







【能力目标】
- 掌握高效便捷的安装和卸载Ollama以及检测其状态;
- 掌握使用Docker镜像和容器技术,来高效便捷的部署Ollama;
- 掌握通过ollama pull等方式运行DeepSeek-R1大模型;
- 掌握Modelfile以及编写逻辑,通过Modelfile运行DeepSeek-R1大模型;
- 掌握编写高效脚本创建、运行大模型;
【任务描述】
本任务要求进行Ollama平台工具的安装,并利用Ollama的两种方式去创建并运行DeepSeek-R1等大模型,对比其中的优缺点,最后能编写高效的脚本去管理Ollama和大模型。
【知识储备】
1. 什么是Ollama
随着人工智能技术的快速发展,大模型(LLM)已越来越突出它的重要性。然而,这些大模型的运行通常需要大量的计算资源和复杂的部署流程。为了解决这个问题,Ollama应运而生。

Ollama是一个开源的大模型服务工具,旨在帮助用户在其本地机器、端边设备上轻松部署和运行开源大型语言模型,如Llama, Qwen, DeepSeek, Phi, Mistral, Gemma系列等。它提供了一个用户友好的界面和强大的功能,使用户能够轻松地部署和管理这些模型。
Ollama由Facebook AI Research(或相关团队)基于Go语言开发,支持在macOS、Linux、Windows上安装并运行。其特点与优势如下:
-
功能齐全:支持众多开源大模型接入、官方提供了模型库下载,并支持ollama pull|list类似docker相似的命令,并允许用户根据特定需求定制和创建自己的模型;提供类似OpenAI的API接口。
-
轻量级:Ollama的代码简洁明了,运行时占用资源少。这使得它能够在本地高效地运行,不需要大量的计算资源。此外,它还支持热加载模型文件,无需重新启动即可切换不同的模型,这使得它非常灵活多变。
-
易用性:Ollama提供了多种安装方式,支持Mac和Linux平台,并提供了Docker镜像。用户只需按照安装指南进行操作即可完成安装,无需具备专业的技术背景。
同类型的主流工具还有vllm、LM_Studio等,至于与Transformers/TGI、llama.cpp这种代码级的有那么些区别。
在实际应用中,Ollama常被用于自然语言处理、计算机视觉任务的本地研发和测试;以及渐渐在端边侧大模型的生产环境运行环境;Ollama还被用于企业内部构建私有AI应用系统的运行环境,通过Ollama,他们不仅能够节省大量的计算资源,还能够提高模型运行的效率。
2. Linux mktemp与install命令
2.1、mktemp命令
mktemp命令用于创建临时文件或目录,该临时文件或目录在系统中是唯一的,并且只有当前用户才能访问。
- -d:创建临时目录而不是文件。
- -u:不要创建文件,只返回一个唯一的文件名。
- --tmpdir=DIR:指定临时文件或目录的存储位置,如果不指定该参数则默认创建到
/tmp目录下。
当您不再需要这个临时文件或目录时,您应该清理它,以避免留下不必要的文件或目录。这可以通过简单地删除该目录来完成,例如使用 rm -rf 命令。 与mkdir的区别主要在于"临时还是持久性"、"命名唯一还是可重复性"。
2.2、install命令
Linux默认的install命令实际上是一个用于复制文件并设置文件权限的工具,它通常用于将文件从源位置复制到目标位置,并可以设置文件的权限、所有者和组,而不是直接用于安装软件包的。是有别于apt、yum等包管理工具。以下为该命令的常见用法:
install -o0 -g0 -m755 /path/to/source /path/to/destination install -o cs -g cs -m755 /path/to/source /path/to/destination
- -o, --owner=所有者:设置目标文件的所有者;
- -g, --group=组:设置目标文件的所属组;
- -m, --mode=模式:设置目标文件的权限模式(类似于chmod),而不是使用默认权限。模式可以用八进制数或符号表示;
- -d, --directory:创建一个目录而不是复制文件。
与cp的区别就是cp只是简单的复制,无法设置权限和所有者。
【任务实施】
Ollama有二进制和Docker等多种的安装方式。二进制又有一健安装和手动安装,所以这节我们全部来掌握它。
1. Ollama一键安装、卸载
一键安装主要依靠Shell脚本文件,通过Shell脚本文件的方式,技术支持工程师、运维工程师可以轻松实现的实现一键操作,从而方便他们快速的管理Ollama服务工具。
1.1、执行以下脚本文件一键安装:
$ curl -fsSL https://ollama.com/install.sh | sh
上述脚本由于保证联网且正常访问Ollama、NVIDIA官网,存在一定的失败率,请CTRL + C取消执行。
所以本教程已经事先下载好了Ollama安装包,并对install.sh进行了微小修改,确保在没有网络和网络不好的情况下,脚本优先使用本地安装包进行安装。

当然Ollama安装包可以从github ollama的主页进行下载,支持的各操作系统安装包:
https://github.com/ollama/ollama/releases
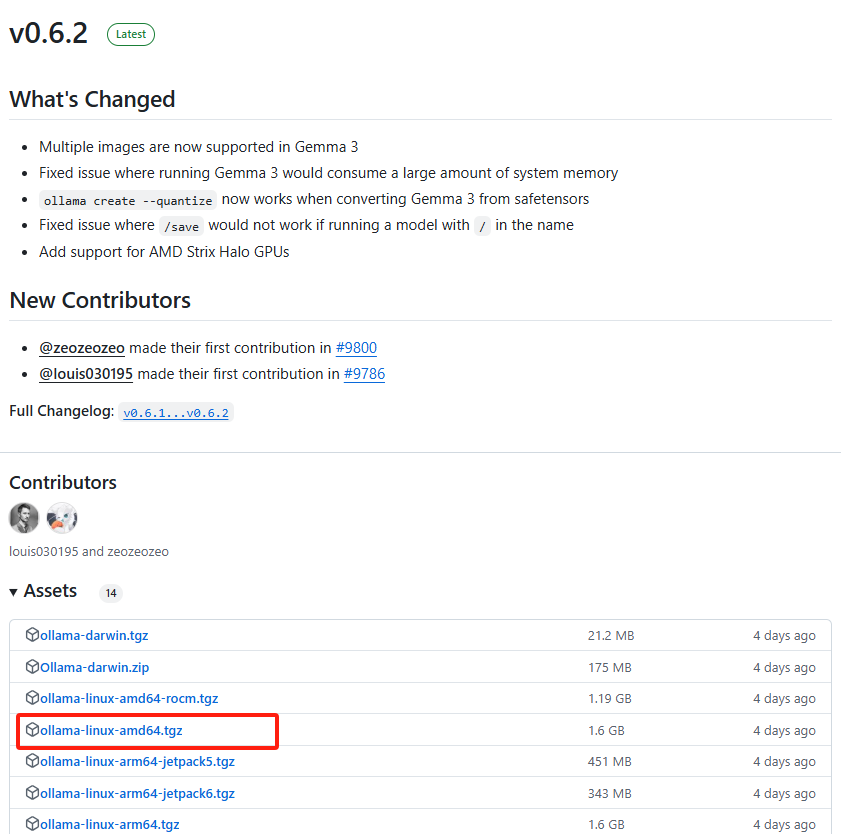
若是Ubuntu操作系统,选择其中ollama-linux-amd64.tgz下载即可,然后存放上传到lmservice/ollama/install.sh同级目录下,如下图所示:
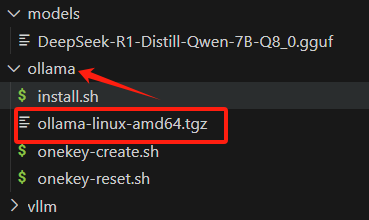
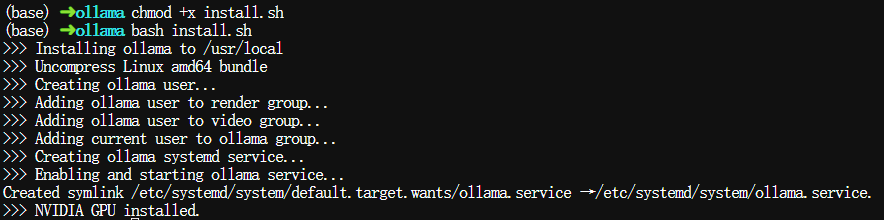
确认已进入lmservice/ollama目录下,接着正式执行以下命令进行安装:
$ chmod +x install.sh $ bash install.sh
1.2、检查安装后的Ollama版本及运行状态,输入以下命令检查:
$ ollama -v $ curl http://localhost:11434

能正常输出版本号 或 Ollama is running,则说明安装成功。
1.3、卸载Ollama,输入以下命令进行卸载:
注意:通过一链脚本安装的Ollama,后续Ollama进行模型权重下载时,会将文件默认保存在/usr/share/ollama/.ollama目录下(稍后在手动安装时再解释)。
1.3、接下来进行一键卸载。一键卸载是一链安装的逆过程,我们将卸载动作编写成Shell脚本文件,命名onekey-reset.sh,执行以下命令一键卸载Ollama:
$ chmod +x onekey-reset.sh $ bash onekey-reset.sh ollama

onekey-reset.sh后面需要紧跟ollama参数,这里的ollama参数表示只需卸载的Ollama。该脚本还可以卸载其它服务,后续再单独介绍。
卸载Ollama后,再执行以下命令查看是否卸载成功,显示未找到相关文件或目录的表示成功卸载:
$ ollama -v

2. Ollama手动安装
Ollama一键安装的优势毋庸置疑。但某些情况下,想掌握Ollama的详细安装过程和逻辑,必要时候可以一步步的操作,让安装过程更清晰。
2.1、解压Ollama包
ollama-linux-amd64.tgz压缩包包含了运行文件和库文件,执行以下命令解压文件到/usr/local,你也可以更改为其它目录,如~/ollama:
$ tar -xzf ollama-linux-amd64.tgz -C /usr/local
![]()
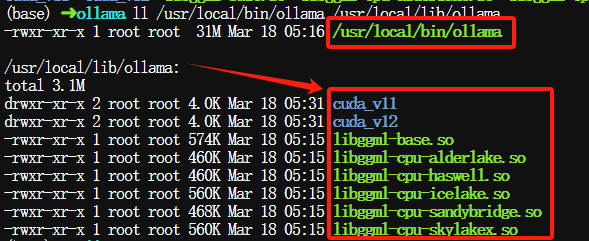
在/usr/local/bin会找到Ollama可执行文件, 在/usr/local/lib目录会找到库文件,查看两个目录情况:
$ ll /usr/local/bin/ollama /usr/local/lib/ollama
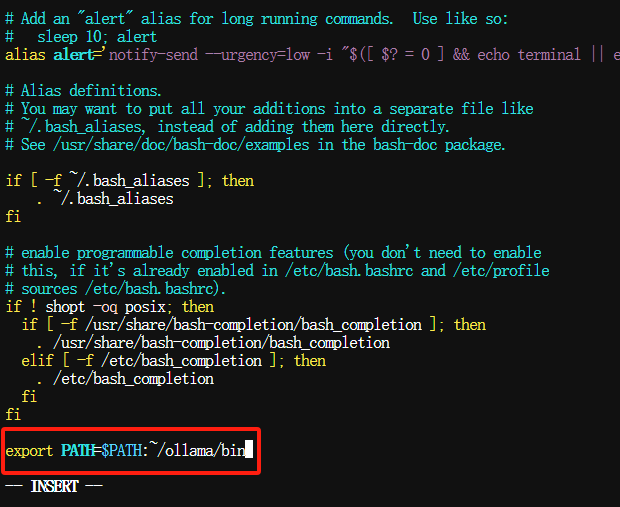
(可选)如果Ollama安装包不是解压到/usr/local目录,为了后续使用方便。需要将解压目录添加到$PATH环境变量中,这样我们可以方便的以ollama [command]运行任何命令。比如解压到~/ollama,我们可以在主目录(如root)下找到.bashrc文件。在结尾写入~/ollama/bin文件路径,保存完退出后,要使环境变量生效:
$ export PATH=$PATH:~/ollama/bin $ source ~/.bashrc
使用chmod命令给/usr/local/bin/ollama添加可执行权限:
$ chmod +x /usr/local/bin/ollama
然后在任意路径下输入如下命令,测试Ollama是否生效:
$ ollama -h
2.2、设置Ollama开机自启或后台运行,且开放所有网络可访问
首先检测系统是否支持systemd:
$ systemctl is-system-running
返回running代表systemd可用,可以通过服务的形式设置Ollama为开机自启。

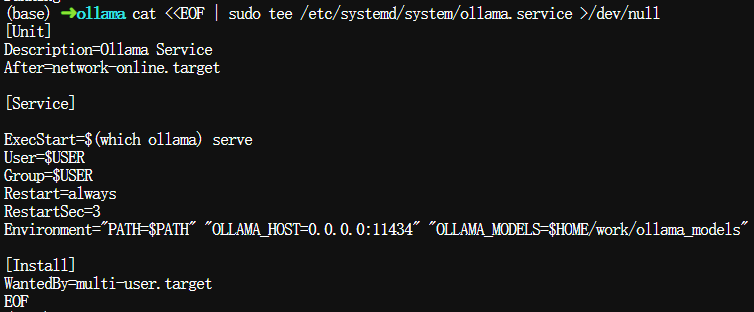
创建Ollama服务文件,其中两个环境变量:
- OLLAMA_HOST:0.0.0.0:11434,表示监听所有网络地址,端口11434;
- OLLAMA_MODELS:$HOME/work/ollama_models,表示Ollama下载的模型权重文件会保存在该设置了目录下。不设置的情况,默认为运行Ollama用户的
家目录/.ollama隐藏目录下。
cat <<EOF | sudo tee /etc/systemd/system/ollama.service >/dev/null [Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=$(which ollama) serve User=$USER Group=$USER Restart=always RestartSec=3 Environment="PATH=$PATH" "OLLAMA_HOST=0.0.0.0:11434" "OLLAMA_MODELS=$HOME/work/ollama_models" [Install] WantedBy=multi-user.target EOF
重新加载配置、开机自启、立马启动Ollama:
$ sudo systemctl daemon-reload && \ sudo systemctl enable ollama && \ sudo systemctl start ollama

如果命令systemctl is-system-running返回degraded或offline等信息,表示systemd不可用(可能系统是以容器运行的)。

此时不方便通过创建服务的方式让Ollama自启动,但可以通过让Ollama以后台进程或任务的形式运行。
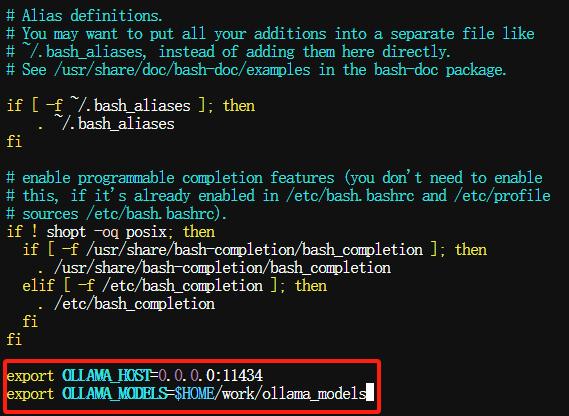
同样设置OLLAMA_HOST和OLLAMA_MODELS两个环境变量,将它们写入到~/.bashrc文件中:
$ sed -i '/OLLAMA_HOST/d' ~/.bashrc && \ echo 'export OLLAMA_HOST=0.0.0.0:11434' >> ~/.bashrc $ sed -i '/OLLAMA_MODELS/d' ~/.bashrc && \ echo 'export OLLAMA_MODELS=$HOME/work/ollama_models' >> ~/.bashrc
接着,以后台进程启动ollama服务:
$ nohup ollama serve > ollama.log 2>&1 &

最终,检查Ollama是否安装成功,输入以下命令查看:
$ ollama -v && curl http://localhost:11434

3. 使用Docker安装Ollama
3.1、使用Docker部署的优势
相对于前面两个方式部署Ollama,使用Docker来安装Ollama具有更明显的优势,比如:
- 更便捷:无须编写大量Shell脚本,容器可快速启动、停止和删除;
- 环境隔离:Docker容器提供了隔离环境,避免与本教程其它应用之间的干扰。
- 可移植性:一键安装或手动安装都需要根据服务器架构及操作系统类型进行安装,而Docker的通用命令很适合在Windows、Linux、MacOS等操作系统上进行。
- GPU可访问:通过配置Docker容器运行时的--gpus参数,可以允许容器访问主机上的GPU。
当前也存在一些缺点,比如:
- 性能:虽然Docker容器提供了比虚拟机更好的性能,但其性能仍然不如直接在物理上运行。在CPU上运行Docker的性能可能会比同样的硬件上的一个主机性能略低。
- 复杂性:对于不熟悉Docker的用户来说,学习和理解Docker可能需要一些时间。同时,管理和维护Docker环境也可能需要额外的技能和资源。
3.2、Ollama镜像拉取和导入
Ollama的官方镜像名为ollama/ollama:
但使用官方仓库没有代理目前基本下载不下来。本教程也提供了离线的镜像包,文件名为ollama.tar。
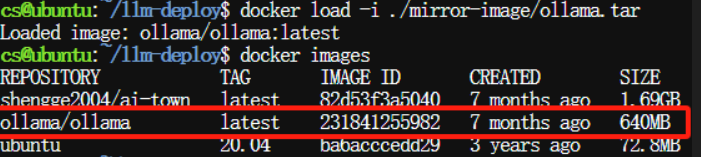
使用以下命令将ollama.tar加载进来:
$ docker load -i ./mirror-image/ollama.tar
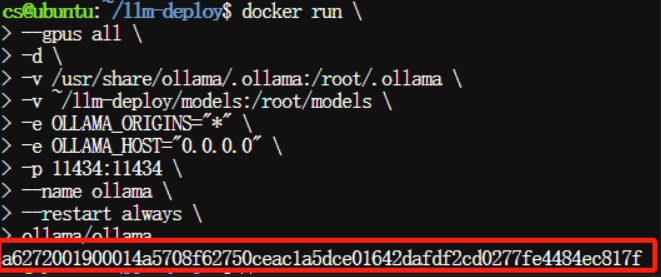
3.3、执行Docker命令安装Ollama
$ docker run \ --gpus all \ -d \ -v /usr/share/ollama/.ollama:/root/.ollama \ -v ~/llm-deploy/models:/root/models \ -e OLLAMA_ORIGINS="*" \ -e OLLAMA_HOST="0.0.0.0" \ -p 11434:11434 \ --name ollama \ --restart always \ ollama/ollama
这里是每个参数和选项的详细解释如下:
- --gpus all:允许容器访问主机上的所有GPU;格式--gpus all|device=[,...]|number=:
all:允许容器访问主机上的所有 GPU。device=<ID>[,<ID>...]:允许容器访问指定ID的GPU,可以通过nvidia-smi命令来查看GPU的ID。number=<num>:允许容器访问主机上指定数量的GPU,但Docker会自动选择它们。
- -v /usr/share/ollama/.ollama:/root/.ollama:将主机上的 /usr/share/ollama/.ollama 目录挂载到容器内的 /root/.ollama 目录;
- -v ~/llm-deploy/models:/root/models:将主机上存入本地大模型文件的目录挂载到容器内,容器内可以直接使用;
- -e OLLAMA_ORIGINS="*":设置环境变量 OLLAMA_ORIGINS。这个环境变量允许的请求来源有所有即可跨域;
- -e OLLAMA_HOST="0.0.0.0":设置环境变量 OLLAMA_HOST ,与下面的端口结合,允许通过任意主机上的IP访问容器内运行的服务;
这个命令执行后,Docker会根据 ollama/ollama 镜像,创建一个新的容器实例,并配置它以使用GPU、挂载卷、设置环境变量、映射端口等。
3.4、检查Ollama容器启动结果
根据各自生成的那串容器ID检查容器挂载情况,验证Ollama容器运行情况:
$ docker inspect a6272001900014a5708f62750ceac1a5dce01642dafdf2cd0277fe4484ec817f
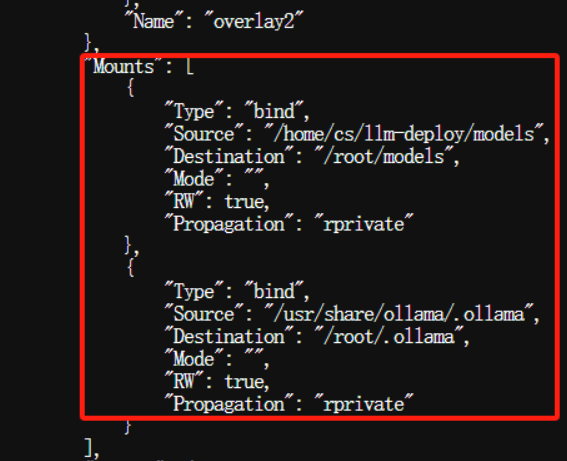
其中Ollama支持除了上面说到的OLLAMA_ORIGINS、OLLAMA_HOST环境变量外,还支持以下几种:
- OLLAMA_PORT:这个变量允许我们更改Ollama的默认端口。例如,设置OLLAMA_PORT=11000可以将服务端口从默认的11434更改为11000。
- OLLAMA_NUM_PARALLEL:这个变量决定了Ollama可以同时处理的用户请求数量。设置OLLAMA_NUM_PARALLEL=4可以让Ollama同时处理两个并发请求,如在对话中,可以同时处理两个用户对话,无须等待。
- OLLAMA_MAX_LOADED_MODELS:这个变量限制了Ollama可以同时加载的模型数量。设置OLLAMA_MAX_LOADED_MODELS=4可以确保系统资源得到合理分配。
- OLLAMA_MODELS:这个变量指定了模型镜像的存储路径,通过设置OLLAMA_MODELS=/usr/.ollama-cache,避免空间不足的问题。
- OLLAMA_KEEP_ALIVE:这个变量控制所有模型在内存中的存活时间,例如设置OLLAMA_KEEP_ALIVE=24h可以让模型在内存中保持24小时,提高访问速度,但会增加显存压力。支持单位s、m、h。
一切正常,这时候不能通过 ollama -v 检查安装是否成功,因为Ollama是安装在容器里面的,需要进入容器才能执行那句命令:
$ docker ps -a $ curl http://localhost:11434

执行以下命令进入容器,进入容器后,可以使用ollama -v命令检查安装是否成功。
$ docker exec -it ollama bash $ ollama -v

4. DeepSeek-R1模型权重下载及管理
Ollama运行大模型之前,需将大模型先导入到Ollama中,导入大模型有两种常见方法:
- 使用ollama pull命令;
- 编写Modelfile文件,通过
ollama create name -f Modelfile文件导入。
两种方法各有优缺点,任选其一执行即可。
4.1、在线导入大模型权重
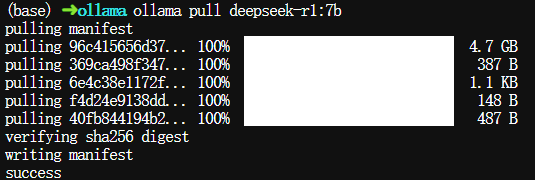
执行以下命令下载DeepSeek-R1 7B的蒸馏权重文件,如果要大点的可以把deepseek-r1:7b改成deepseek-r1:32b,满血版的名称deepseek-r1:671b
$ ollama pull deepseek-r1:7b
- ollama pull:从Ollama服务器下载模型的命令;
- deepseek-r1:7b:模型名称,名称从官网仓库搜索;

ollama pull命令后会自动下载模型权重并自动完成导入,通过ollama list命令查看已下载的模型列表:
$ ollama list

pull下来的文件也会保存到Ollama默认权重存储目录,请根据之前的安装方式,到相应目录查看。例如我们之前设置到~/work/ollama_models,输入以下命令查看~/work/ollama_models下的文件列表:
$ ll -h ~/work/ollama_models/blobs
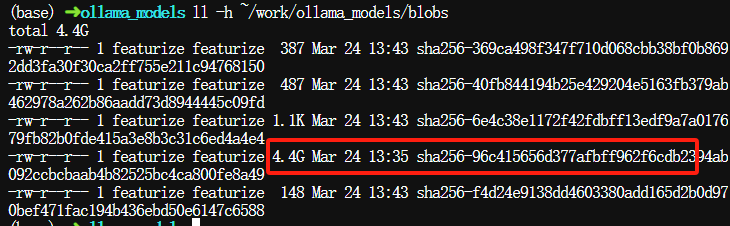
本次pull会生成5个文件,其中标红框的即是模型权重文件,其它4个文件依次是模型配置文件、license文件、提示模板文件、设置参数文件。
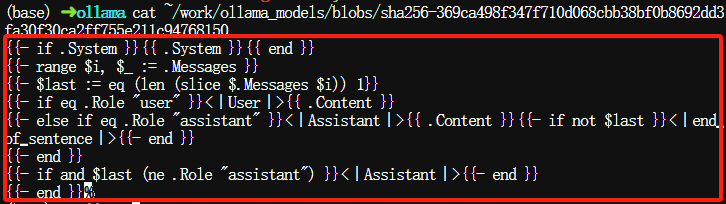
其中提示模板文件具有重要的意义,我们可以查看下它的文件内容,等后面再解释:
$ cat ~/work/ollama_models/blobs/sha256-369ca498f347f710d068cbb38bf0b8692dd3fa30f30ca2ff755e211c94768150
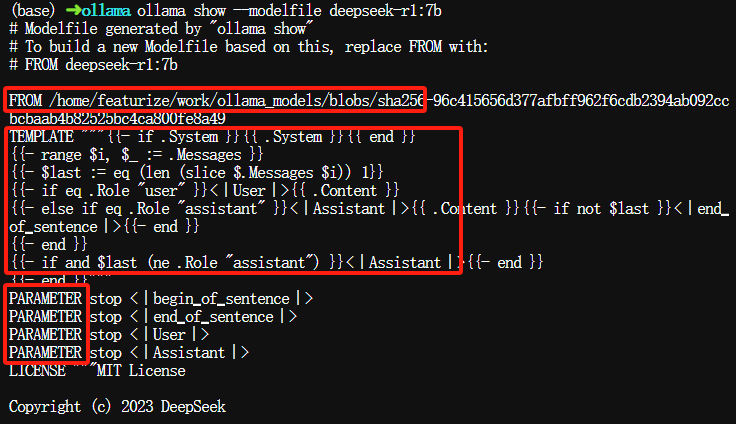
也可以使用ollama show命令查看已下载模型的详细信息,例如模型的名称、版本、大小、配置文件,如下图所示:
$ ollama show --modelfile deepseek-r1:7b
4.2、使用Modelfile导入大模型
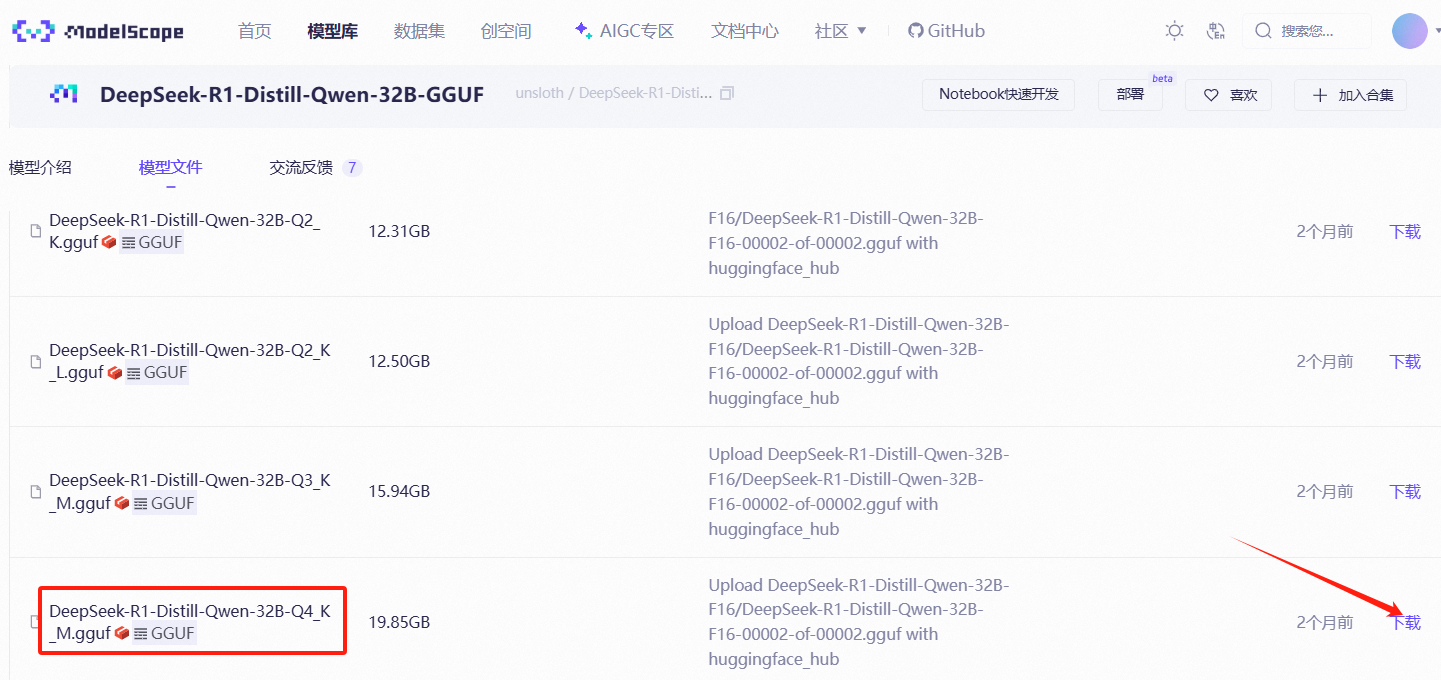
除了使用ollama pull命令外,ollama也支持手动下载模型,但需要是GGUF格式。目 前DeepSeek-R1 32B模型已有各种不同量化版本的GGUF模型在魔搭社区和huggingface中上线了:魔搭社区
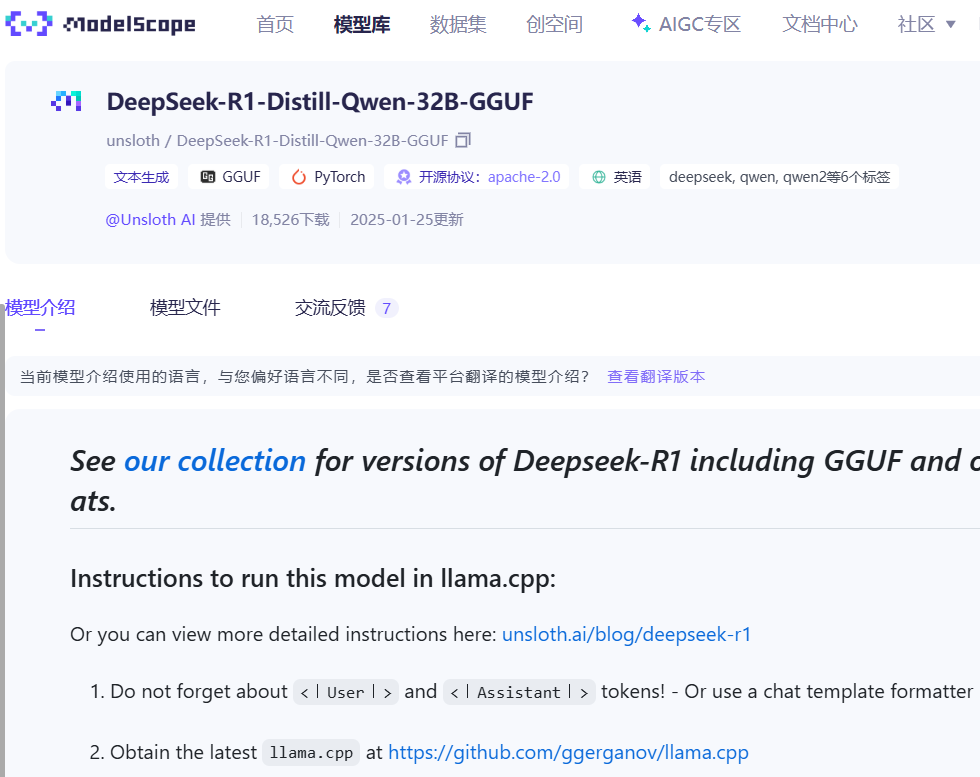
其中包含多个量化版本的GGUF文件:
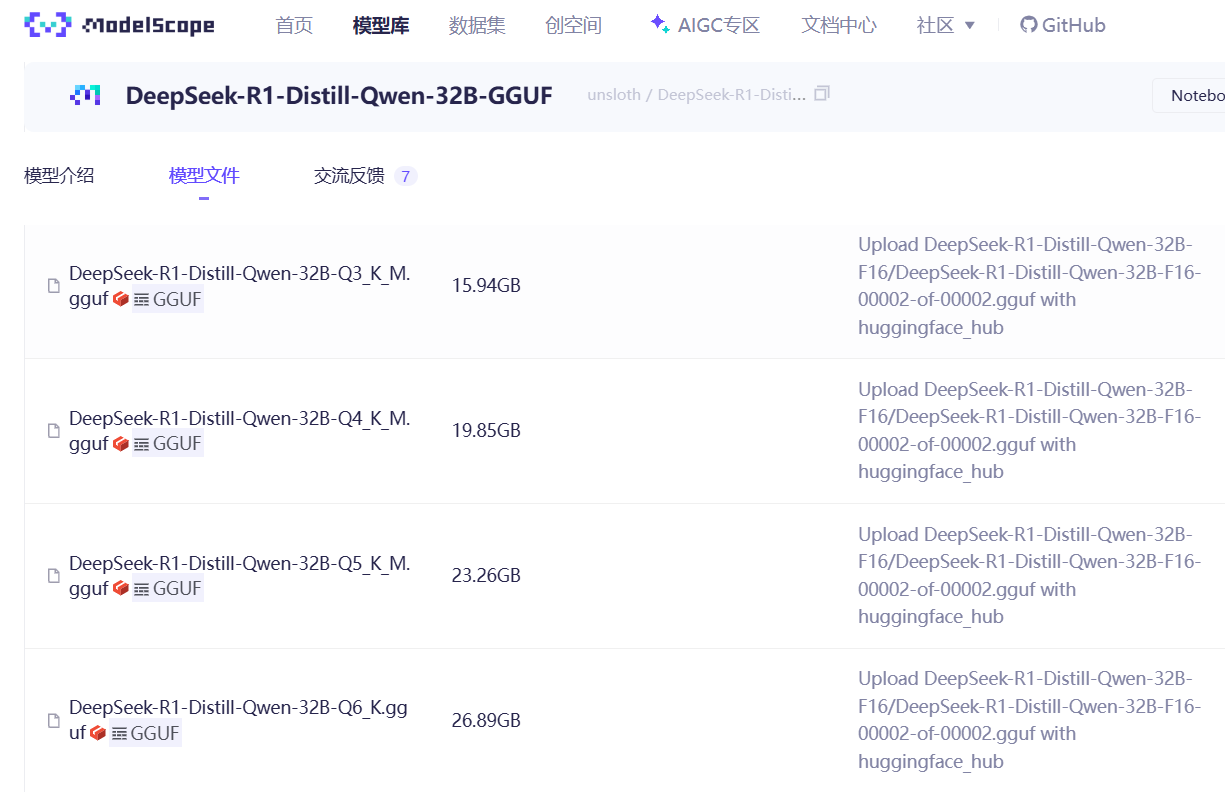
这里我们考虑下载Q4_K_M量化版本的GGUF权重进行调用,具体下载方式也有几种,我们逐一解读:
- 下载方式一:通过
Git下载
切换到"模型文件"标签页,点击右侧的"下载模型",弹出各个下载方式的滑出小窗,复制Git地址,如下图:
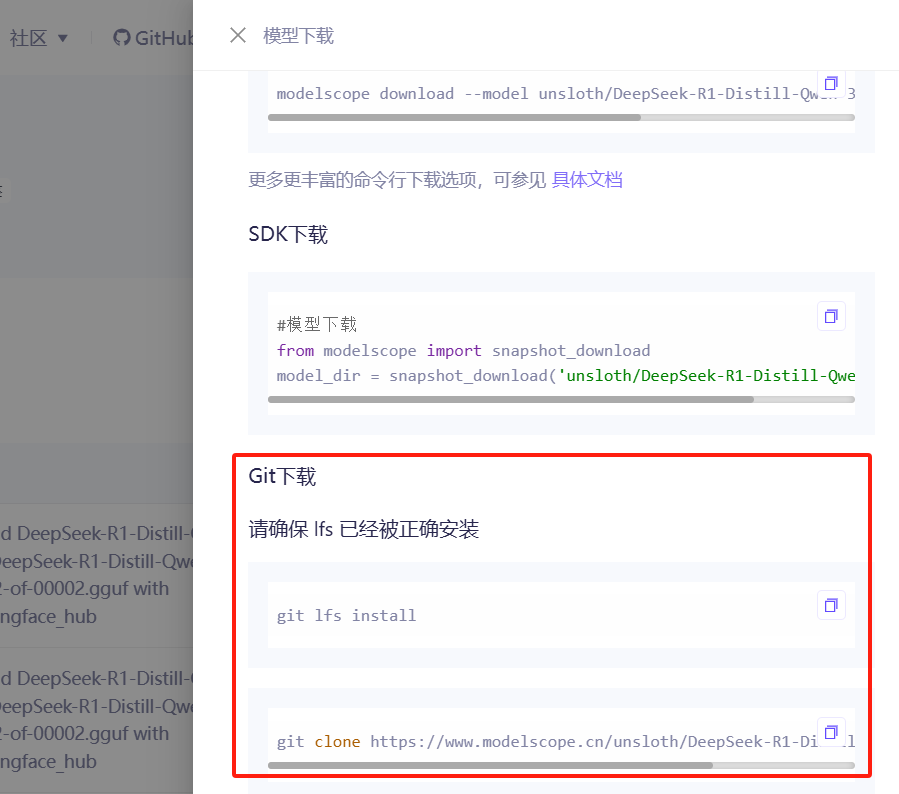
Git拉取大文件,需要Git Large File Storage扩展(简称LFS)支持,用于管理大文件(如二进制文件、数据集等),避免它们直接存储在 Git 仓库中,从而减少仓库体积。安装Git Large File Storage扩展:
$ sudo apt-get install git-lfs
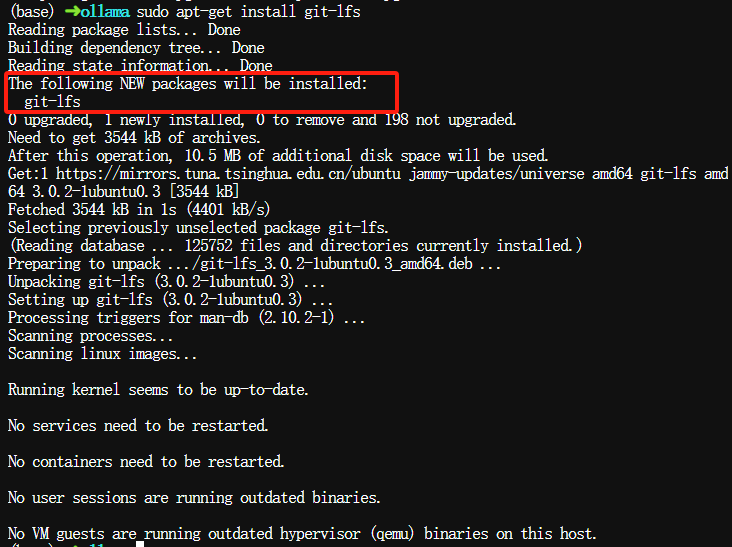
进入lmservice/models目录下,执行以下拉取大模型文件命令,如果网络较慢,可以尝试使用代理。
$ git clone https://www.modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF.git
- 下载方式二:通过
modelscope命令行下载
安装modelscope命令行工具,执行以下命令:
$ pip install modelscope
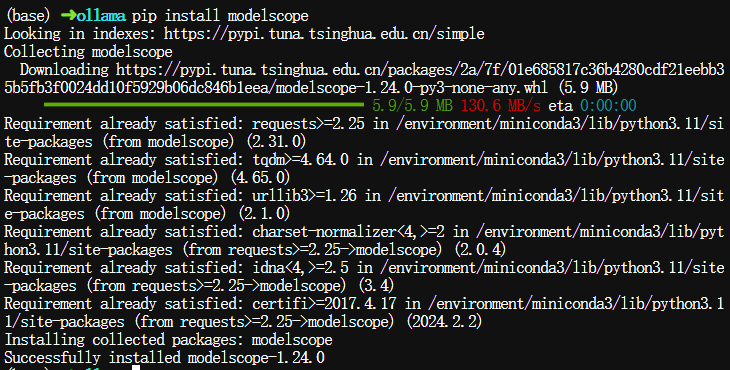
modelscope安装成功后,执行以下命令下载模型文件:
$ cd ~/work/lmservice/models $ modelscope download --model unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf --local_dir ./
- --model: 指定模型名称;
- DeepSeek-R1-Distill-Qwen-32B-GGUF:要下载的单个文件名;
- --local_dir:指定模型文件下载到本地的目录。
关于modelscope更详细的使用,可以参考这里

下载完成,文件如下图:

此外,也可以在课件的网盘中进行下载:
- 下载方式三:通过
浏览器下载
进入模型文件页面,找到以Q4_K_M结尾且.gguf格式的文件,点击右侧的下载,默认使用浏览器的下载,存储在浏览器下载目录。完成后,将文件上传到models目录下:
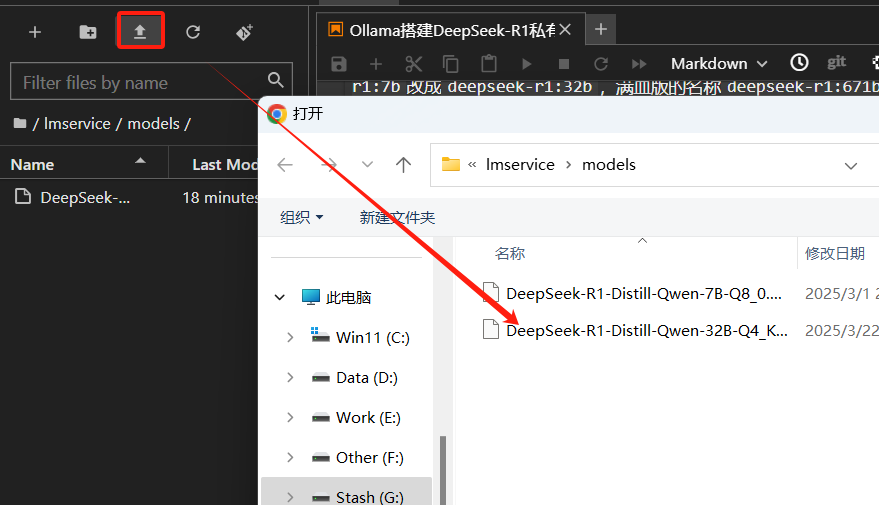
接着创建并编写Modefile文件,可以命名为DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.Modelfile(文件名可以自定义),用于描述模型文件相关信息,包括模型权重文件、参数、提示模板等。执行以下命令:
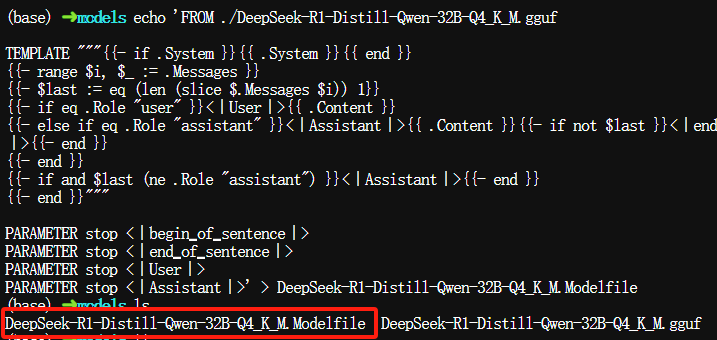
$ echo 'FROM ./DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
PARAMETER stop <|begin▁of▁sentence|>
PARAMETER stop <|end▁of▁sentence|>
PARAMETER stop <|User|>
PARAMETER stop <|Assistant|>' > DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.Modelfile
运行后生成Modefile文件:
- FROM指定的是模型权重GGUF文件所在的相对位置;
- TEMPLATE和PARAMETER的值可以打开模型信息详细页:
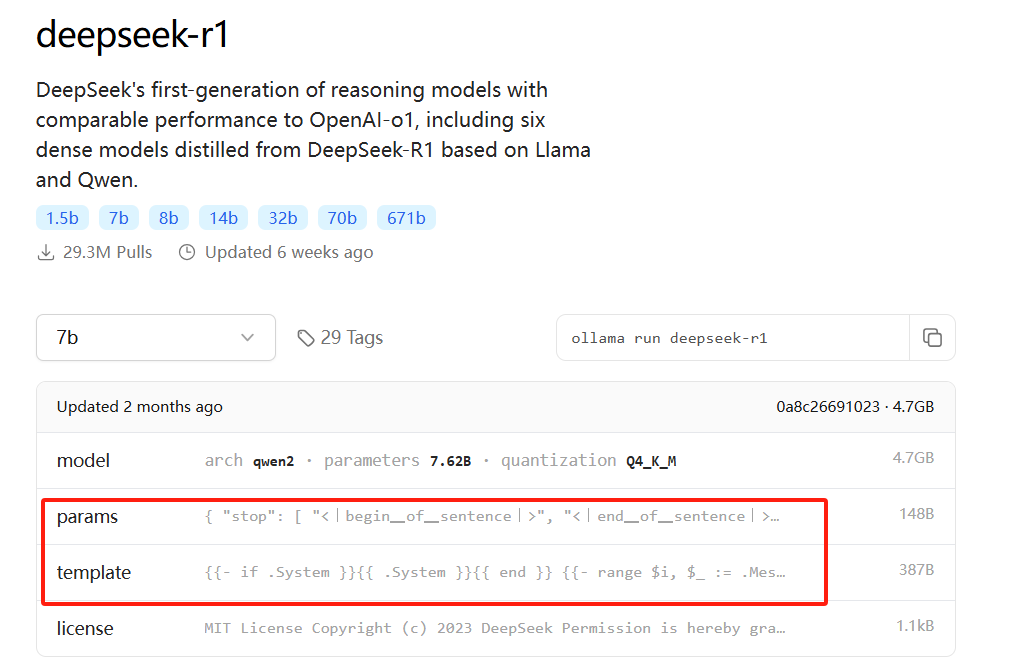
如果不设置TEMPLATE和PARAMETER也是可以,但后续模型回答的效果不佳。
创建deepseek-r1:32b模型,将该模型加入Ollama本地模型列表:
$ ollama create deepseek-r1:32b -f DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.Modelfile

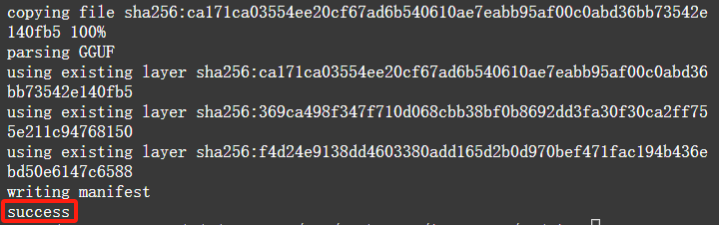
注:使用Ollama的任何命令,都要确保ollama处于运行状态,如果未运行,临时使用ollama start启动
使用ollama list命令查看已导入的模型,如下图所示:
$ ollama list

查看~/.ollama/models/blobs/目录,可以发现多了两个文件:
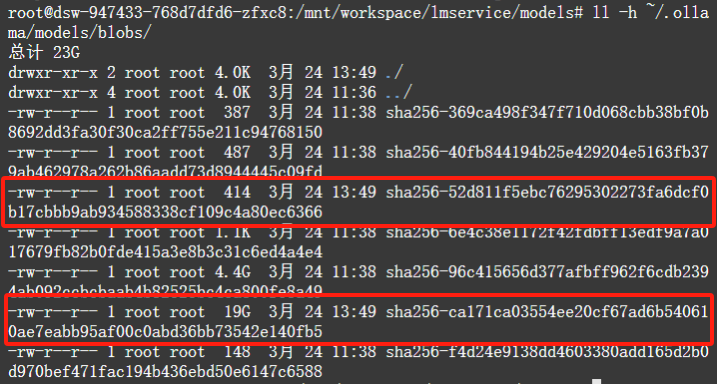
在模型默认存储目录的清单目录,可以发现多了新目录:

4.3、Ollama管理大模型
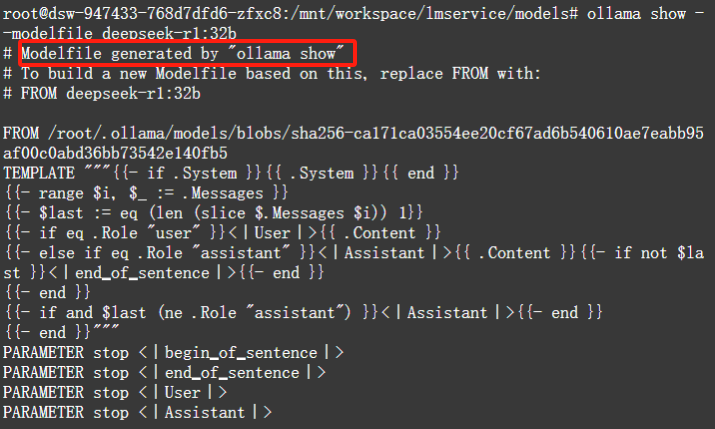
通过以上两种方式可以导入、创建大模型,那么查看已创建的大模型详细信息,执行以下命令:
$ ollama show --modelfile deepseek-r1:32b
ollama list会列出所以已创建的大模型。查看已运行状态的大模型,使用以下命令:
$ ollama ps
![]()
复制一个已存在的大模型,命名为新的名称,执行以下命令:
$ ollama cp deepseek-r1:7b deepseek-r1:7b-copy
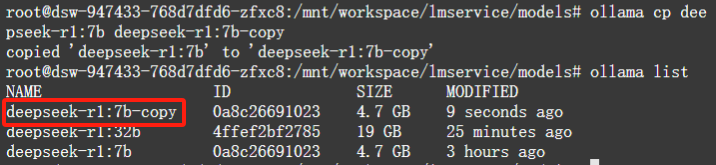
删除大模型,执行以下命令:
$ ollama rm deepseek-r1:7b-copy
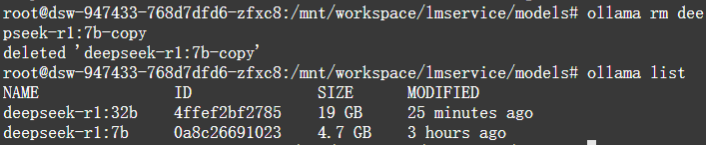
5. 运行DeepSeek-R1模型
完成以上模型导入后,接下来即可在命令行中直接运行:
$ ollama run deepseek-r1:32b
(注:如果本地没有对应名称的已导入模型,Ollama会尝试自动下载模型,等于同时运行了ollama pull)

运行成功后,即可在命令行中直接使用DeepSeek-R1模型进行对话。





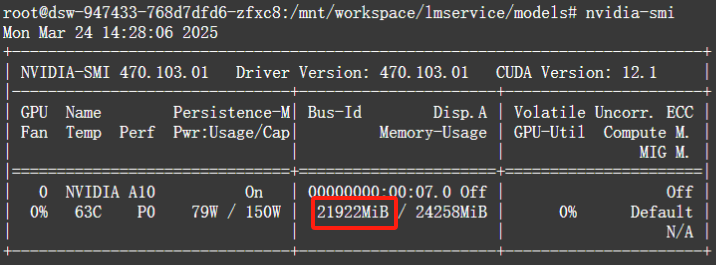
基本也可以达到15Tokens/s左右的速度了,显存占用约22G左右。
6. 聊天机器人App调用Ollama私有大模型服务
之前的几节课程都是调用云端的在线大模型服务,本小节我们来调用基于上述自行搭建的Ollama私有大模型服务。
Ollama运行状态下,默认会暴露11434端口提供API(也就是OpenAI风格API)接口,我们同样可以通过OpenAI SDK调用该服务。
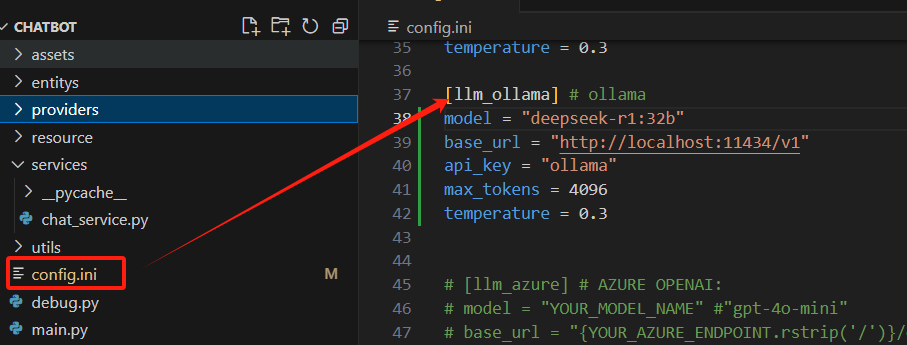
打开应用程序的config.ini文件,配置llm_ollama节内容,内容如下:
在vscode开发环境中,新建一个终端运行python main.py -b=ollama:

显示要演示的功能,选择2进行多轮对话测试。在终端输入提问:编写使用java语言的冒泡排序算法:
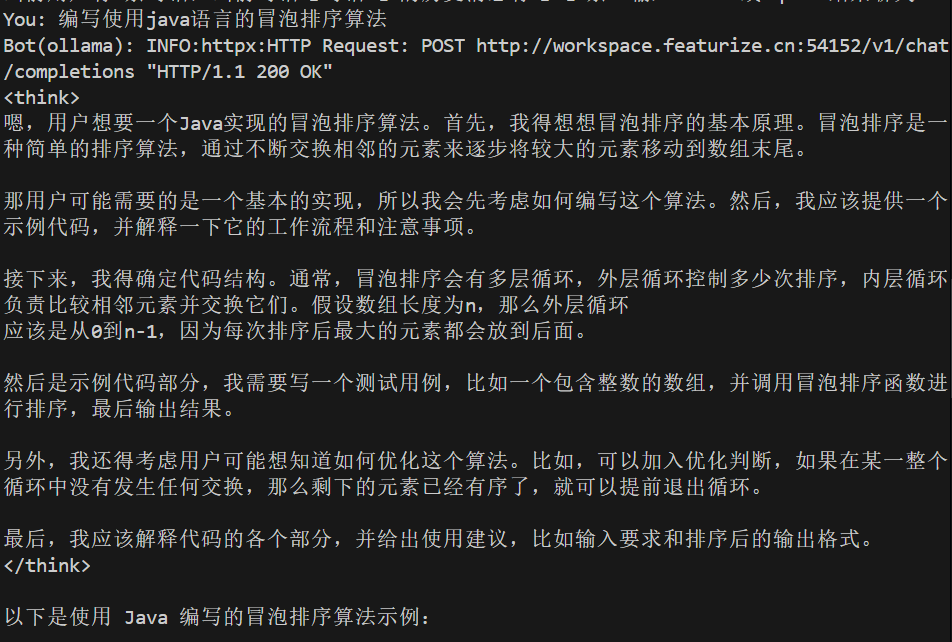

或者直接运行以下代码,根据提示输入问题:
In [6]:
%run ../chatbot/main.py -b=ollama
1: 单轮对话 2: 多轮对话 3: 附带文档的对话 4: 返回JSON格式的对话 5: 工具调用(tool use或Function Calling) 6: 视觉对话 7: 向量化的语义搜索 当前用户有2条对话,当前对话【对话2】的历史消息有【1】条。输入"exit"或"quit"结束聊天. Bot(ollama):
INFO:httpx:HTTP Request: POST http://workspace.featurize.cn:54152/v1/chat/completions "HTTP/1.1 200 OK"
<think>
嗯,我现在要写一个Java程序来实现冒泡排序。我对冒泡排序的基本概念还不是很清楚,所以得先回忆一下什么是冒泡排序。
冒泡排序是一种简单的排序算法,它通过不断交换相邻的元素来进行排序。它的名字来源于水中冒泡的现象,体积大的气泡会逐渐浮到水面。同样地,在冒泡排序中,较大的元素会逐渐“冒”到数组的后面。
那冒泡排序的基本步骤是怎样的呢?我记得大概是这样的:首先比较相邻的两个元素,如果前面的元素比后面的要大,就交换它们的位置。然后重复这个过程,直到整个数组都被排好序了。每次循环都会让最大的未排序元素“沉”到数组的末尾。
那我需要写一个Java程序来实现这个算法。首先,我得考虑输入和输出的情况。用户应该能够输入一组数字,这些数字会被转换为整数,并存入一个数组中。然后,调用冒泡排序函数对数组进行排序,最后输出排序后的结果。
接下来,我需要设计一个冒泡排序的函数。这个函数接收一个整数数组作为参数,然后对其进行排序。函数内部的具体实现步骤是什么呢?
首先,我得确定循环的次数。因为每次最大的元素都会被放到后面,所以外层循环应该从数组长度到2进行遍历。比如,如果数组有n个元素,那么需要进行n-1次这样的循环。
在每个外层循环中,内层循环负责比较相邻的两个元素,并交换它们的位置。内层循环的范围应该是从0到当前外层循环的索引位置减一。这样可以确保每次最大的元素都被放到正确的位置。
举个例子,假设数组是{4, 2, 7, 1}。第一次外层循环i=0时,j会从0到0比较两次:先比较4和2,交换后变成{2,4,7,1};然后比较4和7,不交换;接着比较7和1,交换后变成{2,4,1,7}。这样最大的元素7就被放到最后了。
接下来,我需要考虑如何处理输入的数字。用户应该能够输入多个整数作为输入,可能包括空格分隔或者换行符。所以,在读取输入的时候,我需要用split方法来分割字符串,并将每个部分转换为整数存入数组中。
然后,调用冒泡排序函数并对数组进行排序。最后,输出排序后的结果,每个数字之间用空格分隔。
那现在开始写代码吧。首先导入必要的包,比如Scanner类用于读取输入。
然后,创建一个主类,并在main方法中处理输入和排序。
读取输入的时候,使用System.in.readLine()来获取用户输入的一行字符串。split(" ")可以将这行字符串分割成多个部分,得到一个String数组。然后用try-catch块来处理可能的异常情况,比如空输入或者无效格式的情况。
接着,调用冒泡排序函数sortArray(arr)。这个函数需要实现前面所说的逻辑:双重循环,比较并交换元素。
在冒泡排序函数内部,外层循环i从0到arr.length-2(因为每次最大的元素都会放到后面),内层循环j从0到n-i-1,其中n是数组的长度。这样可以确保每轮都处理剩下的未排序部分。
在内层循环中,比较arr[j]和arr[j+1]。如果前者大于后者,则交换它们的位置。
最后,输出结果。将排序后的数组转换为字符串,用空格连接每个元素,并打印出来。
测试一下代码是否正确。比如输入4 2 7 1,应该得到1 2 4 7。再比如输入5个数字,看看是否能正确排序。
哦,对了,我还需要考虑边界情况,比如数组为空或者只有一个元素的情况。这时候冒泡排序自然会返回原数组,没有问题。
那现在把这些步骤整合成代码。记得处理异常,确保输入是有效的整数数组。
</think>
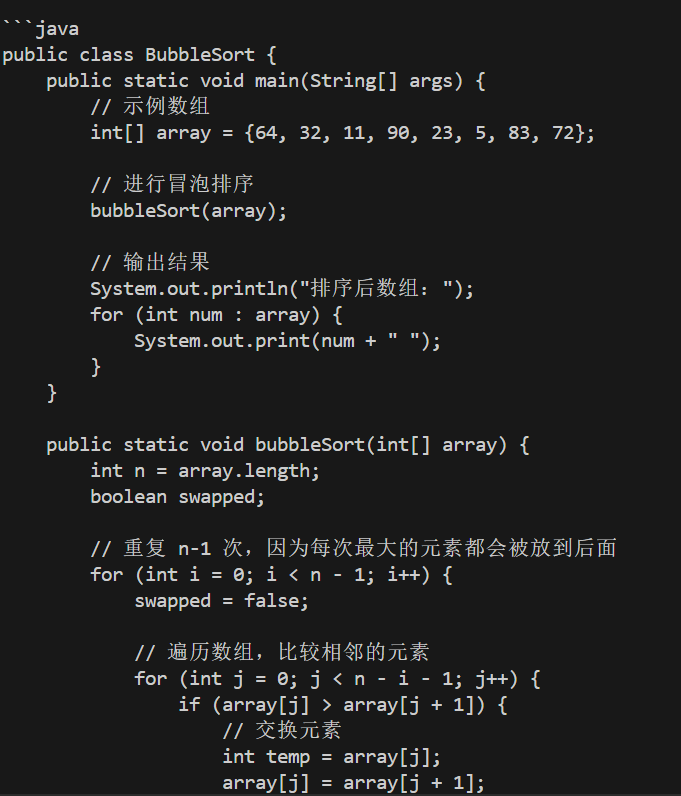
以下是使用Java实现的冒泡排序算法:
```java
import java.util.Arrays;
import java.util.Scanner;
public class BubbleSort {
public static void sortArray(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// 交换元素
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一组数字(用空格分隔):");
String[] input = scanner.nextLine().split(" ");
int[] arr = new int[input.length];
for (int i = 0; i < input.length; i++) {
try {
arr[i] = Integer.parseInt(input[i]);
} catch (NumberFormatException e) {
System.out.println("错误:请输入有效的整数");
return;
}
}
sortArray(arr);
System.out.println("排序后结果为:");
System.out.println(Arrays.toString(arr));
}
}
```
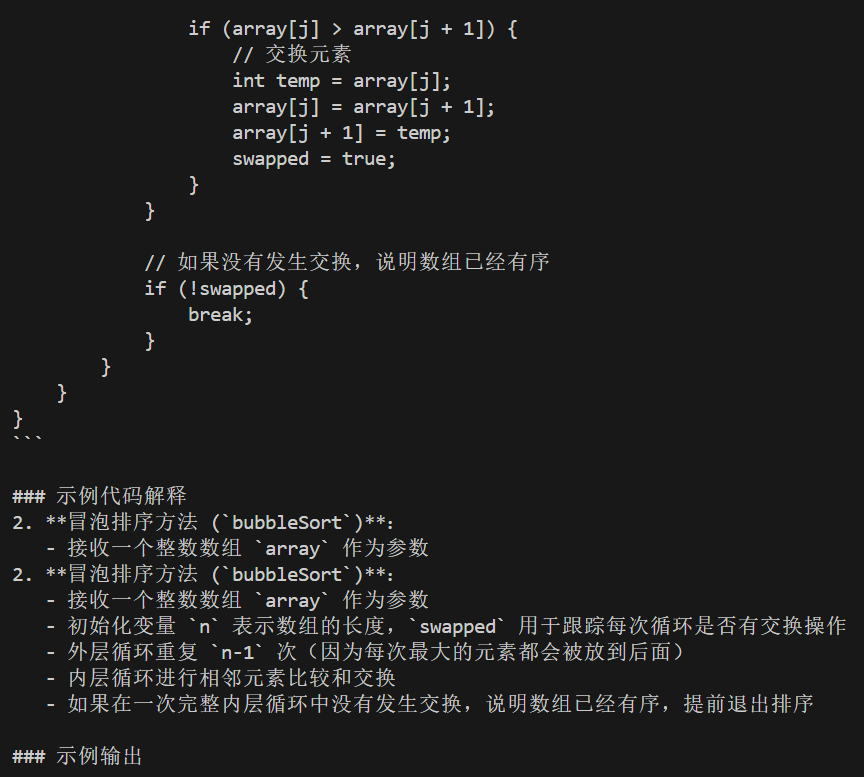
### 代码解释:
1. **冒泡排序函数**:
- `sortArray`方法接收一个整数数组,并对其进行冒泡排序。
- 外层循环控制每轮比较次数,从0到n-2(n为数组长度)。
- 内层循环进行相邻元素的比较和交换,确保每次最大的元素移动到正确位置。
2. **输入处理**:
- 使用`Scanner`读取用户输入,并将其分割成字符串数组。
- 将每个字符串转换为整数存入数组中,处理无效输入时输出错误提示并退出。
3. **排序和输出**:
- 调用`sortArray`方法对数组进行排序。
- 使用`Arrays.toString`将排序后的数组转换为字符串格式输出结果。
ERROR:utils.logger:获取响应失败: name 'exit' is not defined
Goodbye!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











