






摘要
本篇博客面向中国AI开发者,系统讲解思源笔记的底层数据结构与块级存储原理。内容涵盖块级数据模型、存储机制、数据流转、API操作、实用案例、最佳实践与常见问题。通过丰富的Python代码、Mermaid图表和真实案例,帮助开发者深入理解并高效利用思源笔记的数据能力。
目录
- 块级数据结构与模型
- 存储原理与数据流转
- 数据一致性与扩展性设计
- 块级API操作与实践
- 实践案例:块级引用与内容重组
- 最佳实践与注意事项
- 常见问题解答
- 总结与实践建议
- 参考资料与扩展阅读
1. 块级数据结构与模型
思维导图:块级数据结构知识体系
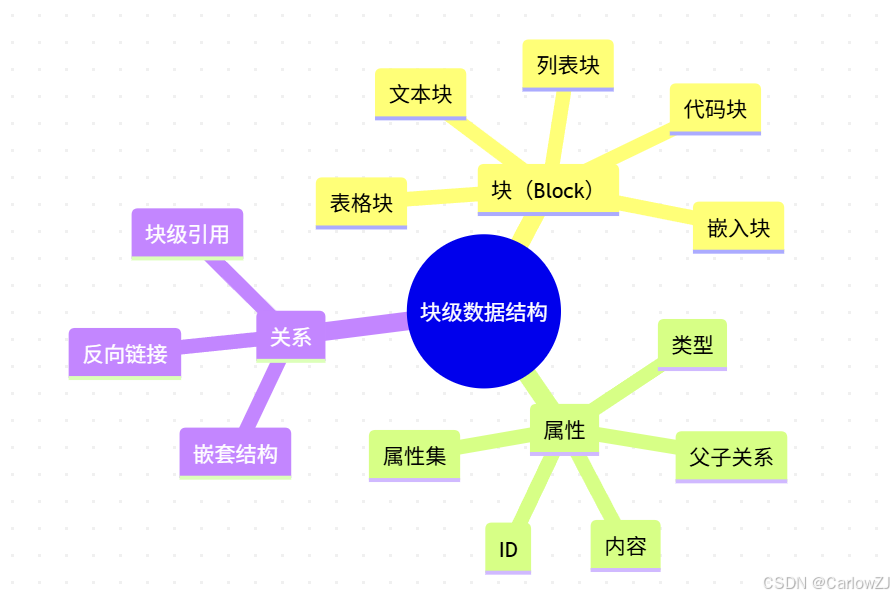
mindmap
root((块级数据结构))
块(Block)
文本块
列表块
表格块
代码块
嵌入块
属性
ID
父子关系
内容
类型
属性集
关系
块级引用
嵌套结构
反向链接
说明:
- 所有内容以“块”为最小单元,支持嵌套、引用、重组。
- 每个块有唯一ID,支持属性扩展。
2. 存储原理与数据流转
架构图:块级存储与数据流转
graph TD
A[前端操作] --> B[API层]
B --> C[内核处理]
C --> D[块级存储(SQLite/文件系统)]
D --> E[数据同步模块]
E --> F[云端/本地同步]
流程图:块级数据操作流程
3. 数据一致性与扩展性设计
- 支持多端同步,保证数据一致性
- 块级操作原子性,防止数据丢失
- 属性扩展机制,便于自定义与插件开发
- 支持大规模数据高效检索与引用
4. 块级API操作与实践
常用API举例
/api/block/getBlockByID:获取块内容/api/block/insertBlock:插入新块/api/block/updateBlock:更新块内容/api/block/removeBlock:删除块
Python代码示例:获取块内容
import requests
def get_block_by_id(block_id, api_token):
url = "http://127.0.0.1:6806/api/block/getBlockByID"
headers = {
"Authorization": f"Token {api_token}",
"Content-Type": "application/json"
}
data = {"id": block_id}
try:
resp = requests.post(url, json=data, headers=headers, timeout=10)
result = resp.json()
if result["code"] == 0:
return result["data"]
else:
return f"请求失败:{result['msg']}"
except Exception as e:
return f"请求异常:{e}"
# 示例用法
api_token = "你的API Token"
block_id = "块ID"
print(get_block_by_id(block_id, api_token))
5. 实践案例:块级引用与内容重组
需求分析
- 实现跨文档块级引用,支持内容重组与知识网络构建
实现步骤
- 获取目标块ID与内容
- 在新文档中插入引用块
- 通过API实现内容重组与同步
Python代码示例:插入引用块
import requests
def insert_reference_block(parent_id, ref_block_id, api_token):
url = "http://127.0.0.1:6806/api/block/insertBlock"
headers = {
"Authorization": f"Token {api_token}",
"Content-Type": "application/json"
}
data = {
"parentID": parent_id,
"dataType": "NodeRef",
"data": ref_block_id
}
try:
resp = requests.post(url, json=data, headers=headers, timeout=10)
result = resp.json()
if result["code"] == 0:
return result["data"]
else:
return f"请求失败:{result['msg']}"
except Exception as e:
return f"请求异常:{e}"
# 示例用法
api_token = "你的API Token"
parent_id = "父块ID"
ref_block_id = "被引用块ID"
print(insert_reference_block(parent_id, ref_block_id, api_token))
6. 最佳实践与注意事项
注意事项:
- 块ID需唯一,避免引用冲突
- 块操作建议通过API完成,防止数据损坏
- 定期备份,防止意外丢失
- 大量块操作时注意性能优化
最佳实践:
- 利用块级引用构建知识网络
- 合理设计块结构,提升检索与重组效率
- 结合插件扩展块属性与功能
7. 常见问题解答
- Q:块ID如何获取?
A:通过API或前端开发者工具查看 - Q:块级引用失效怎么办?
A:检查被引用块是否被删除或移动,及时修复引用 - Q:如何批量操作块?
A:可通过API循环调用实现批量处理
8. 总结与实践建议
- 思源笔记块级数据结构灵活,支持高效内容管理与知识重组
- 推荐通过API进行块级操作,保障数据一致性与安全
- 实践中注重结构设计与性能优化
- 积极参与社区,获取最新数据结构与API扩展资源
9. 参考资料与扩展阅读
如需获取更多块级数据结构与存储原理内容,欢迎关注本专栏并留言交流!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











