







目录
基于HDFS的分布式NoSQL(非关系型)数据库。面向海量数据的存储。在太小的数据量反而不如普通关系型数据库。
特点:
海量存储、列式存储、极易扩展、高并发、稀疏数据、准实时查询(弥补MapReduce的离线延时)
 https://blog.youkuaiyun.com/qq_33208851/article/details/105223419
https://blog.youkuaiyun.com/qq_33208851/article/details/1052234191、HBase表结构
HBase表由行和列组成,每个行由行键(row key)来标识,列划分为若干列族,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一个文件中。当这个文件达到一定大小后,会进行分裂形成多个region。当一个行键在不同的列族中都有相应的列值的话,不同列族中的文件都会存储这个行键的值。也就是说,一行可能包含多个列族,一个列族有多个列,对某一行而言,某列族文件中只存储了这一行键在列族中有值的那些列(列族可能有上百个列),没有不会存储(不存null)。
类似将表下是行列放大,Column family→列,Region→行,在其下才是行列。
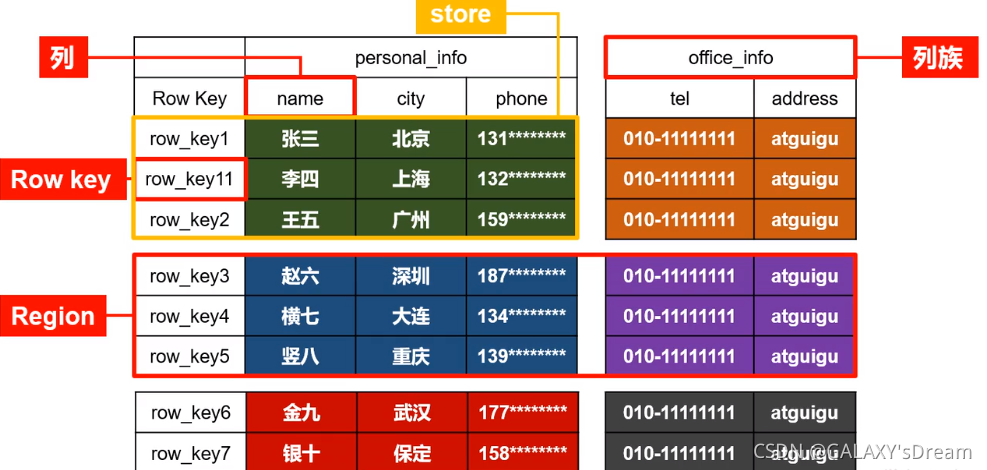
1) RowaKey:每行由行键(row key)来标识,按照字典顺序存储,查询时根据RowKey检索,所以RowKey的设计十分重要。
2) Column Frimly列族:纵向的切片,一个列族可以包含多个列,同一个列族里面的数据存储在一个Store中,当这个文件达到一定大小后(一般是10G),会切割形成多个region
·列族不建议设置有多个,原因主要是列族数据倾斜下容易产生小文件
1、split的时候,A/B列族相差较大,若StoreB本来就很小,切割容易生成了小文件
2、flush的时候,任何一个storeflush其他stroe也会跟着flush,刷多了就产生大量的小文件
3、一个列族对应一个store,也就意味着对应一个memStore,会大量消耗内存
3) Regio:横向的切片,存储着一至多行数据,最原始状态只有一个HRegion,随着数据量不断增大,HRegion也会增多,数量多到一定程度时,会放到其他的RegionServer中
4)Cell单元格:由{rowkey, column Family:column, version} 确定唯一单元,cell 中的数据是没有类型的,全部是字节码形式存贮。
4.1 ·Time Stamp
每个 cell 都保存着同一份数据的多个版本。版本通过时间戳来索引。timestamp是一个很重要的概念。它记录着往HBase进行增删改操作的时间,查是返回时间戳最新的数据。这是HBase实现快速随机读写的机理(用新版本覆盖)。之前的操作(时间戳小的)会保留直到达到一定的版本数或者设定时间。
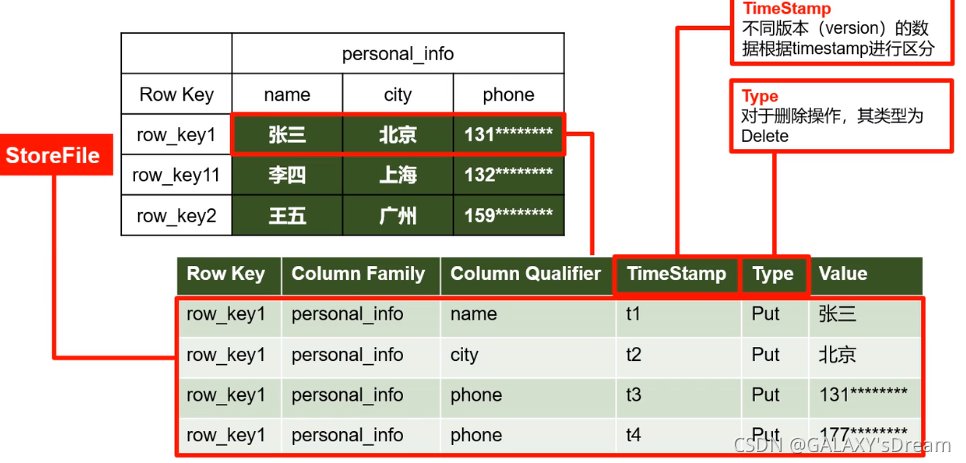
2、HBase架构
四大件MASTER + ZK ,客户端 + RS <HLOG REGION < STORE < MEM STORE/StoreFile
- Master: 管理DDL(表级别)操作,分配Region到每个RegionServer,监控每个RS的状态
- ZOOKEEPER:HA,分担客户端交互与DML功能,所以在Master宕机之后还能进行DML操作。
- Client:提交请求,所有请求先与ZK交互。元数据,和DDL才与Master交互。
- RegionServer:DML操作(GET、PUT、Delete)负责维护HRegion(切割Region,合并region)
Hlog:WAL日志,写入数据之前,要先写入日志,目的是为了容错,一旦出现问题可以通过Hlog进行恢复。
HRegion:
Store:列族
mem Store:内存缓冲区,先把数据写入到这里,达到一定阈值后启动flashCache将数据写入StoreFile,每次写入生成一个StoreFile(落盘)
Store File:会进行合并与拆分,1、数量达到一定阈值后进行合并,并删除一些旧版本的数据。2、当容量达到一定阈值后会拆分形成多个HRegion。
HFile:与StoreFile是同一种东西,是StoreFile的存储形式
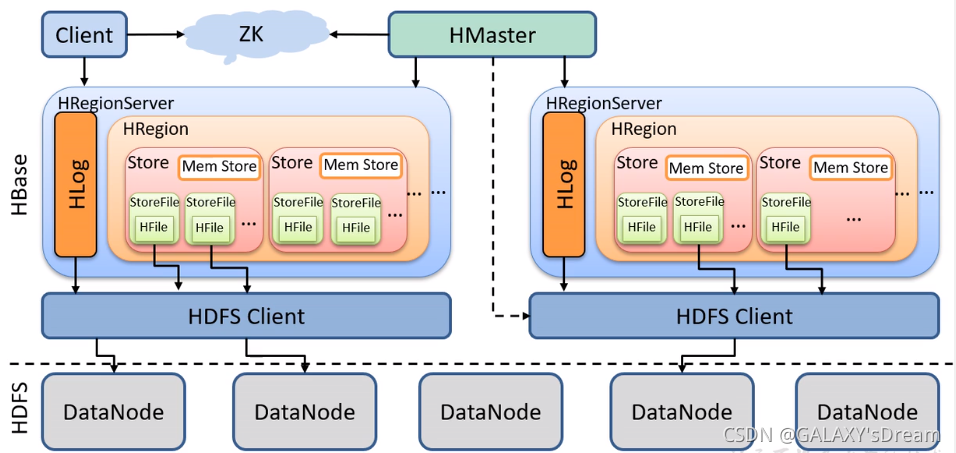
3、HBase读写流程
3.1写入流程
- Client向ZK请求meta表的RegionServer,ZK返回Meta RS
- Clinet请求meta表的数据,RS返回meta数据
- 发送操作请求
- 先写WAL
- Mem Store <flash> StoreFile
- 反馈Client,写入成功

写入源码:
先写WAL,但是此时不同步到HDFS,待数据写入完成WAL才同步
分为Step1 to Step 8
1 请求JUC锁,保证读写分离
2 更新最后时间戳
3 构建WAL日志在内存中
4 写WAL,但是不同步到HDFS
5 写mem store
6 释放锁
7 同步WAL
8 如果WAL同步失败,回滚
3.2读取流程

- Client向ZK请求meta表的RegionServer,ZK返回Meta RS
- Clinet请求meta表的数据,RS返回meta数据
- 先从 MemStore 找数据,如果没有,再到 BlockCache 里面读
- BlockCache 还没有,再到 StoreFile 上读
- 如果是从 StoreFile 里面读取的数据,不是直接返回给客户端,而是先写入 BlockCache,再返回给客户端
4、Flush流程
Flush从空间和时间上做了触发条件,而且在RS级别和R级别都分别做了条件。刷写后不同列族分开存储在不同的文件夹里,类似分区一样能够根据列族快速查找。
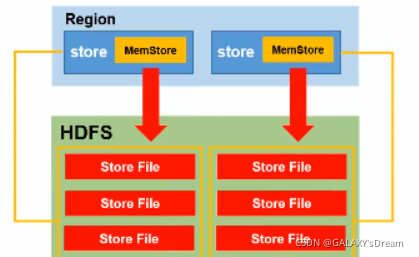
RS级别
a.当一个RegionServer 中的所有MemStore的大小总和超过了堆内存
的40%.则这个RegionServer 中所有的MemStore一起刷到 HFile中
b.最后一次操作时间在MemStore存活时间超过了1h,则这个
RegionServer 中所有的MemStore 一起刷到HFile中.
R级别
c. MemStore达到阈值(老版本64M,新版本128M)后,把数据flush到磁
盘,生成storeFile文件
Flush
Flush完成,删除mem Store与Hlog中的历史数据。
·如果同一条信息插入多次后(在内存中并未刷写)刷写后只刷入最新数据。而刷写不会影响已经落盘的文件。即便是最后一条数据是删除标记也会被刷写进入磁盘(防止诈尸)
5、Compact与Split流程
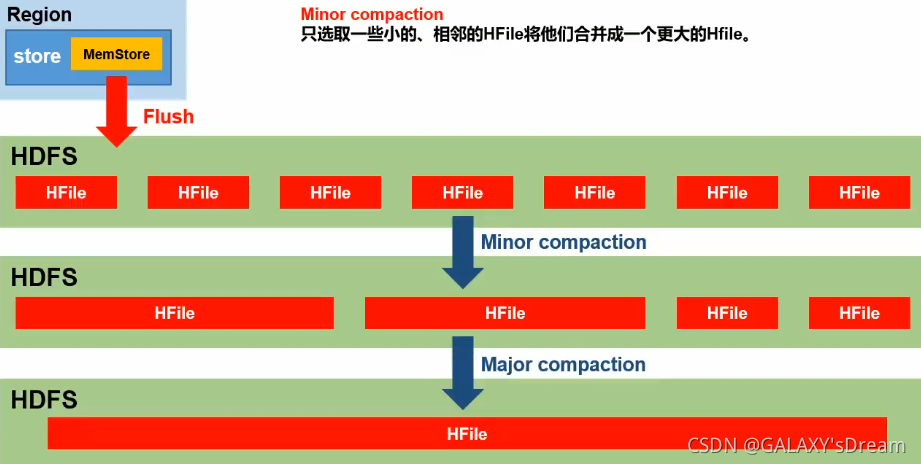
5.1 Compact合并
Compact,storeFile的合并过程,目的是防止小文件过多,提高查询效率起合并文件、清除过期多余版本数据、提高读取效率的作用。
5.1.1Minor Compactior小合并
5.1.2Major Compactior大合并
·将所有的StoreFile合并为一个HFile,是一个rewirte过程,这个过程还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空闲时间手动触发。一般可以是手动控制进行合并,防止出现在业务高峰期。
5.2 Split
Hregion中StoreFile到一定大小会分成多个Hregion
切分触发大小Min.(R个数^2 * 刷写的阈值,10G)
Split若在最后一个rowkey追加,往往会产生热点问题,解决方案:建表时进行预分区并设计合理的Rowkey将数据均匀分布在各region中
6、HBase On Hive
HBase与Hive的区别:
Hive属于一个分析的数据仓库框架,HBase属于存储框架。一个本质是数据仓库,一个本质是数据库。而数据仓库是面向分析的,HBase是面向存储的。
6.1连接Hive:
6.1.1建立依赖,将HBASE下的lib下的jar包拷贝到Hive
6.1.2修改配置文件Hive-Site.xml,添加zookeeper的配置信息
6.2如何使用:
Hive需要创建一个外部表添加关联HBase的参数,并且此时不能直接load加载数据至该表,必须创建中间表以insert方式插入信息。关联表完成后就在hive对该表进行SQL等分析操作。
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,act:,basic:,docs:,pref:,rc:")
> TBLPROPERTIES ("hbase.table.name" = "users:china_mainland")stored by 为依赖
关键步骤是在建表的时候,在WITH SERDEPROPERTIES指定关联到hbase表的哪个列簇或列
7、预分区
在建表的时候设置StartRow与EndRow,如果加入的数据键值符合某个region的范围,则交给对应的Region进行维护。按照这个原则,可以将数据所要投放的分区提前规划好,以提升性能。
8、RowKey的设计原则
1、散列性:为了负载均衡,使数据均匀分布在集群上
方法:生成随机数(加盐)、hash法、反转
2、唯一性:RorKey不能有重复
3、长度原则:根据实际应用设计长度,一般设置为定长


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









