






摘要
本文系统梳理QLib数据层的架构设计、数据准备与接入、特征工程、数据处理与缓存机制、自定义数据接入与转换流程,结合实战案例与最佳实践,助力中国AI量化开发者高效管理、处理和扩展量化数据,提升数据驱动的量化研究效率。
目录
- 数据层架构与核心理念
- 数据准备与格式转换实战
- 数据API与特征工程
- 数据处理与缓存机制
- 自定义数据接入与扩展
- 实战案例:从原始数据到特征工程全流程
- 最佳实践与常见问题
- 项目实施计划(甘特图)
- 总结与实践建议
- 参考资料与扩展阅读
1. 数据层架构与核心理念
1.1 架构图
图1:QLib数据层架构图
说明: QLib数据层支持高效数据管理、特征工程与灵活扩展,助力量化研究全流程。
1.2 主要组件
- 数据准备与转换:支持多源数据接入与格式转换
- 数据API:高性能数据查询与特征表达式引擎
- 数据处理:支持自定义处理器与复杂特征工程
- 缓存机制:提升数据处理与复用效率
2. 数据准备与格式转换实战
2.1 QLib格式数据
- 支持中国、美国市场日频/高频数据
- 数据以
.bin格式高效存储,适合科学计算
2.2 数据下载与转换
实践示例
# 下载中国市场日频数据
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
# 将CSV格式数据转换为QLib格式
python scripts/dump_bin.py dump_all --csv_path ~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor
2.3 注意事项
- CSV需包含股票代码、日期、OHLCV、factor等字段
- 支持自定义因子字段接入
3. 数据API与特征工程
3.1 数据API
- 支持高性能数据查询、切片、聚合
- 支持表达式引擎构建复杂特征
实践示例
from qlib.data import D
# 查询收盘价
close = D.features(['SH600000'], ['$close'], start_time='2021-01-01', end_time='2021-12-31')
# 构建60日收益率特征
ret_60 = D.features(['SH600000'], ['Ref($close, 60) / $close'], start_time='2021-01-01', end_time='2021-12-31')
3.2 特征表达式与处理器
- 支持表达式引擎与自定义处理器
- 适合复杂特征工程与数据清洗
4. 数据处理与缓存机制
4.1 数据处理流程图
flowchart TD
A[原始数据] --> B[表达式引擎]
B --> C[处理器(Processor)]
C --> D[缓存(Cache)]
D --> E[模型/回测]
图2:数据处理与缓存流程图
4.2 缓存机制
- 支持多级缓存,提升特征复用与处理效率
- 支持自定义缓存策略
5. 自定义数据接入与扩展
5.1 支持多源数据接入
- 支持自有CSV、行情API、数据库等多种数据源
- 提供灵活的数据转换与接入脚本
5.2 实践示例
# 假设有自定义CSV行情数据
python scripts/dump_bin.py dump_all --csv_path ./my_csv --qlib_dir ./my_qlib --include_fields open,close,high,low,volume,factor
6. 实战案例:从原始数据到特征工程全流程
6.1 案例流程思维导图
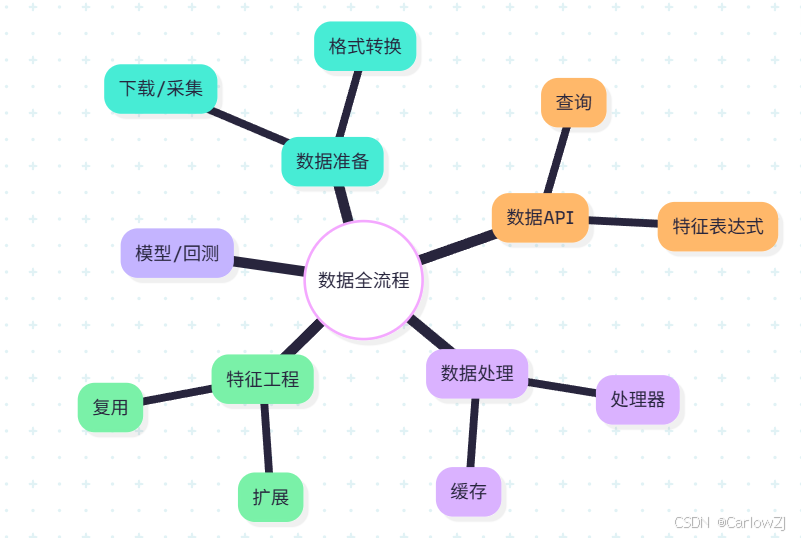
mindmap
root((数据全流程))
数据准备
下载/采集
格式转换
数据API
查询
特征表达式
数据处理
处理器
缓存
特征工程
复用
扩展
模型/回测
图3:数据全流程思维导图
6.2 代码全流程
from qlib.data import D
# 1. 查询原始数据
close = D.features(['SH600000'], ['$close'], start_time='2021-01-01', end_time='2021-12-31')
# 2. 构建特征
ret_20 = D.features(['SH600000'], ['Ref($close, 20) / $close'], start_time='2021-01-01', end_time='2021-12-31')
# 3. 数据处理与缓存(自动完成)
7. 最佳实践与常见问题
7.1 实践建议
- 合理设计特征表达式,提升特征复用性
- 定期检查数据健康,保证数据质量
- 充分利用缓存机制,提升效率
7.2 常见问题解答
Q1:如何接入自定义因子?
A:在CSV中添加自定义因子字段,转换为QLib格式即可。
Q2:数据转换报错怎么办?
A:检查字段命名、数据格式与缺失值,参考官方文档与脚本帮助。
8. 项目实施计划(甘特图)
图4:QLib数据管理与特征工程项目甘特图
9. 总结与实践建议
QLib数据层为AI量化开发者提供了高效、灵活的数据管理、特征工程与扩展能力。建议开发者结合自身业务需求,充分利用数据API、表达式引擎与缓存机制,持续优化数据处理流程,提升量化研究效率。



















 2072
2072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











