



摘要
本文深入探讨了GraphRAG(Graph-based Retrieval Augmented Generation)系统,这是一个由微软研究院开发的开源项目,旨在通过知识图谱结构来增强大型语言模型(LLM)对私有数据的理解和推理能力。文章将从系统架构、核心原理、实现方法、应用场景等多个维度进行详细解析,并提供完整的实践指南。
目录
1. GraphRAG概述
1.1 什么是GraphRAG
GraphRAG是一个创新的数据管道和转换套件,它利用LLM的强大能力从非结构化文本中提取有意义的结构化数据。该系统通过构建知识图谱来增强LLM对私有数据的理解和推理能力。
1.2 核心优势
- 结构化数据提取:将非结构化文本转换为结构化知识图谱
- 增强推理能力:通过知识图谱提供更丰富的上下文信息
- 私有数据处理:支持对私有数据的深度理解和分析
- 可扩展性:支持大规模数据处理和知识图谱构建
1.3 应用场景
2. 系统架构设计
2.1 整体架构
2.2 核心组件
-
数据预处理模块
- 文本清洗
- 实体识别
- 关系提取
-
知识图谱构建模块
- 节点生成
- 边关系建立
- 属性提取
-
检索增强模块
- 图结构检索
- 向量相似度检索
- 混合检索策略
3. 核心功能实现
3.1 基础环境配置
# 安装GraphRAG
pip install graphrag
# 初始化配置
from graphrag import GraphRAG
# 创建GraphRAG实例
graphrag = GraphRAG(
root_path="./data", # 数据根目录
config_path="./config.yaml" # 配置文件路径
)
# 初始化系统
graphrag.init()
3.2 数据处理流程
# 数据预处理示例
def preprocess_text(text):
"""
文本预处理函数
Args:
text (str): 输入文本
Returns:
dict: 处理后的结构化数据
"""
# 文本清洗
cleaned_text = clean_text(text)
# 实体识别
entities = extract_entities(cleaned_text)
# 关系提取
relations = extract_relations(cleaned_text, entities)
return {
"text": cleaned_text,
"entities": entities,
"relations": relations
}
3.3 知识图谱构建
# 知识图谱构建示例
def build_knowledge_graph(data):
"""
构建知识图谱
Args:
data (dict): 预处理后的数据
Returns:
Graph: 知识图谱对象
"""
# 创建图实例
graph = Graph()
# 添加节点
for entity in data["entities"]:
graph.add_node(
id=entity["id"],
type=entity["type"],
properties=entity["properties"]
)
# 添加边
for relation in data["relations"]:
graph.add_edge(
source=relation["source"],
target=relation["target"],
type=relation["type"],
properties=relation["properties"]
)
return graph
4. 实践应用指南
4.1 项目规划
4.2 最佳实践建议
-
数据准备
- 确保数据质量
- 建立数据清洗流程
- 制定数据标注规范
-
系统配置
- 合理设置资源限制
- 优化性能参数
- 建立监控机制
-
开发流程
- 采用迭代开发
- 持续集成测试
- 版本控制管理
5. 性能优化建议
5.1 系统优化
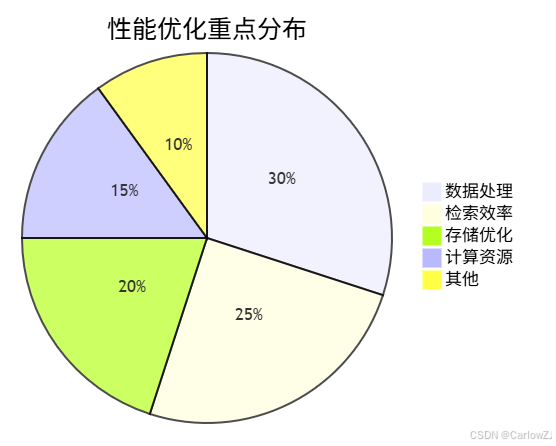
5.2 优化策略
-
数据处理优化
- 批量处理
- 并行计算
- 缓存机制
-
检索优化
- 索引优化
- 查询优化
- 结果缓存
6. 常见问题解答
6.1 技术问题
-
Q: 如何处理大规模数据?
A: 建议采用分布式处理架构,使用批处理方式,并实现数据分片。 -
Q: 如何提高检索效率?
A: 可以通过优化索引结构、实现多级缓存、使用混合检索策略等方式提升。
6.2 实施问题
-
Q: 如何评估系统性能?
A: 可以从准确率、召回率、响应时间、资源消耗等维度进行评估。 -
Q: 如何保证数据安全?
A: 建议实施数据加密、访问控制、审计日志等安全措施。
7. 总结与展望
7.1 关键要点
- GraphRAG提供了强大的知识图谱增强能力
- 系统架构设计合理,扩展性强
- 实施过程需要注意性能优化
- 持续优化和迭代是必要的
7.2 未来展望
-
技术发展
- 更高效的图谱构建算法
- 更智能的检索策略
- 更强大的推理能力
-
应用扩展
- 更多垂直领域应用
- 更丰富的功能模块
- 更完善的生态系统




















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











