-- ******************************************************************** --
-- Author: 蔡义
-- CreateTime: 2025-09-11
-- Comment: 扩展用户常听歌曲序列的side_info信息表 - 性能优化版
-- 优化策略: 热点用户识别+分层处理+动态盐值
-- ******************************************************************** --
-- 设置优化参数
SET hive.map.aggr=true;
SET hive.map.aggr.hash.percentmemory=0.5;
SET hive.groupby.skewindata=true;
SET hive.optimize.skewjoin=true;
SET hive.skewjoin.key=100000;
SET hive.exec.reducers.bytes.per.reducer=256000000;
SET hive.exec.reducers.max=999;
SET hive.auto.convert.join=true;
SET hive.mapjoin.smalltable.filesize=100000000;
SET mapreduce.map.memory.mb=4096;
SET mapreduce.reduce.memory.mb=8192;
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=8;
-- 建表语句(保持不变)
CREATE TABLE IF NOT EXISTS music_most.user_song_sequence_with_side_info (
user_id STRING COMMENT '用户ID',
user_often_listen_song_id_list_7d ARRAY COMMENT '用户7天常听的歌曲ID列表',
user_often_listen_song_name_list_7d ARRAY COMMENT '用户7天常听的歌曲名称列表',
user_often_listen_artist_id_list_7d ARRAY COMMENT '用户7天常听歌曲的艺人ID列表',
user_often_listen_artist_name_list_7d ARRAY COMMENT '用户7天常听歌曲的艺人名称列表',
user_often_listen_genre_list_7d ARRAY COMMENT '用户7天常听歌曲的曲风列表',
user_often_listen_language_list_7d ARRAY COMMENT '用户7天常听歌曲的语种列表',
user_often_listen_play_cnt_list_7d ARRAY COMMENT '用户7天常听歌曲的播放次数列表',
user_often_listen_duration_list_7d ARRAY COMMENT '用户7天常听歌曲的时长列表(毫秒)',
user_often_listen_song_id_list_30d ARRAY COMMENT '用户30天常听的歌曲ID列表',
user_often_listen_song_name_list_30d ARRAY COMMENT '用户30天常听的歌曲名称列表',
user_often_listen_artist_id_list_30d ARRAY COMMENT '用户30天常听歌曲的艺人ID列表',
user_often_listen_artist_name_list_30d ARRAY COMMENT '用户30天常听歌曲的艺人名称列表',
user_often_listen_genre_list_30d ARRAY COMMENT '用户30天常听歌曲的曲风列表',
user_often_listen_language_list_30d ARRAY COMMENT '用户30天常听歌曲的语种列表',
user_often_listen_play_cnt_list_30d ARRAY COMMENT '用户30天常听歌曲的播放次数列表',
user_often_listen_duration_list_30d ARRAY COMMENT '用户30天常听歌曲的时长列表(毫秒)',
user_often_listen_song_id_list_90d ARRAY COMMENT '用户90天常听的歌曲ID列表',
user_often_listen_song_name_list_90d ARRAY COMMENT '用户90天常听的歌曲名称列表',
user_often_listen_artist_id_list_90d ARRAY COMMENT '用户90天常听歌曲的艺人ID列表',
user_often_listen_artist_name_list_90d ARRAY COMMENT '用户90天常听歌曲的艺人名称列表',
user_often_listen_genre_list_90d ARRAY COMMENT '用户90天常听歌曲的曲风列表',
user_often_listen_language_list_90d ARRAY COMMENT '用户90天常听歌曲的语种列表',
user_often_listen_play_cnt_list_90d ARRAY COMMENT '用户90天常听歌曲的播放次数列表',
user_often_listen_duration_list_90d ARRAY COMMENT '用户90天常听歌曲的时长列表(毫秒)',
total_play_count_7d BIGINT COMMENT '7天总播放次数',
total_play_count_30d BIGINT COMMENT '30天总播放次数',
total_play_count_90d BIGINT COMMENT '90天总播放次数',
distinct_song_count_7d BIGINT COMMENT '7天独立歌曲数',
distinct_song_count_30d BIGINT COMMENT '30天独立歌曲数',
distinct_song_count_90d BIGINT COMMENT '90天独立歌曲数',
update_time STRING COMMENT '数据更新时间'
)
COMMENT '用户常听歌曲序列扩展side_info表(7天/30天/90天窗口)'
PARTITIONED BY (dt STRING COMMENT '时间分区yyyy-mm-dd')
STORED AS PARQUET
TBLPROPERTIES (
'PARTITION_LIFECYCLE'='30d',
'table.source'='自定义',
'table.creator'='caiyi05@corp.netease.com'
);
-- 优化版数据插入
INSERT OVERWRITE TABLE music_most.user_song_sequence_with_side_info PARTITION(dt='${bizdate_1}')
WITH
-- ========== 步骤1: 识别热点用户(基于最近一天数据快速识别) ========== --
hot_users AS (
SELECT /+ MAPJOIN /
user_id,
COUNT() as record_count
FROM music_most.user_song_daily_with_side_info
WHERE dt = '${bizdate_1}'
GROUP BY user_id
HAVING COUNT() > 2000 -- 热点用户阈值
),
-- ========== 步骤2: 处理7天窗口 ========== --
-- 2.1 普通用户7天数据(不加盐)
normal_user_7d AS (
SELECT
t1.user_id,
t1.song_id,
MAX(t1.song_name) as song_name,
MAX(t1.singer_artist_id_list) as singer_artist_id_list,
MAX(t1.singer_artist_name_list) as singer_artist_name_list,
MAX(t1.genre_tag_name) as genre_tag_name,
MAX(t1.norm_language) as norm_language,
MAX(t1.duration) as duration,
SUM(t1.effective_play_cnt_1d) as play_count
FROM music_most.user_song_daily_with_side_info t1
LEFT ANTI JOIN hot_users t2 ON t1.user_id = t2.user_id
WHERE t1.dt BETWEEN date_sub('${bizdate_1}', 6) AND '${bizdate_1}'
AND t1.effective_play_cnt_1d > 0
GROUP BY t1.user_id, t1.song_id
),
-- 2.2 热点用户7天数据(加盐处理)
hot_user_7d_salted AS (
SELECT
CASE
WHEN t2.record_count > 10000 THEN CONCAT(t1.user_id, '', CAST(RAND() * 50 AS INT))
WHEN t2.record_count > 5000 THEN CONCAT(t1.user_id, '', CAST(RAND() * 30 AS INT))
ELSE CONCAT(t1.user_id, '_', CAST(RAND() * 20 AS INT))
END as user_id_salt,
t1.user_id,
t1.song_id,
t1.song_name,
t1.singer_artist_id_list,
t1.singer_artist_name_list,
t1.genre_tag_name,
t1.norm_language,
t1.duration,
t1.effective_play_cnt_1d
FROM music_most.user_song_daily_with_side_info t1
INNER JOIN hot_users t2 ON t1.user_id = t2.user_id
WHERE t1.dt BETWEEN date_sub('${bizdate_1}', 6) AND '${bizdate_1}'
AND t1.effective_play_cnt_1d > 0
),
-- 2.3 热点用户第一阶段聚合
hot_user_7d_stage1 AS (
SELECT
user_id_salt,
user_id,
song_id,
MAX(song_name) as song_name,
MAX(singer_artist_id_list) as singer_artist_id_list,
MAX(singer_artist_name_list) as singer_artist_name_list,
MAX(genre_tag_name) as genre_tag_name,
MAX(norm_language) as norm_language,
MAX(duration) as duration,
SUM(effective_play_cnt_1d) as partial_play_count
FROM hot_user_7d_salted
GROUP BY user_id_salt, user_id, song_id
),
-- 2.4 热点用户第二阶段聚合(去盐)
hot_user_7d AS (
SELECT
user_id,
song_id,
MAX(song_name) as song_name,
MAX(singer_artist_id_list) as singer_artist_id_list,
MAX(singer_artist_name_list) as singer_artist_name_list,
MAX(genre_tag_name) as genre_tag_name,
MAX(norm_language) as norm_language,
MAX(duration) as duration,
SUM(partial_play_count) as play_count
FROM hot_user_7d_stage1
GROUP BY user_id, song_id
),
-- 2.5 合并7天数据
user_song_7d AS (
SELECT * FROM normal_user_7d
UNION ALL
SELECT * FROM hot_user_7d
),
-- 2.6 7天排序和聚合
user_song_7d_ranked AS (
SELECT
user_id,
song_id,
play_count,
song_name,
singer_artist_id_list,
singer_artist_name_list,
genre_tag_name,
norm_language,
duration,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY play_count DESC, song_id) as rank
FROM user_song_7d
),
user_song_7d_agg AS (
SELECT
user_id,
collect_list(CASE WHEN rank <= 100 THEN song_id END) as user_often_listen_song_id_list_7d,
collect_list(CASE WHEN rank <= 100 THEN song_name END) as user_often_listen_song_name_list_7d,
collect_list(CASE WHEN rank <= 100 THEN singer_artist_id_list END) as user_often_listen_artist_id_list_7d,
collect_list(CASE WHEN rank <= 100 THEN singer_artist_name_list END) as user_often_listen_artist_name_list_7d,
collect_list(CASE WHEN rank <= 100 THEN genre_tag_name END) as user_often_listen_genre_list_7d,
collect_list(CASE WHEN rank <= 100 THEN norm_language END) as user_often_listen_language_list_7d,
collect_list(CASE WHEN rank <= 100 THEN play_count END) as user_often_listen_play_cnt_list_7d,
collect_list(CASE WHEN rank <= 100 THEN duration END) as user_often_listen_duration_list_7d,
SUM(CASE WHEN rank <= 100 THEN play_count ELSE 0 END) as total_play_count_7d,
COUNT(DISTINCT CASE WHEN rank <= 100 THEN song_id END) as distinct_song_count_7d
FROM user_song_7d_ranked
WHERE rank <= 100
GROUP BY user_id
),
-- ========== 步骤3: 处理30天窗口(复用相同逻辑) ========== --
normal_user_30d AS (
SELECT
t1.user_id,
t1.song_id,
MAX(t1.song_name) as song_name,
MAX(t1.singer_artist_id_list) as singer_artist_id_list,
MAX(t1.singer_artist_name_list) as singer_artist_name_list,
MAX(t1.genre_tag_name) as genre_tag_name,
MAX(t1.norm_language) as norm_language,
MAX(t1.duration) as duration,
SUM(t1.effective_play_cnt_1d) as play_count
FROM music_most.user_song_daily_with_side_info t1
LEFT ANTI JOIN hot_users t2 ON t1.user_id = t2.user_id
WHERE t1.dt BETWEEN date_sub('${bizdate_1}', 29) AND '${bizdate_1}'
AND t1.effective_play_cnt_1d > 0
GROUP BY t1.user_id, t1.song_id
HAVING SUM(t1.effective_play_cnt_1d) > 2 -- 30天播放超过2次
),
hot_user_30d_salted AS (
SELECT
CASE
WHEN t2.record_count > 10000 THEN CONCAT(t1.user_id, '', CAST(RAND() * 50 AS INT))
WHEN t2.record_count > 5000 THEN CONCAT(t1.user_id, '', CAST(RAND() * 30 AS INT))
ELSE CONCAT(t1.user_id, '_', CAST(RAND() * 20 AS INT))
END as user_id_salt,
t1.user_id,
t1.song_id,
t1.song_name,
t1.singer_artist_id_list,
t1.singer_artist_name_list,
t1.genre_tag_name,
t1.norm_language,
t1.duration,
t1.effective_play_cnt_1d
FROM music_most.user_song_daily_with_side_info t1
INNER JOIN hot_users t2 ON t1.user_id = t2.user_id
WHERE t1.dt BETWEEN date_sub('${bizdate_1}', 29) AND '${bizdate_1}'
AND t1.effective_play_cnt_1d > 0
),
hot_user_30d_stage1 AS (
SELECT
user_id_salt,
user_id,
song_id,
MAX(song_name) as song_name,
MAX(singer_artist_id_list) as singer_artist_id_list,
MAX(singer_artist_name_list) as singer_artist_name_list,
MAX(genre_tag_name) as genre_tag_name,
MAX(norm_language) as norm_language,
MAX(duration) as duration,
SUM(effective_play_cnt_1d) as partial_play_count
FROM hot_user_30d_salted
GROUP BY user_id_salt, user_id, song_id
),
hot_user_30d AS (
SELECT
user_id,
song_id,
MAX(song_name) as song_name,
MAX(singer_artist_id_list) as singer_artist_id_list,
MAX(singer_artist_name_list) as singer_artist_name_list,
MAX(genre_tag_name) as genre_tag_name,
MAX(norm_language) as norm_language,
MAX(duration) as duration,
SUM(partial_play_count) as play_count
FROM hot_user_30d_stage1
GROUP BY user_id, song_id
HAVING SUM(partial_play_count) > 2
),
user_song_30d AS (
SELECT * FROM normal_user_30d
UNION ALL
SELECT * FROM hot_user_30d
),
user_song_30d_ranked AS (
SELECT
user_id,
song_id,
play_count,
song_name,
singer_artist_id_list,
singer_artist_name_list,
genre_tag_name,
norm_language,
duration,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY play_count DESC, song_id) as rank
FROM user_song_30d
),
user_song_30d_agg AS (
SELECT
user_id,
collect_list(CASE WHEN rank <= 100 THEN song_id END) as user_often_listen_song_id_list_30d,
collect_list(CASE WHEN rank <= 100 THEN song_name END) as user_often_listen_song_name_list_30d,
collect_list(CASE WHEN rank <= 100 THEN singer_artist_id_list END) as user_often_listen_artist_id_list_30d,
collect_list(CASE WHEN rank <= 100 THEN singer_artist_name_list END) as user_often_listen_artist_name_list_30d,
collect_list(CASE WHEN rank <= 100 THEN genre_tag_name END) as user_often_listen_genre_list_30d,
collect_list(CASE WHEN rank <= 100 THEN norm_language END) as user_often_listen_language_list_30d,
collect_list(CASE WHEN rank <= 100 THEN play_count END) as user_often_listen_play_cnt_list_30d,
collect_list(CASE WHEN rank <= 100 THEN duration END) as user_often_listen_duration_list_30d,
SUM(CASE WHEN rank <= 100 THEN play_count ELSE 0 END) as total_play_count_30d,
COUNT(DISTINCT CASE WHEN rank <= 100 THEN song_id END) as distinct_song_count_30d
FROM user_song_30d_ranked
WHERE rank <= 100
GROUP BY user_id
),
-- ========== 步骤4: 处理90天窗口(复用相同逻辑) ========== --
normal_user_90d AS (
SELECT
t1.user_id,
t1.song_id,
MAX(t1.song_name) as song_name,
MAX(t1.singer_artist_id_list) as singer_artist_id_list,
MAX(t1.singer_artist_name_list) as singer_artist_name_list,
MAX(t1.genre_tag_name) as genre_tag_name,
MAX(t1.norm_language) as norm_language,
MAX(t1.duration) as duration,
SUM(t1.effective_play_cnt_1d) as play_count
FROM music_most.user_song_daily_with_side_info t1
LEFT ANTI JOIN hot_users t2 ON t1.user_id = t2.user_id
WHERE t1.dt BETWEEN date_sub('${bizdate_1}', 89) AND '${bizdate_1}'
AND t1.effective_play_cnt_1d > 0
GROUP BY t1.user_id, t1.song_id
HAVING SUM(t1.effective_play_cnt_1d) > 3 -- 90天播放超过3次
),
hot_user_90d_salted AS (
SELECT
CASE
WHEN t2.record_count > 10000 THEN CONCAT(t1.user_id, '', CAST(RAND() * 50 AS INT))
WHEN t2.record_count > 5000 THEN CONCAT(t1.user_id, '', CAST(RAND() * 30 AS INT))
ELSE CONCAT(t1.user_id, '_', CAST(RAND() * 20 AS INT))
END as user_id_salt,
t1.user_id,
t1.song_id,
t1.song_name,
t1.singer_artist_id_list,
t1.singer_artist_name_list,
t1.genre_tag_name,
t1.norm_language,
t1.duration,
t1.effective_play_cnt_1d
FROM music_most.user_song_daily_with_side_info t1
INNER JOIN hot_users t2 ON t1.user_id = t2.user_id
WHERE t1.dt BETWEEN date_sub('${bizdate_1}', 89) AND '${bizdate_1}'
AND t1.effective_play_cnt_1d > 0
),
hot_user_90d_stage1 AS (
SELECT
user_id_salt,
user_id,
song_id,
MAX(song_name) as song_name,
MAX(singer_artist_id_list) as singer_artist_id_list,
MAX(singer_artist_name_list) as singer_artist_name_list,
MAX(genre_tag_name) as genre_tag_name,
MAX(norm_language) as norm_language,
MAX(duration) as duration,
SUM(effective_play_cnt_1d) as partial_play_count
FROM hot_user_90d_salted
GROUP BY user_id_salt, user_id, song_id
),
hot_user_90d AS (
SELECT
user_id,
song_id,
MAX(song_name) as song_name,
MAX(singer_artist_id_list) as singer_artist_id_list,
MAX(singer_artist_name_list) as singer_artist_name_list,
MAX(genre_tag_name) as genre_tag_name,
MAX(norm_language) as norm_language,
MAX(duration) as duration,
SUM(partial_play_count) as play_count
FROM hot_user_90d_stage1
GROUP BY user_id, song_id
HAVING SUM(partial_play_count) > 3
),
user_song_90d AS (
SELECT * FROM normal_user_90d
UNION ALL
SELECT * FROM hot_user_90d
),
user_song_90d_ranked AS (
SELECT
user_id,
song_id,
play_count,
song_name,
singer_artist_id_list,
singer_artist_name_list,
genre_tag_name,
norm_language,
duration,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY play_count DESC, song_id) as rank
FROM user_song_90d
),
user_song_90d_agg AS (
SELECT
user_id,
collect_list(CASE WHEN rank <= 100 THEN song_id END) as user_often_listen_song_id_list_90d,
collect_list(CASE WHEN rank <= 100 THEN song_name END) as user_often_listen_song_name_list_90d,
collect_list(CASE WHEN rank <= 100 THEN singer_artist_id_list END) as user_often_listen_artist_id_list_90d,
collect_list(CASE WHEN rank <= 100 THEN singer_artist_name_list END) as user_often_listen_artist_name_list_90d,
collect_list(CASE WHEN rank <= 100 THEN genre_tag_name END) as user_often_listen_genre_list_90d,
collect_list(CASE WHEN rank <= 100 THEN norm_language END) as user_often_listen_language_list_90d,
collect_list(CASE WHEN rank <= 100 THEN play_count END) as user_often_listen_play_cnt_list_90d,
collect_list(CASE WHEN rank <= 100 THEN duration END) as user_often_listen_duration_list_90d,
SUM(CASE WHEN rank <= 100 THEN play_count ELSE 0 END) as total_play_count_90d,
COUNT(DISTINCT CASE WHEN rank <= 100 THEN song_id END) as distinct_song_count_90d
FROM user_song_90d_ranked
WHERE rank <= 100
GROUP BY user_id
)
-- ========== 最终结果合并 ========== --
SELECT
COALESCE(s7.user_id, s30.user_id, s90.user_id) as user_id,
-- 7天窗口
s7.user_often_listen_song_id_list_7d,
s7.user_often_listen_song_name_list_7d,
s7.user_often_listen_artist_id_list_7d,
s7.user_often_listen_artist_name_list_7d,
s7.user_often_listen_genre_list_7d,
s7.user_often_listen_language_list_7d,
s7.user_often_listen_play_cnt_list_7d,
s7.user_often_listen_duration_list_7d,
-- 30天窗口
s30.user_often_listen_song_id_list_30d,
s30.user_often_listen_song_name_list_30d,
s30.user_often_listen_artist_id_list_30d,
s30.user_often_listen_artist_name_list_30d,
s30.user_often_listen_genre_list_30d,
s30.user_often_listen_language_list_30d,
s30.user_often_listen_play_cnt_list_30d,
s30.user_often_listen_duration_list_30d,
-- 90天窗口
s90.user_often_listen_song_id_list_90d,
s90.user_often_listen_song_name_list_90d,
s90.user_often_listen_artist_id_list_90d,
s90.user_often_listen_artist_name_list_90d,
s90.user_often_listen_genre_list_90d,
s90.user_often_listen_language_list_90d,
s90.user_often_listen_play_cnt_list_90d,
s90.user_often_listen_duration_list_90d,
-- 统计信息
COALESCE(s7.total_play_count_7d, 0) as total_play_count_7d,
COALESCE(s30.total_play_count_30d, 0) as total_play_count_30d,
COALESCE(s90.total_play_count_90d, 0) as total_play_count_90d,
COALESCE(s7.distinct_song_count_7d, 0) as distinct_song_count_7d,
COALESCE(s30.distinct_song_count_30d, 0) as distinct_song_count_30d,
COALESCE(s90.distinct_song_count_90d, 0) as distinct_song_count_90d,
current_timestamp() as update_time
FROM user_song_7d_agg s7
FULL OUTER JOIN user_song_30d_agg s30 ON s7.user_id = s30.user_id
FULL OUTER JOIN user_song_90d_agg s90 ON COALESCE(s7.user_id, s30.user_id) = s90.user_id
WHERE COALESCE(s7.user_id, s30.user_id, s90.user_id) IS NOT NULL;
🤖
错误内容
通用异常,Spark任务执行失败,错误信息为:
java.lang.Exception: process exitCode: 1
该错误信息为Spark任务执行失败的通用异常,未包含具体的SQL语法或逻辑错误提示。
根据提供的信息,无法定位具体的SQL错误原因。建议检查Spark执行环境配置、资源分配及运行日志以获取详细错误信息。
错误原因:无具体语法或逻辑错误提示,任务执行失败可能由环境配置或资源分配问题引起。
修正建议:无SQL语法错误,暂不修改SQL。看下sql
最新发布




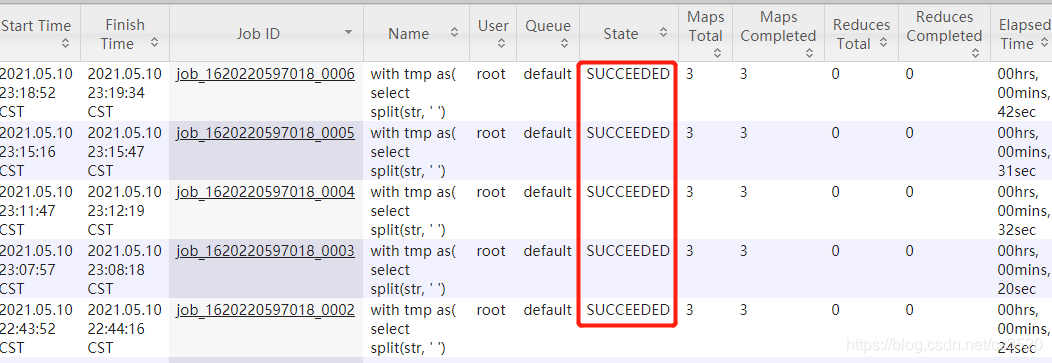
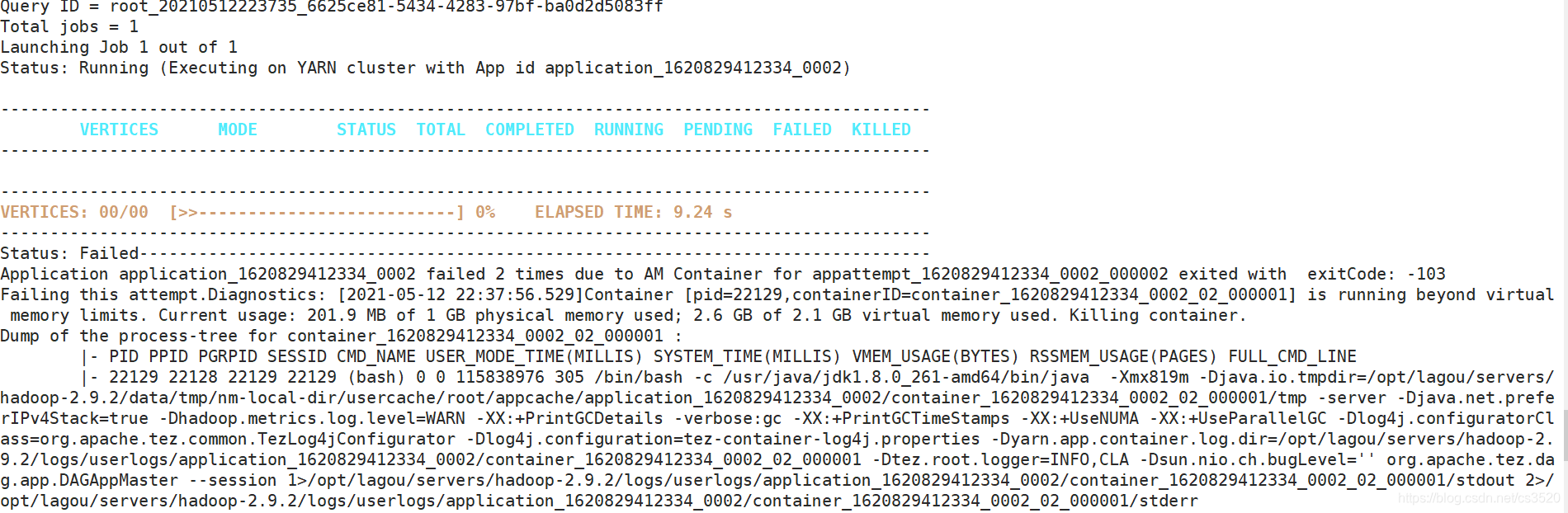
 本文针对Hive SQL执行过程中出现的内存溢出等问题进行了详细排查,并提供了有效的解决方案,包括更改执行引擎、调整YARN配置及优化SQL语句等。
本文针对Hive SQL执行过程中出现的内存溢出等问题进行了详细排查,并提供了有效的解决方案,包括更改执行引擎、调整YARN配置及优化SQL语句等。


















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









