







 超级会员免费看
超级会员免费看
 目录
目录
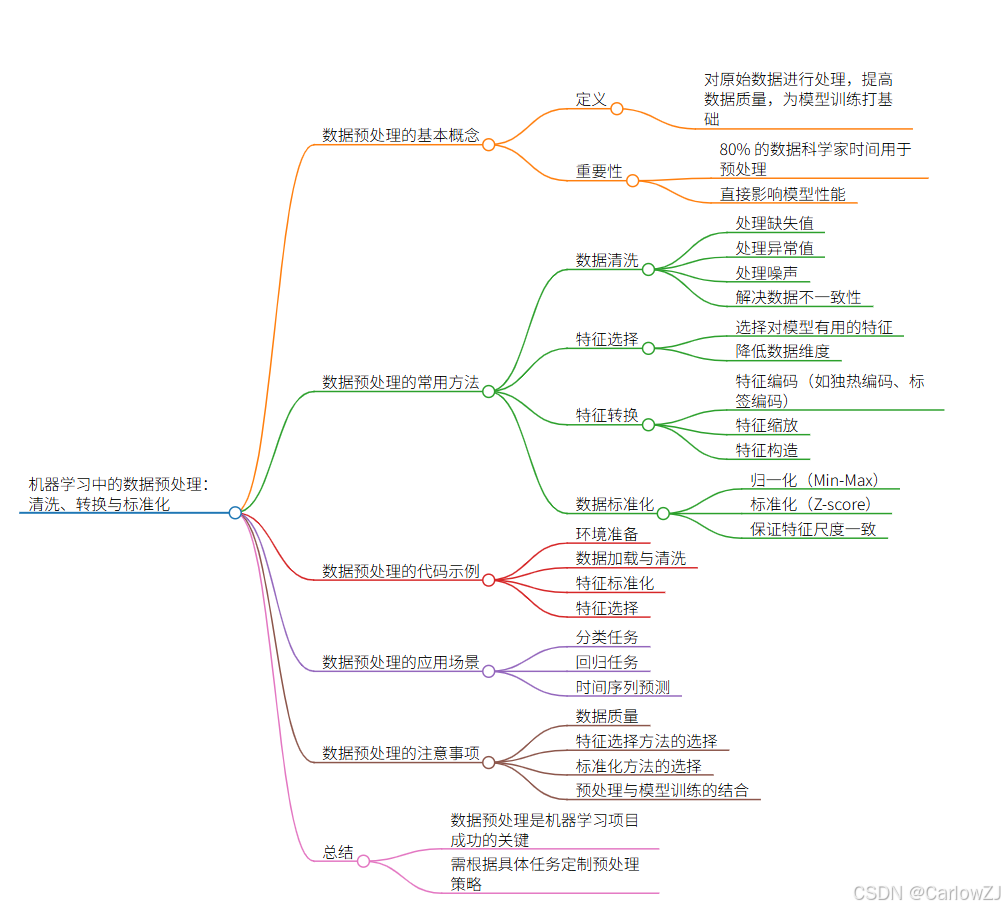
摘要 :在机器学习领域,数据预处理是决定模型性能的关键环节。本文深入浅出地剖析数据预处理的全流程,涵盖数据清洗、特征选择、特征转换与标准化等核心方法,并辅以详实的代码示例,助力读者快速上手实战。同时,结合多元应用场景,如分类、回归及时间序列预测,探讨数据预处理策略的定制要点。借助精心绘制的图表、架构图和流程图,全方位呈现数据预处理的脉络与细节,为机器学习项目实战提供详尽指南。
一、前言
随着人工智能与大数据技术的蓬勃发展,机器学习在众多领域大放异彩。从医疗影像诊断、金融风险预测到智能语音助手,机器学习模型为解决复杂问题提供了强大工具。然而, models are only as good as the data they’re trained on. 原始数据往往存在缺失值、噪声、不一致性等诸多问题,这些问题会严重拖累模型性能。一份研究表明,数据科学家约有 80% 的时间耗费在数据预处理阶段,凸显出该环节的重要性。有效的数据预处理能大幅提升数据质量,挖掘数据潜在价值,为模型训练筑牢根

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











