






摘要
本文系统介绍如何利用Claude大模型的多模态理解能力与Agent子任务协作机制,实现复杂AI应用场景下的PDF文档解析、图表解读与智能协作。通过实战案例与架构图,帮助中国AI开发者掌握多模态+Agent协作的核心技术与最佳实践。
目录
- 多模态理解与PDF处理的应用场景与技术原理
- Claude多模态API与PDF解析实战
- 子Agent协作与Orchestrator-Worker模式详解
- 多模态+Agent协作复合案例:财报分析与图表解读
- 架构图、流程图与思维导图
- 注意事项与最佳实践
- 常见问题与扩展阅读
- 总结与参考资料
多模态理解与PDF处理的应用场景与技术原理
- 多模态AI:支持文本、图片、PDF等多种数据类型的理解与推理。
- 典型场景:财报分析、图表解读、幻灯片讲解、合同审核、学术论文摘要等。
- Claude优势:原生支持PDF上传与视觉理解,结合API可实现自动化批量处理。
重点:多模态能力极大拓展了AI在企业数据、金融、法律等领域的应用边界。
Claude多模态API与PDF解析实战
1. 环境准备与API调用
# 安装Anthropic官方SDK
%pip install anthropic
import base64
from anthropic import Anthropic
# 初始化Claude客户端,开启PDF beta特性
client = Anthropic(default_headers={
"anthropic-beta": "pdfs-2024-09-25"
})
MODEL_NAME = "claude-3-5-sonnet-20241022"
2. PDF文件编码与上传
# 读取PDF文件并编码为base64
with open("./documents/cvna_2021_annual_report.pdf", "rb") as pdf_file:
binary_data = pdf_file.read()
base64_string = base64.b64encode(binary_data).decode('utf-8')
3. 发送多模态请求并解析结果
# 构造多模态消息,提问PDF内容
messages = [
{
"role": 'user',
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": base64_string}},
{"type": "text", "text": "请用一句话总结该报告的核心内容。"}
]
}
]
response = client.messages.create(
model=MODEL_NAME,
max_tokens=8192,
temperature=0,
messages=messages
)
print(response.content[0].text)
4. 进阶:批量PDF分析与图表解读
# 支持批量上传多个PDF,结合多线程并发处理
from concurrent.futures import ThreadPoolExecutor
def analyze_pdf(pdf_path, question):
with open(pdf_path, "rb") as f:
base64_string = base64.b64encode(f.read()).decode('utf-8')
messages = [
{
"role": 'user',
"content": [
{"type": "document", "source": {"type": "base64", "media_type": "application/pdf", "data": base64_string}},
{"type": "text", "text": question}
]
}
]
response = client.messages.create(
model=MODEL_NAME,
max_tokens=4096,
temperature=0,
messages=messages
)
return response.content[0].text
pdf_list = ["./documents/cvna_2021_annual_report.pdf", "./documents/twilio_q4_2023.pdf"]
question = "请提取本报告的年度营收数据及主要增长点。"
with ThreadPoolExecutor() as executor:
results = list(executor.map(lambda pdf: analyze_pdf(pdf, question), pdf_list))
for res in results:
print(res)
子Agent协作与Orchestrator-Worker模式详解
- 核心思想:主Agent(Orchestrator)负责任务拆解与分配,子Agent(Worker)并行处理子任务,主Agent最终汇总结果。
- 适用场景:复杂任务自动分解、批量文档分析、多视角综合推理。
1. Orchestrator-Worker模式架构图
2. 典型代码实现
# 伪代码:主Agent拆解任务,子Agent并行处理
from concurrent.futures import ThreadPoolExecutor
def orchestrator(task, pdf_paths):
# 拆解为子任务
sub_tasks = [
("PDF解析", pdf_paths[0]),
("图表识别", pdf_paths[1]),
("关键信息抽取", pdf_paths[0])
]
with ThreadPoolExecutor() as executor:
results = list(executor.map(lambda t: worker(*t), sub_tasks))
# 汇总结果
return "\n".join(results)
def worker(task_type, pdf_path):
# 根据子任务类型调用不同处理逻辑
return f"子任务[{task_type}]已完成:{pdf_path}"
# 示例调用
result = orchestrator("财报分析", ["./documents/cvna_2021_annual_report.pdf", "./documents/twilio_q4_2023.pdf"])
print(result)
多模态+Agent协作复合案例:财报分析与图表解读
场景描述
- 批量上传多份财报PDF,自动提取营收、利润、增长点等关键信息,并生成可视化图表。
实战流程图
代码片段:多Agent协作分析
# 省略部分重复代码,重点展示多Agent协作与结果整合
# ...(见上文Orchestrator-Worker实现)
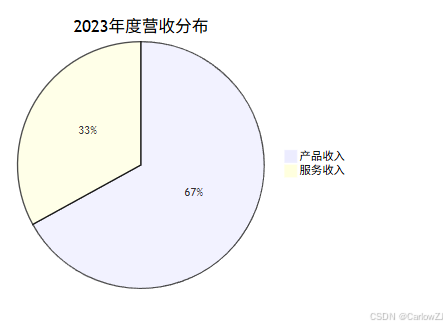
饼图示例:年度营收分布
架构图、流程图与思维导图
系统架构图
思维导图:多模态+Agent协作知识体系
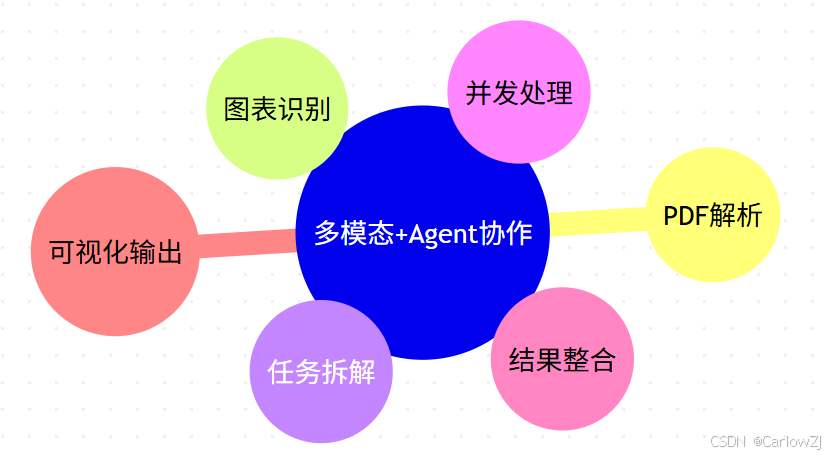
mindmap
root((多模态+Agent协作))
子节点1((PDF解析))
子节点2((图表识别))
子节点3((任务拆解))
子节点4((并发处理))
子节点5((结果整合))
子节点6((可视化输出))
注意事项与最佳实践
- PDF大小与页数限制:单次请求最多支持100页,建议分批处理。
- 图表复杂性:复杂配色、嵌套图表需分步提问或结合视觉工具。
- Agent拆解粒度:子任务应独立、可并行,避免重复计算。
- 错误处理:API调用需加异常捕获,保证批量任务稳定性。
最佳实践:优先结构化拆解任务,合理利用多线程与多Agent并发,提升处理效率。
常见问题与扩展阅读
- Q: Claude能否直接解析图片中的表格?
- A: 支持,但复杂表格建议结合视觉工具辅助。
- Q: 多Agent协作如何避免结果冲突?
- A: 需主Agent统一汇总与去重,设计合理的结果整合逻辑。
- Q: 如何提升多模态理解准确率?
- A: 明确提问、分步推理、结合结构化输出。
扩展阅读:
总结与参考资料
- 多模态+Agent协作是AI应用落地的关键能力,适用于金融、法律、企业数据等复杂场景。
- Claude原生支持PDF、图片等多模态输入,结合Agent模式可实现高效批量处理与智能协作。
- 推荐结合Mermaid图表、思维导图等工具,提升系统可视化与知识梳理能力。
参考资料:
- Anthropic Cookbook官方仓库
- Claude多模态API文档
- Python并发与多线程最佳实践




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











