






今天在做一个数据查询时遇到一个问题,就是在两张表有关联字段,但是数据并非完全关联,现在需要查出不同的数据,开始还想着用!=去写入sql中,,,脑子秀逗了。后来使用not exists解决的问题,确实有些这种方法(我就姑且叫方法了或语法?)少用到,但是真的很容易解决问题,为了写这文章记录一下,我就新建表a,表b说明一下好了,小白阶段需要积累...
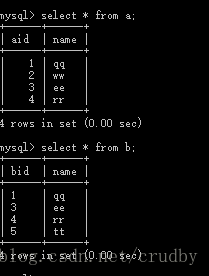
在表a和表b中有三条记录相同,,(我只是想说关联id相同,其他的无所谓)
在查询a与b关联的数据时
select a.* from a, b,where a.aid=b.bid;
在需要查询a中在b没有关联的数据时,则使用到not exists了
select * from a where not exists (select * from b where a.aid=b.bid);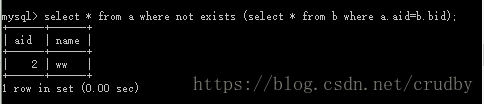
同样,在b中查未被a关联的反过来即可,这个就是将主查询中的数据在子查询中做一个条件判断,再在主查询中查出exists 或not exists 的数据。
其实查找关联数据还有使用exists的写法,就是把上面的not去掉即可(像不像高数里的集合??)
发现很多东西容易忘记,好记性不如烂笔头。。做个小记录
好吧,,突然想起来in好像有同样的功能
试了一下
select * from a where a.aid not in (select bid from b where a.aid=b.bid);结果:

。。。。。有点傻兮兮了,那么就来看两种方式有什么不同呢?
查看的网上一些大牛的博客资料:
https://www.cnblogs.com/liyasong/p/sql_in_exists.html
https://www.cnblogs.com/clarke157/p/7912871.html
其中都总结的很清楚,具体内容请点击上述连接观看。我借取其中一部分(听过一种小表驱动大表的思想):
区别及应用场景
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。

















 7284
7284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









