






本文聚焦Maybe系统的数据同步与导入导出,详细介绍数据同步与导入架构、自动同步原理、CSV导入、Python数据校验、异步任务、数据一致性、数据分布饼图、最佳实践、项目计划、思维导图、常见问题、合规性、团队协作、自动化测试等,助力开发者高效实现数据流与异步任务。
目录
摘要
本篇聚焦Maybe系统的数据同步与导入导出,详细介绍数据同步与导入架构、自动同步原理、CSV导入、Python数据校验、异步任务、数据一致性、数据分布饼图、最佳实践、项目计划、思维导图、常见问题、合规性、团队协作、自动化测试等,助力开发者高效实现数据流与异步任务。
数据同步与导入架构
系统设计原则
- 高可用:支持多数据源、自动降级、异常告警
- 灵活性:支持Plaid、CSV、Excel等多种数据接入方式
- 一致性:所有数据归一化、去重、校验,保证账本准确
- 自动化:同步、导入、校验、分类全流程自动化
- 合规性:满足数据安全、隐私保护、审计等合规要求
数据流与模块分工
| 模块 | 主要职责 | 关键技术 |
|---|---|---|
| 数据接入 | Plaid/CSV/Excel等数据导入 | API、文件上传 |
| 数据归一化 | 统一字段、币种、格式 | Python、Ruby |
| 数据校验 | 校验必填、金额、日期等 | pandas、正则 |
| 数据去重 | 防止重复入库 | 唯一索引、哈希 |
| 异步任务 | 大批量数据异步处理 | Sidekiq、Redis |
| 日志与告警 | 失败重试、异常通知 | 日志、邮件、钉钉 |
Mermaid架构图
自动同步原理与流程
定时任务与触发机制
- 支持定时任务(如Sidekiq Scheduler、Cron)自动触发同步
- 用户可手动发起同步,支持全量/增量同步
- 同步任务入队,异步处理,提升系统吞吐量
数据归一化与去重
- 拉取第三方数据后,统一字段、币种、日期格式
- 通过唯一索引、哈希等方式去重,防止重复入库
- 支持多币种归一化,历史汇率回溯
自动分类与智能处理
- 新交易自动归类,结合规则引擎与AI模型
- 异常数据自动标记,需人工复核
- 支持批量修正与反馈训练
同步流程甘特图
CSV导入与Python数据校验
多格式导入支持
- 支持CSV、Excel、OFX、QIF等主流银行/券商流水格式
- 智能字段映射,自动识别常见字段名
- 支持批量导入、断点续传
Python数据校验实战
import pandas as pd
import re
def validate_csv(file_path):
df = pd.read_csv(file_path)
required_cols = {"date", "amount", "desc"}
if not required_cols.issubset(df.columns):
raise ValueError("缺少必要字段")
# 校验金额格式
if not pd.api.types.is_numeric_dtype(df["amount"]):
raise ValueError("金额格式错误")
# 校验日期格式
date_pattern = re.compile(r"\d{4}-\d{2}-\d{2}")
if not df["date"].apply(lambda x: bool(date_pattern.match(str(x)))).all():
raise ValueError("日期格式错误,应为YYYY-MM-DD")
return df
# 示例
# df = validate_csv("transactions.csv")
数据清洗与异常处理
- 金额、日期、币种等字段自动清洗、标准化
- 异常数据(如负数、缺失、重复)自动标记
- 支持导入日志、错误报告、批量修正
异步任务与数据一致性
Sidekiq/Redis异步架构
- 所有大批量数据导入、同步、分类均通过Sidekiq异步处理
- 支持任务分片、并发、优先级队列
- 任务状态、进度、失败日志全程可追溯
幂等性与一致性保障
- 每个任务有唯一ID,重复提交不会重复入库
- 数据库层唯一索引、幂等校验,防止脏数据
- 支持分布式锁,防止并发冲突
失败重试与告警机制
- 任务失败自动重试,支持最大重试次数
- 失败任务自动告警(邮件、钉钉、短信)
- 支持人工介入、批量修正、日志导出
数据分布与可视化
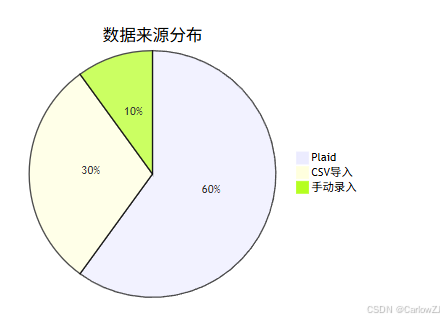
数据来源分布饼图
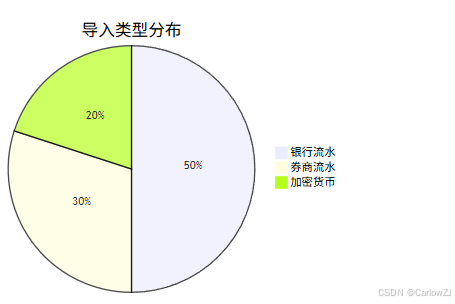
导入类型与趋势分析
导入趋势折线图(伪代码)
import matplotlib.pyplot as plt
dates = ["2024-06-01", "2024-06-02", "2024-06-03"]
counts = [100, 150, 120]
plt.plot(dates, counts)
plt.title("每日导入数据量趋势")
plt.xlabel("日期")
plt.ylabel("导入记录数")
plt.show()
Mermaid与可视化实践
- Mermaid适合结构、分布、计划等可视化
- 数据趋势、分布分析可用Python/JS绘图
最佳实践与注意事项
数据校验与清洗
- 导入数据需严格校验,防止脏数据入库
- 金额、日期、币种等字段需标准化
- 异常数据自动标记,便于后续修正
异步任务幂等性
- 所有异步任务需保证幂等性,防止重复入库
- 任务ID、数据哈希、唯一索引等多重校验
自动化测试与监控
- 集成自动化测试,覆盖导入、同步、分类等关键流程
- 监控任务队列、失败率、告警日志,保障系统稳定
常见问题FAQ
Q1: 如何防止重复导入?
- 通过唯一索引、哈希校验、幂等任务设计
Q2: 导入数据格式不统一怎么办?
- 智能字段映射、数据清洗、异常报告
Q3: 任务失败如何排查?
- 查看失败日志、自动告警、支持人工重试
Q4: 如何支持大批量数据导入?
- 任务分片、并发处理、异步队列
Q5: 如何保障数据安全与合规?
- 数据加密、权限分级、日志审计、合规导出
项目计划与甘特图
开发计划分解
- 同步架构设计:2天
- CSV/Excel导入开发:2天
- 校验与清洗机制:2天
- 异步任务开发:2天
- 自动化测试与上线:2天
团队协作与分工
- 架构师:数据流设计、异步架构
- 后端开发:导入、同步、校验、异步任务
- 前端开发:导入界面、进度展示、日志可视化
- 测试工程师:自动化测试、异常场景覆盖
- 运维:任务监控、告警、日志管理
Mermaid甘特图
思维导图
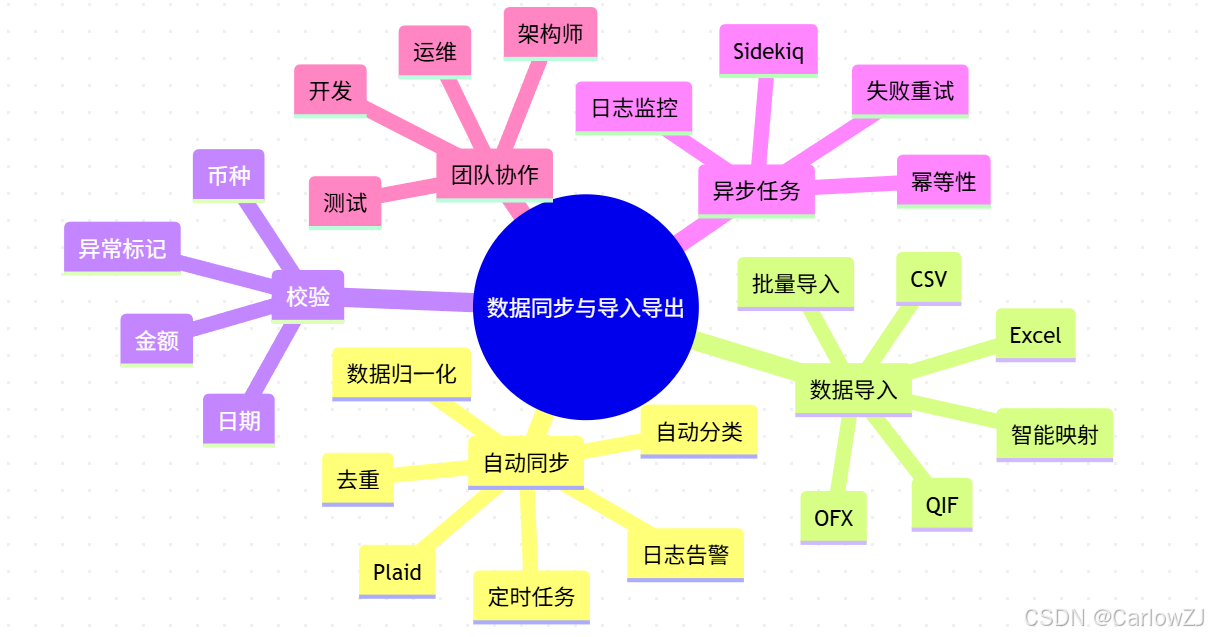
mindmap
root((数据同步与导入导出))
自动同步
Plaid
定时任务
数据归一化
去重
自动分类
日志告警
数据导入
CSV
Excel
OFX
QIF
智能映射
批量导入
校验
金额
日期
币种
异常标记
异步任务
Sidekiq
幂等性
失败重试
日志监控
团队协作
架构师
开发
测试
运维




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











