






 本文介绍了一种端到端视频编解码框架,通过改进PWCnet的运动估计、特征注意力编码和Refine-Net优化,使用YUV输入格式,并详细阐述了训练策略和实验结果。与DVC有显著区别,展示了在CLIC2020竞赛中的竞争力。
本文介绍了一种端到端视频编解码框架,通过改进PWCnet的运动估计、特征注意力编码和Refine-Net优化,使用YUV输入格式,并详细阐述了训练策略和实验结果。与DVC有显著区别,展示了在CLIC2020竞赛中的竞争力。
文章地址:https://arxiv.org/abs/2012.07462
写在前面:本文提出了一个新的基于深度学习的端到端视频编解码框架,与DVC的框架有点相似,但也有几点区别。另外,网络和实验一些关键细节写的很详实。
目录
一、概述
1、本文提出了一种基于学习的P帧编解码框架,对比实验是在CLIC2020 P帧压缩竞赛数据集上进行。
2、和DVC一些不同点:
(1)基于PWC net改进了运动估计;
(2)残差编码基于Balle的框架进行了改进,引入了特征注意力机制;
(3)提出Refine-Net提升编解码效果;
(4)输入图是YUV格式。Y通道首先被处理产生残差和光流,后续处理使用YUV三个通道。一般基于深度学习的图片或视频编解码的输入格式都是RGB。
二、论文方法
1、整体框架

2、运动估计

图片帧下采样喂给PWC Net,可以加快光流计算速度。还有一个创新就是利用局部注意力机制进行增强。论文里提到在训练阶段的损失是![]() ,那这个运动估计的后处理模块似乎又起到了运动补偿的作用。
,那这个运动估计的后处理模块似乎又起到了运动补偿的作用。
3、残差编码
残差编解码网络,还是基于Balle的框架。

最大的创新是特征图注意力模块。中间较少的通道(64),比原来128通道的效果还好,通道减少,也可以减小中间文件的压缩体积。

4、优化网络
本文的优化网络不是一个简单的噪声去除后处理模块。重构图片和光流优化都可以用这一个网络。

5、量化和熵编码
量化需要基于Fig 11中网络中间输出的均值和方差,根据公式:
 ,将特征量化归一到[-1, 1]。
,将特征量化归一到[-1, 1]。
熵编码采用CVPR2020一篇文献提出的混合高斯模型,这个模型的计算复杂度很高。
6、训练策略
涉及到多个网络的端到端视频编解码的训练策略也是非常重要的一个环节。
(1)将运动估计和压缩器分开训练;
(2)运动压缩的损失:
 ,采用多帧平均,其他文献里有提到,多帧平均可以减缓错误传播的速度。
,采用多帧平均,其他文献里有提到,多帧平均可以减缓错误传播的速度。
(3)训练压缩器时采用分步训练策略,损失函数还是率失真函数![]() 。
。
第一步,不训练优化网络(Refine-Net),只训练压缩网络;
第二步,失真损失采用用MSE损失训练优化网络;
第三步,联合训练。失真函数MSSSIM损失。
三、实验
1、训练步骤
图片被裁剪成256x256大小,训练阶段为了防止过拟合,不用UVG数据集。
2、实验结果
(1)CLIC是把MS-SSIM作为评价指标,计算MS-SSIM的公式如下:

size是图片大小。
(2)最后的实验结果:

与最好的几个队伍相比,也具有一定竞争力。
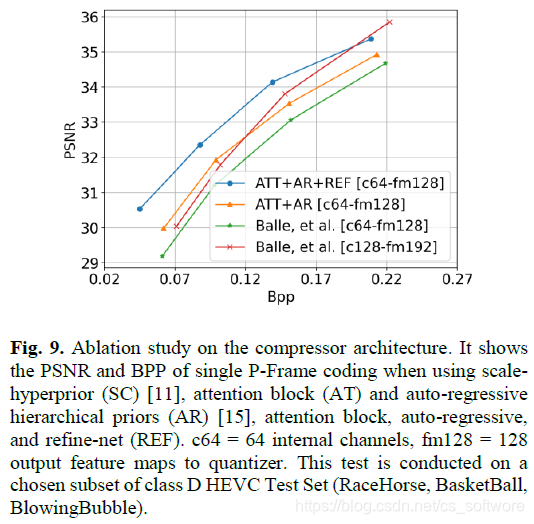
(3)消融实验。
从优化网络、输入格式、模型大小、压缩器表现四个方面进行了消融实验。


四、总结
针对端到端的视频编解码方案,本文的方法中还是有很多值得借鉴的地方,比如输入是YUV通道、增加注意力机制、后续的优化网络等。最后的实验作者并没有像其它方法那样和经典的端到端方案以及和H265、H266算法进行比较,总觉得差那么点感觉。

















 1707
1707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









