




《从零构建大语言模型》学习笔记3,文本数据处理2
前言
本书原项目地址:https://github.com/rasbt/LLMs-from-scratch
在使用tiktoken库将本地语料转换为标记ID后,下一步就是基于这些标记ID序列构建训练数据集。在机器学习领域,典型的数据集包含两个核心组成部分:输入数据和对应的目标输出数据。
模型本质上是在学习输入与输出之间的映射关系,这种关系可以看作是一个高维参数空间中的复杂函数。通过训练不断调整参数,当模型能够很好地拟合训练数据后,就可以应用于只有输入数据的场景中进行预测。
对于LLMs(大语言模型)而言,其输入和输出都来自同一语料,只是按照位置顺序进行了错位处理:将序列的前半部分作为输入,后半部分作为输出。整个数据处理流程如下图所示:


将一段文本拆分为n个词元后,按顺序构造n组训练数据:每组以前n个词元作为输入,第n+1个词元作为输出目标。下面我们通过代码实现这个流程。
1、使用滑动窗口进行数据采样
我们这里使用pytorch框架来构建数据集,关于pytorch的使用,如果接触过CNN网络的应该都使用过吧,没有基础的可以自行搜一些pytorch的使用教程,当然这本书的附录部分也有部分学习pytorch的建议,我这里就不详细说了。
import torch
print("PyTorch version:", torch.__version__)
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
#让GPT初始化一个类型
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})#id是文本内容编码过来的
# Use a sliding window to chunk the book into overlapping sequences of max_length
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("gpt2")
# Create dataset
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# Create dataloader
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
dataloader = create_dataloader_v1(#raw_text 中创建一个数据加载器 但是所批次
raw_text, batch_size=1, max_length=4, stride=1, shuffle=False
)
data_iter = iter(dataloader)#数据加载器 dataloader 转换为一个迭代器
first_batch = next(data_iter)
print(first_batch)
通过创建继承自torch.utils.data.Dataset的GPTDatasetV1类,我们可以构建自定义数据集。在该类的__init__方法中初始化输入输出数据,重写__getitem__方法实现按索引获取数据,并重写__len__方法返回数据总长度。这样就能配合DataLoader按批次加载数据。
由于计算机内存和算力限制,数据需要分批处理。通过调用PyTorch的DataLoader,可以自动完成整个分批加载过程。
2、创建词嵌入
上一步创建的数据集内容还是原始的自然数编码,为方便后续的运算,我们还需要把自然数编码再编码为词向量,每一个自然数编码ID都可以转为n个长度的向量来表示,这个过程也叫词嵌入。原理图如下:

这里面把每一个词元ID转为了3个长度的向量,
比如这里:
vocab_size = 6#嵌入层需要支持的唯一标记的总数
output_dim = 3#嵌入向量的维度
torch.manual_seed(123)#用于设置随机数生成器的种子,确保结果的可复现性
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)#每行表示一个标记的嵌入向量。
作者使用pytorch的Embedding函数,构造了一个6组,每组长度为3的Embedding层,
print(embedding_layer.weight)
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)print(embedding_layer(torch.tensor([3])))
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=)
需要注意的是现在的计算都是要转换为tensor类型了,不了解的可以先看下pytorch的使用。
接下来就是把之前的数据集转成embedding后的数据集了。
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)#映射为tensor
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
token_embeddings = token_embedding_layer(inputs)#调用token_embedding_layer将输入inputs映射为对应的嵌入向量。
print(token_embeddings.shape)
这里设置的embedding属性是每个词元id转换为256个长度的向量,gpt2一共有50257个不重复的词元id。
在embedding之前,我们的数据集是每个批次8组数据,每组数据是4个词元,经过embedding后,我们数据集每个批次的矩阵形状应该是(8,4,256)
torch.Size([8, 4, 256])
3、编码词位置
我们已将所有词元转换为嵌入向量,但这还不足以充分表达语义。由于文本本质上是时序数据,词元在不同位置可能出现完全不同的含义。例如,"我爱你"和"你爱我"这两个句子虽然包含相同的词元,仅顺序不同,但表达的意思却截然不同。为了让模型更好地捕捉这种差异,我们需要为每个词元添加位置编码信息,然后将位置编码与原始词嵌入向量相加即可。
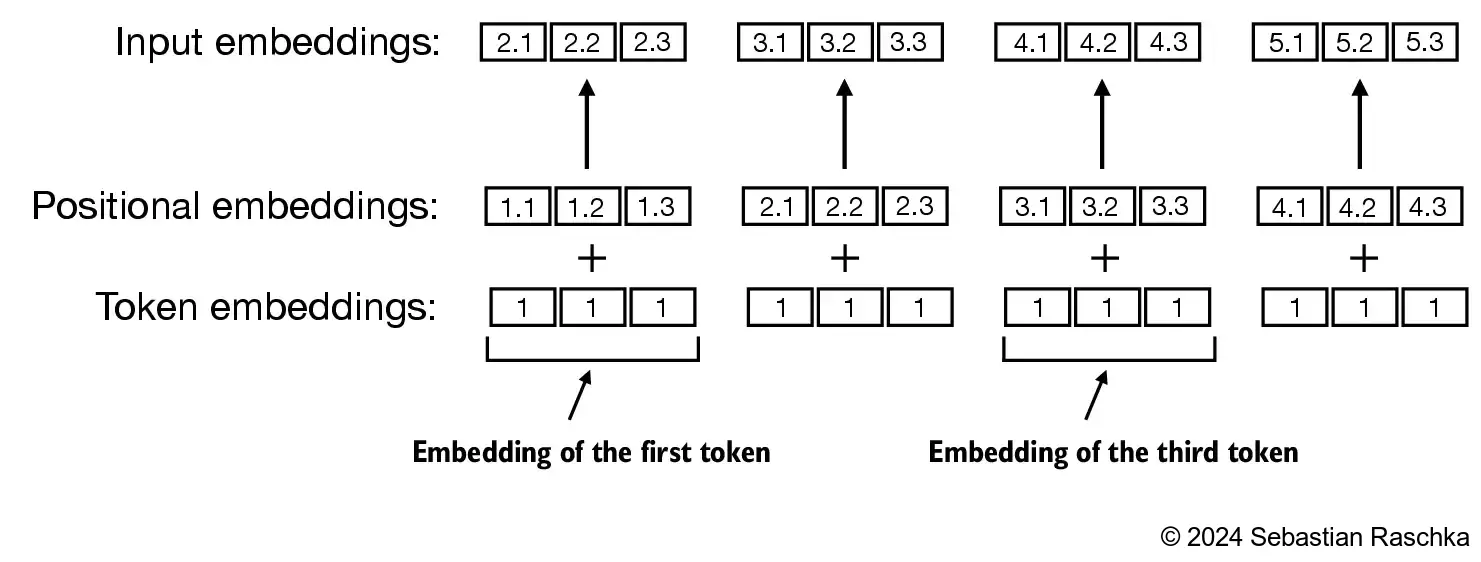
位置编码同样通过embeddings函数实现:
pos_embedding_layer = torch.nn.Embedding(4, 256)
由于数据集宽度为4,我们仅需4个位置编码。为确保与先前向量能正确进行矩阵相加操作,每个位置编码的维度需保持一致,均为256。这就是这两个参数的设置依据。
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)#映射为tensor
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
token_embeddings = token_embedding_layer(inputs)#调用token_embedding_layer将输入inputs映射为对应的嵌入向量。
print(token_embeddings.shape)
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(max_length))#生成一个连续整数的1D tensor
print(pos_embeddings.shape)
input_embeddings = token_embeddings + pos_embeddings#特征是词语信息跟位置信息的结合
print(input_embeddings.shape)
以上代码就是对输入数据进行embeddings的整个过程,同理对输出目标数据也要进行这个embeddings过程。
总结

本次文本数据处理的学习内容就到这里。原作者讲解得非常细致,从简单到复杂层层递进,循序渐进地引导我们理解。简而言之,文本数据处理的核心是将训练语料按照固定词元长度进行分割,然后转化为向量形式,以便计算机进行后续运算处理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









