






摘要
LobeChat Agent系统通过推理链(Chain of Thought)、思维链(Reasoning)和灵活的工作流机制,极大提升了AI对复杂任务的处理能力。本文结合源码与实际案例,系统讲解Agent推理链的原理、实现与最佳实践,助力开发者高效构建智能对话应用。
目录
- Agent与传统“话题”模型的区别
- Agent推理链(Chain of Thought)机制详解
- 源码解读:推理链的实现与扩展
- 工作流(Workflow)与多步任务处理
- 实战案例:自定义推理链Agent
- Python代码示例(含中文注释)
- Mermaid架构图/流程图/思维导图
- 常见问题与最佳实践
- 参考资料
1. Agent与传统“话题”模型的区别
- ChatGPT仅有“话题”概念,历史会话分散,重复任务效率低。
- LobeChat引入“Agent+话题”双层结构,每个Agent独立承担任务,拥有专属历史与配置,极大提升多任务与高频任务的效率。
2. Agent推理链(Chain of Thought)机制详解
- 推理链让AI具备“分步思考”能力,适合复杂推理、决策、规划等场景。
- 相关配置项:
enableReasoning:是否启用推理链reasoningEffort:推理强度(low/medium/high)reasoningBudgetToken:推理token预算
- 支持多轮推理、思维链流转,提升AI输出的逻辑性和可解释性。
3. 源码解读:推理链的实现与扩展
- 关键流程:
- 前端通过
createAssistantMessage发起请求,参数中可携带推理链相关配置 - 后端
/webapi/chat/[provider]路由接收,初始化AgentRuntime - 推理链消息流转与状态管理见
generateAIChat、chainAnswerWithContext等源码
- 前端通过
- 相关TypeScript类型:
LobeAgentChatConfig、ModelReasoning等
4. 工作流(Workflow)与多步任务处理
- Agent可串联多步任务,结合插件/工具调用,实现复杂业务流程
- 支持RAG(检索增强生成)、多轮推理、插件调用等高级场景
- 工作流灵活可扩展,适合自动化、智能助手等应用
5. 实战案例:自定义推理链Agent
- 在Agent配置中启用推理链:
enableReasoning: truereasoningEffort: 'high'
- 复杂任务可拆解为多步推理,逐步引导AI输出
- 可结合知识库、插件等能力,提升Agent智能水平
6. Python代码示例(含中文注释)
import requests
# 向LobeChat后端API发送多步推理请求
def lobechat_chain_of_thought(api_url, messages, agent_id):
"""
发送推理链消息到LobeChat Agent
:param api_url: LobeChat后端API地址
:param messages: 消息历史(含多步推理内容)
:param agent_id: 目标Agent ID
:return: AI回复
"""
payload = {
"agentId": agent_id,
"messages": messages,
"enableReasoning": True, # 启用推理链
"reasoningEffort": "high"
}
try:
resp = requests.post(api_url, json=payload, timeout=30)
resp.raise_for_status()
return resp.json()
except Exception as e:
print("请求失败:", e)
return None
# 示例调用
if __name__ == "__main__":
api = "http://localhost:3210/webapi/chat/your-provider"
msgs = [{"role": "user", "content": "请分步推理如何写一个LobeChat插件"}]
result = lobechat_chain_of_thought(api, msgs, "agent-xxx")
print(result)
7. Mermaid架构图/流程图/思维导图
Agent推理链工作流流程图
Agent与话题关系思维导图
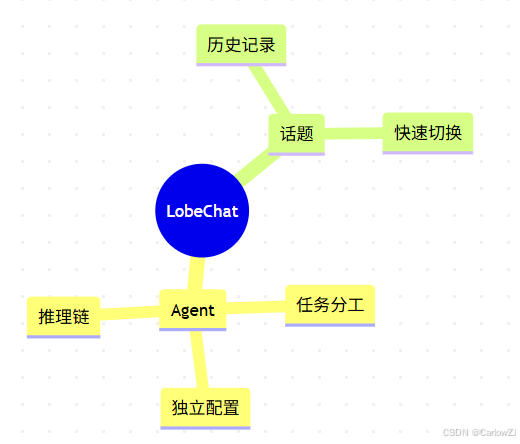
mindmap
root((LobeChat))
Agent
任务分工
独立配置
推理链
话题
历史记录
快速切换
8. 常见问题与最佳实践
- Q: 推理链会影响响应速度吗?
- A: 高推理强度下,AI会分步思考,响应略慢但更具逻辑性。
- Q: 如何调试多步推理?
- A: 可通过分步输出、日志追踪等方式定位推理链每一步。
- Q: 推理链适合哪些场景?
- A: 复杂决策、规划、代码生成、自动化助手等。
- 最佳实践:
- 合理设置推理强度与token预算,兼顾性能与智能
- 结合知识库、插件等能力,提升Agent综合表现
9. 参考资料
- LobeChat官方文档
- 源码关键文件:
src/chains/answerWithContext.ts、src/features/ChatInput/ActionBar/Model/ControlsForm.tsx等 - Anthropic Claude推理机制说明



















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











