



摘要
在人工智能技术飞速发展的今天,构建功能强大且用户友好的AI聊天应用已成为许多开发者的需求。LobeChat作为一个开源、现代化设计的AI聊天框架,支持多种AI提供商(如OpenAI、Claude、Gemini、DeepSeek等)、知识库(文件上传、知识管理、RAG)、多模态(插件、工件)和思考能力。它还提供了一键免费部署私人ChatGPT/Claude/DeepSeek应用的功能。本文将深入探讨LobeChat的技术架构、核心功能实现以及最佳实践,通过详细的实践示例、架构图、流程图等可视化内容,帮助中国开发者快速掌握并应用LobeChat构建自己的AI聊天应用,提升开发效率和用户体验。
思维导图:LobeChat知识点全景
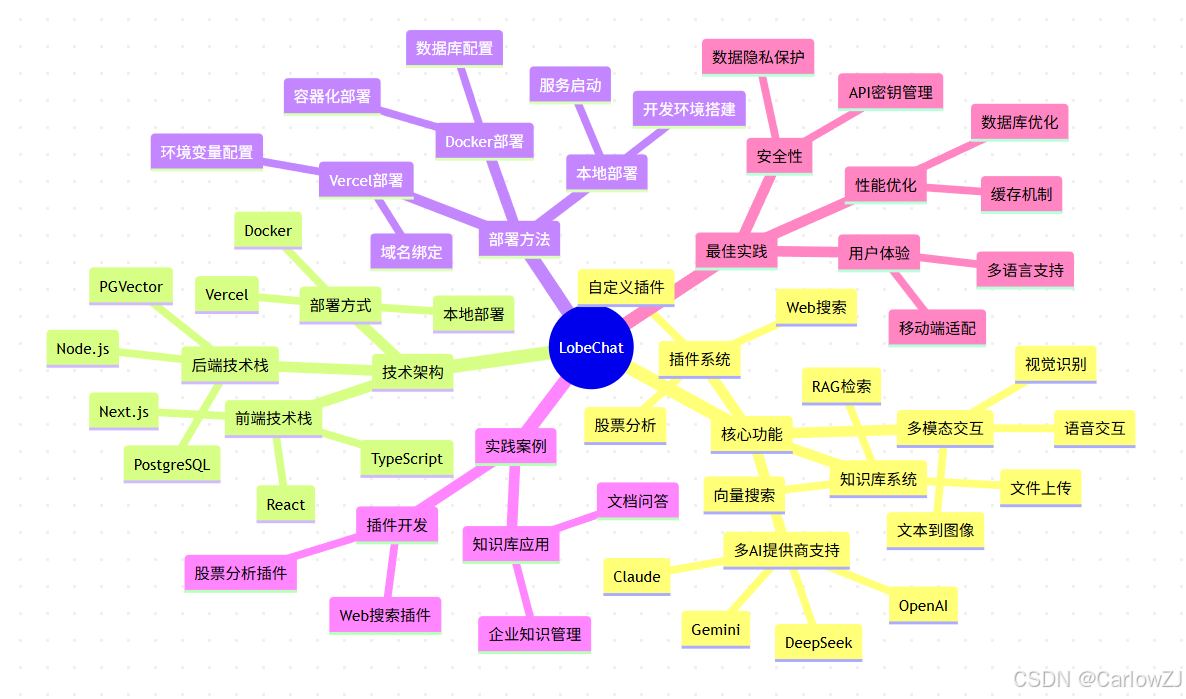
mindmap
root((LobeChat))
核心功能
多AI提供商支持
OpenAI
Claude
Gemini
DeepSeek
知识库系统
文件上传
RAG检索
向量搜索
多模态交互
文本到图像
语音交互
视觉识别
插件系统
Web搜索
股票分析
自定义插件
技术架构
前端技术栈
Next.js
TypeScript
React
后端技术栈
Node.js
PostgreSQL
PGVector
部署方式
Docker
Vercel
本地部署
部署方法
Vercel部署
环境变量配置
域名绑定
Docker部署
容器化部署
数据库配置
本地部署
开发环境搭建
服务启动
实践案例
插件开发
Web搜索插件
股票分析插件
知识库应用
文档问答
企业知识管理
最佳实践
安全性
API密钥管理
数据隐私保护
性能优化
缓存机制
数据库优化
用户体验
多语言支持
移动端适配
1. LobeChat核心功能详解
1.1 多AI提供商支持
LobeChat最突出的特点之一是支持多种AI提供商,这使得开发者和用户可以根据需求选择最适合的模型。主要支持的提供商包括:
- OpenAI:提供GPT系列模型,包括最新的GPT-4和GPT-3.5系列
- Claude:Anthropic提供的先进语言模型,以安全性和可控性著称
- Gemini:Google的多模态AI模型,支持文本、图像等多种输入
- DeepSeek:国内领先的AI公司,提供强大的对话和代码处理能力
- Ollama:支持本地部署的大语言模型,保障数据隐私和安全
1.2 知识库与RAG系统
LobeChat的知识库系统基于检索增强生成(RAG)技术,允许用户上传各种类型的文件并创建知识库,使AI能够基于私有信息生成回答。
# 知识库处理流程示例
import os
from typing import List
import PyPDF2
import docx
class DocumentProcessor:
"""
文档处理器,用于处理不同格式的文档
"""
def __init__(self):
self.supported_formats = ['.pdf', '.docx', '.txt']
def process_document(self, file_path: str) -> List[str]:
"""
处理文档并提取文本内容
:param file_path: 文档路径
:return: 文本内容列表
"""
_, ext = os.path.splitext(file_path)
if ext not in self.supported_formats:
raise ValueError(f"不支持的文件格式: {ext}")
if ext == '.pdf':
return self._process_pdf(file_path)
elif ext == '.docx':
return self._process_docx(file_path)
elif ext == '.txt':
return self._process_txt(file_path)
def _process_pdf(self, file_path: str) -> List[str]:
"""
处理PDF文件
:param file_path: PDF文件路径
:return: 文本内容列表
"""
text_chunks = []
try:
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
for page in pdf_reader.pages:
text = page.extract_text()
if text.strip():
# 将文本按段落分割
paragraphs = text.split('\n\n')
text_chunks.extend([p for p in paragraphs if p.strip()])
except Exception as e:
print(f"处理PDF文件时出错: {e}")
return text_chunks
def _process_docx(self, file_path: str) -> List[str]:
"""
处理Word文档
:param file_path: Word文档路径
:return: 文本内容列表
"""
text_chunks = []
try:
doc = docx.Document(file_path)
for paragraph in doc.paragraphs:
if paragraph.text.strip():
text_chunks.append(paragraph.text)
except Exception as e:
print(f"处理Word文档时出错: {e}")
return text_chunks
def _process_txt(self, file_path: str) -> List[str]:
"""
处理文本文件
:param file_path: 文本文件路径
:return: 文本内容列表
"""
text_chunks = []
try:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 按段落分割
paragraphs = content.split('\n\n')
text_chunks.extend([p for p in paragraphs if p.strip()])
except Exception as e:
print(f"处理文本文件时出错: {e}")
return text_chunks
# 使用示例
if __name__ == "__main__":
processor = DocumentProcessor()
# 处理示例文档(需要实际文件)
# chunks = processor.process_document("example.pdf")
# print(f"提取了 {len(chunks)} 个文本块")
# for i, chunk in enumerate(chunks[:3]): # 显示前3个块
# print(f"块 {i+1}: {chunk[:100]}...")
print("文档处理器已准备就绪")
1.3 多模态支持
LobeChat支持多模态交互,包括文本到图像生成、语音交互和视觉识别等功能:
import requests
import base64
from typing import Optional
class MultimodalProcessor:
"""
多模态处理器,支持图像生成和语音处理
"""
def __init__(self, openai_api_key: str):
self.api_key = openai_api_key
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
def generate_image(self, prompt: str, size: str = "1024x1024") -> Optional[str]:
"""
使用DALL-E生成图像
:param prompt: 图像描述
:param size: 图像尺寸
:return: 图像URL
"""
url = "https://api.openai.com/v1/images/generations"
payload = {
"model": "dall-e-3",
"prompt": prompt,
"n": 1,
"size": size
}
try:
response = requests.post(url, headers=self.headers, json=payload)
response.raise_for_status()
data = response.json()
return data["data"][0]["url"]
except requests.exceptions.RequestException as e:
print(f"生成图像时出错: {e}")
return None
def text_to_speech(self, text: str, voice: str = "alloy") -> Optional[bytes]:
"""
文本转语音
:param text: 要转换的文本
:param voice: 声音类型
:return: 音频数据
"""
url = "https://api.openai.com/v1/audio/speech"
payload = {
"model": "tts-1",
"input": text,
"voice": voice
}
try:
response = requests.post(url, headers=self.headers, json=payload)
response.raise_for_status()
return response.content
except requests.exceptions.RequestException as e:
print(f"文本转语音时出错: {e}")
return None
def speech_to_text(self, audio_file_path: str) -> Optional[str]:
"""
语音转文本
:param audio_file_path: 音频文件路径
:return: 识别的文本
"""
url = "https://api.openai.com/v1/audio/transcriptions"
try:
with open(audio_file_path, "rb") as audio_file:
files = {
"file": audio_file,
"model": (None, "whisper-1")
}
response = requests.post(url, headers=self.headers, files=files)
response.raise_for_status()
data = response.json()
return data["text"]
except requests.exceptions.RequestException as e:
print(f"语音转文本时出错: {e}")
return None
# 使用示例(需要实际的API密钥)
# multimodal = MultimodalProcessor("your-openai-api-key")
# image_url = multimodal.generate_image("一只可爱的猫咪在花园里玩耍")
# if image_url:
# print(f"生成的图像URL: {image_url}")
1.4 插件系统
LobeChat提供了强大的插件系统,支持动态加载和扩展功能:
import requests
import yfinance as yf
from typing import Dict, Any, Optional
class LobeChatPlugin:
"""
LobeChat插件基类
"""
def __init__(self, name: str):
self.name = name
def execute(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""
执行插件功能
:param params: 插件参数
:return: 执行结果
"""
raise NotImplementedError("子类必须实现execute方法")
class WebSearchPlugin(LobeChatPlugin):
"""
Web搜索插件
"""
def __init__(self, bing_api_key: str):
super().__init__("Web搜索")
self.api_key = bing_api_key
def execute(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""
执行Web搜索
:param params: 搜索参数
:return: 搜索结果
"""
query = params.get("query", "")
if not query:
return {"error": "缺少搜索关键词"}
url = f"https://api.bing.microsoft.com/v7.0/search?q={query}"
headers = {"Ocp-Apim-Subscription-Key": self.api_key}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
search_results = []
for result in data.get("webPages", {}).get("value", [])[:5]:
search_results.append({
"title": result.get("name", ""),
"url": result.get("url", ""),
"snippet": result.get("snippet", "")
})
return {
"results": search_results,
"total_results": data.get("webPages", {}).get("totalEstimatedMatches", 0)
}
except requests.exceptions.RequestException as e:
return {"error": f"搜索失败: {str(e)}"}
class StockAnalysisPlugin(LobeChatPlugin):
"""
股票分析插件
"""
def __init__(self):
super().__init__("股票分析")
def execute(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""
执行股票分析
:param params: 股票参数
:return: 股票数据
"""
symbol = params.get("symbol", "")
if not symbol:
return {"error": "缺少股票代码"}
try:
stock = yf.Ticker(symbol)
info = stock.info
# 获取关键信息
result = {
"symbol": symbol,
"company_name": info.get("longName", "未知"),
"current_price": info.get("currentPrice", 0),
"previous_close": info.get("previousClose", 0),
"day_high": info.get("dayHigh", 0),
"day_low": info.get("dayLow", 0),
"volume": info.get("volume", 0),
"market_cap": info.get("marketCap", 0),
"pe_ratio": info.get("trailingPE", 0)
}
# 计算涨跌幅
if result["previous_close"] and result["current_price"]:
change = result["current_price"] - result["previous_close"]
change_percent = (change / result["previous_close"]) * 100
result["change"] = round(change, 2)
result["change_percent"] = round(change_percent, 2)
return result
except Exception as e:
return {"error": f"获取股票数据失败: {str(e)}"}
# 插件管理器
class PluginManager:
"""
插件管理器
"""
def __init__(self):
self.plugins = {}
def register_plugin(self, plugin: LobeChatPlugin):
"""
注册插件
:param plugin: 插件实例
"""
self.plugins[plugin.name] = plugin
def execute_plugin(self, plugin_name: str, params: Dict[str, Any]) -> Dict[str, Any]:
"""
执行插件
:param plugin_name: 插件名称
:param params: 插件参数
:return: 执行结果
"""
plugin = self.plugins.get(plugin_name)
if not plugin:
return {"error": f"未找到插件: {plugin_name}"}
return plugin.execute(params)
# 使用示例
if __name__ == "__main__":
# 创建插件管理器
plugin_manager = PluginManager()
# 注册插件(需要实际的API密钥)
# web_search_plugin = WebSearchPlugin("your-bing-api-key")
# plugin_manager.register_plugin(web_search_plugin)
stock_plugin = StockAnalysisPlugin()
plugin_manager.register_plugin(stock_plugin)
print("插件系统已准备就绪")
2. LobeChat架构设计
2.1 系统架构图
2.2 技术栈
LobeChat采用了现代化的技术栈:
- 前端:Next.js + TypeScript + React
- 后端:Node.js + Express
- 数据库:PostgreSQL + PGVector(用于向量搜索)
- 部署:Docker容器化部署
3. 部署方法详解
3.1 Vercel部署
Vercel部署是最简单的部署方式,适合快速体验LobeChat:
# 1. 克隆仓库
git clone https://github.com/lobehub/lobe-chat.git
cd lobe-chat
# 2. 安装依赖
pnpm install
# 3. 构建项目
pnpm build
# 4. 部署到Vercel
# 使用Vercel CLI或通过GitHub集成部署
环境变量配置:
# 必需的环境变量
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ACCESS_CODE=your-access-code # 可选,用于访问控制
# 可选的环境变量
OPENAI_PROXY_URL=https://api.openai.com/v1 # API代理地址
DEFAULT_AGENT_CONFIG={"provider":"openai","model":"gpt-3.5-turbo"} # 默认模型配置
3.2 Docker部署
Docker部署适合生产环境,提供更好的可控性和扩展性:
# 1. 拉取Docker镜像
docker pull lobehub/lobe-chat:latest
# 2. 运行容器
docker run -d \
--name lobe-chat \
-p 3210:3210 \
-e OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
-e ACCESS_CODE=your-access-code \
lobehub/lobe-chat:latest
3.3 数据库版部署
对于需要知识库功能的场景,需要部署数据库版本:
# 1. 创建Docker网络
docker network create lobe-chat-network
# 2. 启动PostgreSQL数据库
docker run -d \
--name lobe-chat-db \
--network lobe-chat-network \
-e POSTGRES_DB=lobechat \
-e POSTGRES_USER=lobechat \
-e POSTGRES_PASSWORD=lobechat_password \
-v lobe-chat-db:/var/lib/postgresql/data \
postgres:15
# 3. 安装PGVector扩展
docker exec -it lobe-chat-db psql -U lobechat -d lobechat -c "CREATE EXTENSION IF NOT EXISTS vector;"
# 4. 启动LobeChat服务
docker run -d \
--name lobe-chat \
--network lobe-chat-network \
-p 3210:3210 \
-e DATABASE_URL=postgresql://lobechat:lobechat_password@lobe-chat-db:5432/lobechat \
-e OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
lobehub/lobe-chat:database-latest
3.4 本地开发部署
本地开发部署适合开发者进行二次开发:
# 1. 克隆仓库
git clone https://github.com/lobehub/lobe-chat.git
cd lobe-chat
# 2. 安装依赖
pnpm install
# 3. 配置环境变量
cp .env.example .env
# 编辑 .env 文件,填入必要的环境变量
# 4. 启动开发服务器
pnpm dev
4. 实践案例
4.1 自定义插件开发
以下是一个完整的自定义插件开发示例:
import requests
import json
from typing import Dict, Any
class WeatherPlugin:
"""
天气查询插件
"""
def __init__(self, api_key: str):
self.api_key = api_key
self.base_url = "http://api.openweathermap.org/data/2.5/weather"
def get_manifest(self) -> Dict[str, Any]:
"""
获取插件清单
"""
return {
"api": {
"url": "http://localhost:8000/weather",
"method": "POST"
},
"identifier": "weather_query",
"name": "天气查询",
"description": "查询指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
}
},
"required": ["city"]
}
}
def execute(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""
执行天气查询
:param params: 查询参数
:return: 天气信息
"""
city = params.get("city", "")
if not city:
return {"error": "缺少城市名称"}
try:
# 调用天气API
url = f"{self.base_url}?q={city}&appid={self.api_key}&units=metric&lang=zh_cn"
response = requests.get(url)
response.raise_for_status()
data = response.json()
# 提取关键信息
weather_info = {
"city": data["name"],
"country": data["sys"]["country"],
"temperature": data["main"]["temp"],
"feels_like": data["main"]["feels_like"],
"humidity": data["main"]["humidity"],
"description": data["weather"][0]["description"],
"wind_speed": data["wind"]["speed"]
}
return {
"result": weather_info,
"message": f"{weather_info['city']}当前天气:{weather_info['description']},温度{weather_info['temperature']}°C,湿度{weather_info['humidity']}%"
}
except requests.exceptions.RequestException as e:
return {"error": f"获取天气信息失败: {str(e)}"}
except KeyError as e:
return {"error": f"解析天气数据失败: {str(e)}"}
# Flask API服务示例
from flask import Flask, request, jsonify
app = Flask(__name__)
# 初始化插件(需要实际的API密钥)
# weather_plugin = WeatherPlugin("your-openweathermap-api-key")
@app.route('/weather', methods=['POST'])
def weather_api():
"""
天气查询API端点
"""
try:
params = request.json
# result = weather_plugin.execute(params)
# 由于缺少实际API密钥,返回模拟数据
result = {
"result": {
"city": params.get("city", "北京"),
"country": "CN",
"temperature": 22,
"feels_like": 23,
"humidity": 65,
"description": "晴",
"wind_speed": 3.5
},
"message": "北京当前天气:晴,温度22°C,湿度65%"
}
return jsonify(result)
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000, debug=True)
4.2 知识库应用案例
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from typing import List, Tuple
class SimpleRAGSystem:
"""
简单的RAG系统实现
"""
def __init__(self):
self.documents = []
self.vectorizer = TfidfVectorizer()
self.document_vectors = None
def add_documents(self, documents: List[str]):
"""
添加文档到知识库
:param documents: 文档列表
"""
self.documents.extend(documents)
# 重新计算向量
self.document_vectors = self.vectorizer.fit_transform(self.documents)
def search_similar_documents(self, query: str, top_k: int = 3) -> List[Tuple[int, float, str]]:
"""
搜索相似文档
:param query: 查询文本
:param top_k: 返回最相似的K个文档
:return: (索引, 相似度, 文档内容)元组列表
"""
if self.document_vectors is None or len(self.documents) == 0:
return []
# 将查询转换为向量
query_vector = self.vectorizer.transform([query])
# 计算相似度
similarities = cosine_similarity(query_vector, self.document_vectors).flatten()
# 获取最相似的文档
top_indices = np.argsort(similarities)[::-1][:top_k]
results = []
for idx in top_indices:
if similarities[idx] > 0: # 只返回相似度大于0的文档
results.append((idx, similarities[idx], self.documents[idx]))
return results
# 使用示例
if __name__ == "__main__":
# 创建RAG系统
rag = SimpleRAGSystem()
# 添加示例文档
sample_documents = [
"人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。",
"机器学习是人工智能的一个子集,它使计算机能够从数据中学习并做出决策或预测。",
"深度学习是机器学习的一个分支,它模仿人脑的工作方式来处理数据和创建模式,用于决策制定。",
"自然语言处理是人工智能的一个领域,专注于计算机与人类语言之间的交互,特别是如何编程计算机来处理和分析大量的自然语言数据。",
"计算机视觉是人工智能的一个领域,它训练计算机解释和理解视觉世界,使用摄像头、数据和算法来尝试自动识别和理解图像。",
"Python是一种高级编程语言,因其简洁易读的语法和强大的库生态系统而广泛用于数据科学和人工智能领域。"
]
rag.add_documents(sample_documents)
# 查询示例
query = "什么是深度学习?"
results = rag.search_similar_documents(query, top_k=3)
print(f"查询: {query}")
print("相似文档:")
for i, (idx, similarity, doc) in enumerate(results, 1):
print(f"{i}. 相似度: {similarity:.4f}")
print(f" 内容: {doc}")
print()
5. 注意事项与最佳实践
5.1 安全性考虑
import os
import secrets
from typing import Optional
class SecurityManager:
"""
安全管理器
"""
def __init__(self):
self.access_tokens = {}
def generate_access_token(self, user_id: str) -> str:
"""
生成访问令牌
:param user_id: 用户ID
:return: 访问令牌
"""
token = secrets.token_urlsafe(32)
self.access_tokens[token] = user_id
return token
def validate_token(self, token: str) -> Optional[str]:
"""
验证访问令牌
:param token: 访问令牌
:return: 用户ID或None
"""
return self.access_tokens.get(token)
def revoke_token(self, token: str):
"""
撤销访问令牌
:param token: 访问令牌
"""
if token in self.access_tokens:
del self.access_tokens[token]
# API密钥安全存储示例
class APIKeyManager:
"""
API密钥管理器
"""
def __init__(self):
self.encrypted_keys = {}
def store_api_key(self, provider: str, api_key: str):
"""
安全存储API密钥
:param provider: AI提供商
:param api_key: API密钥
"""
# 在实际应用中,应该使用加密存储
# 这里仅作示例
self.encrypted_keys[provider] = self._encrypt(api_key)
def get_api_key(self, provider: str) -> Optional[str]:
"""
获取API密钥
:param provider: AI提供商
:return: 解密后的API密钥
"""
encrypted_key = self.encrypted_keys.get(provider)
if encrypted_key:
return self._decrypt(encrypted_key)
return None
def _encrypt(self, data: str) -> str:
"""
加密数据(示例实现)
:param data: 要加密的数据
:return: 加密后的数据
"""
# 在实际应用中,应该使用强加密算法
# 这里仅作示例
return f"encrypted_{data}"
def _decrypt(self, data: str) -> str:
"""
解密数据(示例实现)
:param data: 要解密的数据
:return: 解密后的数据
"""
# 在实际应用中,应该使用对应的解密算法
# 这里仅作示例
return data.replace("encrypted_", "")
# 环境变量安全检查
def check_environment_security():
"""
检查环境变量安全性
"""
required_vars = ["OPENAI_API_KEY"]
missing_vars = [var for var in required_vars if not os.getenv(var)]
if missing_vars:
print(f"警告: 缺少必要的环境变量: {', '.join(missing_vars)}")
return False
# 检查API密钥格式
openai_key = os.getenv("OPENAI_API_KEY", "")
if openai_key and not openai_key.startswith("sk-"):
print("警告: OpenAI API密钥格式可能不正确")
return False
print("环境变量安全检查通过")
return True
# 使用示例
if __name__ == "__main__":
# 检查环境安全性
check_environment_security()
# 创建安全管理器
security_manager = SecurityManager()
token = security_manager.generate_access_token("user123")
print(f"生成的访问令牌: {token}")
# 验证令牌
user_id = security_manager.validate_token(token)
print(f"验证的用户ID: {user_id}")
5.2 性能优化建议
import functools
import time
from typing import Any, Callable
def cache_result(expiration_time: int = 300):
"""
缓存装饰器
:param expiration_time: 缓存过期时间(秒)
"""
def decorator(func: Callable) -> Callable:
cache = {}
@functools.wraps(func)
def wrapper(*args, **kwargs) -> Any:
# 创建缓存键
key = str(args) + str(sorted(kwargs.items()))
current_time = time.time()
# 检查缓存
if key in cache:
result, timestamp = cache[key]
if current_time - timestamp < expiration_time:
print(f"缓存命中: {func.__name__}")
return result
else:
# 缓存过期,删除
del cache[key]
# 执行函数并缓存结果
result = func(*args, **kwargs)
cache[key] = (result, current_time)
print(f"缓存已更新: {func.__name__}")
return result
return wrapper
return decorator
class PerformanceOptimizer:
"""
性能优化器
"""
def __init__(self):
self.request_count = 0
self.cache_hits = 0
@cache_result(expiration_time=600) # 缓存10分钟
def expensive_operation(self, param: str) -> str:
"""
模拟耗时操作
:param param: 参数
:return: 结果
"""
# 模拟耗时操作
time.sleep(2)
return f"处理结果: {param}"
def batch_process(self, items: list, batch_size: int = 10) -> list:
"""
批量处理
:param items: 待处理项目
:param batch_size: 批次大小
:return: 处理结果
"""
results = []
for i in range(0, len(items), batch_size):
batch = items[i:i+batch_size]
# 模拟批量处理
batch_results = [f"处理: {item}" for item in batch]
results.extend(batch_results)
print(f"处理批次 {i//batch_size + 1}: {len(batch)} 个项目")
return results
# 使用示例
if __name__ == "__main__":
optimizer = PerformanceOptimizer()
# 测试缓存功能
print("第一次调用:")
result1 = optimizer.expensive_operation("测试参数")
print(result1)
print("\n第二次调用(应该命中缓存):")
result2 = optimizer.expensive_operation("测试参数")
print(result2)
# 测试批量处理
items = [f"项目{i}" for i in range(25)]
print(f"\n批量处理 {len(items)} 个项目:")
batch_results = optimizer.batch_process(items, batch_size=8)
print(f"处理完成,共 {len(batch_results)} 个结果")
6. 常见问题解答
6.1 部署相关问题
Q: 如何解决Git克隆失败的问题?
A: 如果在克隆LobeChat仓库时遇到"Encountered end of file"错误,可以尝试以下方法:
- 检查网络连接是否稳定
- 使用代理工具(如VPN或SSH代理)
- 确保Git版本为最新
- 直接从GitHub页面下载仓库的ZIP文件
# 方法1: 增加Git缓冲区大小
git config --global http.postBuffer 524288000
# 方法2: 使用浅克隆
git clone --depth 1 https://github.com/lobehub/lobe-chat.git
# 方法3: 配置代理(如果需要)
git config --global http.proxy http://proxy.server:port
Q: 如何更新已部署的LobeChat项目?
A: 如果使用Vercel部署,可以通过以下步骤更新项目:
- 在GitHub仓库中拉取最新代码
- 更新环境变量(如
OPENAI_API_KEY) - 重新部署项目
# 本地更新步骤
git pull origin main
pnpm install
pnpm build
# Docker更新步骤
docker pull lobehub/lobe-chat:latest
docker stop lobe-chat
docker rm lobe-chat
docker run -d --name lobe-chat -p 3210:3210 lobehub/lobe-chat:latest
6.2 功能使用问题
Q: 如何配置不同的AI提供商?
A: LobeChat支持多种AI提供商,可以通过环境变量或界面配置:
# OpenAI配置
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_PROXY_URL=https://api.openai.com/v1
# Claude配置
ANTHROPIC_API_KEY=your-anthropic-api-key
# Gemini配置
GOOGLE_API_KEY=your-google-api-key
# Ollama配置(本地模型)
OLLAMA_HOST=http://localhost:11434
Q: 知识库功能无法使用怎么办?
A: 知识库功能需要数据库支持,请确保:
- 使用数据库版本部署
- PostgreSQL数据库正常运行
- PGVector扩展已安装
- 数据库连接配置正确
# 检查PGVector扩展
docker exec -it lobe-chat-db psql -U lobechat -d lobechat -c "SELECT * FROM pg_extension WHERE extname = 'vector';"
# 如果未安装,执行安装命令
docker exec -it lobe-chat-db psql -U lobechat -d lobechat -c "CREATE EXTENSION IF NOT EXISTS vector;"
7. 扩展阅读
7.1 相关技术栈
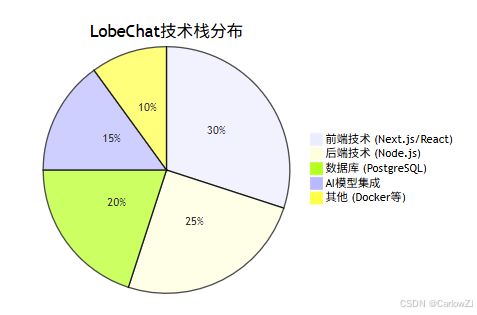
7.2 学习资源推荐
实施计划甘特图
交互流程时序图
总结
LobeChat作为一个开源、现代化设计的AI聊天框架,为开发者提供了构建AI聊天应用的强大工具。通过本文的详细介绍,我们了解了LobeChat的核心功能、技术架构、部署方法以及最佳实践。
关键要点回顾
-
多AI提供商支持:LobeChat支持OpenAI、Claude、Gemini、DeepSeek等多种AI提供商,满足不同场景需求。
-
知识库与RAG系统:基于检索增强生成技术,使AI能够基于私有数据生成回答,提升应用的专业性。
-
多模态交互:支持文本到图像生成、语音交互和视觉识别等多模态功能,丰富用户体验。
-
插件系统:灵活的插件架构允许开发者扩展功能,满足特定业务需求。
-
多种部署方式:支持Vercel、Docker和本地部署,适应不同环境需求。
实践建议
-
选择合适的部署方式:根据实际需求选择Vercel快速部署或Docker生产部署。
-
重视安全性:妥善管理API密钥,实施访问控制和数据加密。
-
优化性能:合理使用缓存机制,优化数据库查询和AI调用。
-
持续集成:建立自动化部署和测试流程,确保应用稳定运行。
未来展望
随着AI技术的不断发展,LobeChat也将持续演进:
- 更多AI模型支持:集成更多国内外主流AI模型
- 增强知识库功能:提供更智能的文档处理和检索能力
- 改进插件生态:建立更丰富的插件市场
- 优化用户体验:提供更直观的界面和交互方式
通过正确应用LobeChat,开发者可以快速构建功能强大、用户体验优秀的AI聊天应用,为用户提供智能化的服务体验。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











