




 Ceph中的数据同步通过recovery和backfill进行,两者在OSD之间同步PG数据。recovery用于OSD启动时,当pglog中的更新少于设定值时。backfill则在其他情况下使用。peering是OSD比较状态的过程,会阻止数据访问。异步恢复的引入旨在减少recovery对IO的影响。可以通过调整参数强制backfill并使用nobackfill/norecover标志避免同步操作。
Ceph中的数据同步通过recovery和backfill进行,两者在OSD之间同步PG数据。recovery用于OSD启动时,当pglog中的更新少于设定值时。backfill则在其他情况下使用。peering是OSD比较状态的过程,会阻止数据访问。异步恢复的引入旨在减少recovery对IO的影响。可以通过调整参数强制backfill并使用nobackfill/norecover标志避免同步操作。
在 Ceph 中,有两种方法可以在集群内的 OSD 之间同步数据,recovery和backfill。虽然这两种方法都实现了相同的最终目标,但在这两个过程中存在细微差别,如下所述。
什么时候使用 Recovery 而不是 Backfill?
- Ceph OSD 进程为每个归置组 (PG) 维护一个名为 的日志pglog,其中包含该 PG 中最近 3,000 到 10,000 次更改的详细信息。
- 与 Ceph 中的大多数东西一样,日志条目的数量可以使用osd_min_pg_log_entries和osd_max_pg_log_entries参数进行调整。
- entry 是 PG不存在时要保留的max条目数。 active+clean
- entry 是 PG时要保留的min条目数。 active+clean
- 如果:
OSD 已关闭但现在已启动
pglog并且该 OSD 上的给定 PG 发生的可用更新少于 - 然后:
recovery用于那个PG。 - 除非:
backfill用于那个PG。
有什么区别?
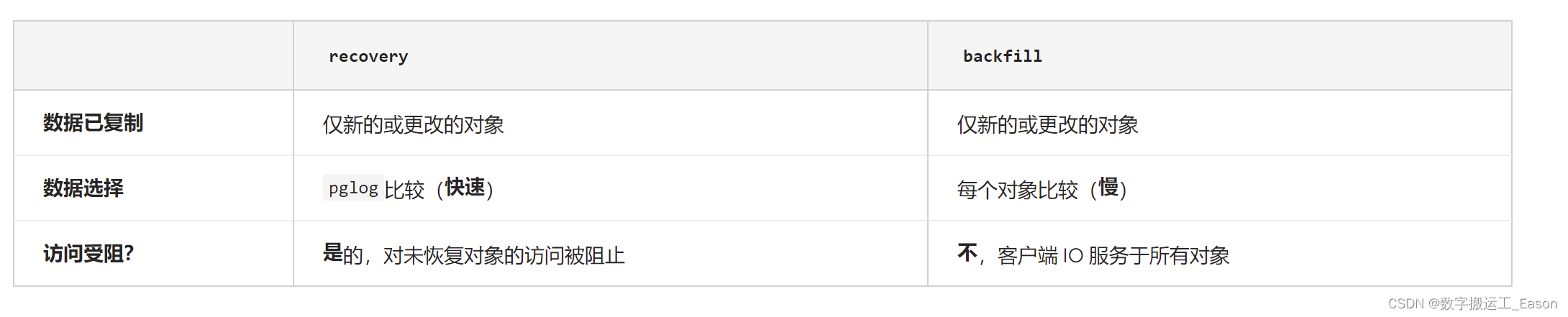
为什么访问在期间被阻止recovery,而不是在期间backfill?
- 这只是 Ceph 数据同步进程设计早期选择的一个历史怪癖。
- 正在努力改变这一点,这样recovery就不会阻塞对象 IO(异步恢复)。
- 有关异步恢复更改的详细信息,请参见:
最小化执行集中基于日志的恢复
在 Ceph 中实现异步恢复
我可以强制backfill而不是recovery这样我永远不会阻止客户端 IO 吗?
是的!
为此,您只需调整上面min提到的和maxlog 值。
#the number of entries to keep in the pg log when trimming it. Defaults to 3000.
osd_min_pg_log_entries = 1
# the max entries, say when degraded, before we trim. Defaults to 10000.
osd_max_pg_log_entries = 2
重要的!我们强烈建议在生产中实施之前在测试环境中测试这些选项,以便您了解它们在生产中的行为方式。
什么是peering?
- peering是 OSD 比较 PG 状态以确定 PG 的正确当前状态的过程。
- peering还记录了哪些 OSD 具有 PG 中各种对象的最新数据和元数据。
- peering当一个 OSD 启动(一个新的 OSD,或者之前关闭的 OSD)或关闭时发生。
- 整个 PG 的数据访问peering在进行 时被阻止
- 这可以防止客户端 IO 请求的更改使peering进程无效。
- peering完成后,PG 将进入或backfill_wait状态recovery_wait。
- PG 应该从waitstate 移动到
backfillingor recoveringas slots for these operations become available on the target OSD.
注意:状态一致并不代表它们都是最新的内容。这是什么backfill和recovery成就。
在某些情况下,我们已经看到对等互连需要相当多的时间。
设置recovery_deletes标志可以peering缩短时间。
这些过程能否导致slow request日志条目?
- 如果您ceph.log在 Ceph MON 节点上监控或查看,您可能会看到slow request条目。
- “慢速请求”行的末尾将指示哪种类型的操作是该请求的阻碍。
- Typewaiting on peering表示当 PG 正在对等时 IO 被阻塞。
- Typewaiting on degraded objects表示 IO 被阻塞到那些正在等待或处于活动状态的对象recovery。
可以预防backfill或recovery避免发生吗?
可以,
为此,我们有nobackfill和norecover标志。
ceph osd set nobackfill
ceph osd set norecover
当你的进化完成并且你想重新启用backfillandrecovery时,你可以unset使用标志。
ceph osd unset nobackfill
ceph osd unset norecover
norebalance flag呢?
- 这个标志比nobackfillor更具选择性norecover。
- 具体来说,只要 PG 是 only ,这个标志就会阻止数据移动remapped,但不是degraded
remapped和degraded有什么区别?
- remappedPG 状态表示 PG 在非最佳位置至少有 1 个数据副本。
- degradedPG 状态表示 PG 至少丢失了 1 个数据副本。
请珍惜劳动成果,支持原创,欢迎点赞或者关注收藏,你每一次的点赞和收藏都是作者的动力,内容如有问题请私信随时联系作者,谢谢!




















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











