



摘要
在当今数字化时代,数据隐私和安全问题日益凸显。传统的集中式机器学习方法往往需要将数据集中存储和处理,这不仅增加了数据泄露的风险,还可能受到数据所有权和隐私法规的限制。联邦学习作为一种新兴的分布式机器学习技术,为解决这些问题提供了新的思路。它通过在多个参与方之间协作训练模型,能够在不共享原始数据的情况下实现高效的模型优化,同时保护数据隐私。本文将详细介绍联邦学习的基本原理、关键术语、代码实现、应用场景以及注意事项,并通过Mermaid格式绘制架构图和数据流图,帮助读者全面深入地理解联邦学习的核心内容。
一、概念讲解
(一)联邦学习的基本原理
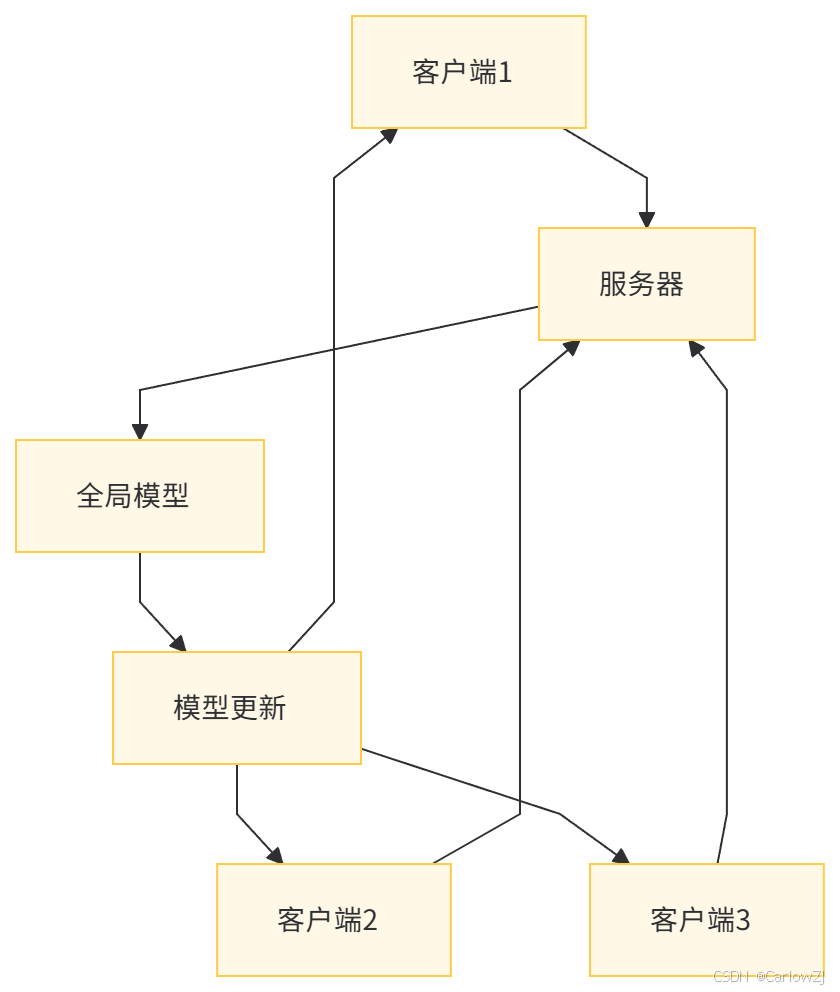
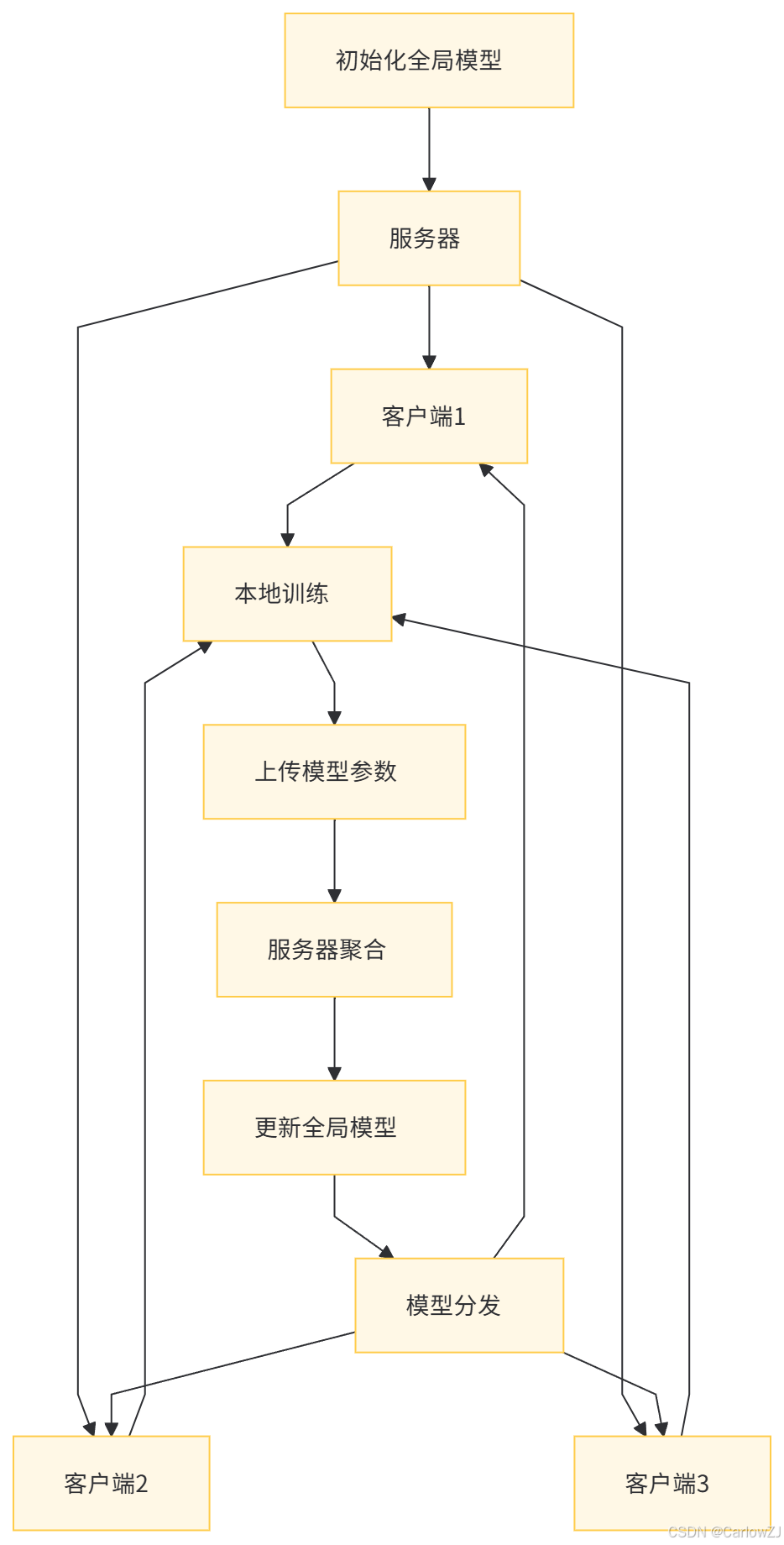
联邦学习是一种分布式机器学习框架,其核心思想是将模型训练过程分解为多个局部训练步骤,并通过加密通信等方式确保数据隐私。在联邦学习中,数据所有者(客户端)在本地对数据进行模型训练,仅共享模型参数,而不是原始数据。服务器负责协调客户端的训练过程,聚合模型参数并更新全局模型。通过这种方式,联邦学习能够在保护数据隐私的同时,充分利用分散在不同客户端的数据资源,提高模型的性能和泛化能力。
(二)关键术语
-
客户端(Client):数据所有者,负责在本地进行模型训练并上传模型参数。
-
服务器(Server):协调客户端的训练过程,聚合模型参数并更新全局模型。
-
全局模型(Global Model):由服务器维护,整合所有客户端的训练结果。
-
本地模型(Local Model):客户端在本地数据上训练的模型。
-
模型聚合(Model Aggregation):服务器将多个客户端的模型参数进行加权平均或其他聚合方法,更新全局模型。
(三)与其他技术的对比
-
与集中式机器学习的对比
-
数据存储:集中式机器学习需要将所有数据集中存储在一个中心服务器上,而联邦学习允许数据保留在客户端本地。
-
隐私保护:集中式机器学习存在数据泄露风险,联邦学习通过加密通信和本地训练保护数据隐私。
-
模型性能:集中式机器学习可能受到数据分布不均的影响,联邦学习能够整合多个数据源的信息,提高模型的泛化能力。
-
-
与分布式机器学习的对比
-
数据共享:分布式机器学习通常需要在节点之间共享部分数据,联邦学习则完全不共享原始数据。
-
通信开销:分布式机器学习的通信开销主要集中在数据传输上,联邦学习的通信开销主要集中在模型参数的传输上。
-
容错性:分布式机器学习对节点的可靠性要求较高,联邦学习对客户端的容错性更强,即使部分客户端离线,也不会影响全局模型的更新。
-
二、代码示例
(一)环境搭建
在开始联邦学习的代码实现之前,我们需要准备相应的开发环境。以下是一个基于Python和TensorFlow Federated(TFF)的环境搭建示例:
# 安装TensorFlow和TensorFlow Federated
!pip install tensorflow==2.8.0
!pip install tensorflow-federated==0.22.0
(二)模型训练
接下来,我们将通过一个简单的联邦学习示例来展示如何进行模型训练。假设我们有一个简单的线性回归模型,用于预测房价。
import tensorflow as tf
import tensorflow_federated as tff
import numpy as np
# 模拟数据生成
def create_data():
client_data = []
for i in range(3): # 假设有3个客户端
x = np.random.rand(100, 1) # 每个客户端有100个样本
y = 3 * x + 2 + np.random.randn(100, 1) / 1.0 # 添加噪声
client_data.append((x, y))
return client_data
client_data = create_data()
# 定义模型
def create_keras_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape=(1,))
])
return model
def model_fn():
keras_model = create_keras_model()
return tff.learning.models.from_keras_model(
keras_model,
input_spec=client_data[0],
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.MeanSquaredError()]
)
# 联邦学习算法
fed_avg = tff.learning.algorithms.build_unweighted_fed_avg(
model_fn=model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0)
)
# 模拟联邦学习训练过程
state = fed_avg.initialize()
for round_num in range(10):
state, metrics = fed_avg.next(state, client_data)
print(f'Round {round_num}: {metrics}')
(三)结果展示
在训练完成后,我们可以通过以下代码展示模型的预测结果:
# 获取全局模型
global_model = create_keras_model()
global_model.compile(optimizer='sgd', loss='mean_squared_error')
global_model.set_weights(state.model_weights.trainable)
# 测试数据
test_x = np.random.rand(10, 1)
test_y = 3 * test_x + 2
# 预测
predictions = global_model.predict(test_x)
print("Predictions:", predictions)
print("True values:", test_y)
三、应用场景
(一)医疗领域
在医疗领域,数据隐私和患者信息安全至关重要。联邦学习可以用于多医院之间的医学图像分析、疾病预测等任务,无需共享患者数据,从而保护患者隐私。例如,多个医院可以联合训练一个医学影像诊断模型,每个医院只需在本地对患者的影像数据进行模型训练,并将模型参数上传至中央服务器进行聚合。这样,不仅可以提高模型的准确性,还可以避免患者数据的泄露。
(二)金融领域
金融机构可以利用联邦学习整合不同地区的客户数据,进行风险评估和欺诈检测,同时避免数据泄露风险。例如,多家银行可以联合训练一个信用评分模型,每个银行只需在本地对客户的交易数据进行模型训练,并将模型参数上传至中央服务器进行聚合。这样,不仅可以提高模型的泛化能力,还可以保护客户的隐私。
(三)物联网
在物联网设备中,数据分散在各个设备上。联邦学习可以在设备端进行模型训练,减少数据传输开销,同时提高模型的实时性和隐私性。例如,智能家居设备可以联合训练一个能源管理模型,每个设备只需在本地对自身的能耗数据进行模型训练,并将模型参数上传至中央服务器进行聚合。这样,不仅可以优化能源管理,还可以保护用户的隐私。
四、注意事项
(一)数据异构性
不同客户端的数据分布可能存在差异,这可能导致模型训练的不均衡。例如,某些客户端的数据可能具有较高的噪声,或者某些客户端的数据分布与全局数据分布不一致。为了解决这个问题,可以采用以下方法:
-
数据预处理:对客户端的数据进行标准化、归一化等预处理操作,减少数据分布的差异。
-
算法优化:采用自适应学习率、权重调整等算法优化方法,提高模型对不同客户端数据的适应性。
-
数据采样:对客户端的数据进行采样,确保每个客户端的数据具有代表性。
(二)通信开销
联邦学习需要频繁的客户端与服务器之间的通信,可能会导致较高的通信开销。例如,当客户端数量较多或模型参数较大时,通信时间可能会显著增加。为了解决这个问题,可以采用以下方法:
-
模型压缩:对模型参数进行压缩,减少通信数据量。例如,可以采用量化、稀疏化等技术,将模型参数压缩为更小的表示形式。
-
通信优化:采用高效的通信协议和算法,减少通信延迟。例如,可以采用异步通信、批量通信等技术,提高通信效率。
-
本地更新:增加客户端的本地更新次数,减少与服务器的通信频率。
(三)安全与隐私
虽然联邦学习在一定程度上保护了数据隐私,但仍需考虑模型参数泄露等潜在风险。例如,攻击者可能通过分析模型参数来推断客户端的数据分布或敏感信息。为了解决这个问题,可以采用以下方法:
-
加密技术:采用加密技术对模型参数进行加密,确保通信过程的安全性。例如,可以采用同态加密、差分隐私等技术,保护模型参数的隐私。
-
访问控制:对服务器和客户端进行严格的访问控制,确保只有授权的用户可以访问模型参数。
-
安全审计:定期对联邦学习系统进行安全审计,发现并修复潜在的安全漏洞。
五、架构图和流程图
(一)架构图
(二)流程图
六、总结
联邦学习作为一种新兴的分布式机器学习技术,为解决数据隐私保护和模型优化之间的矛盾提供了新的思路。它通过在多个参与方之间协作训练模型,能够在不共享原始数据的情况下实现高效的模型优化,同时保护数据隐私。本文详细介绍了联邦学习的基本原理、代码实现、应用场景以及注意事项,并通过Mermaid格式绘制了架构图和数据流图,帮助读者全面深入地理解联邦学习的核心内容。
尽管联邦学习具有诸多优势,但它仍然面临着一些挑战。例如,数据异构性、通信开销和安全与隐私等问题需要进一步研究和解决。未来,联邦学习有望在更多领域得到广泛应用,如医疗、金融、物联网等。随着技术的不断发展和创新,联邦学习将为分布式机器学习的发展注入新的活力,推动人工智能技术的进一步发展。



















 2095
2095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











