使用指南
1. 在左侧导航栏选择"数据预测"
2. 填写预测所需的数据
3. 点击"获取预测结果"按钮
4. 查看预测结果和置信度
""")
# 显示系统架构图
st.markdown("### 🏗️ 系统架构")
st.image("https://placehold.co/600x300.png?text=系统架构图",
caption="AI 应用系统架构图", use_column_width=True)
def show_prediction_page():
"""
显示预测页面
"""
st.header("🔮 数据预测")
st.markdown("""
在此页面您可以输入数据进行预测。请根据您的数据特征填写以下表单。
""")
# 创建输入表单
with st.form("prediction_form"):
st.subheader("输入数据特征")
# 示例特征输入(根据实际模型调整)
col1, col2 = st.columns(2)
with col1:
feature1 = st.number_input("特征 1", value=0.0, step=0.1)
feature2 = st.number_input("特征 2", value=0.0, step=0.1)
feature3 = st.number_input("特征 3", value=0.0, step=0.1)
with col2:
feature4 = st.number_input("特征 4", value=0.0, step=0.1)
feature5 = st.number_input("特征 5", value=0.0, step=0.1)
feature6 = st.number_input("特征 6", value=0.0, step=0.1)
# 提交按钮
submitted = st.form_submit_button("获取预测结果")
if submitted:
# 构造请求数据
input_data = {
"feature1": feature1,
"feature2": feature2,
"feature3": feature3,
"feature4": feature4,
"feature5": feature5,
"feature6": feature6
}
# 显示加载状态
with st.spinner("正在获取预测结果..."):
try:
# 这里应该调用实际的 API
# response = requests.post("http://localhost:5000/predict", json=input_data)
# result = response.json()
# 模拟预测结果
import random
result = {
"prediction": random.choice(["类别 A", "类别 B", "类别 C"]),
"confidence": random.uniform(0.7, 0.95)
}
# 显示结果
st.success("预测完成!")
st.subheader("预测结果")
col1, col2 = st.columns(2)
with col1:
st.metric("预测类别", result["prediction"])
with col2:
st.metric("置信度", f"{result['confidence']:.2%}")
# 显示概率分布图
st.subheader("概率分布")
probabilities = {
"类别 A": 0.35,
"类别 B": 0.42,
"类别 C": 0.23
}
st.bar_chart(probabilities)
except Exception as e:
st.error(f"预测过程中出现错误: {str(e)}")
def show_model_info_page():
"""
显示模型信息页面
"""
st.header("📊 模型信息")
st.markdown("""
当前部署的模型信息如下:
""")
# 模拟模型信息
model_info = {
"模型类型": "随机森林分类器",
"版本": "1.0.0",
"训练数据量": "10,000 样本",
"特征数量": 15,
"类别数量": 3,
"训练时间": "2024-01-15",
"最后更新": "2024-01-20",
"准确率": "92.5%"
}
# 以表格形式显示
df = pd.DataFrame(list(model_info.items()), columns=["属性", "值"])
st.table(df)
# 显示特征重要性(模拟)
st.subheader("特征重要性")
feature_importance = {
"年龄": 0.25,
"收入": 0.20,
"教育水平": 0.15,
"工作经验": 0.12,
"地理位置": 0.10,
"行业类型": 0.08,
"公司规模": 0.05,
"其他": 0.05
}
st.bar_chart(feature_importance)
if __name__ == "__main__":
main()
6. 容器化部署
6.1 Docker 配置
创建 Dockerfile 实现应用容器化:
# 使用 Python 3.9 基础镜像
FROM python:3.9-slim
# 设置工作目录
WORKDIR /app
# 设置环境变量
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
# 安装系统依赖
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
build-essential \
gcc \
&& rm -rf /var/lib/apt/lists/*
# 复制依赖文件
COPY requirements.txt .
# 安装 Python 依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 5000
# 创建非 root 用户
RUN adduser --disabled-password --gecos '' appuser
RUN chown -R appuser:appuser /app
USER appuser
# 启动应用
CMD ["gunicorn", "--bind", "0.0.0.0:5000", "--workers", "4", "app:app"]
6.2 Docker Compose 配置
使用 Docker Compose 管理多容器应用:
version: '3.8'
services:
# AI 应用服务
ai-app:
build: .
ports:
- "5000:5000"
environment:
- FLASK_ENV=production
- MODEL_PATH=/app/models/model.pkl
volumes:
- ./models:/app/models
- ./logs:/app/logs
depends_on:
- redis
restart: unless-stopped
networks:
- ai-network
# Redis 缓存服务
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
- redis_data:/data
restart: unless-stopped
networks:
- ai-network
# Nginx 反向代理
nginx:
image: nginx:alpine
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
- ./ssl:/etc/nginx/ssl
depends_on:
- ai-app
restart: unless-stopped
networks:
- ai-network
# Prometheus 监控
prometheus:
image: prom/prometheus:v2.40.0
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
restart: unless-stopped
networks:
- ai-network
# Grafana 可视化
grafana:
image: grafana/grafana-enterprise
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin123
depends_on:
- prometheus
restart: unless-stopped
networks:
- ai-network
volumes:
redis_data:
prometheus_data:
grafana_data:
networks:
ai-network:
driver: bridge
6.3 Kubernetes 部署配置
创建 Kubernetes 部署配置文件:
# ai-app-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-app-deployment
labels:
app: ai-app
spec:
replicas: 3
selector:
matchLabels:
app: ai-app
template:
metadata:
labels:
app: ai-app
spec:
containers:
- name: ai-app
image: your-registry/ai-app:latest
ports:
- containerPort: 5000
env:
- name: FLASK_ENV
value: "production"
- name: MODEL_PATH
value: "/app/models/model.pkl"
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
volumeMounts:
- name: model-storage
mountPath: /app/models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: model-pvc
---
apiVersion: v1
kind: Service
metadata:
name: ai-app-service
spec:
selector:
app: ai-app
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ai-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ai-app-deployment
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
7. 监控与日志
7.1 应用监控
集成 Prometheus 监控应用性能:
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import time
import threading
class MetricsCollector:
"""
应用指标收集器
"""
def __init__(self, port=8000):
"""
初始化指标收集器
Args:
port (int): Prometheus 指标服务端口
"""
# 定义指标
self.request_count = Counter(
'ai_app_requests_total',
'Total number of requests',
['method', 'endpoint', 'status']
)
self.request_duration = Histogram(
'ai_app_request_duration_seconds',
'Request duration in seconds',
['method', 'endpoint']
)
self.active_requests = Gauge(
'ai_app_active_requests',
'Number of active requests'
)
self.model_accuracy = Gauge(
'ai_app_model_accuracy',
'Current model accuracy'
)
# 启动 Prometheus HTTP 服务器
start_http_server(port)
print(f"Prometheus metrics server started on port {port}")
def track_request(self, method, endpoint, status, duration):
"""
跟踪请求指标
Args:
method (str): HTTP 方法
endpoint (str): 请求端点
status (int): HTTP 状态码
duration (float): 请求持续时间(秒)
"""
self.request_count.labels(method=method, endpoint=endpoint, status=status).inc()
self.request_duration.labels(method=method, endpoint=endpoint).observe(duration)
def track_active_request(self, change):
"""
跟踪活跃请求数量
Args:
change (int): 变化量 (+1 或 -1)
"""
self.active_requests.inc(change)
def update_model_accuracy(self, accuracy):
"""
更新模型准确率指标
Args:
accuracy (float): 模型准确率
"""
self.model_accuracy.set(accuracy)
# 初始化指标收集器
metrics = MetricsCollector(port=8000)
# Flask 应用中使用装饰器跟踪请求
from functools import wraps
def track_request_metrics(f):
"""
装饰器:跟踪请求指标
"""
@wraps(f)
def decorated_function(*args, **kwargs):
start_time = time.time()
method = request.method
endpoint = request.endpoint or 'unknown'
# 增加活跃请求数
metrics.track_active_request(1)
try:
result = f(*args, **kwargs)
status = result[1] if isinstance(result, tuple) and len(result) > 1 else 200
return result
except Exception as e:
status = 500
raise e
finally:
# 减少活跃请求数
metrics.track_active_request(-1)
# 记录请求持续时间
duration = time.time() - start_time
metrics.track_request(method, endpoint, status, duration)
return decorated_function
7.2 日志管理
配置结构化日志系统:
import logging
import logging.handlers
import json
from datetime import datetime
class JSONFormatter(logging.Formatter):
"""
JSON 格式化日志
"""
def format(self, record):
"""
格式化日志记录为 JSON
Args:
record (LogRecord): 日志记录对象
Returns:
str: JSON 格式的日志字符串
"""
log_entry = {
'timestamp': datetime.fromtimestamp(record.created).isoformat(),
'level': record.levelname,
'logger': record.name,
'message': record.getMessage(),
'module': record.module,
'function': record.funcName,
'line': record.lineno
}
# 添加异常信息(如果存在)
if record.exc_info:
log_entry['exception'] = self.formatException(record.exc_info)
# 添加额外字段
if hasattr(record, '__dict__'):
for key, value in record.__dict__.items():
if key not in ['name', 'msg', 'args', 'levelname', 'levelno',
'pathname', 'filename', 'module', 'lineno',
'funcName', 'created', 'msecs', 'relativeCreated',
'thread', 'threadName', 'processName', 'process',
'exc_info', 'exc_text', 'stack_info']:
log_entry[key] = value
return json.dumps(log_entry, ensure_ascii=False)
def setup_logging(log_file='app.log', max_bytes=10*1024*1024, backup_count=5):
"""
设置日志系统
Args:
log_file (str): 日志文件路径
max_bytes (int): 单个日志文件最大字节数
backup_count (int): 保留的备份文件数量
"""
# 创建 logger
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# 创建格式化器
json_formatter = JSONFormatter()
# 创建文件处理器(轮转)
file_handler = logging.handlers.RotatingFileHandler(
log_file,
maxBytes=max_bytes,
backupCount=backup_count,
encoding='utf-8'
)
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(json_formatter)
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
console_handler.setFormatter(console_formatter)
# 添加处理器到 logger
logger.addHandler(file_handler)
logger.addHandler(console_handler)
return logger
# 初始化日志系统
logger = setup_logging()
# 使用示例
# logger.info("应用启动", extra={'version': '1.0.0', 'environment': 'production'})
# logger.error("预测失败", extra={'input_data': input_data, 'error': str(e)})
8. 系统架构设计
8.1 架构图
8.2 数据流图
9. 实践案例
9.1 智能客服系统
构建一个智能客服系统,展示完整的 AI 应用开发流程:
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
import jieba
import re
class SmartCustomerService:
"""
智能客服系统
"""
def __init__(self):
"""
初始化智能客服系统
"""
# 创建分类管道
self.classifier = Pipeline([
('tfidf', TfidfVectorizer(
tokenizer=self.chinese_tokenizer,
stop_words=self.get_stop_words(),
max_features=5000
)),
('classifier', MultinomialNB())
])
# 定义问题类别
self.categories = {
0: "账户问题",
1: "订单问题",
2: "产品咨询",
3: "技术支持",
4: "退款问题",
5: "其他问题"
}
# 初始化已训练标志
self.is_trained = False
def chinese_tokenizer(self, text):
"""
中文分词器
Args:
text (str): 输入文本
Returns:
list: 分词结果
"""
# 清理文本
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', ' ', text)
# 分词
words = jieba.cut(text)
# 过滤空字符串和单字符
return [word.strip() for word in words if len(word.strip()) > 1]
def get_stop_words(self):
"""
获取停用词列表
Returns:
set: 停用词集合
"""
# 常见中文停用词
stop_words = {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个',
'上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好',
'自己', '这', '那', '里', '就是', '还是', '为了', '只有', '可以', '什么',
'怎么', '哪里', '哪个', '为什么', '怎么样', '多少', '多么', '难道', '是否'
}
return stop_words
def preprocess_text(self, text):
"""
预处理文本
Args:
text (str): 输入文本
Returns:
str: 预处理后的文本
"""
# 转换为小写
text = text.lower()
# 移除特殊字符
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]', '', text)
# 移除多余空格
text = re.sub(r'\s+', ' ', text).strip()
return text
def train(self, questions, labels):
"""
训练分类模型
Args:
questions (list): 问题列表
labels (list): 标签列表
"""
print("开始训练智能客服模型...")
# 预处理问题
processed_questions = [self.preprocess_text(q) for q in questions]
# 训练模型
self.classifier.fit(processed_questions, labels)
self.is_trained = True
print("模型训练完成!")
def predict_category(self, question):
"""
预测问题类别
Args:
question (str): 用户问题
Returns:
tuple: (预测类别ID, 类别名称, 置信度)
"""
if not self.is_trained:
raise ValueError("模型尚未训练,请先调用 train() 方法")
# 预处理问题
processed_question = self.preprocess_text(question)
# 预测
prediction = self.classifier.predict([processed_question])[0]
probabilities = self.classifier.predict_proba([processed_question])[0]
confidence = np.max(probabilities)
category_name = self.categories.get(prediction, "未知类别")
return prediction, category_name, confidence
def get_response_template(self, category_id):
"""
根据类别获取回复模板
Args:
category_id (int): 类别ID
Returns:
str: 回复模板
"""
templates = {
0: "关于您的账户问题,您可以尝试以下操作:\n1. 检查登录信息是否正确\n2. 重置密码\n3. 联系客服人工处理",
1: "关于您的订单问题,请提供订单号,我们将尽快为您查询处理。",
2: "感谢您对我们产品的关注!请问您想了解产品的哪些具体信息?",
3: "关于技术问题,我们的技术团队会尽快为您解答,请稍等。",
4: "关于退款问题,请提供订单信息和退款原因,我们会按流程处理。",
5: "您的问题已记录,客服人员会尽快联系您。"
}
return templates.get(category_id, "感谢您的咨询,客服人员会尽快回复您。")
def process_question(self, question):
"""
处理用户问题
Args:
question (str): 用户问题
Returns:
dict: 处理结果
"""
try:
# 预测问题类别
category_id, category_name, confidence = self.predict_category(question)
# 获取回复模板
response_template = self.get_response_template(category_id)
# 构造结果
result = {
'question': question,
'predicted_category': category_name,
'confidence': float(confidence),
'response': response_template,
'need_human_support': confidence < 0.7
}
return result
except Exception as e:
return {
'question': question,
'error': str(e),
'response': "抱歉,处理您的问题时出现错误,请稍后重试或联系人工客服。"
}
# 示例使用
def demo_customer_service():
"""
演示智能客服系统
"""
# 创建客服系统实例
customer_service = SmartCustomerService()
# 示例训练数据
training_questions = [
"我的账户登录不了怎么办",
"忘记密码如何重置",
"账户被锁定了怎么解锁",
"订单什么时候能发货",
"如何查询订单状态",
"订单取消了什么时候退款",
"这个产品有什么功能",
"产品的使用方法是什么",
"产品保修期多长",
"软件安装出现问题",
"系统运行很慢怎么办",
"如何联系技术支持",
"退款申请多久能处理",
"退款金额不对怎么办",
"不想要了能退款吗",
"其他问题咨询"
]
training_labels = [0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5]
# 训练模型
customer_service.train(training_questions, training_labels)
# 测试问题
test_questions = [
"登录不上账户",
"订单发货时间",
"产品功能介绍",
"软件运行卡顿",
"申请退款了",
"我想咨询其他问题"
]
print("智能客服系统演示:")
print("=" * 50)
for question in test_questions:
result = customer_service.process_question(question)
print(f"用户问题: {result['question']}")
print(f"问题分类: {result['predicted_category']}")
print(f"置信度: {result['confidence']:.2f}")
print(f"系统回复: {result['response']}")
if result.get('need_human_support'):
print("⚠️ 建议转接人工客服")
print("-" * 30)
# 运行演示
# demo_customer_service()
9.2 内容推荐系统
构建一个简单的推荐系统:
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import pickle
class ContentRecommendationSystem:
"""
内容推荐系统
"""
def __init__(self):
"""
初始化推荐系统
"""
self.content_data = None
self.tfidf_matrix = None
self.tfidf_vectorizer = None
self.is_trained = False
def load_content_data(self, data_path):
"""
加载内容数据
Args:
data_path (str): 数据文件路径
"""
try:
self.content_data = pd.read_csv(data_path)
print(f"成功加载 {len(self.content_data)} 条内容数据")
return True
except Exception as e:
print(f"加载数据失败: {e}")
return False
def prepare_content_features(self, content_columns):
"""
准备内容特征
Args:
content_columns (list): 用于特征提取的列名列表
"""
if self.content_data is None:
raise ValueError("请先加载内容数据")
# 合并指定列的内容
self.content_data['combined_features'] = ''
for col in content_columns:
if col in self.content_data.columns:
self.content_data['combined_features'] += self.content_data[col].fillna('') + ' '
# 初始化 TF-IDF 向量化器
self.tfidf_vectorizer = TfidfVectorizer(
max_features=10000,
stop_words='english',
ngram_range=(1, 2)
)
# 计算 TF-IDF 矩阵
self.tfidf_matrix = self.tfidf_vectorizer.fit_transform(
self.content_data['combined_features']
)
self.is_trained = True
print("内容特征准备完成")
def get_recommendations(self, content_id, top_n=5):
"""
获取推荐内容
Args:
content_id (int): 内容ID
top_n (int): 推荐数量
Returns:
pandas.DataFrame: 推荐内容
"""
if not self.is_trained:
raise ValueError("系统尚未训练,请先调用 prepare_content_features()")
# 计算余弦相似度
content_idx = self.content_data[self.content_data['id'] == content_id].index[0]
cosine_similarities = cosine_similarity(
self.tfidf_matrix[content_idx],
self.tfidf_matrix
).flatten()
# 获取相似度最高的内容索引
similar_indices = cosine_similarities.argsort()[::-1][1:top_n+1]
# 构造推荐结果
recommendations = self.content_data.iloc[similar_indices][
['id', 'title', 'description']
].copy()
recommendations['similarity_score'] = cosine_similarities[similar_indices]
return recommendations.sort_values('similarity_score', ascending=False)
def search_content(self, query, top_n=5):
"""
搜索内容
Args:
query (str): 搜索查询
top_n (int): 返回结果数量
Returns:
pandas.DataFrame: 搜索结果
"""
if not self.is_trained:
raise ValueError("系统尚未训练,请先调用 prepare_content_features()")
# 向量化查询
query_vector = self.tfidf_vectorizer.transform([query])
# 计算相似度
cosine_similarities = cosine_similarity(query_vector, self.tfidf_matrix).flatten()
# 获取最相似的内容索引
similar_indices = cosine_similarities.argsort()[::-1][:top_n]
# 构造搜索结果
results = self.content_data.iloc[similar_indices][
['id', 'title', 'description']
].copy()
results['similarity_score'] = cosine_similarities[similar_indices]
return results.sort_values('similarity_score', ascending=False)
def save_model(self, model_path):
"""
保存模型
Args:
model_path (str): 模型保存路径
"""
model_data = {
'content_data': self.content_data,
'tfidf_matrix': self.tfidf_matrix,
'tfidf_vectorizer': self.tfidf_vectorizer
}
with open(model_path, 'wb') as f:
pickle.dump(model_data, f)
print(f"模型已保存到 {model_path}")
def load_model(self, model_path):
"""
加载模型
Args:
model_path (str): 模型文件路径
"""
with open(model_path, 'rb') as f:
model_data = pickle.load(f)
self.content_data = model_data['content_data']
self.tfidf_matrix = model_data['tfidf_matrix']
self.tfidf_vectorizer = model_data['tfidf_vectorizer']
self.is_trained = True
print(f"模型已从 {model_path} 加载")
# 使用示例
def demo_recommendation_system():
"""
演示推荐系统
"""
# 创建推荐系统实例
recommender = ContentRecommendationSystem()
# 模拟内容数据
sample_data = pd.DataFrame({
'id': range(1, 11),
'title': [
'Python 机器学习入门',
'深度学习实战教程',
'数据分析与可视化',
'Web 开发全栈指南',
'移动应用开发技术',
'人工智能前沿研究',
'大数据处理技术',
'云计算架构设计',
'网络安全防护策略',
'区块链技术原理'
],
'description': [
'介绍机器学习基础概念和 Python 实现',
'深入讲解深度学习模型和应用案例',
'数据处理、分析和可视化技术',
'前端后端全栈开发技术详解',
'iOS 和 Android 应用开发指南',
'最新 AI 研究成果和应用前景',
'Hadoop、Spark 等大数据技术',
'云原生架构和微服务设计',
'网络安全威胁和防护措施',
'区块链技术原理和应用场景'
],
'category': [
'机器学习', '深度学习', '数据分析', 'Web开发', '移动开发',
'人工智能', '大数据', '云计算', '网络安全', '区块链'
]
})
# 保存示例数据
sample_data.to_csv('sample_content.csv', index=False)
# 加载数据
recommender.load_content_data('sample_content.csv')
# 准备特征
recommender.prepare_content_features(['title', 'description', 'category'])
# 获取推荐
print("为内容 'Python 机器学习入门' 推荐相关内容:")
recommendations = recommender.get_recommendations(content_id=1, top_n=3)
print(recommendations)
# 搜索内容
print("\n搜索 '深度学习' 相关内容:")
search_results = recommender.search_content('深度学习', top_n=3)
print(search_results)
# 运行演示
# demo_recommendation_system()
10. 项目实施计划
10.1 甘特图
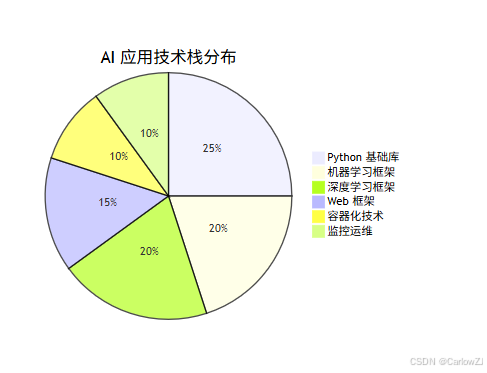
10.2 技术栈分布
11. 注意事项
11.1 数据隐私与安全
在开发 AI 应用时,数据隐私和安全是首要考虑的问题:
import hashlib
import base64
from cryptography.fernet import Fernet
class DataSecurityManager:
"""
数据安全管理器
"""
def __init__(self, encryption_key=None):
"""
初始化数据安全管理器
Args:
encryption_key (bytes): 加密密钥
"""
if encryption_key is None:
encryption_key = Fernet.generate_key()
self.cipher_suite = Fernet(encryption_key)
def encrypt_data(self, data):
"""
加密数据
Args:
data (str): 待加密数据
Returns:
str: 加密后的数据
"""
encrypted_data = self.cipher_suite.encrypt(data.encode())
return base64.urlsafe_b64encode(encrypted_data).decode()
def decrypt_data(self, encrypted_data):
"""
解密数据
Args:
encrypted_data (str): 加密数据
Returns:
str: 解密后的数据
"""
encrypted_bytes = base64.urlsafe_b64decode(encrypted_data.encode())
decrypted_data = self.cipher_suite.decrypt(encrypted_bytes)
return decrypted_data.decode()
def hash_sensitive_data(self, data):
"""
对敏感数据进行哈希处理
Args:
data (str): 敏感数据
Returns:
str: 哈希值
"""
return hashlib.sha256(data.encode()).hexdigest()
# 使用示例
# security_manager = DataSecurityManager()
# encrypted = security_manager.encrypt_data("敏感信息")
# decrypted = security_manager.decrypt_data(encrypted)
# hashed = security_manager.hash_sensitive_data("用户ID")
11.2 模型性能优化
优化模型性能以提高响应速度和准确性:
import time
from functools import wraps
def performance_monitor(func):
"""
性能监控装饰器
"""
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
execution_time = end_time - start_time
print(f"{func.__name__} 执行时间: {execution_time:.4f} 秒")
# 记录性能指标(可以集成到监控系统中)
# metrics.record_execution_time(func.__name__, execution_time)
return result
return wrapper
class ModelOptimizer:
"""
模型优化器
"""
def __init__(self, model):
"""
初始化模型优化器
Args:
model: 待优化的模型
"""
self.model = model
self.cache = {}
@performance_monitor
def predict_with_cache(self, input_data):
"""
带缓存的预测方法
Args:
input_data: 输入数据
Returns:
预测结果
"""
# 将输入数据转换为可哈希的键
data_key = self._generate_key(input_data)
# 检查缓存
if data_key in self.cache:
print("从缓存中获取结果")
return self.cache[data_key]
# 执行预测
result = self.model.predict(input_data)
# 存储到缓存
self.cache[data_key] = result
return result
def _generate_key(self, data):
"""
生成数据键值
Args:
data: 输入数据
Returns:
str: 数据键值
"""
# 简化的键生成方法,实际应用中可能需要更复杂的实现
return str(hash(str(data)))
# 使用示例
# optimizer = ModelOptimizer(trained_model)
# result = optimizer.predict_with_cache(input_data)
12. 最佳实践
12.1 持续集成与部署
使用 GitHub Actions 实现 CI/CD:
# .github/workflows/ci-cd.yml
name: AI 应用 CI/CD
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: 设置 Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: 安装依赖
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: 运行测试
run: |
pytest tests/
- name: 代码质量检查
run: |
flake8 .
black --check .
build-and-deploy:
needs: test
runs-on: ubuntu-latest
if: github.ref == 'refs/heads/main'
steps:
- uses: actions/checkout@v3
- name: 构建 Docker 镜像
run: |
docker build -t ai-app:${{ github.sha }} .
docker tag ai-app:${{ github.sha }} your-registry/ai-app:latest
- name: 登录到镜像仓库
run: echo "${{ secrets.DOCKER_PASSWORD }}" | docker login -u ${{ secrets.DOCKER_USERNAME }} --password-stdin
- name: 推送镜像
run: |
docker push your-registry/ai-app:latest
- name: 部署到 Kubernetes
run: |
kubectl set image deployment/ai-app ai-app=your-registry/ai-app:${{ github.sha }}
12.2 配置管理
使用配置文件管理应用设置:
import os
import yaml
from typing import Dict, Any
class ConfigManager:
"""
配置管理器
"""
def __init__(self, config_path: str = "config.yaml"):
"""
初始化配置管理器
Args:
config_path (str): 配置文件路径
"""
self.config_path = config_path
self.config = self._load_config()
def _load_config(self) -> Dict[str, Any]:
"""
加载配置文件
Returns:
dict: 配置字典
"""
# 默认配置
default_config = {
"app": {
"name": "AI Application",
"version": "1.0.0",
"debug": False
},
"model": {
"path": "models/model.pkl",
"type": "scikit-learn"
},
"api": {
"host": "0.0.0.0",
"port": 5000,
"workers": 4
},
"database": {
"host": "localhost",
"port": 5432,
"name": "ai_app",
"user": "ai_user"
},
"redis": {
"host": "localhost",
"port": 6379,
"db": 0
},
"logging": {
"level": "INFO",
"file": "logs/app.log",
"max_bytes": 10485760,
"backup_count": 5
}
}
# 如果配置文件存在,加载并合并
if os.path.exists(self.config_path):
with open(self.config_path, 'r', encoding='utf-8') as f:
file_config = yaml.safe_load(f)
default_config.update(file_config)
# 环境变量覆盖
default_config = self._override_with_env(default_config)
return default_config
def _override_with_env(self, config: Dict[str, Any]) -> Dict[str, Any]:
"""
使用环境变量覆盖配置
Args:
config (dict): 原始配置
Returns:
dict: 更新后的配置
"""
# 定义环境变量映射
env_mapping = {
"APP_DEBUG": ("app", "debug"),
"API_HOST": ("api", "host"),
"API_PORT": ("api", "port"),
"MODEL_PATH": ("model", "path"),
"DATABASE_HOST": ("database", "host"),
"REDIS_HOST": ("redis", "host")
}
for env_var, (section, key) in env_mapping.items():
value = os.getenv(env_var)
if value is not None:
# 类型转换
if value.lower() in ('true', 'false'):
value = value.lower() == 'true'
elif value.isdigit():
value = int(value)
config[section][key] = value
return config
def get(self, key_path: str, default=None):
"""
获取配置值
Args:
key_path (str): 配置键路径,如 "app.name"
default: 默认值
Returns:
配置值
"""
keys = key_path.split('.')
value = self.config
try:
for key in keys:
value = value[key]
return value
except (KeyError, TypeError):
return default
def set(self, key_path: str, value):
"""
设置配置值
Args:
key_path (str): 配置键路径
value: 配置值
"""
keys = key_path.split('.')
config = self.config
# 导航到倒数第二层
for key in keys[:-1]:
if key not in config:
config[key] = {}
config = config[key]
# 设置值
config[keys[-1]] = value
# 使用示例
# config = ConfigManager()
# app_name = config.get("app.name")
# debug_mode = config.get("app.debug", False)
13. 常见问题与解决方案
13.1 模型性能问题
问题: 模型预测速度慢
解决方案:
# 1. 使用模型量化
import tensorflow as tf
def quantize_model(model_path):
"""
量化模型以减小体积和提高速度
"""
converter = tf.lite.TFLiteConverter.from_saved_model(model_path)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with open('quantized_model.tflite', 'wb') as f:
f.write(tflite_model)
# 2. 使用模型缓存
from functools import lru_cache
@lru_cache(maxsize=1000)
def cached_prediction(input_data):
"""
缓存预测结果
"""
return model.predict(input_data)
13.2 部署问题
问题: Docker 容器启动失败
解决方案:
# 检查 Dockerfile 中的基础镜像和依赖
FROM python:3.9-slim
# 确保安装了所有必要的系统依赖
RUN apt-get update && apt-get install -y \
build-essential \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
# 检查依赖文件和安装命令
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
13.3 内存泄漏问题
问题: 应用运行时间长后内存占用过高
解决方案:
import gc
import psutil
import os
class MemoryManager:
"""
内存管理器
"""
@staticmethod
def get_memory_usage():
"""
获取当前进程内存使用情况
"""
process = psutil.Process(os.getpid())
memory_info = process.memory_info()
return {
'rss': memory_info.rss / 1024 / 1024, # MB
'vms': memory_info.vms / 1024 / 1024 # MB
}
@staticmethod
def force_garbage_collection():
"""
强制垃圾回收
"""
collected = gc.collect()
print(f"垃圾回收清理了 {collected} 个对象")
return collected
@staticmethod
def monitor_memory(threshold_mb=500):
"""
监控内存使用情况
Args:
threshold_mb (int): 内存使用阈值(MB)
"""
memory_usage = MemoryManager.get_memory_usage()
if memory_usage['rss'] > threshold_mb:
print(f"警告: 内存使用过高 ({memory_usage['rss']:.2f} MB)")
MemoryManager.force_garbage_collection()
# 在关键位置调用内存监控
# MemoryManager.monitor_memory()
14. 扩展阅读
14.1 推荐书籍
-
《Python 机器学习》 - Sebastian Raschka
- 全面介绍使用 Python 进行机器学习的方法和实践
-
《深度学习》 - Ian Goodfellow, Yoshua Bengio, Aaron Courville
- 深度学习领域的权威教材,理论深入
-
《流畅的 Python》 - Luciano Ramalho
- 提升 Python 编程技能的经典著作
-
《设计数据密集型应用》 - Martin Kleppmann
- 系统设计和数据处理的优秀参考书
14.2 在线资源
-
Kaggle (https://www.kaggle.com/)
- 数据科学竞赛平台,提供大量数据集和学习资源
-
Google AI Blog (https://ai.googleblog.com/)
- Google 的 AI 研究博客,了解最新技术进展
-
Papers With Code (https://paperswithcode.com/)
- 论文与代码实现的集合,便于学习最新算法
-
Towards Data Science (https://towardsdatascience.com/)
- Medium 上的数据科学专栏,大量高质量技术文章
15. 总结
本文全面介绍了基于 Python 的 AI 应用开发与部署的完整流程,涵盖了从环境搭建、数据处理、模型训练到应用部署、监控优化的各个环节。通过丰富的代码示例和实践案例,读者可以系统地掌握 AI 应用开发的核心技术。
关键技术要点回顾:
- 环境搭建: 使用 Anaconda 管理 Python 环境,安装必要的 AI 库
- 数据处理: 数据清洗、特征工程、标准化等预处理技术
- 模型开发: 传统机器学习和深度学习模型的构建与训练
- 应用部署: 使用 Flask 构建 RESTful API,Streamlit 创建 Web 界面
- 容器化: Docker 和 Kubernetes 实现应用容器化部署
- 监控运维: Prometheus 和 Grafana 实现系统监控
实践建议:
- 从简单开始: 初学者应从简单的项目开始,逐步增加复杂度
- 重视数据质量: 数据质量直接影响模型性能,投入足够时间进行数据清洗
- 持续学习: AI 领域发展迅速,需要持续关注新技术和方法
- 注重工程化: 将 AI 模型成功应用到生产环境需要良好的工程实践
通过本文的学习和实践,相信读者能够掌握基于 Python 的 AI 应用开发技能,并能够独立完成从概念到生产环境的完整项目开发。在实际工作中,还需要根据具体需求和场景进行调整和优化,不断积累经验,提升技术水平。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











