




文献地址:https://arxiv.org/abs/2004.10290
代码地址:https://github.com/JianpingLin/M-LVC_CVPR2020
文章入选CVPR2020,网络上已经有对本文进行了简单解读(https://blog.youkuaiyun.com/moxibingdao/article/details/105804082,https://zhuanlan.zhihu.com/p/136343529),本文是对DVC的改进,因为在实际工作中,我们对DVC也进行了深入了解并复现,所以非常有必要对本文进行学习,对文献的理解做一下记录。
目录
一、概述
因为DVC的编解码框架类似于混合编解码框架,所以减少MV和残差的码率是优化的关键,DVC框架的P帧编码是借助前一个解码帧进行运动估计、运动补偿、残差编解码等相关操作,而本文是借助借助前面多帧进行这些操作,理论上是可以提升DVC的编解码性能,可以减缓错误传播的速度。
二、本文贡献
1、对基于学习的端到端视频编解码框架增加四个模块:基于多帧的运动估计、基于多帧的运动步长、运动优化、残差优化;
2、只采用优化一个率失真损失函数和step-by-step的训练策略。
3、性能超过现有基于学习的视频编解码和H265算法(低延时)。
三、论文思想
1、本文提出的方法见下图,蓝色框为本文创新:增加的四个模块。
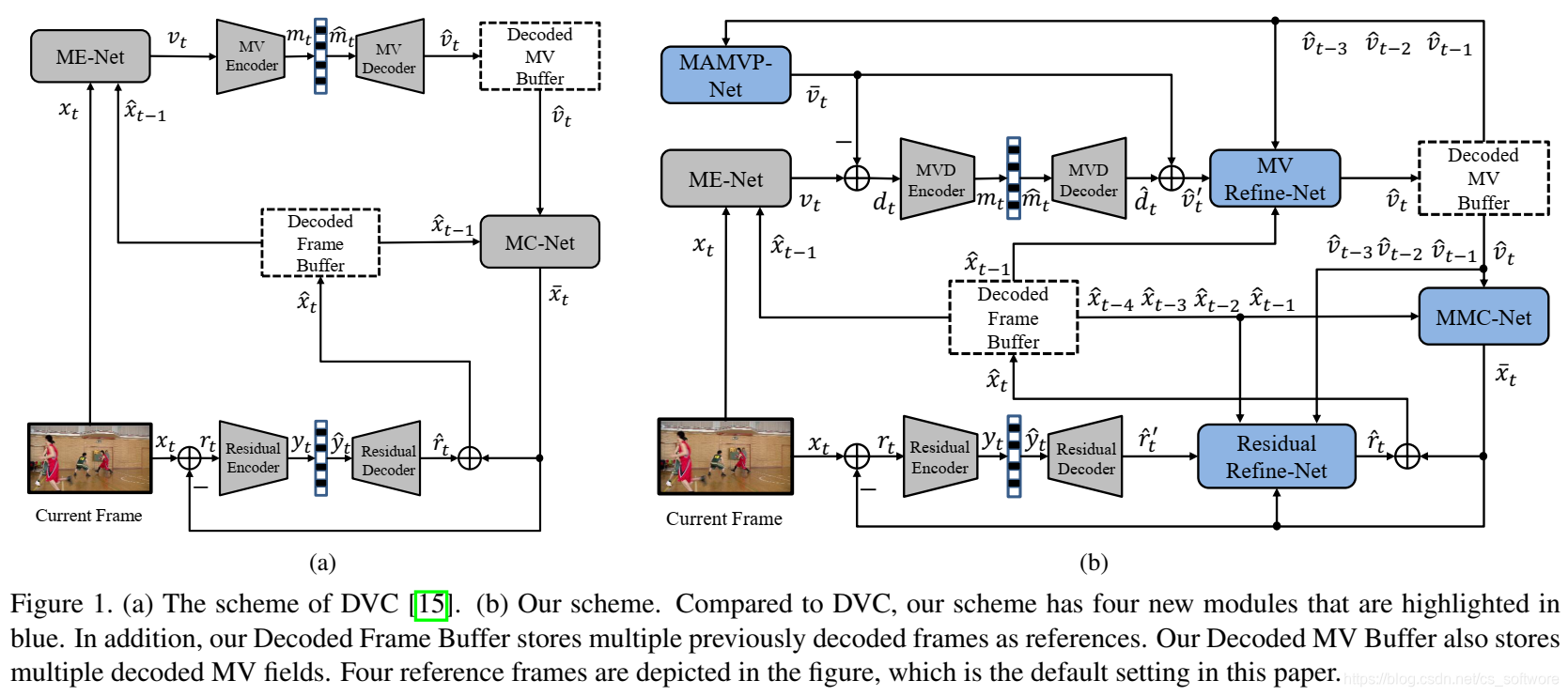
编解码流程与DVC一致,本文对光流编解码除了多参考帧和MV优化,还有另外一个改进:并不是直接编解码光流,而是对预测光流与原始光流的残差进行编解码。
2、
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+





 到【灌水乐园】发言
到【灌水乐园】发言







