



摘要
本文系统介绍Claude大模型的自管理记忆与长期上下文机制,涵盖智能Agent知识追踪、记忆压缩、滚动摘要与多层级知识管理等核心技术。通过实战案例与可视化图表,帮助中国AI开发者掌握高效构建长期智能对话与知识管理系统的最佳实践。
目录
自管理记忆原理与意义
- 自管理记忆:让Agent自主读写、压缩和检索长期对话与知识,突破上下文窗口限制。
- 意义:支持长周期任务、复杂多轮对话、知识积累与智能追踪。
- 应用场景:企业知识库、智能助理、长期项目管理、个性化推荐等。
重点:自管理记忆是智能Agent实现长期智能与知识进化的关键。
Claude Agent长期上下文与知识追踪机制
- 有限上下文窗口:如Claude 4支持20万token,但超长上下文计算成本高。
- 知识追踪:通过记忆工具,Agent可自主记录、检索、更新关键信息。
- 典型机制:
- 简单记忆(字符串/笔记)
- 滚动摘要(定期压缩历史)
- 文件型记忆(多层级目录结构)
记忆压缩与滚动摘要实战
1. 简单记忆工具
- 代码示例:
class SimpleMemory:
def __init__(self):
self.memory = ""
def read(self):
return self.memory
def write(self, content):
self.memory = content
def edit(self, old, new):
self.memory = self.memory.replace(old, new)
# 用法
mem = SimpleMemory()
mem.write("用户喜欢被称为小明")
print(mem.read())
mem.edit("小明", "小王")
print(mem.read())
2. 记忆压缩与滚动摘要
- 原理:定期将对话历史压缩为摘要,节省上下文空间。
- 代码示例:
from anthropic import Anthropic
client = Anthropic()
message_history = [
{"role": "user", "content": "我喜欢科幻小说。"},
{"role": "assistant", "content": "你最喜欢哪本?"},
{"role": "user", "content": "三体。"}
]
# 当历史过长时,自动压缩
prompt = "请将以下对话总结为简明笔记:" + str(message_history)
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=128,
messages=[{"role": "user", "content": prompt}]
)
summary = response.content
print("滚动摘要:", summary)
文件型记忆与多层级知识管理案例
- 原理:用文件/目录结构管理多主题、多用户、多项目知识。
- 代码示例:
class MemoryTree:
def __init__(self):
self.tree = {"root": {}}
def add(self, path, content):
parts = path.split("/")
node = self.tree["root"]
for part in parts[:-1]:
node = node.setdefault(part, {})
node[parts[-1]] = content
def get(self, path):
parts = path.split("/")
node = self.tree["root"]
for part in parts:
node = node.get(part, {})
return node if node else None
# 用法
mem_tree = MemoryTree()
mem_tree.add("用户/偏好/称呼", "小明")
mem_tree.add("项目/2024/目标", "发布AI助手")
print(mem_tree.get("用户/偏好/称呼"))
print(mem_tree.get("项目/2024/目标"))
架构图、流程图与思维导图
图1:自管理记忆与长期上下文系统架构图
图2:记忆压缩与滚动摘要业务流程图
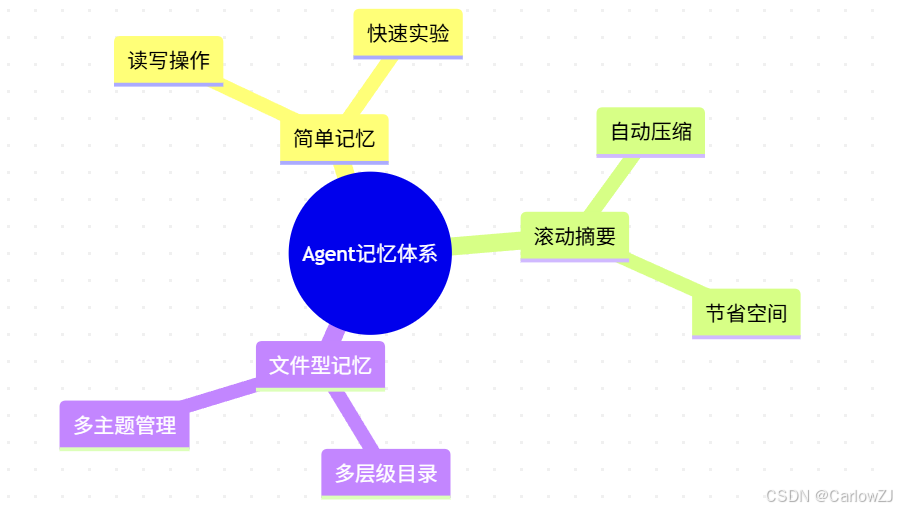
图3:Agent记忆体系思维导图
注意事项与最佳实践
- 记忆内容需定期压缩,防止上下文溢出
- 滚动摘要建议人工+自动结合,提升准确性
- 文件型记忆结构需合理规划,防止混乱
- 敏感信息需加密或脱敏存储
- Agent应能自主判断何时读写/压缩记忆
常见问题与扩展阅读
常见问题:
- Agent为何偶尔遗忘关键信息?
- 建议定期回顾与补充记忆内容。
- 记忆压缩后信息丢失怎么办?
- 结合原文引用与摘要,重要内容单独存储。
- 多用户/多项目如何隔离记忆?
- 用多层级目录或多实例管理。
扩展阅读:
总结与参考资料
本文系统梳理了Claude自管理记忆与长期上下文的核心原理、压缩机制与多层级知识管理实战。建议开发者结合自身业务场景,灵活选用记忆工具与结构,持续关注官方文档与社区动态,提升AI应用长期智能与知识管理能力。
参考资料:



















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











