



摘要
自然语言处理(NLP)是人工智能领域中一个极具挑战性和应用前景的方向。近年来,深度学习技术的发展为NLP带来了突破性的进展。本文将详细介绍基于深度学习的自然语言处理技术的基本概念、核心模型、开发流程以及典型应用场景。通过实际代码示例和架构图,帮助读者快速理解和掌握如何利用深度学习技术解决自然语言处理中的问题。同时,本文还将探讨在开发过程中需要注意的事项,以及未来的发展趋势。
一、引言
自然语言处理(NLP)的目标是使计算机能够理解、生成和处理人类语言。随着互联网的普及和大数据时代的到来,文本数据的数量呈爆炸式增长,NLP技术的重要性日益凸显。深度学习技术的出现为NLP带来了新的机遇,使得机器能够更好地理解和生成自然语言。本文将深入探讨基于深度学习的NLP技术,分析其优势和挑战,并展望未来的发展方向。
二、自然语言处理的基本概念
(一)定义
自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,旨在使计算机能够理解、生成和处理人类语言。其目标是开发能够与人类自然交互的智能系统。
(二)主要任务
-
文本分类:将文本分配到预定义的类别中,如情感分析、主题分类等。
-
文本生成:自动生成自然语言文本,如聊天机器人、文本摘要等。
-
机器翻译:将一种语言的文本自动翻译成另一种语言。
-
命名实体识别(NER):从文本中识别出具有特定意义的实体,如人名、地名、组织名等。
-
情感分析:判断文本中所表达的情感倾向,如正面、负面或中性。
-
问答系统:自动回答用户的问题,如智能客服、知识问答等。
三、深度学习在NLP中的应用
(一)词嵌入(Word Embedding)
词嵌入是将单词映射到高维向量空间的技术,使得语义相近的单词在向量空间中距离更近。常用的词嵌入方法包括Word2Vec、GloVe和BERT。
(二)循环神经网络(RNN)
循环神经网络(RNN)及其变体(如LSTM和GRU)能够处理序列数据,适用于文本生成、机器翻译等任务。
(三)卷积神经网络(CNN)
卷积神经网络(CNN)在图像处理中表现出色,也可以应用于文本分类等任务,通过卷积层提取文本的局部特征。
(四)Transformer架构
Transformer架构通过自注意力机制(Self-Attention)处理序列数据,显著提高了模型的性能和效率,BERT、GPT等预训练模型均基于此架构。
四、基于深度学习的NLP开发流程
(一)数据准备
-
数据收集:收集与任务相关的文本数据,如新闻文章、社交媒体帖子、用户评论等。
-
数据清洗:去除噪声数据,如HTML标签、特殊字符等。
-
数据标注:根据任务需求对数据进行标注,如情感分类标签、实体标签等。
(二)模型选择与训练
-
模型选择:根据任务选择合适的深度学习模型,如RNN、CNN、Transformer等。
-
模型训练:使用标注好的数据对模型进行训练,调整超参数以优化模型性能。
(三)模型评估与优化
-
模型评估:使用测试集对模型进行评估,常用的指标包括准确率、召回率、F1值等。
-
模型优化:通过正则化、数据增强、模型融合等方法优化模型性能。
(四)系统部署与应用
-
系统部署:将训练好的模型部署到实际应用中,如Web服务、移动应用等。
-
在线优化:根据用户反馈实时优化模型,提高系统的性能和用户体验。
五、代码示例
(一)基于BERT的情感分析
import torch
from transformers import BertTokenizer, BertForSequenceClassification
# 加载预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 示例文本
text = "I love this product!"
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True, max_length=512)
# 模型推理
with torch.no_grad():
outputs = model(**inputs)
# 获取预测结果
logits = outputs.logits
predicted_class = torch.argmax(logits).item()
print(f"Predicted class: {predicted_class}")
(二)基于LSTM的文本生成
import torch
import torch.nn as nn
class LSTMTextGenerator(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(LSTMTextGenerator, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x)
x = self.fc(x[:, -1, :])
return x
# 示例训练
vocab_size = 10000 # 示例词汇表大小
embedding_dim = 128
hidden_dim = 256
model = LSTMTextGenerator(vocab_size, embedding_dim, hidden_dim)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 假设输入数据和标签
inputs = torch.randint(0, vocab_size, (32, 10)) # 示例输入
labels = torch.randint(0, vocab_size, (32,))
# 训练模型
for epoch in range(10):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
六、基于深度学习的NLP架构图

七、基于深度学习的NLP数据流图
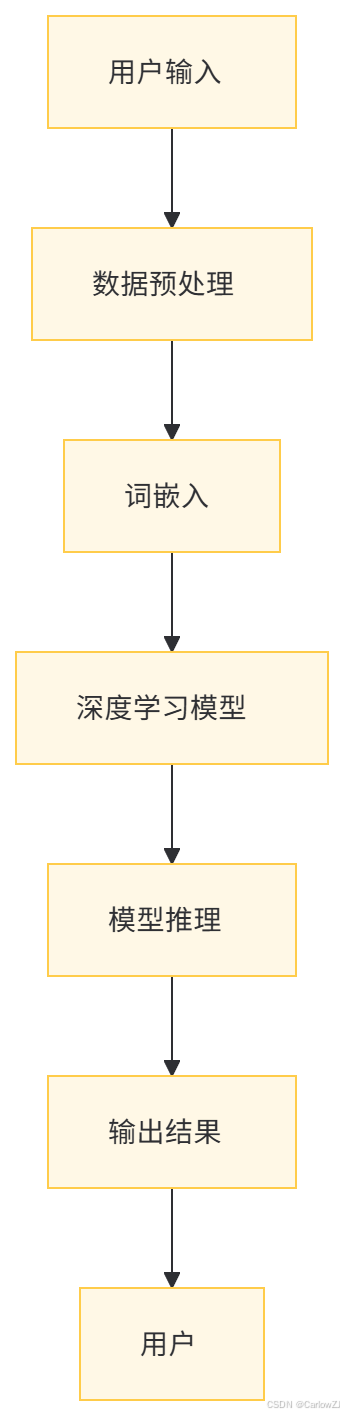
八、基于深度学习的NLP应用场景
(一)情感分析
-
社交媒体监控:分析用户在社交媒体上的评论,判断其情感倾向,帮助企业了解用户反馈。
-
产品评价分析:分析用户对产品的评价,提取正面和负面意见,辅助产品改进。
(二)机器翻译
-
跨语言交流:实时翻译不同语言之间的对话,促进国际交流。
-
文档翻译:将文档从一种语言翻译成另一种语言,提高工作效率。
(三)文本生成
-
聊天机器人:生成自然语言回复,实现人机交互。
-
内容创作:辅助创作文章、故事等文本内容。
(四)问答系统
-
智能客服:自动回答用户问题,提高客户服务效率。
-
知识问答:提供专业知识解答,如医学、法律等领域。
(五)命名实体识别
-
信息抽取:从新闻、文档中抽取关键信息,如人名、地名、组织名等。
-
知识图谱构建:为知识图谱提供实体和关系信息。
九、基于深度学习的NLP开发注意事项
(一)数据质量
-
数据标注准确性:确保标注数据的准确性,避免因标注错误导致模型性能下降。
-
数据多样性:收集多样化的数据,以提高模型的泛化能力。
(二)模型选择
-
任务适配性:根据具体任务选择合适的模型架构,如RNN适用于序列生成,CNN适用于文本分类。
-
计算资源:考虑模型的计算复杂度和硬件需求,选择适合的模型。
(三)模型优化
-
超参数调整:通过交叉验证等方法调整超参数,优化模型性能。
-
正则化技术:使用Dropout、L2正则化等技术防止过拟合。
(四)伦理和法律问题
-
数据隐私保护:在数据收集和使用过程中,严格保护用户隐私。
-
内容审核:确保生成的文本内容符合法律法规和道德标准。
十、总结
基于深度学习的自然语言处理技术已经在多个领域取得了显著的成果,并广泛应用于实际场景中。本文详细介绍了深度学习在NLP中的基本概念、开发流程、代码示例以及应用场景。通过合理选择模型架构、优化模型性能和注意开发过程中的伦理问题,可以构建高效、准确的NLP系统。未来,随着深度学习技术的不断发展,NLP将在更多领域发挥更大的作用,为人类生活和工作带来更多的便利。
十一、参考文献
-
[1] 《自然语言处理入门》
-
[2] 《深度学习在自然语言处理中的应用》
-
[3] 《BERT模型原理与应用》
-
[4] 《循环神经网络及其变体》
-
[5] 《Transformer架构详解》




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











