



1、算法优化
(1)momentum算法

(2)RMSprop算法
root mean square

(3)Adam算法

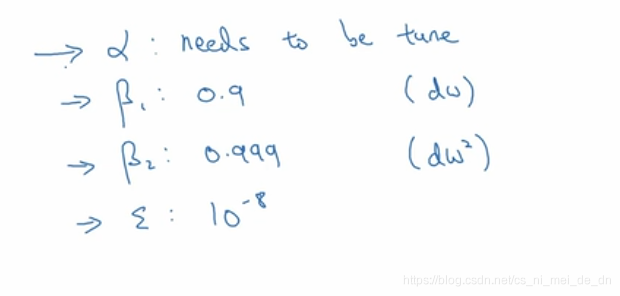

2、根据偏差和方差大小分别如何完善网络
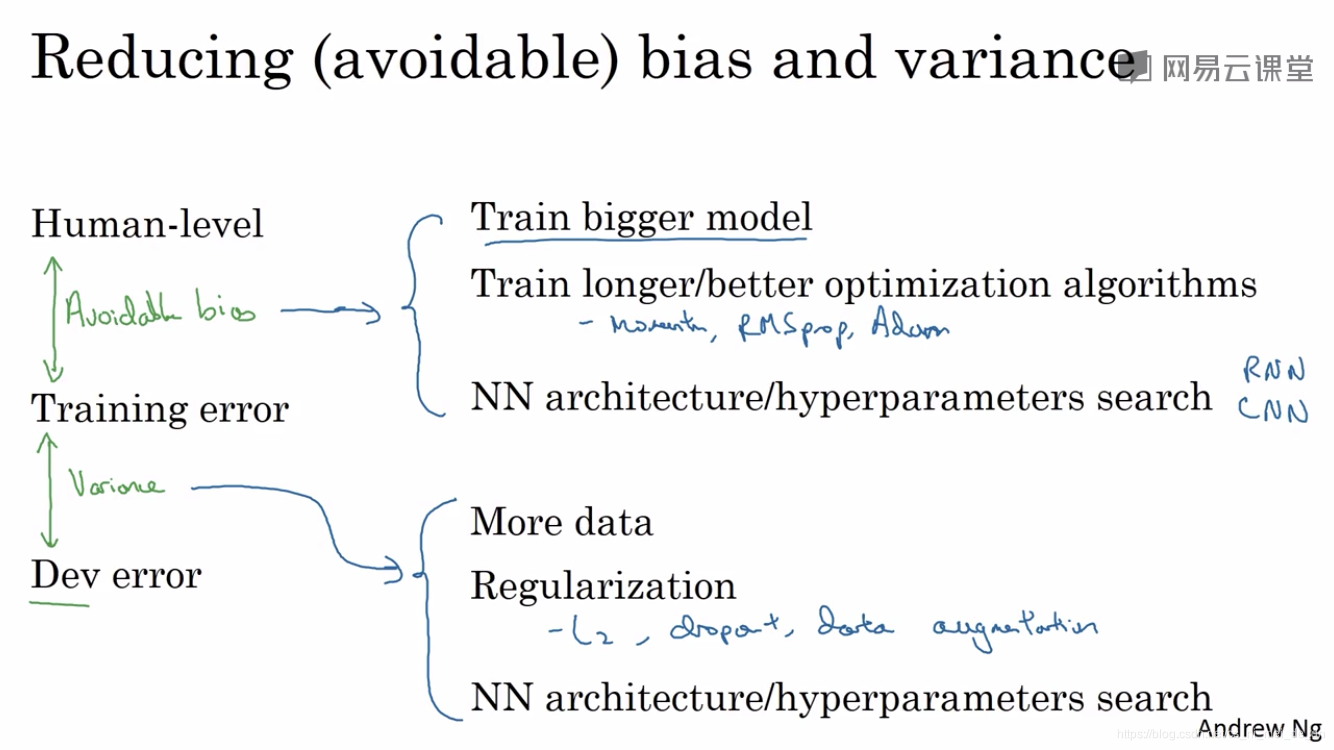 (1)、human leve和training error之间相差比较大,也就是可避免偏差比较大的时候,也就是偏差大的时候通过扩大网络结构,更长时间的训练,更好的优化算法,或者更换更适合的网络
(1)、human leve和training error之间相差比较大,也就是可避免偏差比较大的时候,也就是偏差大的时候通过扩大网络结构,更长时间的训练,更好的优化算法,或者更换更适合的网络
(2)、training error和Dev error相差比较大,也就是方差比较大的时候,更好地理解是过拟合了,这时候优化方法是:可以扩大训练集的数量,正则化(包括L2、dropout、强化数据等方法),或者更换网络(试试RNN、CNN)
3、不匹配数据集的划分
例如你有2w数据是app应用的真实数据,训练集有50w的已有其他途径数据
可以这样划分:
training 49w
train-dev 1w
dev 1w
test 1w

- 用training和human level的error率差值作为可避免偏差(avoidable bias)
- trainging集和training-dev的error率差值衡量偏差(variance)
- dev集和training-dev集的error率差值衡量数据不匹配程度(data mismatch)
- test集和dev集的error率差值衡量dev集的过拟合率(degree of overfitting)
4、迁移学习和多任务学习
TaskA ->TaskB

前提是 :
- TaskA和TaskB的输入要相同
- TaskA的训练集量级要比TaskB大很多,两个任务的
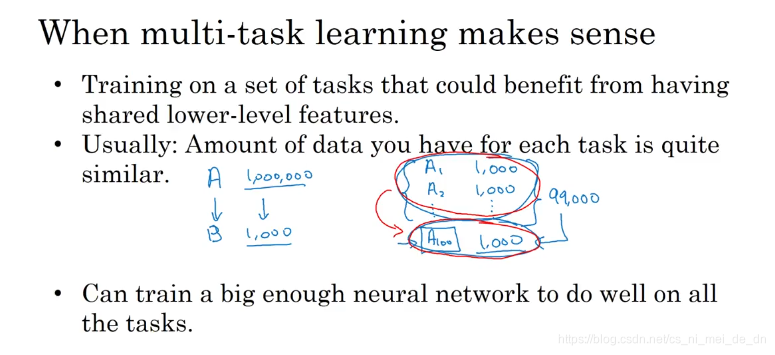
多任务学习:
- 多个任务有相似的低层特征
- 任务的数量级差不多
- 要构建一个足够大的网络才能使多任务表现良好


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









