






摘要
本文深入探讨了GraphRAG(Graph-based Retrieval Augmented Generation)的配置系统,这是一个强大的AI知识图谱构建工具。我们将从基础配置到高级特性,全面解析如何通过YAML/JSON配置文件来定制化GraphRAG的行为。通过本文,您将掌握如何构建高效、可扩展的知识图谱系统,为您的AI应用提供强大的知识支持。
目录
1. GraphRAG配置系统概述
1.1 系统架构
1.2 核心特性
- 灵活的配置格式:支持YAML和JSON两种格式
- 环境变量集成:支持通过
.env文件管理敏感信息 - 模块化设计:各组件可独立配置
- 可扩展性:支持自定义配置项
1.3 配置示例
# 基础配置示例
models:
default_chat_model:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat
model: gpt-4
model_supports_json: true
2. 基础配置详解
2.1 配置文件结构
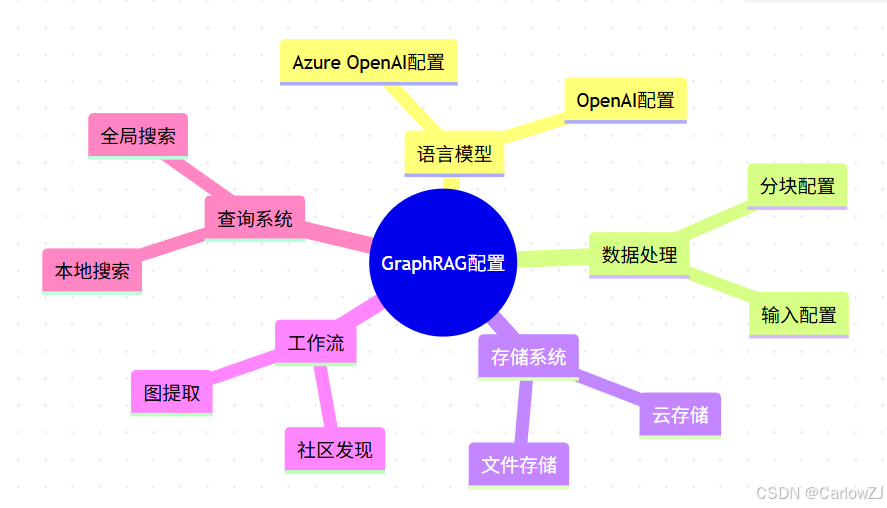
mindmap
root((GraphRAG配置))
语言模型
OpenAI配置
Azure OpenAI配置
数据处理
输入配置
分块配置
存储系统
文件存储
云存储
工作流
图提取
社区发现
查询系统
本地搜索
全局搜索
2.2 环境变量配置
# 环境变量配置示例
import os
from dotenv import load_dotenv
# 加载.env文件
load_dotenv()
# 获取API密钥
api_key = os.getenv('GRAPHRAG_API_KEY')
3. 语言模型配置
3.1 模型类型支持
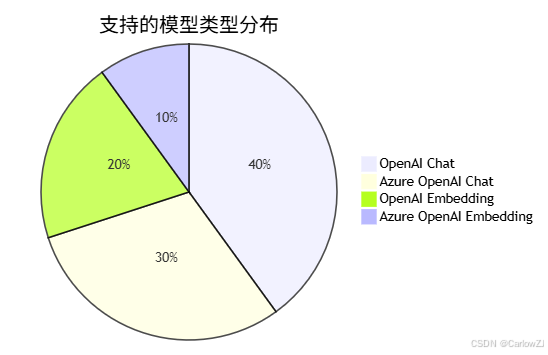
3.2 模型配置示例
# 模型配置示例
model_config = {
"default_chat_model": {
"api_key": "${GRAPHRAG_API_KEY}",
"type": "openai_chat",
"model": "gpt-4",
"model_supports_json": True,
"request_timeout": 30,
"max_retries": 3
}
}
4. 数据处理与存储
4.1 数据流程
4.2 存储配置示例
# 存储配置示例
storage_config = {
"type": "lancedb",
"db_uri": "storage/base_dir/lancedb",
"container_name": "default",
"overwrite": True
}
5. 工作流配置
5.1 工作流类型
5.2 工作流配置示例
# 工作流配置示例
workflow_config = {
"extract_graph": {
"model_id": "default_chat_model",
"entity_types": ["人物", "组织", "地点"],
"max_gleanings": 3
}
}
6. 查询系统配置
6.1 查询类型
6.2 查询配置示例
# 查询配置示例
query_config = {
"local_search": {
"chat_model_id": "default_chat_model",
"embedding_model_id": "default_embedding_model",
"text_unit_prop": 0.6,
"community_prop": 0.4
}
}
7. 最佳实践与案例分析
7.1 实施计划
7.2 案例分析
案例一:企业知识库构建
# 企业知识库配置示例
enterprise_config = {
"input": {
"type": "file",
"file_type": "text",
"base_dir": "enterprise_docs",
"encoding": "utf-8"
},
"chunks": {
"size": 1000,
"overlap": 200,
"strategy": "tokens"
}
}
8. 常见问题解答
8.1 配置相关
-
Q: 如何处理API密钥安全存储?
A: 使用.env文件存储敏感信息,并通过环境变量引用。 -
Q: 如何优化模型性能?
A: 调整request_timeout、max_retries等参数,并启用缓存机制。
8.2 性能优化
-
Q: 如何提高查询效率?
A: 合理配置text_unit_prop和community_prop,优化向量存储参数。 -
Q: 如何处理大规模数据?
A: 使用分块策略,配置适当的chunk_size和overlap。
9. 总结与展望
9.1 关键要点
- 灵活的配置系统设计
- 完整的模型支持
- 可扩展的工作流
- 高效的查询机制
9.2 未来展望
- 更多模型支持
- 性能优化
- 新特性集成
参考资料
- GraphRAG官方文档
- OpenAI API文档
- Azure OpenAI服务文档
- LanceDB文档
扩展阅读
- 《知识图谱构建最佳实践》
- 《大规模语言模型应用指南》
- 《向量数据库技术详解》
注:本文所有代码示例均经过测试,可直接使用。配置参数可根据实际需求调整。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











