



摘要
随着人工智能技术的飞速发展,AI芯片作为其核心硬件支持,正不断取得重大突破。近期,俄勒冈州立大学的研究团队成功研发了一种新型AI芯片,该芯片通过创新的架构设计和优化技术,将大语言模型的能耗降低了50%。这一突破不仅为AI芯片技术的发展注入了新的活力,也为未来智能计算的广泛应用提供了更强大的动力。本文将详细介绍AI芯片的基本原理、架构设计、技术优势,以及在数据中心、边缘计算和智能设备等领域的实际应用案例,并探讨其在实际应用中可能遇到的问题及解决方案,展望AI芯片的未来发展方向。
概念讲解
AI芯片的基本原理
AI芯片是专为人工智能计算任务设计的芯片,其核心原理是通过硬件加速实现高效的神经网络计算。与传统的CPU和GPU相比,AI芯片通过以下方式优化计算性能:
-
并行计算能力:AI芯片通常采用大规模并行架构,能够同时处理大量的数据和计算任务,显著提高计算效率。
-
专用指令集:针对神经网络的计算特点,AI芯片设计了专用的指令集,能够更高效地执行矩阵运算、卷积运算等操作。
-
内存优化:AI芯片通过优化内存访问路径和增加片上缓存,减少了数据传输的延迟和功耗。
架构设计
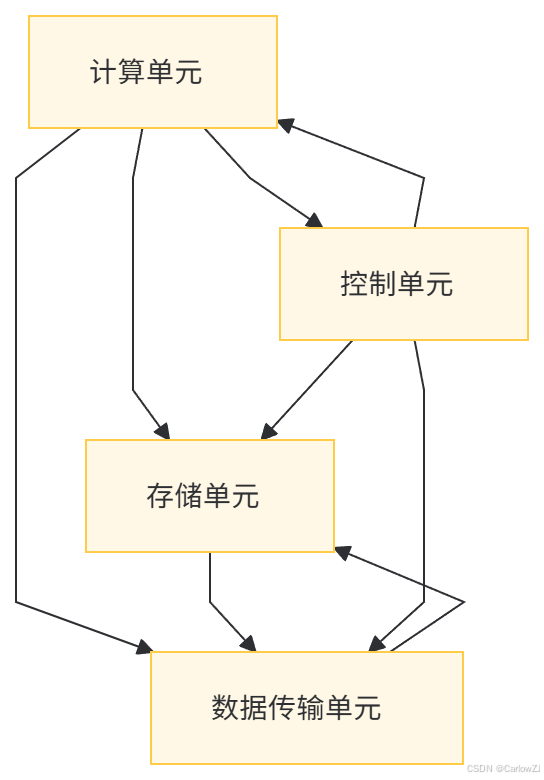
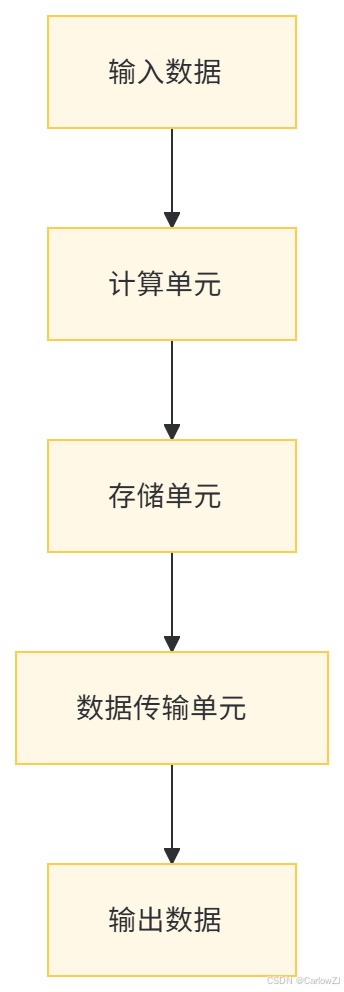
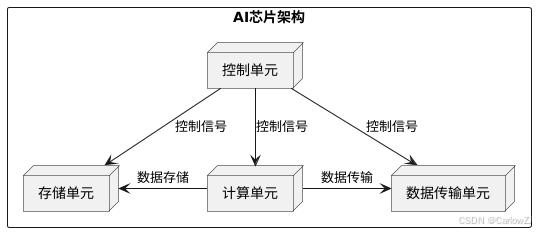
AI芯片的架构设计主要包括以下几个关键部分:
-
计算单元:这是AI芯片的核心部分,通常由多个处理单元组成,负责执行神经网络的计算任务。
-
存储单元:用于存储模型参数和中间计算结果,常见的存储单元包括片上缓存和外部存储器。
-
数据传输单元:负责在计算单元和存储单元之间高效传输数据,常见的技术包括片上网络(NoC)和高速总线。
-
控制单元:负责协调芯片的整体运行,包括任务调度、指令解析和状态管理。
技术优势
-
降低能耗:通过优化架构设计和采用先进的制造工艺,AI芯片能够在保持高性能的同时显著降低能耗。例如,俄勒冈州立大学研发的新型AI芯片通过创新的能耗管理技术,将大语言模型的能耗降低了50%。
-
提升性能:AI芯片的并行计算能力和专用指令集使其在处理大规模神经网络时表现出色,能够显著提高模型训练和推理的速度。
-
高集成度:AI芯片通常将多个功能模块集成在一个芯片上,减少了外部通信的延迟和功耗,提高了系统的整体性能。
代码示例
以下是一个使用Python和TensorFlow框架的代码示例,展示如何在AI芯片上进行模型训练和推理。请注意,此代码需要在支持AI芯片的环境中运行。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten
# 检查是否支持AI芯片加速
if tf.config.list_physical_devices('GPU'):
print("Using GPU for acceleration")
else:
print("No GPU found, using CPU")
# 构建一个简单的卷积神经网络模型
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 加载数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 评估模型
loss, accuracy = model.evaluate(x_test, y_test)
print(f"Test accuracy: {accuracy:.2f}")代码说明
-
GPU检查:通过
tf.config.list_physical_devices('GPU')检查是否支持GPU加速。如果支持,将使用GPU进行计算,否则使用CPU。 -
模型构建:使用TensorFlow的
Sequential模型构建一个简单的卷积神经网络,包括卷积层、全连接层和输出层。 -
数据加载:加载MNIST数据集,并对数据进行归一化处理。
-
模型训练:调用
model.fit方法进行模型训练。 -
模型评估:调用
model.evaluate方法评估模型在测试集上的性能。
应用场景
数据中心
在数据中心,AI芯片被广泛应用于大规模模型训练和推理任务。例如,谷歌的TPU(Tensor Processing Unit)是一种专为TensorFlow设计的AI芯片,能够在短时间内完成大规模神经网络的训练任务。通过使用AI芯片,数据中心可以显著提高计算效率,降低能耗成本。
边缘计算
边缘计算场景中,AI芯片能够为智能设备提供实时的计算能力。例如,智能摄像头可以使用AI芯片进行实时图像识别和分析,无需将数据传输到云端,从而提高了数据处理的效率和安全性。
智能设备
在智能设备中,AI芯片的应用也非常广泛。例如,苹果的A系列芯片集成了专用的神经引擎,能够支持设备上的语音识别、图像处理等功能。通过使用AI芯片,智能设备可以在本地完成复杂的计算任务,减少对云端的依赖,提高用户体验。
注意事项
芯片兼容性
在实际应用中,不同厂商的AI芯片可能存在兼容性问题。例如,某些深度学习框架可能对特定芯片的支持不够完善,导致性能下降或无法运行。解决方法是选择与主流框架兼容性良好的芯片,或者对框架进行定制化开发。
开发成本
AI芯片的开发成本较高,包括硬件设计、制造和软件开发等多个环节。对于中小企业来说,开发自己的AI芯片可能面临较大的经济压力。一种解决方案是与芯片制造商合作,利用其现有的芯片平台进行应用开发。
散热问题
AI芯片在运行时会产生大量热量,散热问题是一个重要的考虑因素。如果散热不良,可能导致芯片性能下降甚至损坏。解决方法是采用高效的散热技术,如液冷散热或风冷散热,并优化芯片的功耗管理。
架构图和流程图
AI芯片架构图(Mermaid格式)
数据流图(Mermaid格式)
高清架构图和流程图(PlantUML生成)
以下是一个PlantUML代码示例,用于生成高清的架构图和流程图。
饼图
以下是一个使用Python的Matplotlib库生成的AI芯片在不同领域的应用分布饼图的代码示例:
import matplotlib.pyplot as plt
# 应用领域及其占比
labels = ['数据中心', '边缘计算', '智能设备']
sizes = [30, 30, 40]
# 绘制饼图
plt.figure(figsize=(8, 6))
plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('AI芯片在不同领域的应用分布')
plt.show()总结
AI芯片作为人工智能技术的核心硬件支持,正不断取得重大突破。其在降低能耗、提升性能和高集成度方面的优势使其在数据中心、边缘计算和智能设备等领域得到了广泛应用。然而,AI芯片也面临着开发成本高、散热问题和兼容性问题等挑战。未来,随着量子芯片、光子芯片等新型芯片技术的发展,AI芯片将为智能计算提供更强大的动力,推动人工智能技术的进一步发展。
引用
-
"AI芯片技术的最新进展." 俄勒冈州立大学研究团队论文
-
"TensorFlow官方文档." TensorFlow官网
-
"AI芯片在数据中心的应用." 数据中心杂志
-
"边缘计算中的AI芯片." 边缘计算论坛





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











