







摘要
在大型语言模型(LLM)层出不穷的今天,如何为特定应用挑选最合适的模型,并最大化其性能,已成为开发者面临的关键挑战。本文将作为一份全面的实战指南,带领读者深入探索LLM的世界。我们将系统性地梳理LLM的多种分类维度,包括按模态、按开源与否、按输出类型及核心架构等。本文还将以Azure AI Studio为例,手把手展示如何利用云平台进行模型的筛选、评估与部署。更重要的是,文章将深度剖析并比较三种主流的模型性能提升策略:提示工程(Prompt Engineering)、检索增强生成(RAG)和模型微调(Fine-tuning),帮助开发者根据成本、复杂度和数据依赖性做出最佳技术选型。












引言:“启智未来”的十字路口
在上一篇文章中,我们的教育科技初创公司“启智未来”明确了利用生成式AI革新教育的愿景。现在,团队走到了一个关键的十字路口:面对市面上琳琅满目的LLM,我们该如何选择?
是选择像GPT-4这样的业界顶尖模型,还是拥抱更为灵活的开源模型?是满足于开箱即用的基础能力,还是需要针对我们的教育数据进行深度定制?这个决策不仅关系到应用的最终效果,更直接影响到研发成本、部署难度和未来的扩展性。
这篇“风云录”,正是为“启智未来”以及所有像我们一样在AI浪潮中探索前行的开发者准备的导航图。
第一章:LLM分类大全:一文看懂模型差异
要做出明智的选择,首先要了解全局。LLM的“江湖”派系林立,我们可以从以下几个维度来为它们“画像”。
1. 按模态划分 (By Modality)
模态指模型处理的信息类型。
- 文本 (Text): 绝大多数模型的“主战场”,如GPT系列,专注于理解和生成文本。
- 图像 (Image): 专攻图像生成,如DALL-E、Midjourney。
- 音频 (Audio): 用于语音识别和生成,如OpenAI的Whisper模型。
- 多模态 (Multi-modality): 新一代模型的演进方向,能同时理解和处理多种类型的信息,如GPT-4o可以结合文本和视觉信息进行交互。
2. 开源 vs. 闭源 (Open Source vs. Proprietary)
这是一个核心的商业和技术考量。

图1: LLM模型生态分布概念图
- 闭源模型: 由商业公司掌控,如OpenAI的GPT系列、Anthropic的Claude系列。
- 优点: 性能强大、优化成熟、通常有稳定的API服务和技术支持。
- 缺点: “黑箱”操作,无法探查内部细节;有服务依赖风险;数据隐私需信任服务商。
- 开源模型: 公开给社区,如Meta的LLaMA系列、阿联酋的Falcon、法国的Mistral。
- 优点: 透明度高,可自由修改、定制和私有化部署,数据安全可控。
- 缺点: 性能可能参差不齐,需要自行解决部署、维护和优化问题,对技术团队要求高。
3. 按输出类型划分 (By Output Type)
- 文本/代码生成 (Text/Code Generation): 最常见的类型,用于对话、写作、生成代码等。
- 嵌入 (Embeddings): 将文本转换为高维度的数字向量(Vector)。这些向量能够捕捉文本的语义关系,是构建知识库问答、语义搜索等高级应用(如RAG)的基石。
- 图像生成 (Image Generation): 输入文本描述(Prompt),输出图像。
4. 按架构划分 (By Architecture)
这个划分比较技术,但有助于理解模型的能力偏好。让我们用一个生动的比喻来理解。
任务:为学生出一套历史测验题。

graph TD
subgraph "任务分工"
A(试卷主题: 宋朝历史) --> B{出题人 (Decoder-Only)};
A --> C{审题人 (Encoder-Only)};
A --> D{全能出题+审题人 (Encoder-Decoder)};
end
B -- "只看前方,不断续写<br/>擅长创意生成" --> E((GPT, LLaMA));
C -- "通读全文,理解上下文<br/>擅长分析和分类" --> F((BERT));
D -- "既能理解,又能生成<br/>擅长翻译和摘要" --> G((T5, BART));
style E fill:#f9f,stroke:#333
style F fill:#ccf,stroke:#333
style G fill:#cfc,stroke:#333
图2: LLM架构能力偏好示意图
- 仅解码器 (Decoder-Only): 像一个“续写者”,只能看到前面的内容来预测下一个词。非常适合开放式的生成任务,如写文章、聊天。(代表:GPT系列)
- 仅编码器 (Encoder-Only): 像一个“阅读理解高手”,可以完整地、双向地阅读整个句子来理解其深层含义。不擅长生成,但非常适合做文本分类、情感分析等任务。(代表:BERT)
- 编码器-解码器 (Encoder-Decoder): 结合了前两者,先由编码器“深度理解”输入,再由解码器“精准生成”输出。是机器翻译、文本摘要等任务的理想选择。(代表:T5, BART)
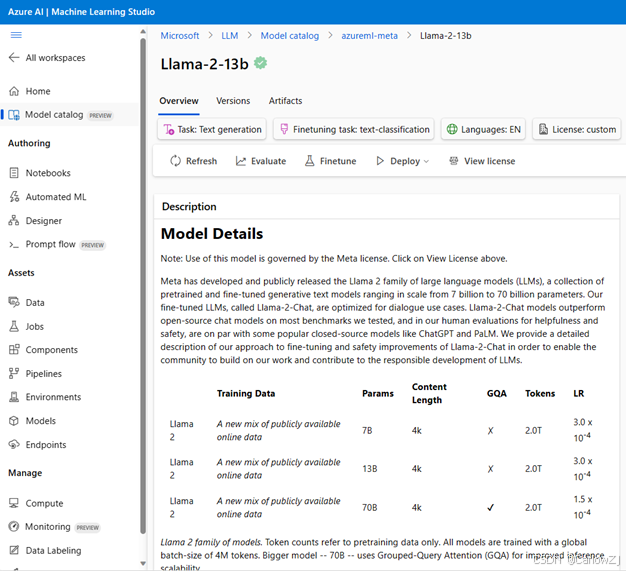
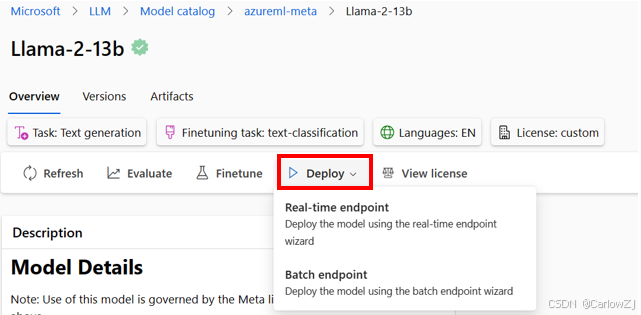
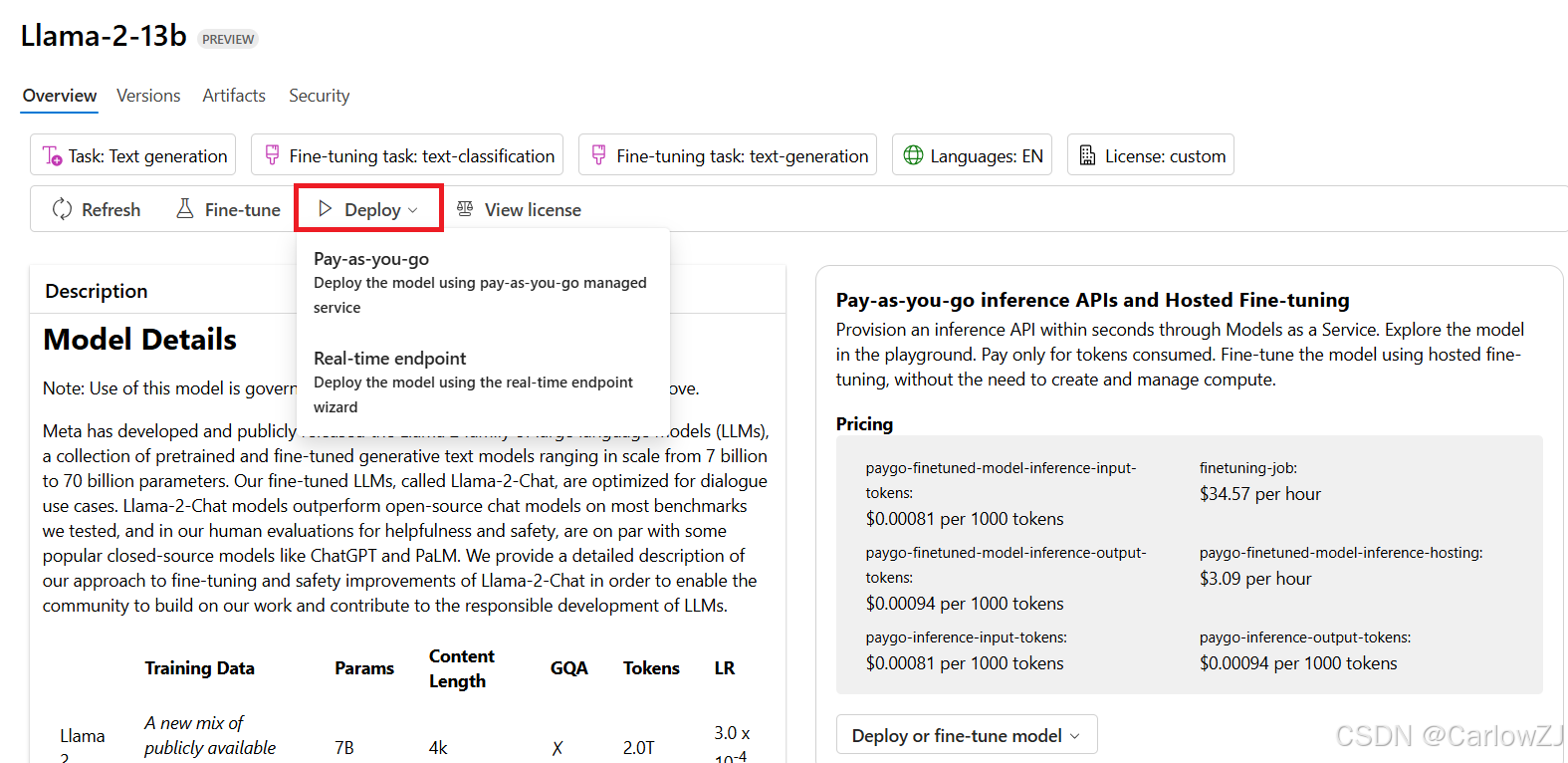
第二章:模型选型实战:Azure AI Studio深度探索
理论学习后,我们需要一个“练兵场”。Azure AI Studio 便是这样一个集模型探索、测试、微调和部署于一体的强大平台。
对于“启智未来”来说,模型选型的流程应该是系统化、数据驱动的。

flowchart TD
A[进入Azure AI Studio模型目录] --> B{按任务筛选<br/>(如: 对话, 摘要)};
B --> C{按许可证筛选<br/>(如: 开源, 商业)};
C --> D[选择候选模型<br/>(如: Llama-2, GPT-4)];
D --> E[查阅模型卡片<br/>(了解用途、限制、训练数据)];
E --> F[对比性能基准<br/>(查看模型在标准数据集上的跑分)];
F --> G{在Playground中测试<br/>(使用我们的真实教育场景Prompt)};
G --> H((确定初步选型));
style A fill:#1976D2,color:white
style H fill:#4CAF50,color:white
图3: 在Azure AI Studio中的模型选型工作流
- 浏览与筛选: 在模型目录中,可以根据任务(如聊天、内容生成)、许可证类型(如MIT、Apache 2.0)和集合(如OpenAI、Hugging Face)快速缩小选择范围。
- 解读模型卡片: 这是模型的“身份证”。它详细描述了模型的预期用途、训练方法、性能评估结果和潜在的偏见与风险。仔细阅读模型卡片是负责任AI实践的第一步。
- 对比基准: 平台提供了模型在多个行业标准评测基准(Benchmark)上的性能数据,可以进行横向比较,做出数据驱动的初步判断。
- 沙盒测试 (Playground): “是骡子是马,拉出来遛遛”。在Playground中,我们可以用自己业务场景的真实Prompt来测试候选模型的实际表现,直观感受其输出质量、风格是否符合“启智未来”的需求。
第三章:提升模型表现的三大策略
选择了基础模型,只是万里长征第一步。为了让模型在“启智未来”的教育场景中发挥最大效用,我们必须对其进行优化。主要有三条路径,它们的成本、复杂度和效果各不相同。

图4: LLM部署的几种方法 (来源: Fiddler.ai)
图5: 三大优化策略对比
策略一:提示工程 (Prompt Engineering)
这是最轻量、最快捷的优化方式,本质是“更好地与LLM对话”。
- 零样本 (Zero-shot): 直接提出请求,不给任何示例。
- 单样本 (One-shot): 在请求中给出一个示例,引导模型输出格式或风格。
- 少样本 (Few-shot): 给出多个示例,进一步强化模型的理解。
对于“启智未来”,我们可以设计精良的Prompt模板,用于生成教案、解释概念等,这是成本最低的“杠杆”。
策略二:检索增强生成 (RAG)
这相当于给LLM一本“开卷考试”的参考书。当模型需要回答其训练数据中不包含的私有知识(如我们最新的课程大纲)或实时信息时,RAG是最佳选择。
工作流程:
- 检索 (Retrieve): 当用户提问时,系统首先从我们的私有知识库(如课程文档、教学视频字幕等,通常存储在向量数据库中)中检索最相关的几段信息。
- 增强 (Augment): 将检索到的信息作为上下文(Context),与用户的原始问题一起,打包成一个新的、更丰富的Prompt。
- 生成 (Generate): 将这个增强后的Prompt喂给LLM,模型便能根据提供的上下文,生成一个既准确又基于事实的回答。
伪代码示例:
# RAG流程的伪代码表示
def answer_question_with_rag(user_question: str, vector_db: VectorDatabase, llm: LanguageModel):
"""
使用RAG流程回答用户问题
"""
# 1. 检索 (Retrieve)
# 从向量数据库中找到与问题最相关的知识片段
relevant_docs = vector_db.search(query=user_question, top_k=3)
# 2. 增强 (Augment)
# 将检索到的知识与原始问题整合成一个Prompt
context = "\n".join(doc.content for doc in relevant_docs)
augmented_prompt = f"""
请根据以下上下文信息回答问题。如果上下文中没有相关信息,请说你不知道。
上下文:
{context}
问题: {user_question}
"""
# 3. 生成 (Generate)
# 调用LLM生成最终答案
final_answer = llm.generate(prompt=augmented_prompt)
return final_answer
# -- 示例调用 --
# my_vector_db = setup_my_course_database() # 假设已将课程资料灌入向量数据库
# my_llm = OpenAI_GPT4()
# answer = answer_question_with_rag("请解释一下'启智未来'课程中的'深度学习'单元包含哪些主题?", my_vector_db, my_llm)
# print(answer)
策略三:模型微调 (Fine-tuning)
这相当于为LLM请一位“专业私教”,让它深度学习特定领域的知识或模仿特定的“说话风格”。微调会更新模型的权重,生成一个全新的、定制化的模型。
何时选择微调?
- 追求极致性能: 当RAG无法满足延迟或准确性要求时。
- 学习特定风格: 当需要模型模仿特定的语气、格式或角色(如一位风趣幽默的历史老师)时。
- 拥有大量高质量标注数据: 微调需要成百上千个“问题-答案”对作为训练样本,数据质量直接决定微调效果。
微调成本高昂,且需要持续维护,通常是优化路径的最后选择。
总结:为你的应用选择最佳路径
“LLM江湖”没有绝对的“天下第一”,只有最适合你的“神兵利器”。作为开发者,我们的决策过程应该是一个系统性的权衡。
决策框架(问自己这几个问题):
- 核心任务是什么? (创意写作?知识问答?代码生成?) -> 这决定了模型架构和类型的初步方向。
- 预算和资源有多少? (能承担多高的API费用?有无GPU资源?) -> 这决定了在闭源服务和自托管开源模型间的选择。
- 是否依赖私有或实时数据? (需要回答关于公司内部文档的问题吗?) -> 如果是,RAG是首选。
- 对性能和风格有何种极致要求? (需要模型模仿特定专家口吻吗?) -> 如果是,且有充足数据,可以考虑微调。
对于“启智未来”,一个合理的起步策略可能是:选择一个性能强大的闭源模型(如GPT-4)作为基础,通过精密的提示工程实现核心功能,并搭建RAG系统来提供个性化的课程问答。 随着业务发展和数据积累,再考虑对特定任务(如自动作文评分)进行模型微调。
探索LLM的旅程,是一个不断实验、迭代和优化的过程。希望这篇指南,能成为你在这趟旅程中一份可靠的地图。
参考资料
- 官方课程: Generative AI for Beginners - Microsoft/Github
- RAG介绍: Azure认知搜索中的检索增强生成 (RAG)
- Azure AI Studio: 什么是Azure AI Studio
- 基础模型论文: On the Opportunities and Risks of Foundation Models




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











