



目录
一、引言
在当今快节奏的数字化世界中,自动化流程已成为提高效率、减少错误和释放人力资源的关键手段。Dify工作流作为一种强大的自动化工具,为企业和个人提供了灵活、高效的解决方案。本文将深入探讨Dify工作流的概念、架构、应用场景、代码示例以及使用时需要注意的事项。
二、Dify工作流的概念讲解
(一)工作流的定义
工作流是一种将业务流程中的任务、数据和资源按照一定规则和顺序进行自动化处理的技术。它通过定义流程的起点、中间环节和终点,将复杂的业务逻辑分解为一系列可管理的步骤,从而实现高效、透明的业务操作。
(二)Dify工作流的特点
-
灵活性 Dify工作流支持多种触发方式,包括时间触发、事件触发等。用户可以根据实际需求自定义工作流的触发条件和执行逻辑。例如,当一个项目管理工具中的任务状态从“待处理”变为“已完成”时,可以自动触发通知相关人员的工作流。
-
可扩展性 Dify工作流允许用户通过插件或API集成第三方应用和服务。例如,可以将Dify工作流与企业现有的CRM系统、ERP系统或云存储服务(如阿里云OSS)进行无缝对接,实现数据的自动同步和业务流程的协同操作。
-
可视化设计 Dify工作流提供可视化的流程设计界面,用户无需编写复杂的代码即可通过拖拽组件、连接节点等方式构建工作流。这种可视化设计方式大大降低了工作流的开发门槛,使非技术背景的业务人员也能轻松上手。
(三)工作流的组成要素
-
节点(Node) 节点是工作流的基本单元,代表一个具体的任务或操作。例如,在一个订单处理工作流中,节点可以是“接收订单”“检查库存”“生成发货单”等。每个节点都有自己的输入参数和输出结果。
-
连接线(Edge) 连接线用于定义节点之间的执行顺序和数据流向。通过连接线,用户可以指定一个节点的输出结果作为另一个节点的输入参数,从而实现节点之间的协同工作。例如,在一个数据处理工作流中,一个数据清洗节点的输出结果可以作为数据分析节点的输入数据。
-
触发器(Trigger) 触发器是工作流的启动条件,用于指定何时开始执行工作流。常见的触发器类型包括时间触发器(如定时任务)、事件触发器(如收到新的电子邮件)等。例如,可以设置一个时间触发器,每天凌晨自动执行数据备份工作流。
-
变量(Variable) 变量用于在工作流中存储和传递数据。它可以是字符串、数字、对象等多种数据类型。例如,在一个用户注册工作流中,可以使用变量存储用户的姓名、邮箱地址等信息,并在后续的节点中使用这些变量完成用户信息的验证和存储操作。
三、Dify工作流的架构图
(一)架构概述
Dify工作流的架构设计充分考虑了可扩展性、灵活性和高可用性。其核心架构可以分为以下几个主要部分:工作流引擎、节点管理器、数据存储、API接口和用户界面。
(二)架构图
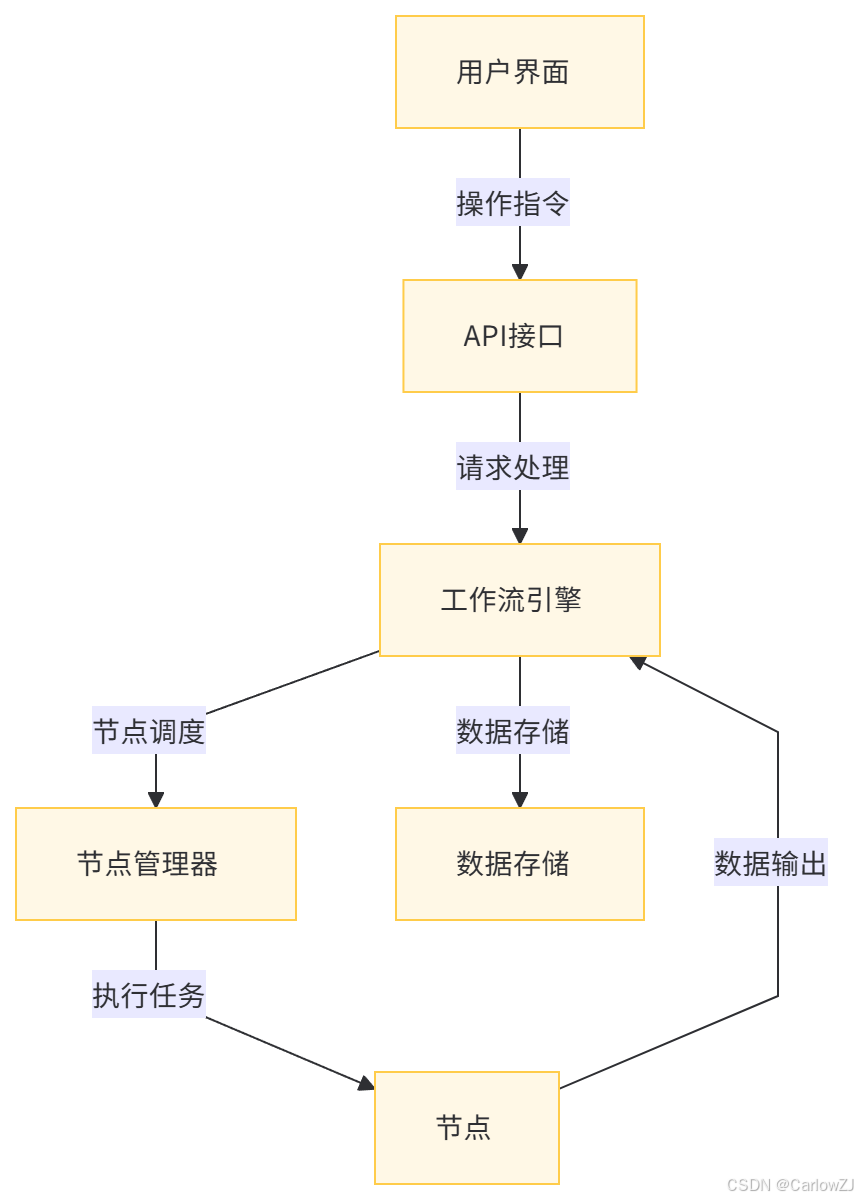
(三)架构组件说明
-
用户界面(UI) 用户界面是用户与Dify工作流交互的入口。它提供了可视化的流程设计工具、工作流管理功能和监控界面。用户可以通过拖拽组件、配置参数等方式在用户界面上设计和管理自己的工作流。
-
API接口 API接口是Dify工作流与其他系统进行通信的桥梁。它提供了丰富的接口方法,允许用户通过编程方式创建、更新、删除工作流,以及启动、停止和监控工作流的执行状态。例如,可以通过API接口将Dify工作流集成到企业现有的开发平台中,实现工作流的自动化管理和调度。
-
工作流引擎 工作流引擎是Dify工作流的核心组件,负责解析工作流定义、调度节点执行和管理工作流的运行状态。它根据用户定义的工作流逻辑,按照节点之间的连接关系和触发条件,依次执行各个节点的任务,并在执行过程中处理数据的传递和异常情况。
-
节点管理器 节点管理器负责管理和调度工作流中的节点。它接收工作流引擎的调度指令,根据节点的类型和配置参数,启动相应的节点任务,并将节点的执行结果反馈给工作流引擎。节点管理器还支持对节点的动态加载和卸载,方便用户根据需要扩展工作流的功能。
-
数据存储 数据存储用于保存工作流的定义、执行状态和相关数据。它支持多种存储方式,如关系型数据库、非关系型数据库或云存储服务。通过数据存储,用户可以方便地查询和管理自己的工作流历史记录,以及对工作流中的数据进行持久化存储。
四、Dify工作流的应用场景
(一)自动化办公流程
-
文档审批流程 在企业中,文档审批是一个常见的办公流程。通过Dify工作流,可以将文档审批流程自动化。例如,当员工提交一份报销单时,Dify工作流可以自动将报销单发送给直接上级进行审批。如果上级审批通过,则自动将报销单发送给财务部门进行付款处理;如果审批不通过,则将报销单退回给员工并附上审批意见。整个审批流程无需人工干预,大大提高了审批效率。
-
会议安排流程 会议安排也是一个繁琐的办公任务。Dify工作流可以根据会议主题、参会人员和时间要求,自动安排会议时间和地点。例如,当用户在工作流中输入会议主题和参会人员名单后,Dify工作流可以查询参会人员的日程安排,找到一个所有人都有空的时间段,并自动预订会议室。同时,它还可以向参会人员发送会议通知,提醒他们参加会议。
(二)数据处理与分析
-
数据清洗与预处理 在数据分析项目中,数据清洗和预处理是一个重要的步骤。Dify工作流可以自动化地完成数据清洗和预处理任务。例如,可以定义一个工作流,从多个数据源(如数据库、Excel文件等)读取数据,然后通过一系列的清洗节点(如去除重复数据、填补缺失值等)对数据进行清洗。清洗后的数据可以自动存储到指定的数据仓库中,供后续的数据分析节点使用。
-
数据分析与报告生成 Dify工作流还可以用于数据分析和报告生成。例如,可以定义一个工作流,定期从数据仓库中提取数据,使用数据分析工具(如Python的Pandas库)进行数据分析,然后根据分析结果生成报告。报告可以以PDF、Excel等格式保存,并自动发送给相关人员。通过这种方式,用户可以及时获取数据分析结果,为决策提供支持。
(三)业务流程自动化
-
客户订单处理 在电商行业中,客户订单处理是一个关键的业务流程。Dify工作流可以实现客户订单的自动化处理。例如,当客户在电商平台上提交订单时,Dify工作流可以自动接收订单信息,检查库存是否充足。如果库存充足,则生成发货单并通知仓库发货;如果库存不足,则自动向客户发送缺货通知,并将订单标记为待处理状态。同时,Dify工作流还可以将订单处理状态实时更新到订单管理系统中,方便客户和客服人员查询。
-
供应链管理 供应链管理涉及到多个环节,如采购、生产、物流等。Dify工作流可以将这些环节进行自动化连接。例如,当库存管理系统中的库存低于安全库存时,Dify工作流可以自动触发采购工作流,向供应商发送采购订单。采购订单完成后,Dify工作流可以自动通知生产部门安排生产计划,并跟踪物流信息,确保货物按时到达仓库。通过这种方式,企业可以实现供应链的高效协同,降低运营成本。
五、Dify工作流的代码示例
(一)简单的工作流定义
以下是一个简单的Dify工作流定义示例,用于实现一个定时发送邮件的任务:
JSON
复制
{
"nodes": [
{
"id": "node1",
"type": "timer",
"params": {
"interval": "0 0 * * *", // 每天凌晨执行
"output": {
"message": "Hello, this is a scheduled email."
}
}
},
{
"id": "node2",
"type": "email",
"params": {
"to": "example@example.com",
"subject": "Scheduled Email",
"body": "{{node1.output.message}}"
}
}
],
"edges": [
{
"source": "node1",
"target": "node2"
}
]
}在这个工作流中,node1是一个定时节点,用于触发工作流的执行。它按照0 0 * * *的Cron表达式(每天凌晨)触发。node2是一个邮件节点,用于发送邮件。邮件的内容从node1的输出结果中获取。
(二)带有条件分支的工作流
以下是一个带有条件分支的工作流示例,用于处理客户订单:
JSON
复制
{
"nodes": [
{
"id": "node1",
"type": "order_received",
"params": {
"order_id": "{{input.order_id}}",
"output": {
"order_info": {
"id": "{{input.order_id}}",
"product": "Product A",
"quantity": 2
}
}
}
},
{
"id": "node2",
"type": "check_inventory",
"params": {
"product": "{{node1.output.order_info.product}}",
"quantity": "{{node1.output.order_info.quantity}}",
"output": {
"inventory_status": "available"
}
}
},
{
"id": "node3",
"type": "generate_shipping_order",
"params": {
"order_info": "{{node1.output.order_info}}",
"output": {
"shipping_order_id": "SH12345"
}
}
},
{
"id": "node4",
"type": "notify_customer",
"params": {
"order_id": "{{node1.output.order_info.id}}",
"message": "Your order has been shipped. Shipping Order ID: {{node3.output.shipping_order_id}}"
}
},
{
"id": "node5",
"type": "notify_customer",
"params": {
"order_id": "{{node1.output.order_info.id}}",
"message": "Sorry, your order is out of stock."
}
}
],
"edges": [
{
"source": "node1",
"target": "node2"
},
{
"source": "node2",
"target": "node3",
"condition": "{{node2.output.inventory_status == 'available'}}"
},
{
"source": "node2",
"target": "node5",
"condition": "{{node2.output.inventory_status != 'available'}}"
},
{
"source": "node3",
"target": "node4"
}
]
}在这个工作流中,node1接收客户订单信息,node2检查库存是否充足。如果库存充足(inventory_status == 'available'),则执行node3生成发货单,并通过node4通知客户订单已发货;如果库存不足,则执行node5通知客户订单缺货。
六、Dify工作流的注意事项
(一)性能优化
-
合理设计工作流 在设计工作流时,应尽量避免过多的节点和复杂的逻辑,以减少工作流的执行时间和资源消耗。例如,可以通过合并一些简单的任务节点,或者将一些重复的操作提取为子工作流来简化工作流的结构。
-
优化节点性能 对于一些性能敏感的节点,如数据处理节点或API调用节点,应优化其内部逻辑。例如,可以通过缓存数据、批量处理数据或优化算法等方式提高节点的执行效率。同时,应合理配置节点的并发数,避免过多的并发请求导致系统性能下降。
(二)数据安全与隐私
-
数据加密 在工作流中处理敏感数据时,应确保数据的安全性。例如,可以对数据进行加密存储和传输,防止数据泄露。Dify工作流支持多种加密算法,用户可以根据需要选择合适的加密方式。
-
访问控制 应严格控制对工作流的访问权限,只有授权的用户才能创建、修改和执行工作流。可以通过用户认证和授权机制(如OAuth2.0)来管理用户权限。同时,应定期审计工作流的访问记录,发现异常访问行为及时处理。
(三)错误处理与监控
-
错误处理机制 在工作流中,应设计完善的错误处理机制。例如,当某个节点执行失败时,可以根据错误类型采取不同的处理策略,如重试、跳过或终止工作流。同时,应记录错误信息,方便后续的排查和修复。
-
监控与报警 应对工作流的执行情况进行实时监控,及时发现和处理异常情况。例如,可以通过监控工作流的执行时间、节点状态等指标,当发现异常时(如工作流执行超时、节点失败等)及时发出报警通知。Dify工作流提供了丰富的监控接口和报警机制,用户可以根据需要配置监控策略和报警方式。
七、总结
Dify工作流作为一种强大的自动化工具,为企业和个人提供了灵活、高效的流程管理解决方案。通过本文的介绍,我们了解了Dify工作流的概念、架构、应用场景、代码示例以及使用时需要注意的事项。在实际应用中,用户可以根据自己的业务需求,充分发挥Dify工作流的优势,实现业务流程的自动化和优化,提高工作效率和竞争力。



















 1181
1181



 到【灌水乐园】发言
到【灌水乐园】发言










