 基于人工智能的智能推荐系统详解
基于人工智能的智能推荐系统详解




摘要
智能推荐系统是人工智能领域的重要应用之一,广泛应用于电子商务、内容平台、金融等多个行业。本文将详细介绍智能推荐系统的概念、原理、架构设计、开发流程以及应用场景。通过实际代码示例和架构图,帮助读者快速理解和掌握如何构建一个高效的智能推荐系统。同时,本文还将探讨在开发过程中需要注意的事项,以及未来的发展趋势。
一、引言
在信息爆炸的时代,用户面临着海量的选择,如何快速找到自己感兴趣的内容或商品成为了一个重要问题。智能推荐系统应运而生,它通过分析用户的行为数据和偏好信息,为用户提供个性化的推荐内容。本文将深入探讨智能推荐系统的原理、开发路径和应用场景,帮助读者全面了解这一领域。
二、智能推荐系统的概念与分类
(一)概念
智能推荐系统是一种通过分析用户行为和偏好信息,为用户提供个性化推荐内容的系统。它可以帮助用户快速发现感兴趣的商品、文章、视频等,提高用户体验和平台的用户粘性。
(二)分类
-
基于内容的推荐:根据用户的历史行为和偏好,推荐与用户之前喜欢的内容相似的项目。
-
协同过滤推荐:通过分析用户之间的相似性或项目之间的相似性,推荐用户可能感兴趣的项目。
-
基于模型的推荐:利用机器学习或深度学习模型,对用户行为数据进行建模,预测用户的兴趣。
-
混合推荐:结合多种推荐方法,以提高推荐的准确性和多样性。
三、智能推荐系统的架构设计
(一)架构图
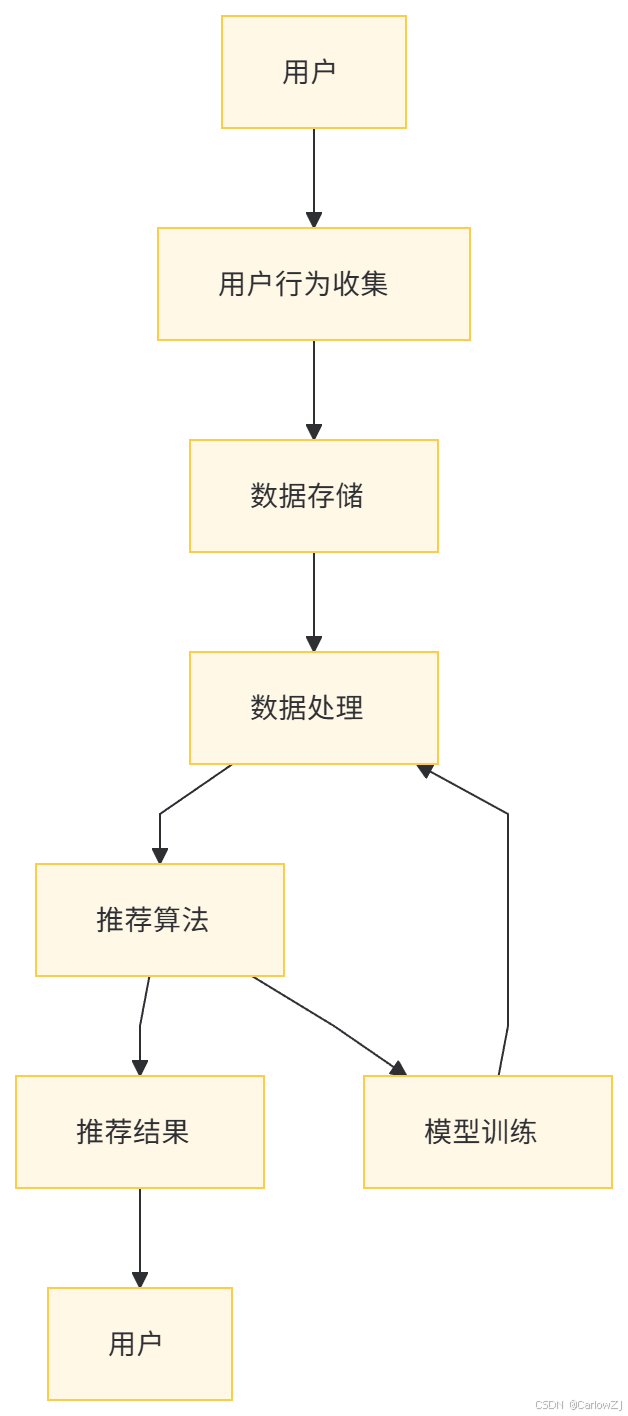
(二)组件说明
-
用户行为收集:通过日志系统收集用户的行为数据,如点击、购买、浏览等。
-
数据存储:将收集到的数据存储到数据库中,如MySQL、Hadoop等。
-
数据处理:对数据进行清洗、转换和特征提取,以便用于推荐算法。
-
推荐算法:根据选择的推荐方法(如协同过滤、基于内容的推荐等)进行推荐计算。
-
模型训练:对于基于模型的推荐系统,需要定期对模型进行训练和优化。
-
推荐结果:将推荐结果展示给用户,用户可以通过反馈进一步优化推荐系统。
四、智能推荐系统的开发流程
(一)需求分析
明确推荐系统的应用场景、目标用户群体和推荐内容类型。
(二)数据收集与处理
-
数据收集:通过日志系统收集用户的行为数据,包括点击、购买、浏览等。
-
数据清洗:去除噪声数据和异常值。
-
特征提取:从用户行为数据中提取有用的特征,如用户兴趣标签、行为频率等。
(三)选择推荐算法
根据应用场景选择合适的推荐算法,如协同过滤、基于内容的推荐或深度学习模型。
(四)模型训练与评估
-
模型训练:使用标注好的数据对推荐模型进行训练。
-
模型评估:通过准确率、召回率、F1值等指标评估模型性能。
(五)系统部署与优化
-
系统部署:将训练好的模型部署到实际的推荐系统中。
-
在线优化:根据用户的实时反馈,动态调整推荐结果。
五、代码示例
(一)基于协同过滤的推荐
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 示例用户-项目评分矩阵
ratings = np.array([
[5, 3, 0, 1],
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4],
])
# 计算用户之间的相似度
user_similarity = cosine_similarity(ratings)
# 预测用户对项目的评分
def predict_ratings(user_index, ratings, user_similarity):
weighted_sum = np.dot(user_similarity[user_index], ratings)
sum_of_weights = np.sum(np.abs(user_similarity[user_index]) - 1)
user_prediction = weighted_sum / sum_of_weights
return user_prediction
# 示例预测
predicted_ratings = predict_ratings(0, ratings, user_similarity)
print(predicted_ratings)
(二)基于内容的推荐
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
# 示例项目内容
documents = [
"Science is amazing",
"I love reading science fiction books",
"Mathematics is the queen of sciences",
"Fiction books are great for leisure",
]
# 使用TF-IDF提取项目内容的特征
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(documents)
# 计算项目之间的相似度
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
# 推荐与目标项目相似的项目
def recommend_items(item_index, cosine_sim, documents, top_n=2):
sim_scores = list(enumerate(cosine_sim[item_index]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:top_n+1]
item_indices = [i[0] for i in sim_scores]
return [documents[i] for i in item_indices]
# 示例推荐
recommended_items = recommend_items(0, cosine_sim, documents)
print(recommended_items)
六、智能推荐系统的应用场景
(一)电子商务
-
商品推荐:根据用户的浏览和购买历史,推荐用户可能感兴趣的商品。
-
个性化首页:根据用户的兴趣,动态生成个性化的首页内容。
(二)内容平台
-
文章推荐:根据用户的阅读历史,推荐相关的文章或新闻。
-
视频推荐:根据用户的观看历史,推荐用户可能喜欢的视频内容。
(三)金融领域
-
理财产品推荐:根据用户的资产状况和风险偏好,推荐合适的理财产品。
-
信用卡推荐:根据用户的消费习惯,推荐适合的信用卡产品。
(四)社交平台
-
好友推荐:根据用户的社交关系和兴趣,推荐可能认识的人。
-
群组推荐:根据用户的兴趣,推荐相关的群组或社区。
七、智能推荐系统的注意事项
(一)数据隐私与安全
-
数据加密:对用户数据进行加密处理,确保数据的安全性。
-
隐私保护:明确告知用户数据的使用方式,保护用户隐私。
(二)模型性能与优化
-
实时性:推荐系统需要具备实时性,及时响应用户的行为变化。
-
多样性:推荐结果需要具备多样性,避免过度集中于少数项目。
(三)冷启动问题
-
新用户冷启动:对于新用户,可以采用基于人口统计学信息的推荐。
-
新项目冷启动:对于新项目,可以通过内容分析进行推荐。
(四)可扩展性
-
系统架构设计:设计可扩展的系统架构,以应对用户量和数据量的增长。
-
分布式计算:使用分布式计算框架(如Spark)提高系统的处理能力。
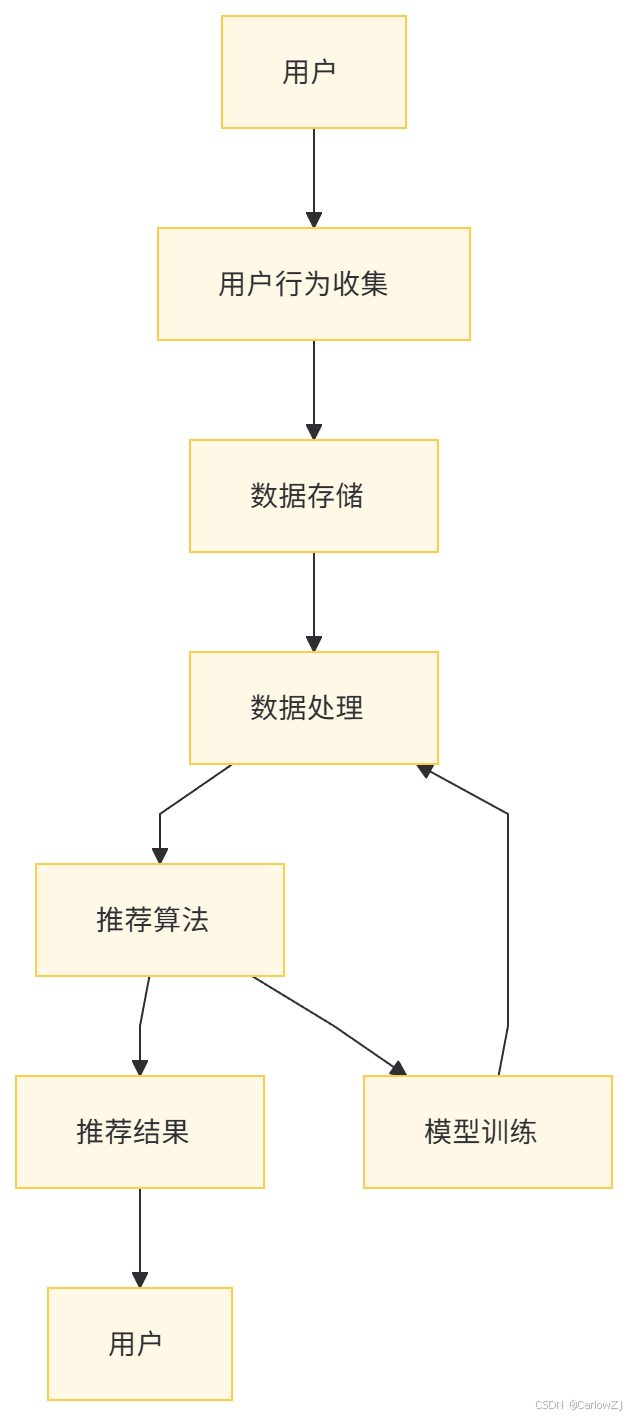
八、智能推荐系统的数据流图
九、总结
智能推荐系统是人工智能领域的重要应用之一,它通过分析用户的行为和偏好,为用户提供个性化的推荐内容。本文详细介绍了智能推荐系统的概念、架构设计、开发流程以及应用场景,并通过代码示例展示了如何实现基于协同过滤和基于内容的推荐算法。在开发智能推荐系统时,需要注意数据隐私与安全、模型性能与优化、冷启动问题以及系统的可扩展性。未来,随着人工智能技术的不断发展,智能推荐系统将在更多领域发挥重要作用,为用户提供更加精准和个性化的服务。
十、参考文献
-
[1] 《智能推荐系统:原理与实践》
-
[2] 《基于深度学习的推荐系统》
-
[3] 《协同过滤推荐算法研究》
-
[4] 《基于内容的推荐系统设计与实现》



















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











