




 本文详细介绍了Java集合框架中的重要组成部分,包括Collection接口及其特点,如查询、修改和批量操作;Map接口中的HashMap,解释了哈希映射的概念和其无序性、key可为null的特性;ArrayList和LinkedList的区别,强调了它们在增删查上的性能差异;最后详细阐述了HashMap的存储结构、冲突解决以及树化、链化机制。通过对这些基础概念的深入理解,有助于提升Java开发中的数据存储和处理能力。
本文详细介绍了Java集合框架中的重要组成部分,包括Collection接口及其特点,如查询、修改和批量操作;Map接口中的HashMap,解释了哈希映射的概念和其无序性、key可为null的特性;ArrayList和LinkedList的区别,强调了它们在增删查上的性能差异;最后详细阐述了HashMap的存储结构、冲突解决以及树化、链化机制。通过对这些基础概念的深入理解,有助于提升Java开发中的数据存储和处理能力。
目录标题
- 集合
- 什么是集合
- Map
- Collection集合
- Collection中的方法分类
- add和addAll方法
- 练习一
- 讲解 修改操作中 boolean add(E e) 重点 boolean add(E e) 数据类型和集合类型一样
- 一般来说,super() 的含义可有以下四个理解: 1.子类的构造过程中必须调用父类的构造方法 2.子类可在自己的构造方法中使用super()来调用父类的有参构造方法 (而此刻显示调用super(name)就是调用父类的有参构造方法) 3.如果子类的构造方法中没有显示的调用父类的构造方法,则系统默认的调用父类的无参的构造方法。 4.如果子类的构造方法中既没有显示调用父类的构造方法,而父类中又没有无参的构造方法,则编译出错。 public Banana(String name) { //(而此刻显示调用super(name)就是调用父类的有参构造方法) super(name); }
- 练习二
- 讲解 批量操作中 boolean addAll(Collection <? extends E> c)方法
- 总结
- 集合删除数据的方法
- 讲解boolean remove(Object o);
- 迭代器Iterator和Iterable
- collection集合选择了迭代器模式来访问数据的方法 迭代器是一个接口 有两个抽象方法 hasNext();用来判断 还有没有数据可供访问 next();方法 用来访问 集合的下一个数据
- 而集合List中的get()方法 依赖索引来获取数据 而集合Queue中的poll()方法 依赖队列规则来获取数据
- 而迭代器具有通用性 可以访问不同特性的集合数据 而不用关心它们的内部实现
- 迭代器的使用 跟游标卡尺使用差不多
- 重点!!! 注意点 集合不是直接去实现Itertor接口的 而是实现Iterable接口 是用这个Iterable定义的方法来返回当前集合的迭代器
- 从下图可以看出 Collection集合 就继承Iterable接口 则Collection体系中都要按照这种方式返回迭代器 以供大家访问数据
- 重点解释 为什么要通过这种方式 来使用迭代器 如果当集合直接实现迭代器的话 那如果别人调用当前集合的next()方法 那么就会影响到你遍历数据 因为你自己原本定义从头开始遍历所有数据的 但是别人已经将数据遍历完了 这样的话你本身就拿不到数据了
- 解决办法 通过实现Iterable接口方式 就可以每次返回新的迭代器 不同的迭代器 遍历数据互不影响 所以这里可以看出 迭代器具有独立性和隔离性
- 迭代器具有屏蔽集合间不同特性
- 还有一个好处: 如果你实现了Iterable接口 并且按照要求返回迭代器 那么就可以使用foreach循环 来直接遍历数据
- 理解foreach循环 foreach循环是一个Java的语法糖 反编译后就会发现 它本身用的就是迭代器
- 总结:
- 集合批量删除数据的方法
- removAll()方法
- 练习
- retainAll(Collection <?>)方法
- removeIf(Predicate <? super E> filter) 方法
- clear()方法
- 总结上面内容
- 学习ArrayLIst
- 介绍ArrayLIst
- Array 数组 List 列表 ArrayList 数组列表 所以可以看出 ArrayList 是一个基于数组的集合 ArrayList 内部就是用数组来存储数据的
- 而数组的特点就是 一 有序 : 元素存入集合的顺序和取出的顺序一致 二 可重复 :它里面可以存储重复的元素 三 可存null : 它里面可以存储 null元素
- ArrayList 的优点: 查询快 (只要知道索引 一瞬间就查到了) ArrayLIst是所有容器中 查询速度最快的一个 缺点 :增删慢 原因:因为数组存满后要扩容 而扩容的过程 是先 创建一个是原来容量1.5倍的数组 然后再把原来的元素拷贝到新数组中 这样导致添加元素的效率就大大的降低了 (所以 在增删过程中 ArrayList集合 数据越多 增删数据就慢 删除也是一样的)
- 什么是大小(size): 大小就是元素的个数 什么是容量(capacity): 就是数组的长度
- ArrayList的创建方式:
- ArrayList的常用方法
- Collection集合框架结构体系图
- Collection集合里面的所有方法
- List集合里面的所有方法
- 总结:
- LinkedList
- Collection集合框架结构体系图
- 介绍 LinkedList
- LInked 链式 list 列表 LinkedList 链式列表 简称列表
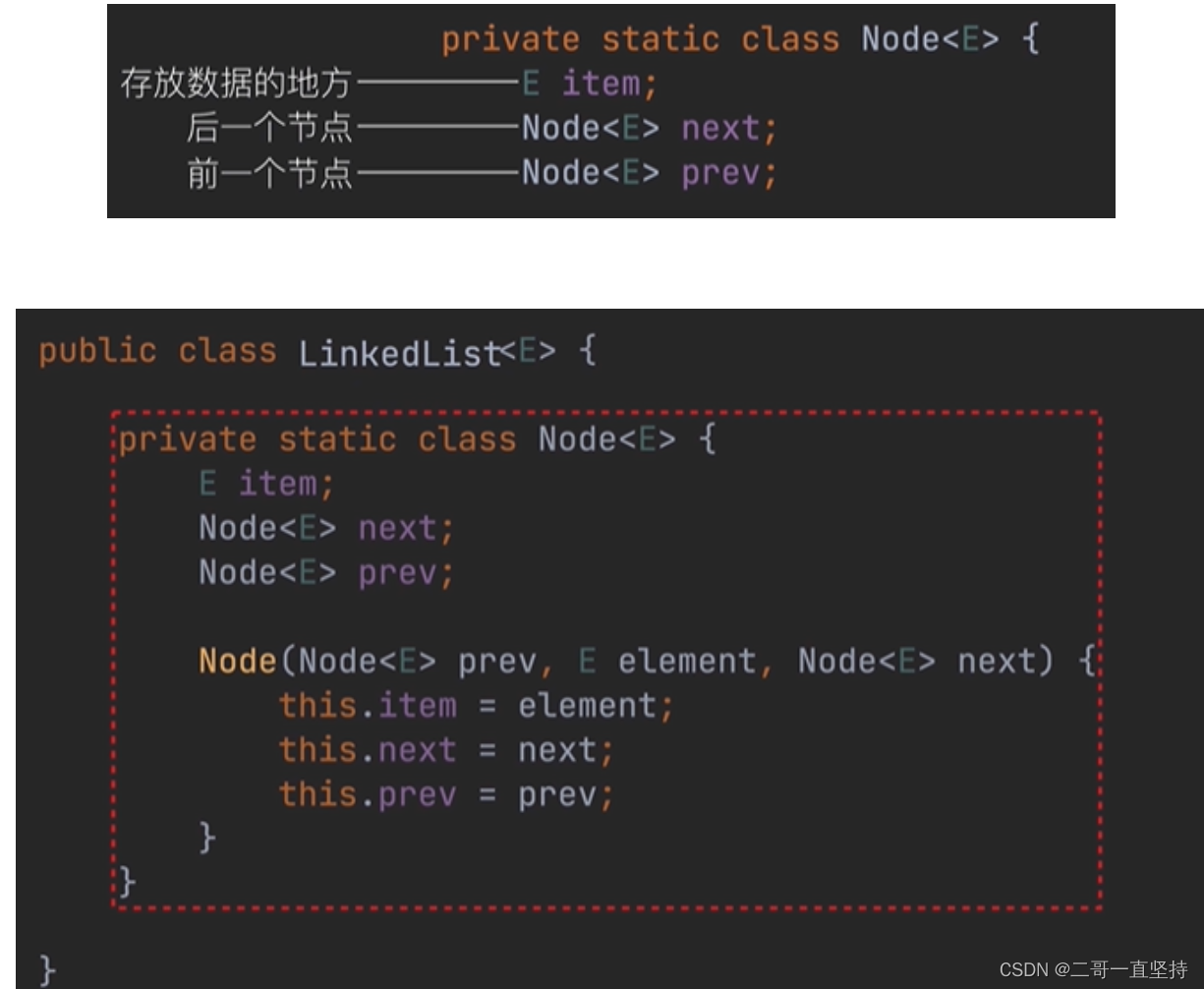
- 可以看出 它是基于链表实现的 而且还是双向的 Node< E > next; Node< E > prev; 所以LinkedList又称 双向链表
- E item:用来存放数据的地方 next用于记录前一个节点 prev(previous)属性用于记录前一个节点 这就是双向的意思 如果单向的话 就没有prev属性 只有next属性
- 练习
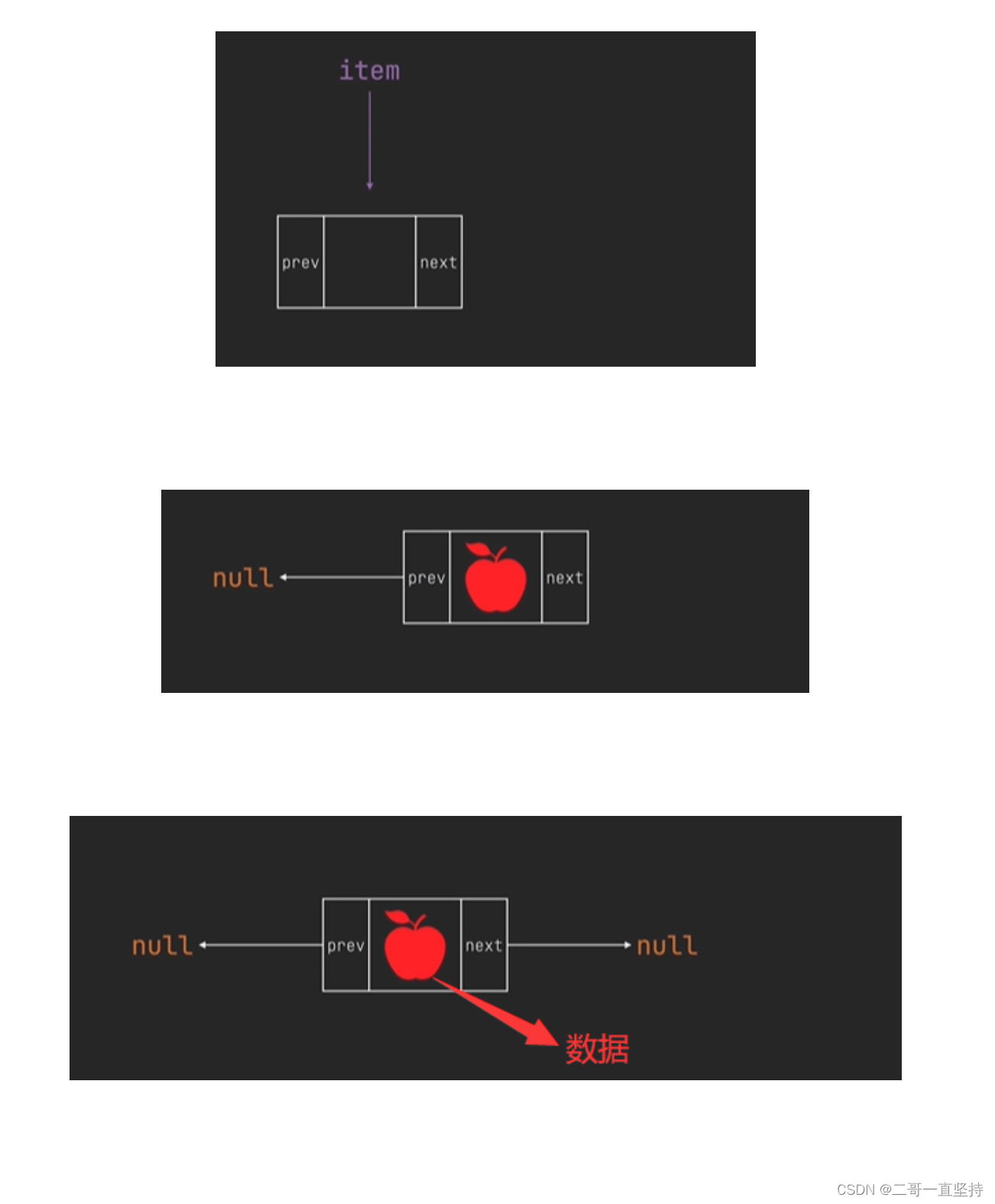
- 下面演示一个节点 数据就放在item中 此时prev属性的值为null 说明它前面没有节点 next属性的值也为null 说明它后面也没有节点
- 在LinkedList集合中 用first属性来记录第一个元素 first 为头节点 而 last属性来记录最后一个元素 为尾节点
- 当只有一个元素时
- 当有三个元素时
- LInkedList集合默认是从尾部开始添加元素的 但是你也可以调用 addFirst方法 从头部开始添加元素
- LinkedList集合的特点
- LinkedList的三个特点 一: 有序 元素存入的顺序和取出的顺序一致 二 : 可重复 它里面可以存储重复的元素 三 : 可为null 它里面可以存储null元素
- 优点 : 一: 增删快 当增加元素时:只需记录前后的节点是谁 不需要像ArrayList那样 还要调整数组大小 当删除元素时:只需要调整前后节点的记录 效率非常的快
- 缺点: 一: 查询慢 即便是知道索引也要从头部或者是从尾部 开始一个接一个的查
- LinkedList的常用方法 LinkedList既实现了List接口 又实现了Deque接口 而Deque又继承Queue List和 Queue又继承 Collection 所以它拥有的方法特别的多
- LinkedList UML 类图(重点)
- 它拥有Collection里面的所有方法 List 里面的所有方法 Queue里面的所有方法 也有Deque里面的所有方法 但是在这些方法里 它只有九个方法是常用的 这九个方法中缺少删除数据的方法、
- Collection方法分类 List方法分类 Queue方法分类 Deque方法分类 LinkedList 常用方法分类
- LinkedList删除数据
- 在LinkedList删除数据 —般是找到匹配项以后 使用迭代器的remove方法 进行删除
- LinkedList 与 ArrayList 的区别
- 它俩的区别主要来自于数据结构的不同 ArrayList是基于数组实现的 LinkedList是基于链表实现的
- 因为数组是基于索引 (index)的数据结构 所以它查询数据的速度是很快的 相对于ArrayList LinkedList查询数据的速度是很慢的 因为需要在双向链表中 一个接一个地找
- 但是在增删数据中 LinkedList要比ArrayList快得多 因为它不需要频繁地调整数组大小 只需要记录前一个元素 和后一个元素是谁 就可以了 正是因为这样 LinkedList需要更多的内存 而ArrayList 不需要花费额外的内存 来记录前后都是谁
- 所以综上所述 ArrayList多用于查询较多的应用场景 而LinkedList多用于增删较多的应用场景
- 总结:
- HashMap
- 什么是HashMap
- Map集合框架结构体系图
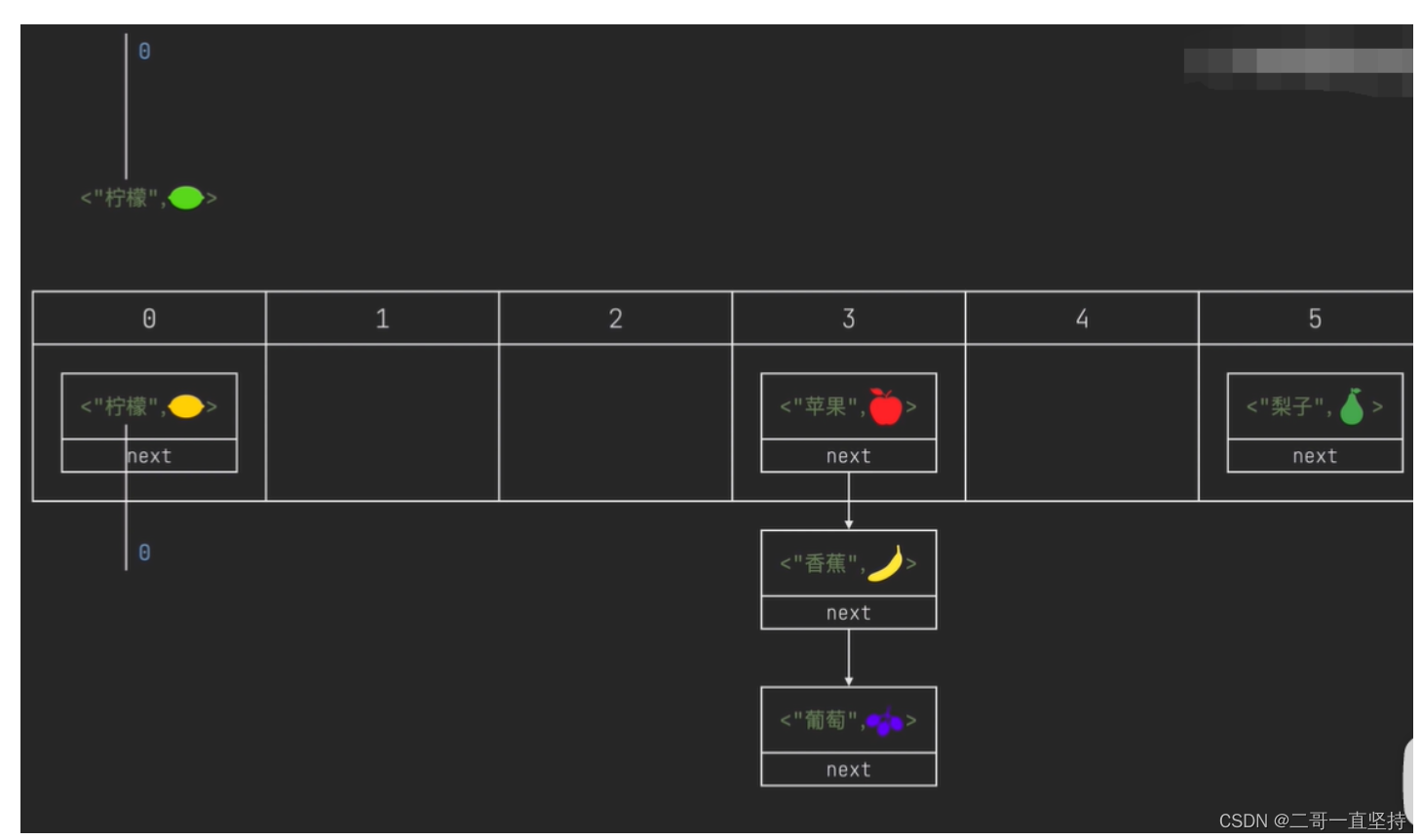
- 所以可以看出 它是以key-value(键值对)形式存储数据的 而且这些数据保存在数组中 默认的初始容量为16
- 数组的特点是有序 但 HashMap里面的元素 并不是按顺序存放的 而是先根据key计算出 元素的哈希值 再&(与上)(数组容量-1)
- 这个操作等同于 与数组容量取余 得到的余数 就是元素的位置
- 如此以来 势必会有多个元素 被分配到同一个位置上 那该怎么办呢
- HashMap 用链表将这些元素 单向的连接起来 这样解决了多个元素位置冲突的问题
- 但是这样存了以后 该怎么取呢 取出的顺序:先从数组下标0开始 再从链表头节点开始 重点!!! 所以 依次是 柠檬 苹果香蕉 葡萄 梨子
- 练习
- 重点!!! 程序验证 是不是这个顺序取出的
- 总结HashMap集合的特点
- 总结HashMap集合的特点 重点: 第一 无序: 元素存入的顺序和取出的顺序不一致 同时 这也是它唯一的缺点
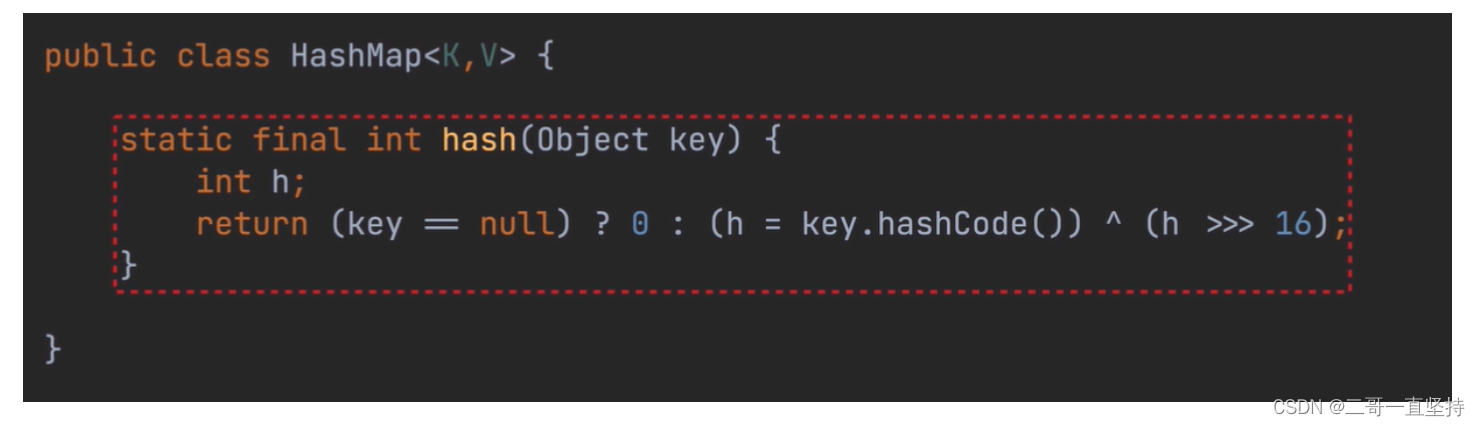
- HashMap的第二个特点: key可以为null 我们在计算元素哈希值的地方 发现了key 还可以为null 并且还给它分配了哈希值是 0 下面为三元运算符: /X ? y : z //如果x== true则结果为y否则结果为z 例如 :key==null 的时候结果为0
- 所以可以总结出 HashMap的第二个特点 key可以为null 并且哈希值为0
- HashMap的第三个特点 : key不可以重复 因为通过前面的知识 我们可以知道 key相同 哈希值就一定相同 位置也就相同 出现这种情况 新值会覆盖旧值
- 由此我们可以总结出: key不可以重复 重复的key 新值会覆盖旧值
- 什么是哈希冲突
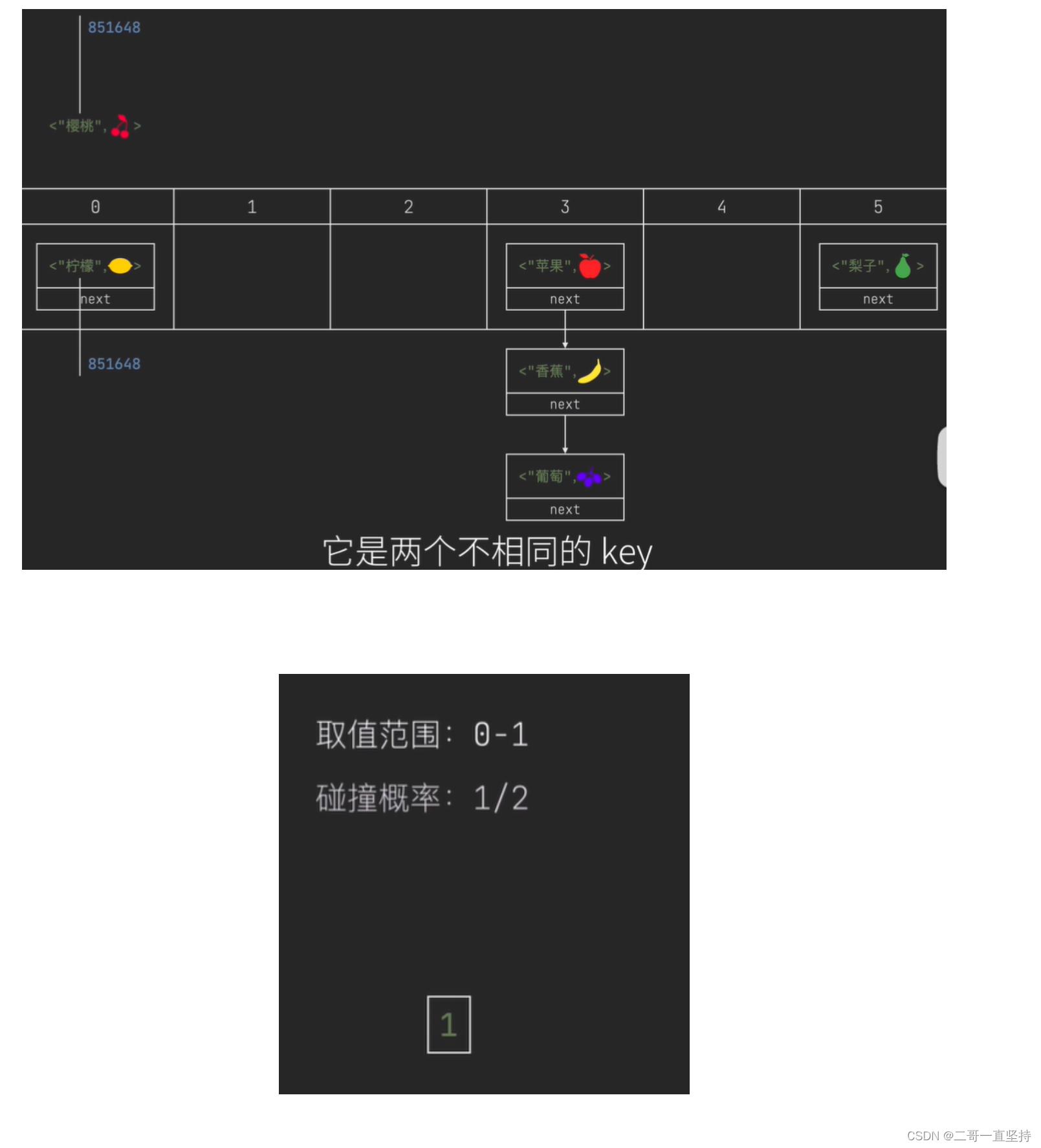
- 它是两个不相同的key 产生了相同的哈希值 我们把这种情况称之为 哈希冲突 也叫 哈希碰撞
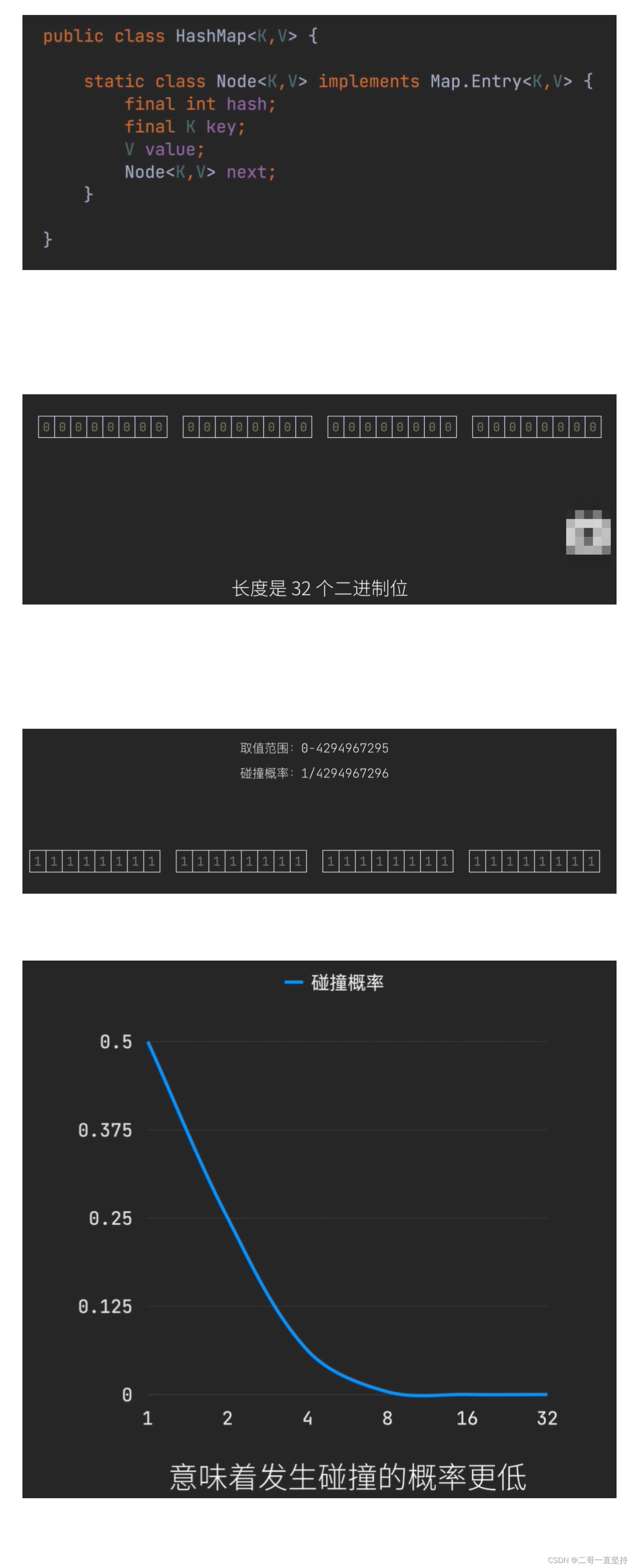
- 发生碰撞的本质 还是取值范围的问题 比如 一个二进制位 它的取值范围是0-1 若在它里面取哈希值的话 要么是0 要么是1 此时发生碰撞的概率是1/2 也就是说 如果有三个key时 就一定会发生碰撞
- 但是 如果我们将哈希值的长度 扩大到16个二进制位 那么它的取值范围就会越大 发生碰撞的概率就会越小
- 在HashMap中 哈希值是int类型 (final int hash;) 四个字节 长度是32个二进制位 碰撞的概率是1/4294967296
- 更长的哈希值 意味着发生碰撞的概率更低 但是也需要更大的储存空间 和更多的计算 我们需要在性能和成本之间做好权衡
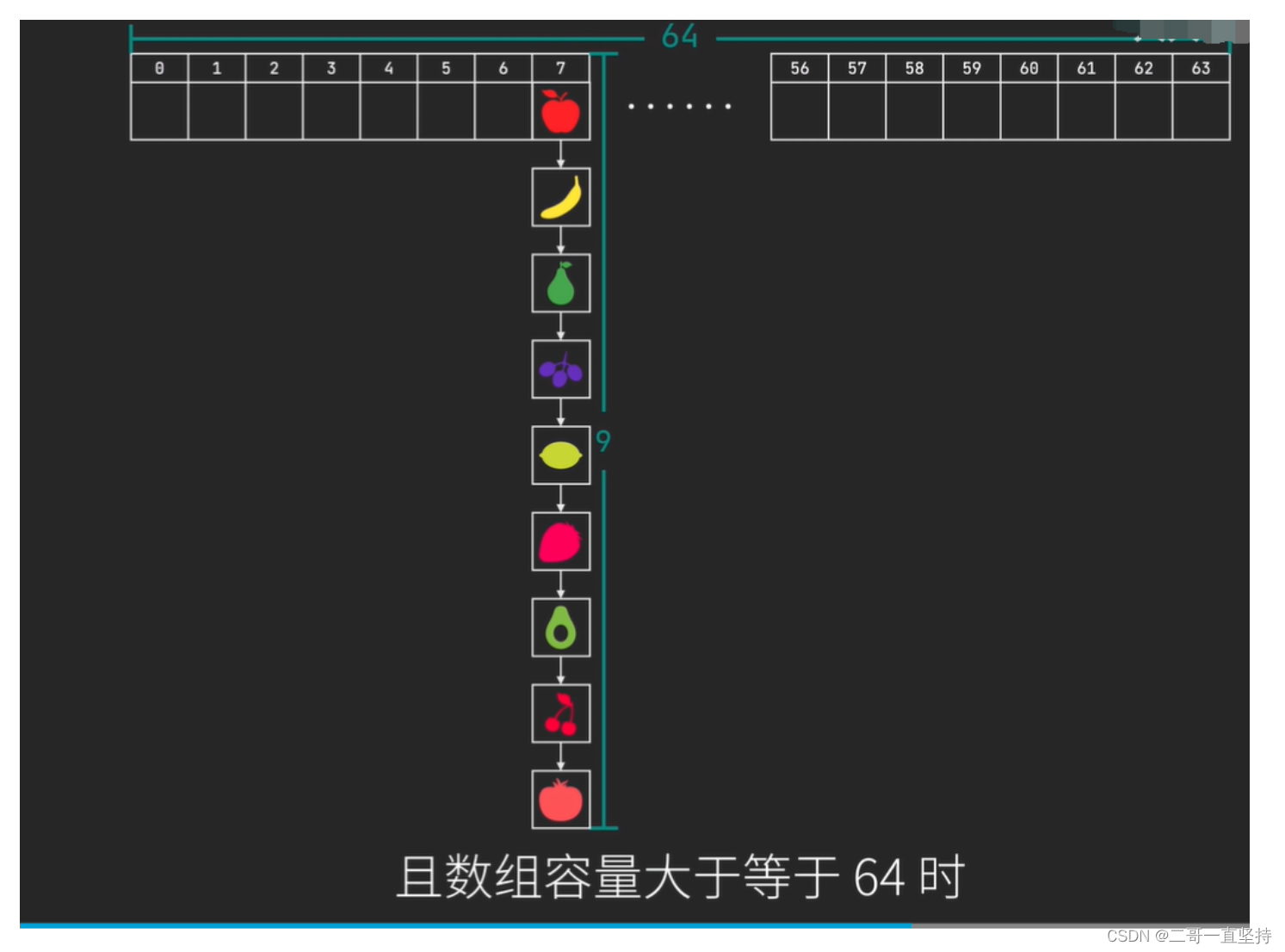
- HashMap的特点: 链化<==>树化
- 什么是链化 什么是树化 “树化”是当链表长度大于8 且数组容量大于等于64时 将链表转换为红黑树
- 红黑树是一种自平衡的二叉树 这样做的目的 是为了提高查询速度 因为链表一旦长了以后 查询就会变得很慢
- 另外 红黑树也会变回链表 当红黑树中的节点小于等于6时 红黑树将转换为链表 这个过程称之为"链化" 此时的节点数很少 链表与红黑树的查询速度不相上下
- 而且 在新增元素的时候 链表不用计算节点的位置 直接插在尾部 但红黑树还要计算节点的位置 因此 它们两个互相转换 可以形成很好的互补
- 注意点: HashMap在JDK1.8中 才引入的红黑树 以前采用的是数组+链表这种形式
- HashMap的特点:扩容
- 当元素个数超过临界值时 HashMap就需要扩容 临界值=容量 * 负载因子 扩容后的容量是之前的两倍 频繁扩容很影响HashMap 性能 所以 设置合适的初始容量与负载因子至关重要
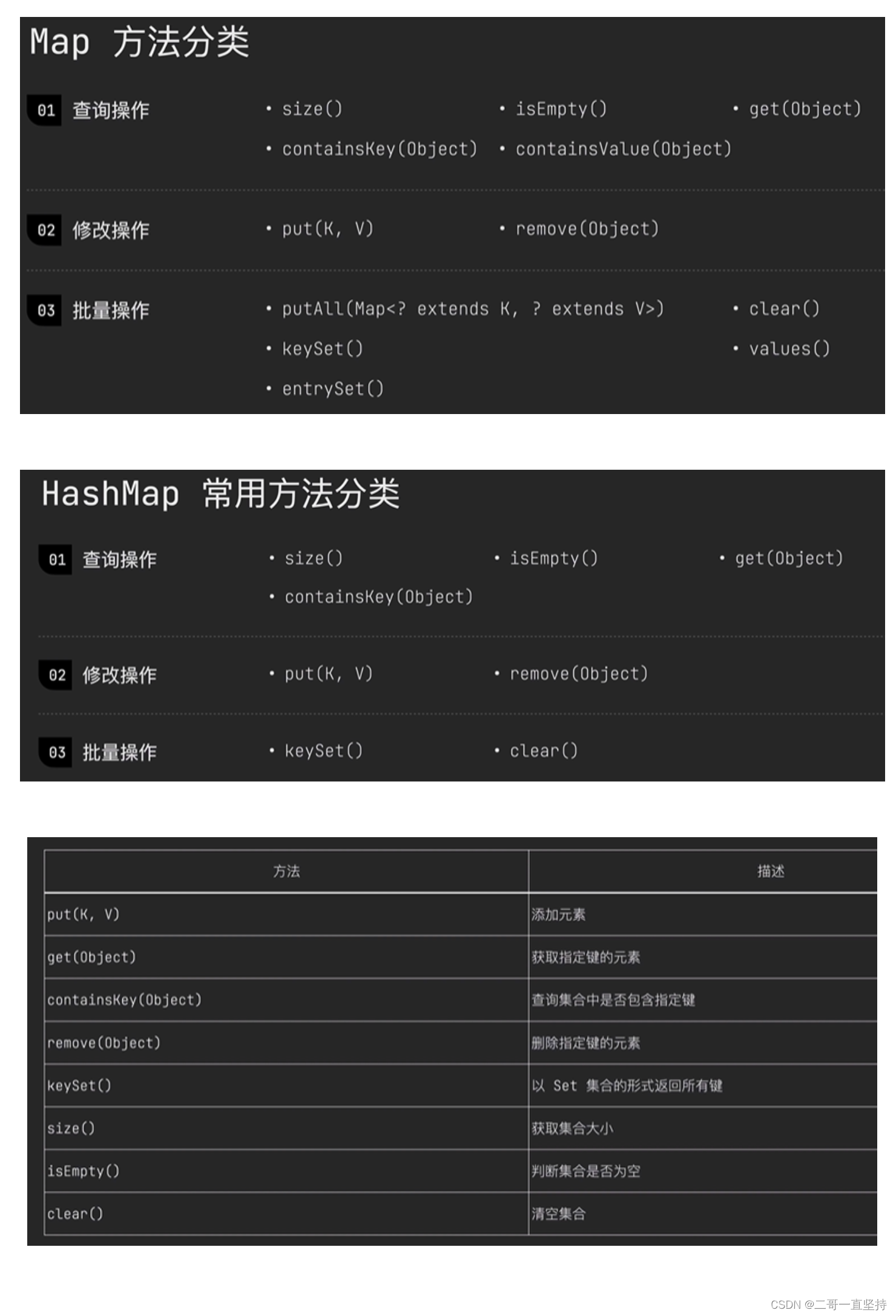
- HashMap的常用方法
- HashMap 实现了Map接口 拥有Map 里面的所有方法 但是在这些方法里面 它只是有8个方法是常用的 重点:! 其中 put和get方法用得最频繁
- Map方法分类和HashMap常用方法分类
- 总结HashMap集合
集合

什么是集合

集合和数组不同
不要将两者混洗
数组的特点:创建的时候要指定其长度 而且使用时 长度是不可改变的
所以当我们统计不可控制变量的数据的时候
这时候我们需要
使用集合Collection
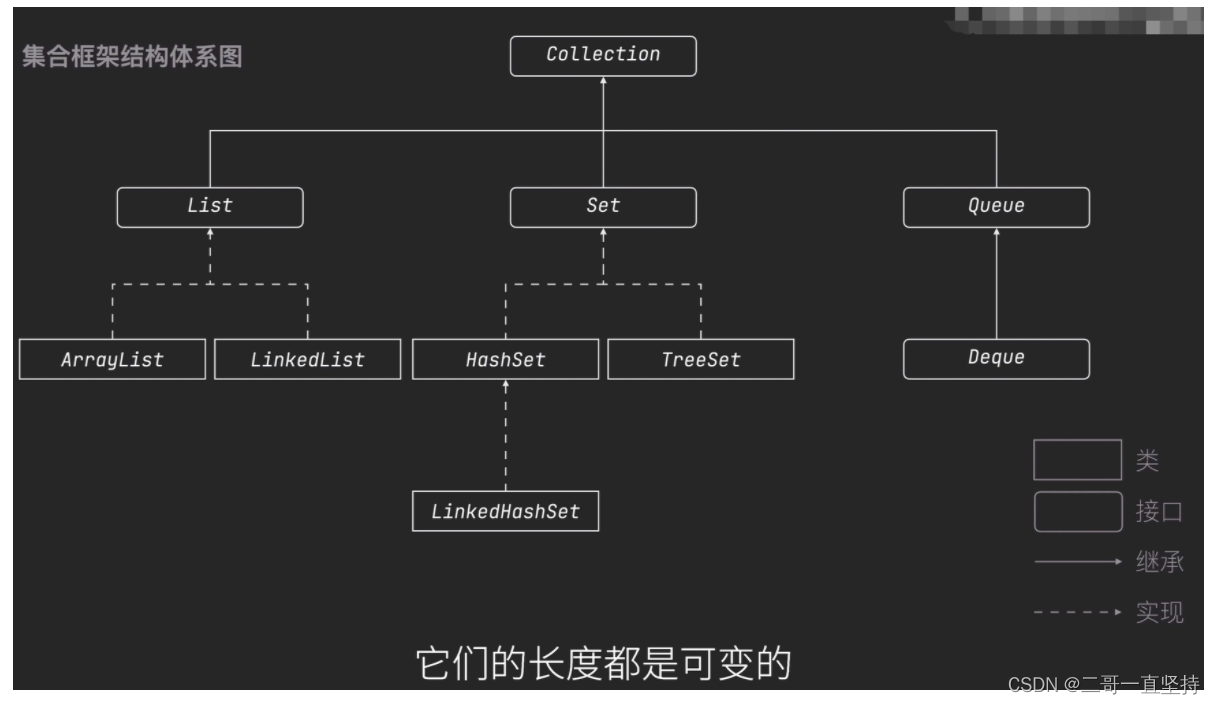
Map
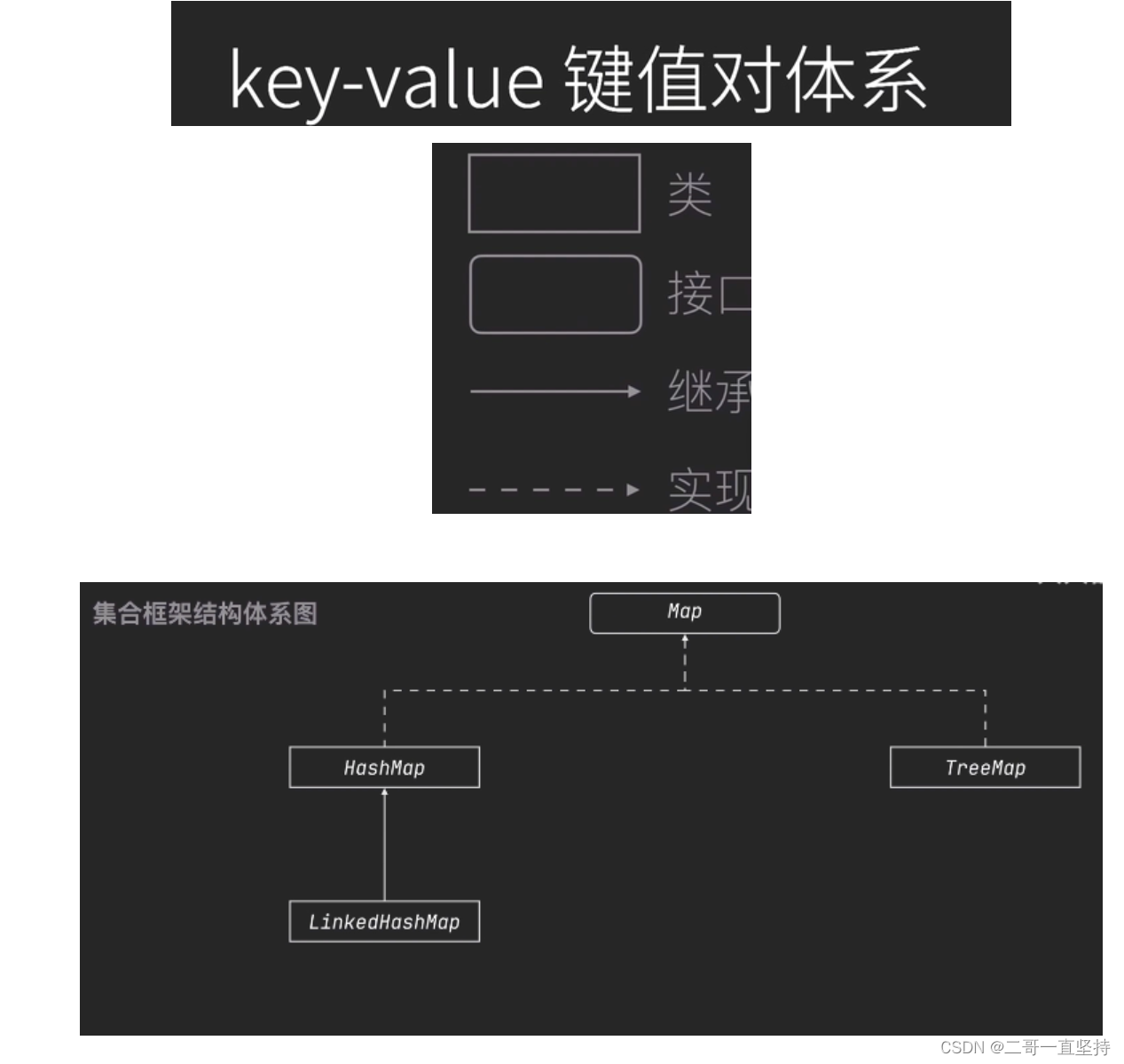
集合框架中第二个体系
Collection集合
一共有十七个公共方法!!!
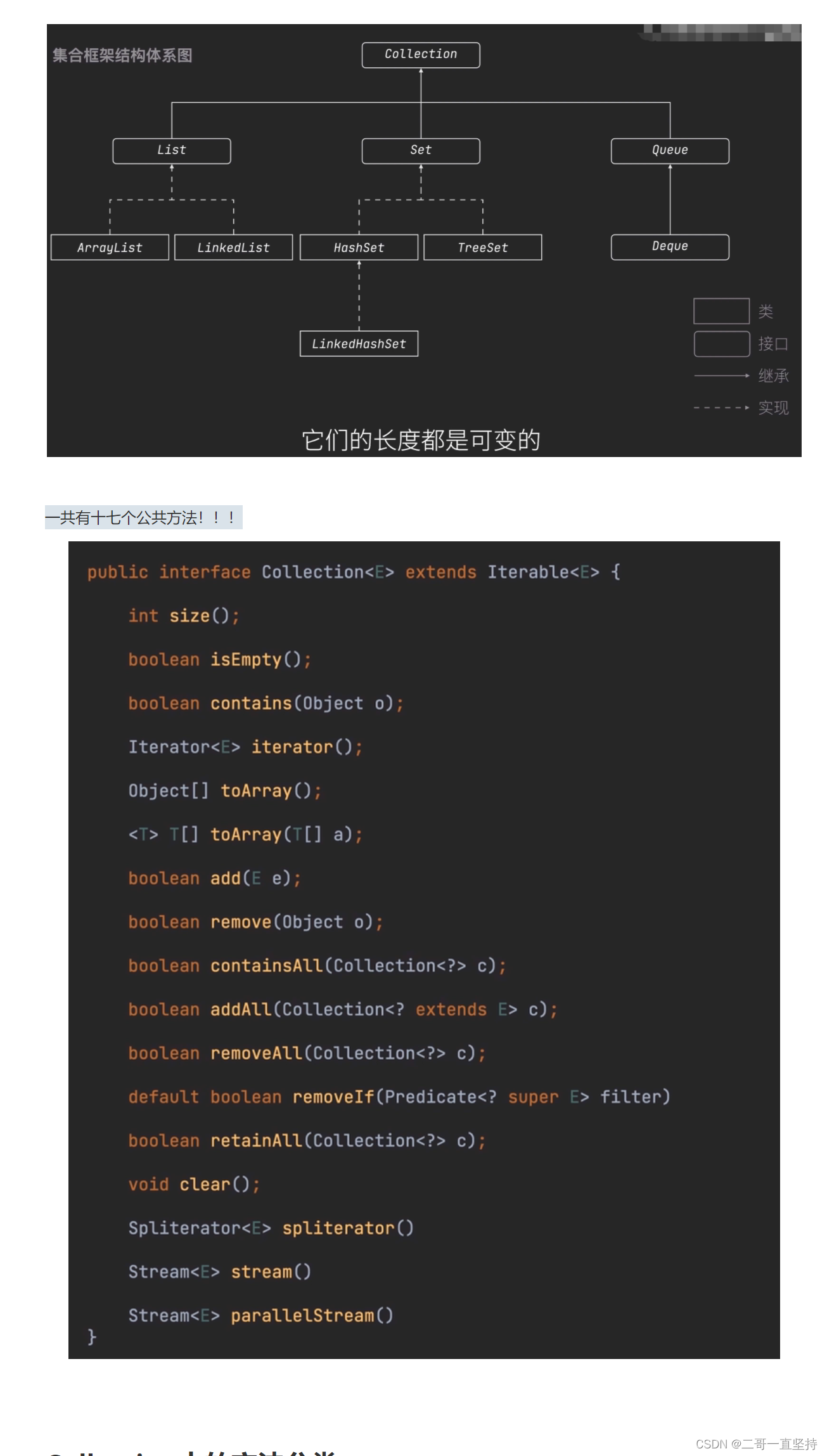
Collection中的方法分类
第一类 修改操作
add(E)添加数据
remove(Object)删除数据
第二类 查询操作
size()查询集合中有多少个数据
isEmpty()集合是否为空
contains(Object)集合中是否包含某个数据
第三类 批量操作
addAll(Collection <? extends E>) 添加批量数据 removeAll(Collection <?>) 删除批量数据
清空集合等等

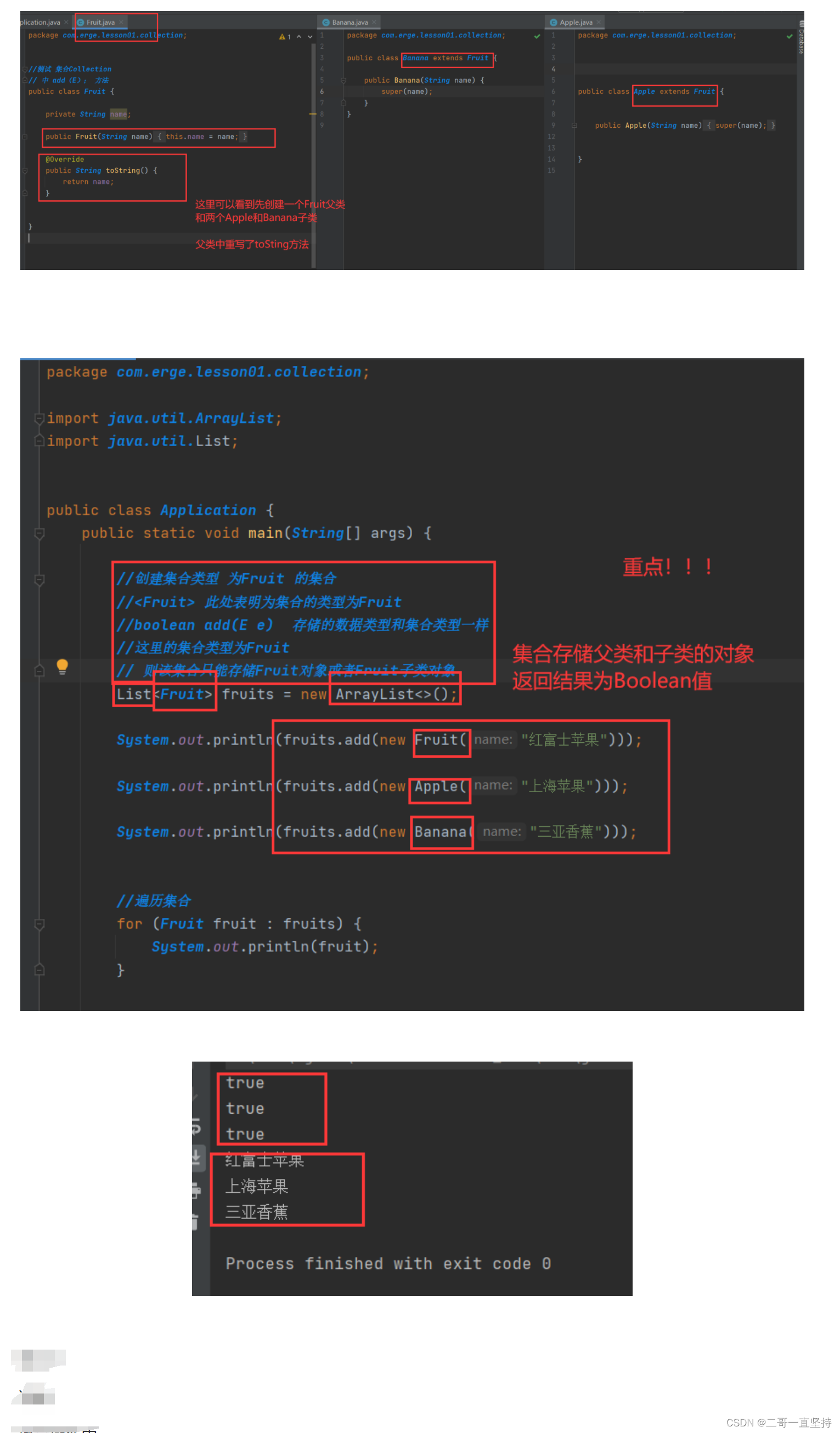
add和addAll方法
练习一
讲解
修改操作中 boolean add(E e)
重点
boolean add(E e)
数据类型和集合类型一样

一般来说,super() 的含义可有以下四个理解:
1.子类的构造过程中必须调用父类的构造方法
2.子类可在自己的构造方法中使用super()来调用父类的有参构造方法
(而此刻显示调用super(name)就是调用父类的有参构造方法)
3.如果子类的构造方法中没有显示的调用父类的构造方法,则系统默认的调用父类的无参的构造方法。
4.如果子类的构造方法中既没有显示调用父类的构造方法,而父类中又没有无参的构造方法,则编译出错。
public Banana(String name) {
//(而此刻显示调用super(name)就是调用父类的有参构造方法)
super(name);
}
练习二
讲解
批量操作中
boolean addAll(Collection <? extends E> c)方法
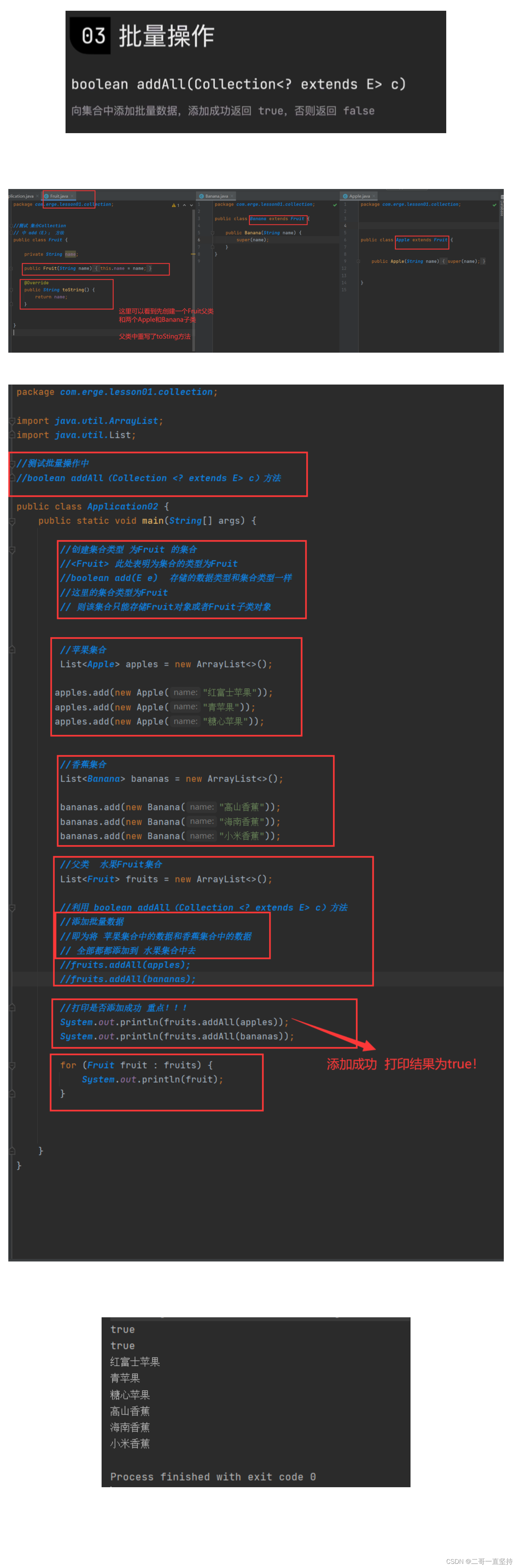
总结

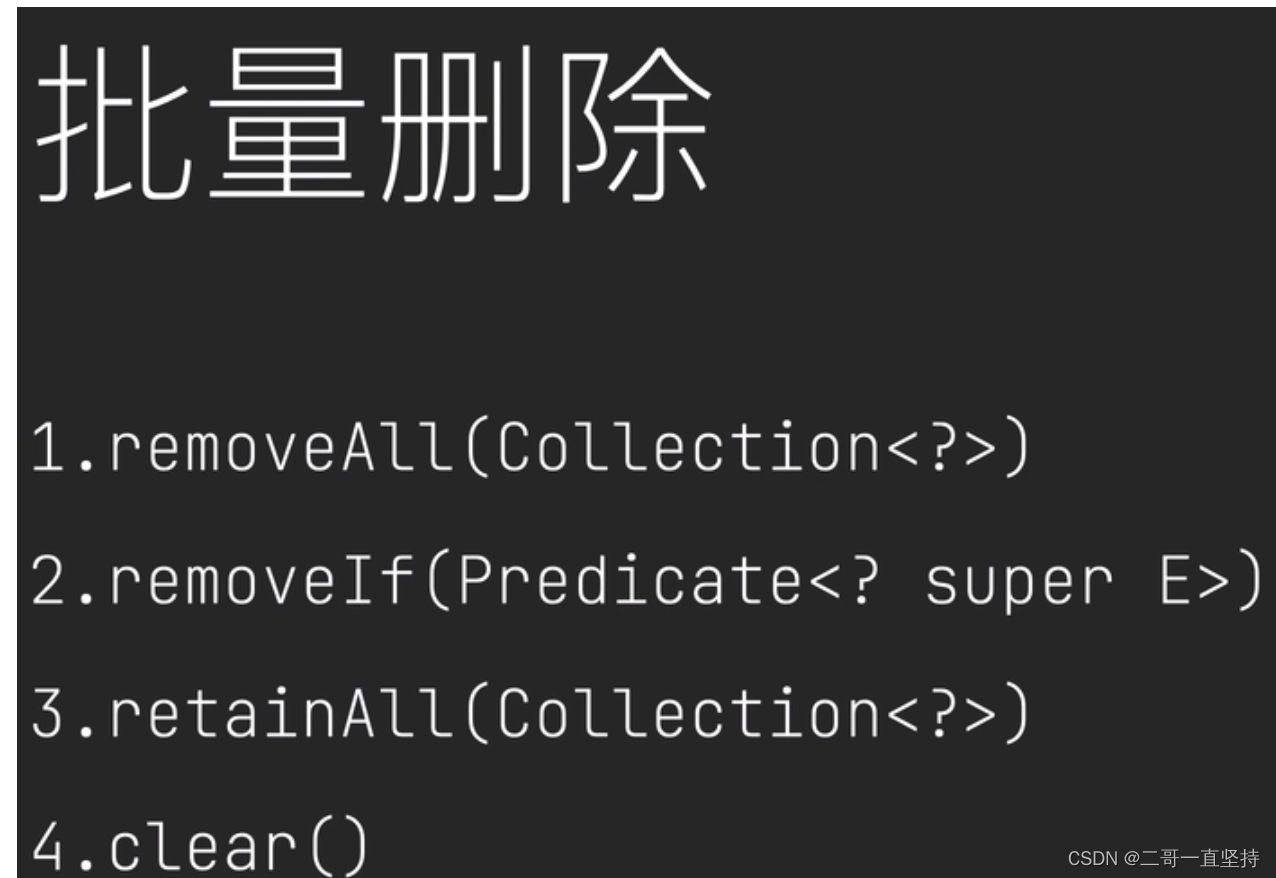
集合删除数据的方法
集合删除数据的方法一共有四种
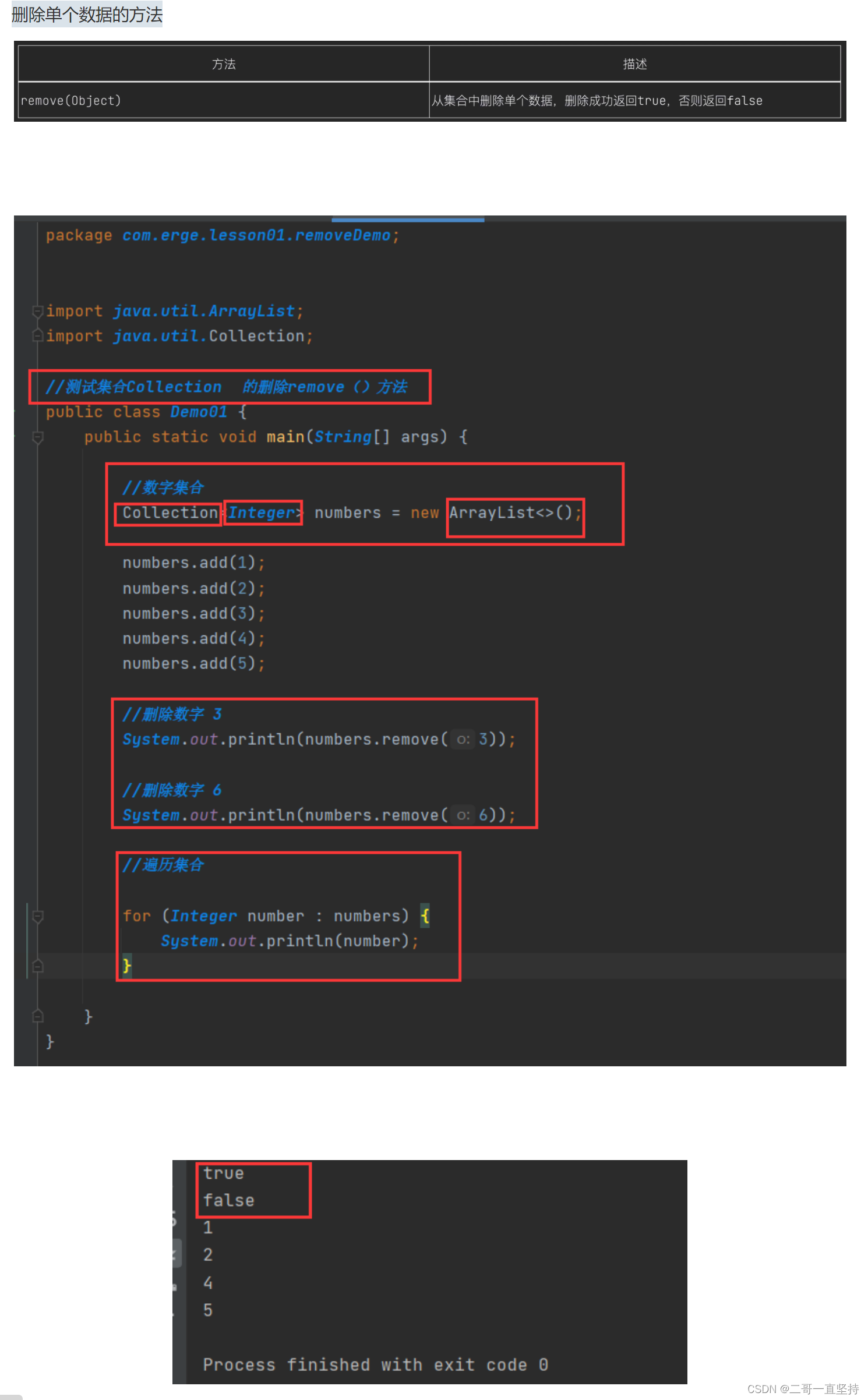
remove(Object);删除单个数据
删除批量数据 removeAll(Collection<?>)
删除符合条件的数据 removeIf(Predicate< ? super E >)
JDK 1.8 新加入的方法: 删除所有数据 直接清空集合 Clear();
讲解boolean remove(Object o);
删除单个数据的方法
数据如何删除的原理
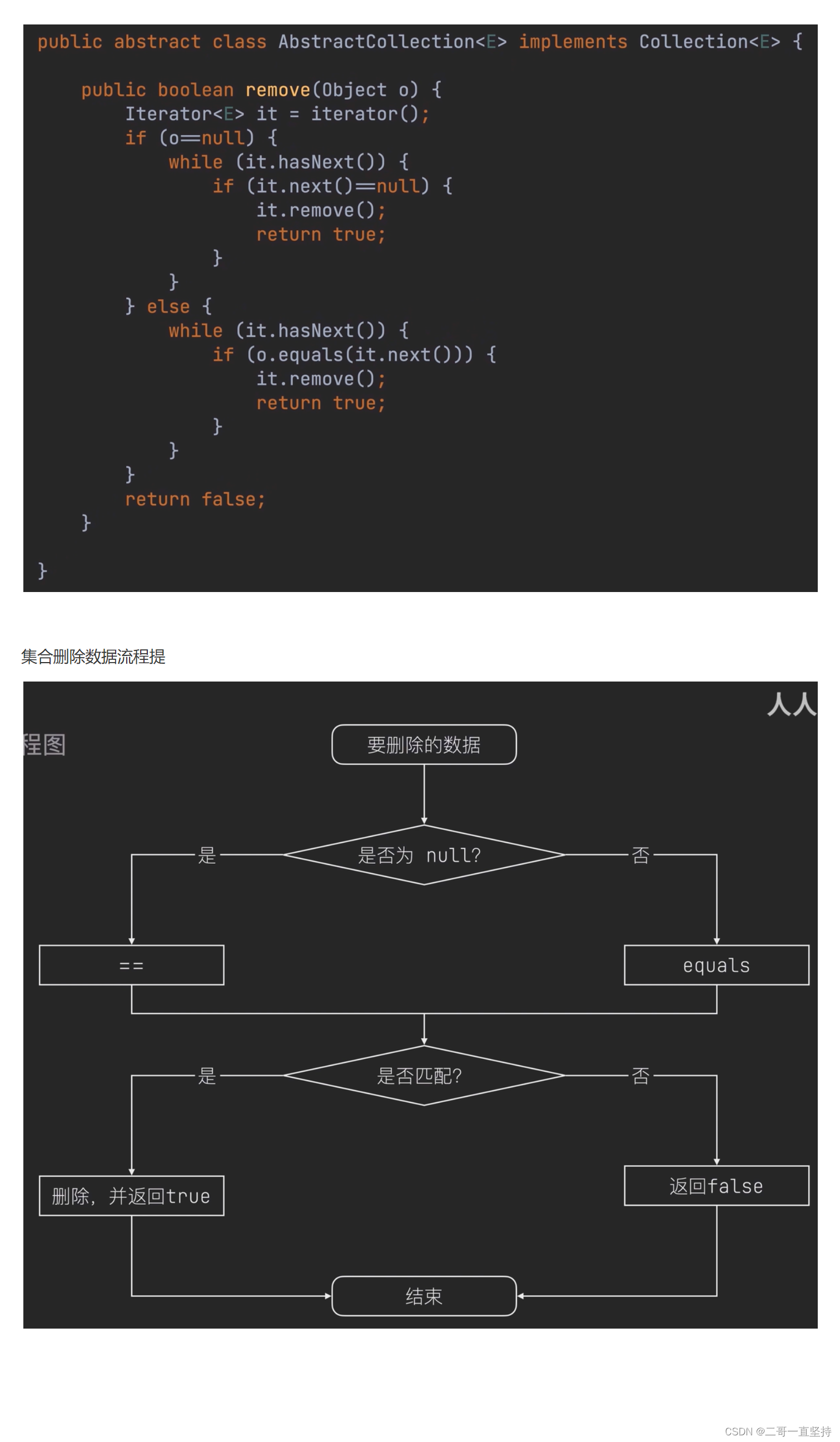
数据如何删除的原理
查看源码 remove()方法
数据通过迭代器来删除的
先判断删除的数据是否为null
第一种情况 如果数据为null是
使用“==”号 来匹配集合中是否存在null
第二种情况
利用equals来匹配删除的数据
集合删除数据流程图
迭代器Iterator和Iterable
collection集合选择了迭代器模式来访问数据的方法
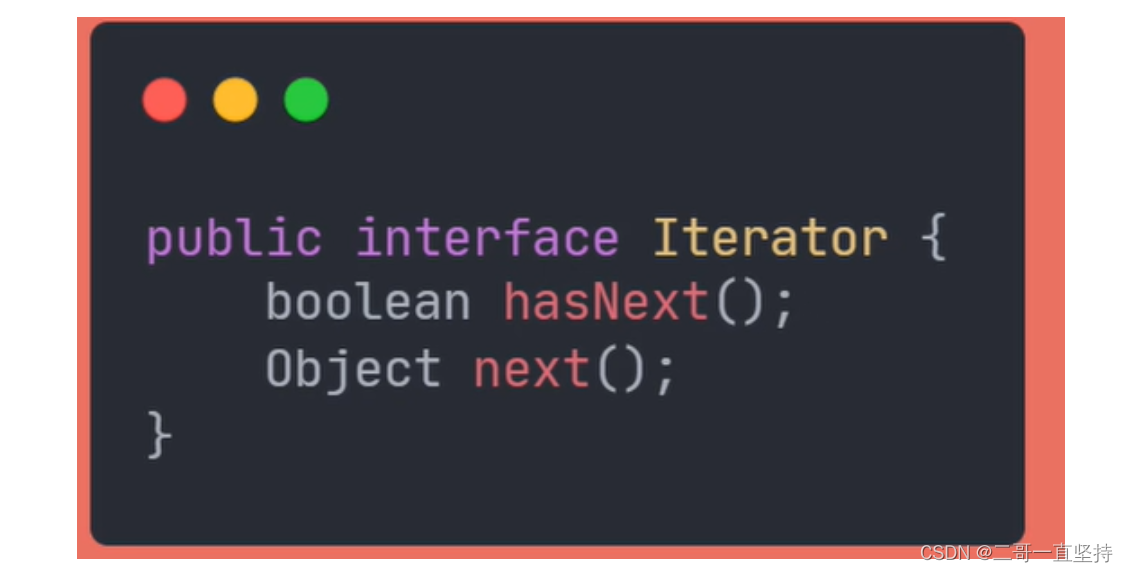
迭代器是一个接口
有两个抽象方法
hasNext();用来判断 还有没有数据可供访问
next();方法 用来访问 集合的下一个数据
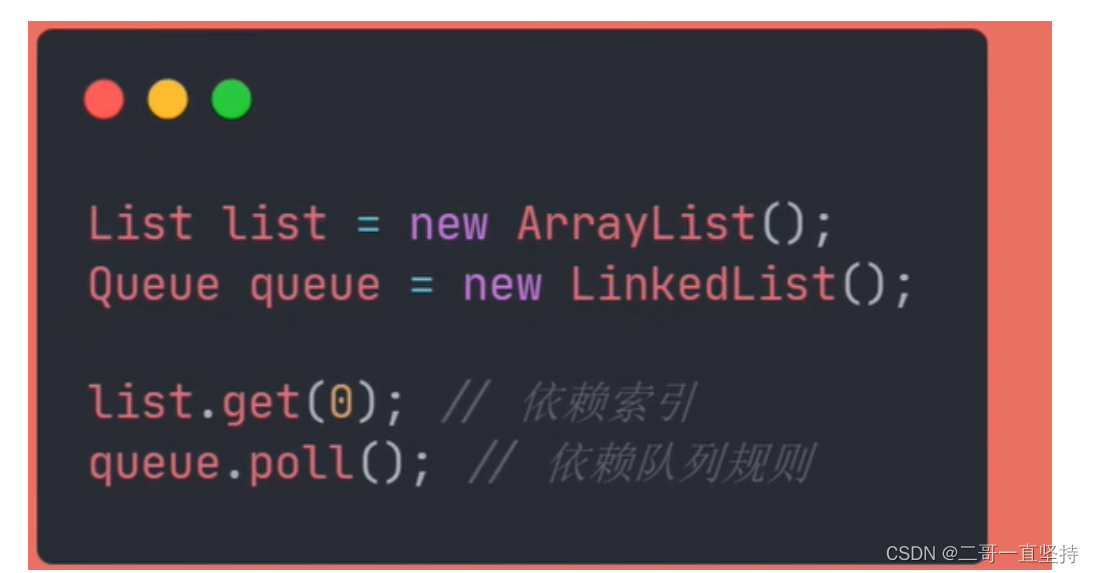
而集合List中的get()方法
依赖索引来获取数据
而集合Queue中的poll()方法
依赖队列规则来获取数据
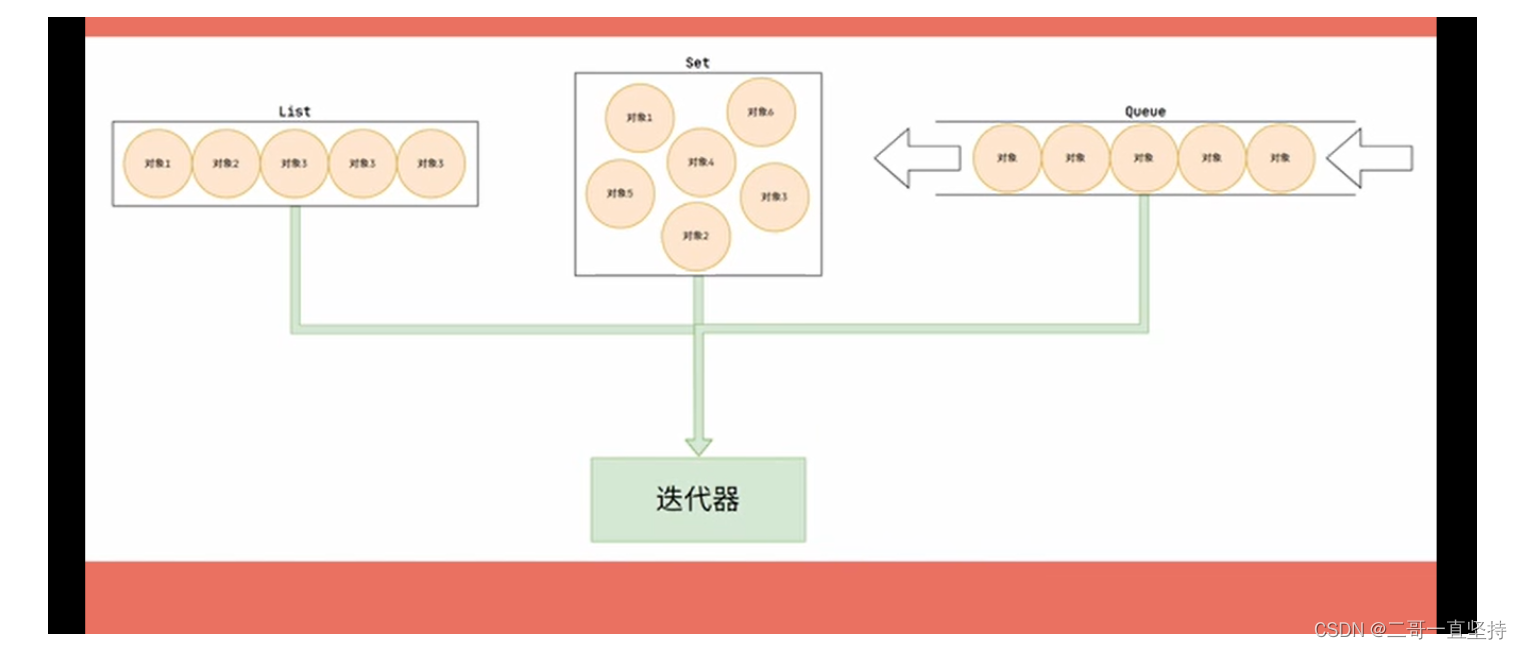
而迭代器具有通用性
可以访问不同特性的集合数据
而不用关心它们的内部实现
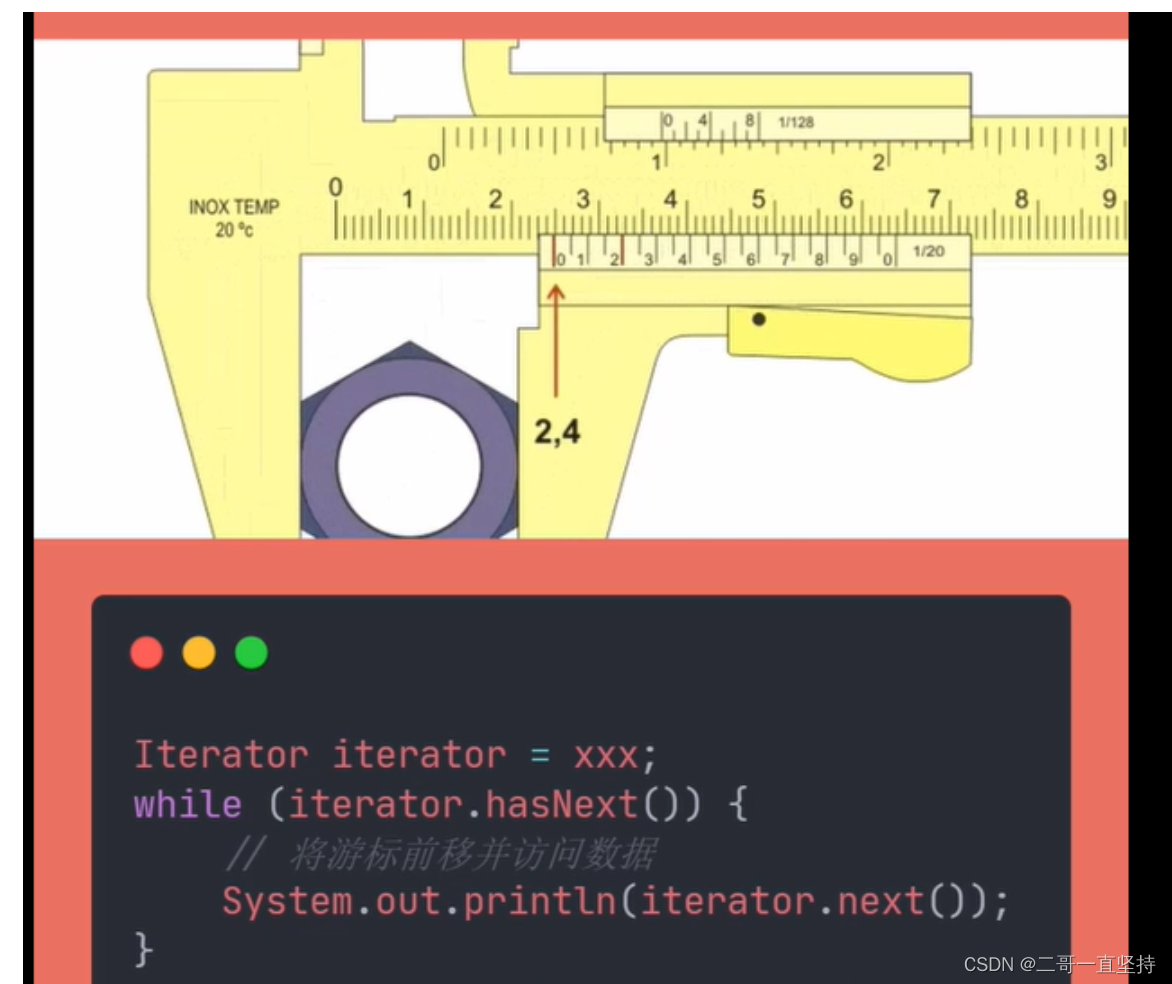
迭代器的使用
跟游标卡尺使用差不多
重点!!!
注意点
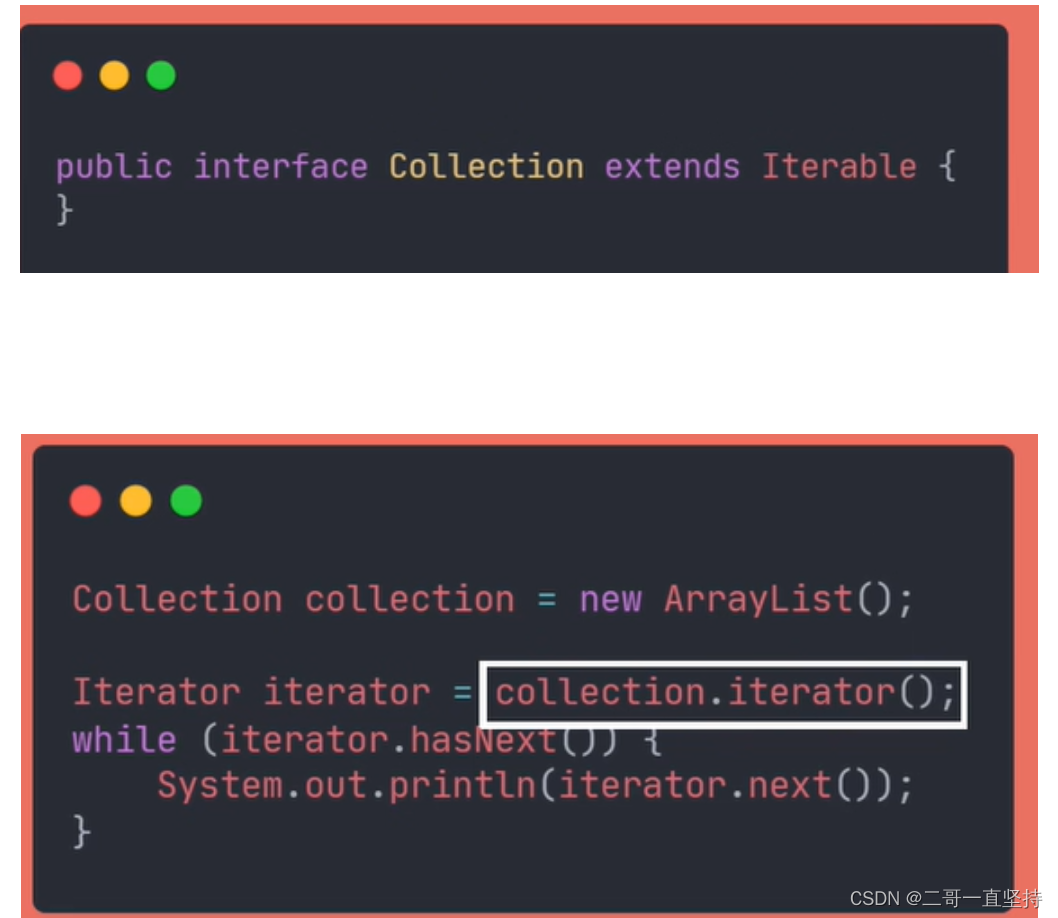
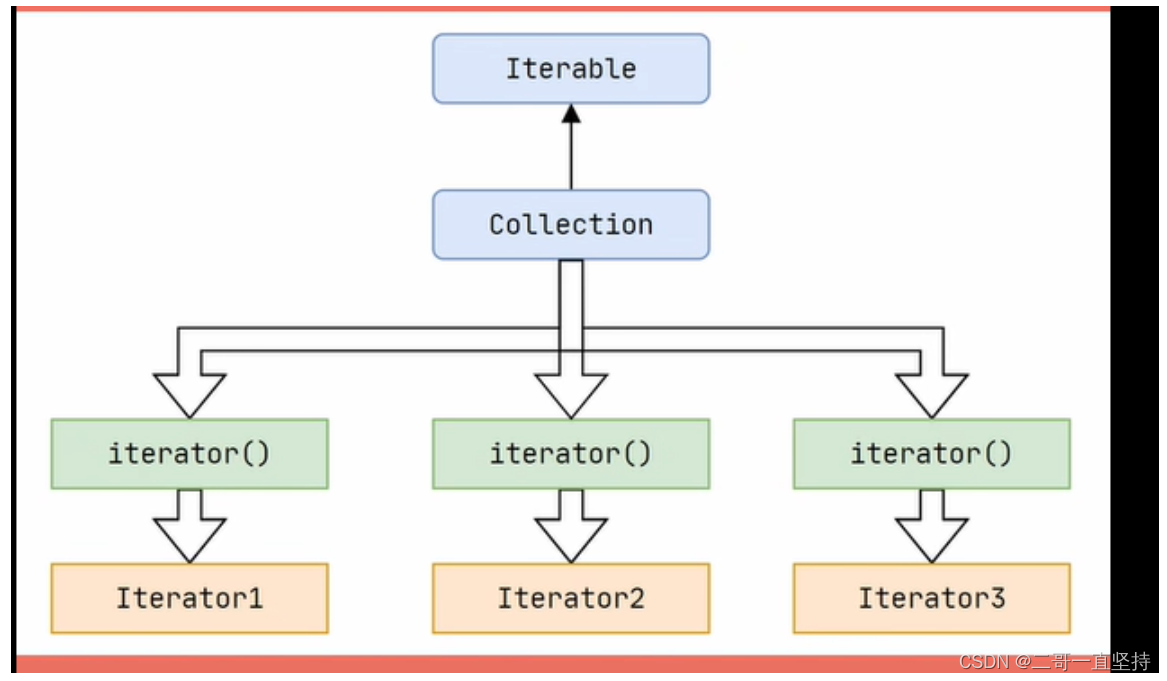
集合不是直接去实现Itertor接口的
而是实现Iterable接口
是用这个Iterable定义的方法来返回当前集合的迭代器

从下图可以看出 Collection集合 就继承Iterable接口
则Collection体系中都要按照这种方式返回迭代器 以供大家访问数据
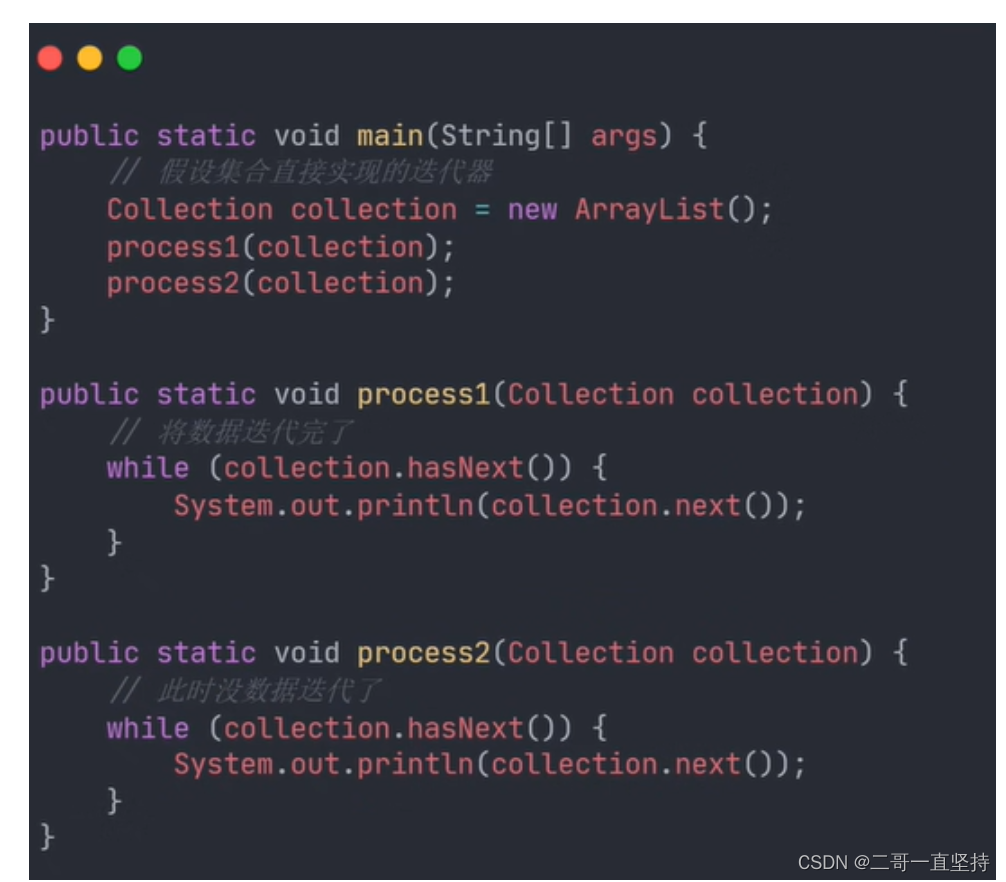
重点解释
为什么要通过这种方式 来使用迭代器
如果当集合直接实现迭代器的话
那如果别人调用当前集合的next()方法
那么就会影响到你遍历数据
因为你自己原本定义从头开始遍历所有数据的
但是别人已经将数据遍历完了 这样的话你本身就拿不到数据了
解决办法
通过实现Iterable接口方式
就可以每次返回新的迭代器
不同的迭代器 遍历数据互不影响
所以这里可以看出
迭代器具有独立性和隔离性
迭代器具有屏蔽集合间不同特性
还有一个好处:
如果你实现了Iterable接口
并且按照要求返回迭代器
那么就可以使用foreach循环
来直接遍历数据
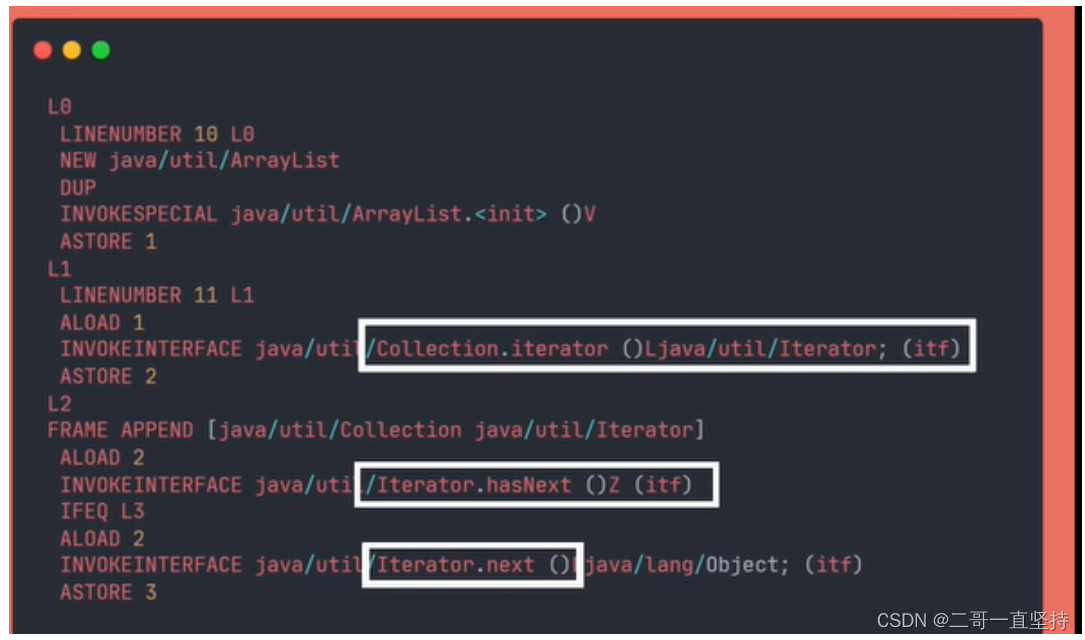
理解foreach循环
foreach循环是一个Java的语法糖
反编译后就会发现 它本身用的就是迭代器
总结:
iterable 用来返回迭代器
实现了该接口的类 算是可迭代对象了
可直接使用foreach循环来访问数据
Iterator 用来遍历集合的数据
不用关心集合的内部实现
foreach 循环本身用的就是迭代器
集合批量删除数据的方法
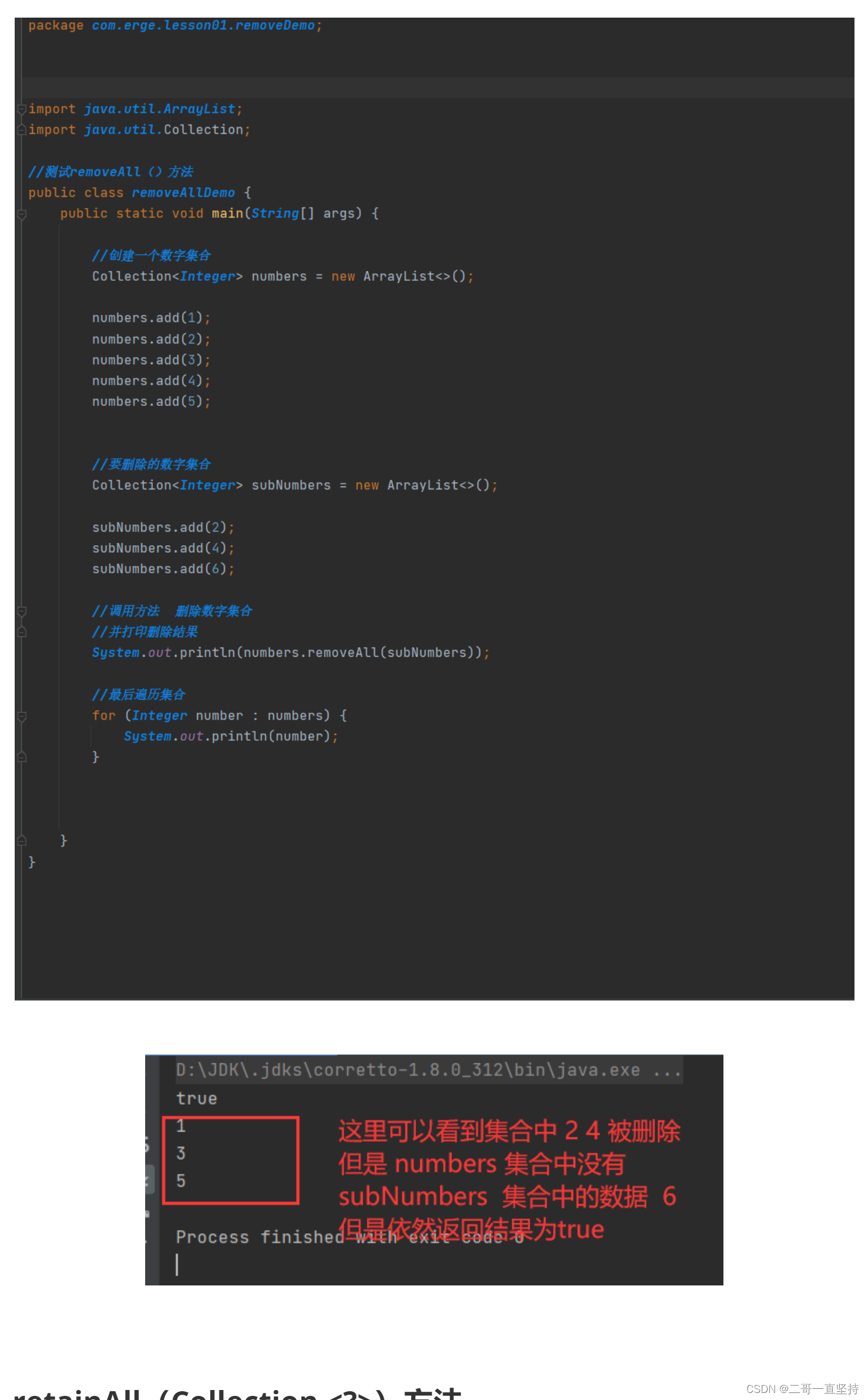
removAll()方法
在该集合中删除指定集合中 一样的数据
c 为指定要删除的数据集合
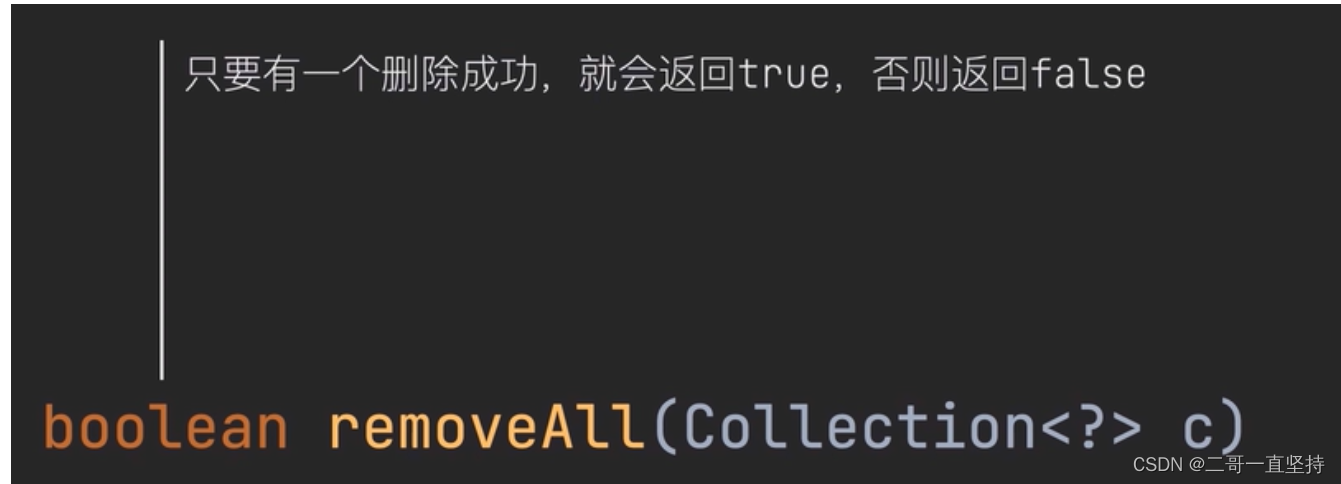
只要有一个删除成功 就会返回true 否则返回false
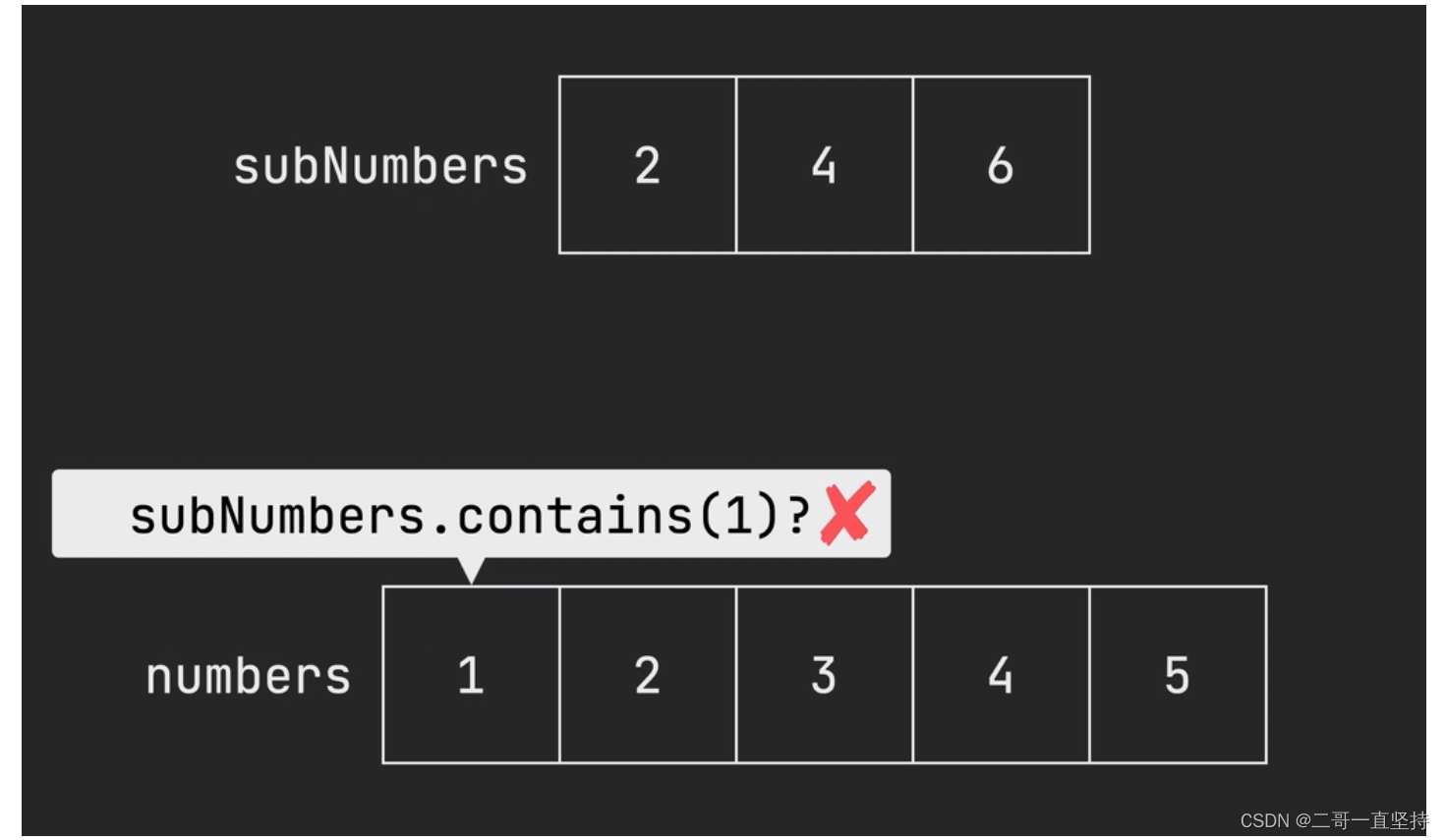
removeAll()方法删除原理
numbers数据集合 删除 subNumbers数据集合中
存在一样的数据
依次检查迭代器中返回的每一个数据 来查看它是否包含在指定的
subNumbers数据集合中
如果包含在内 则使用迭代器中的remove方法 将它从这个集合中删除
练习
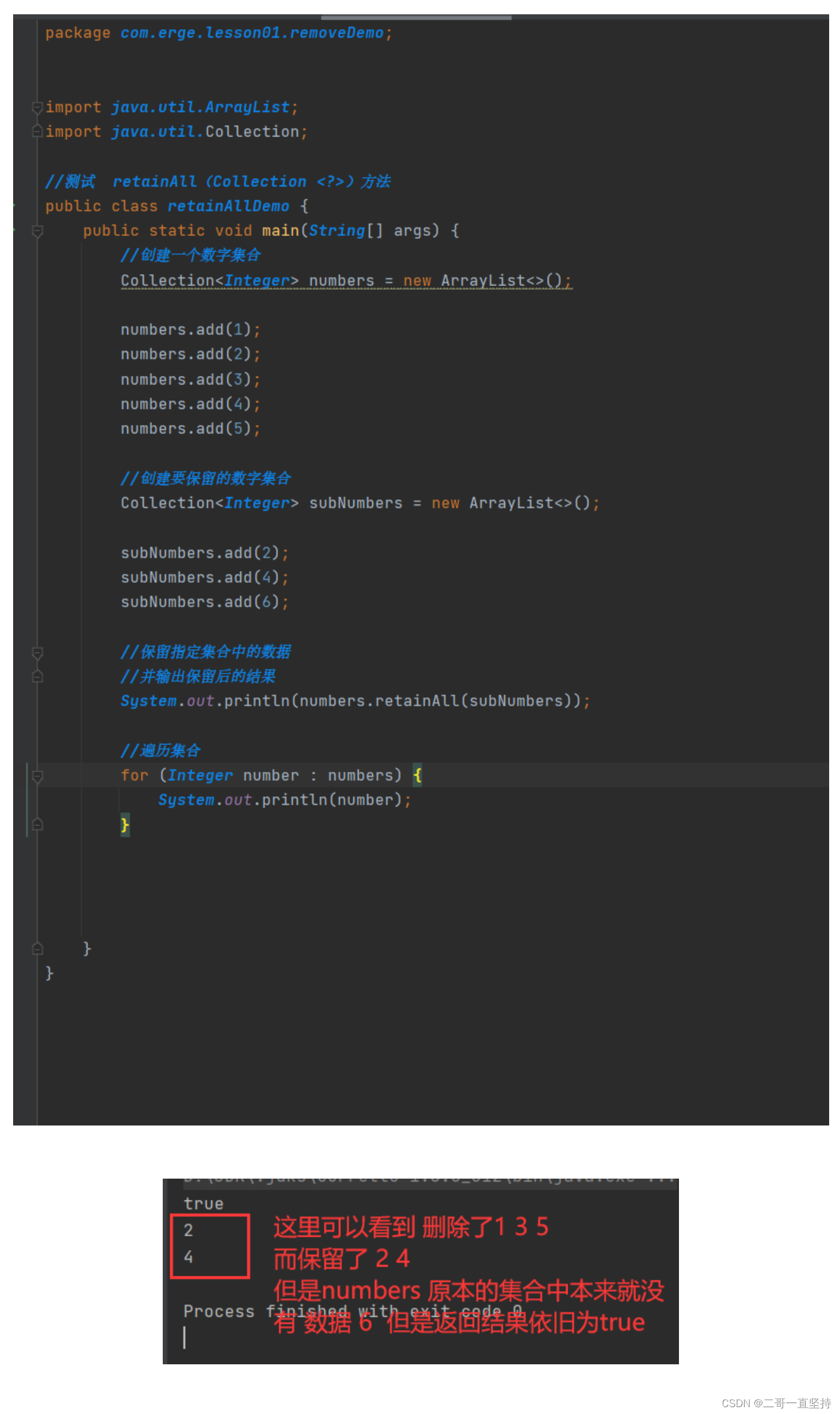
retainAll(Collection <?>)方法
跟removeAll方法正好相反
保留在指定集合中存在的数据
c 为 要保留的数据集合
同理也是 只要有一个匹配成功 就会返回true 否则返回false

retainAll方法保留数据集合原理
遍历集合 依次检查迭代器返回的每一个数据
来查看它是否不包含在指定的集合中
如果不包含在内 则使用迭代器的remove方法
将它从这个集合中删除

练习
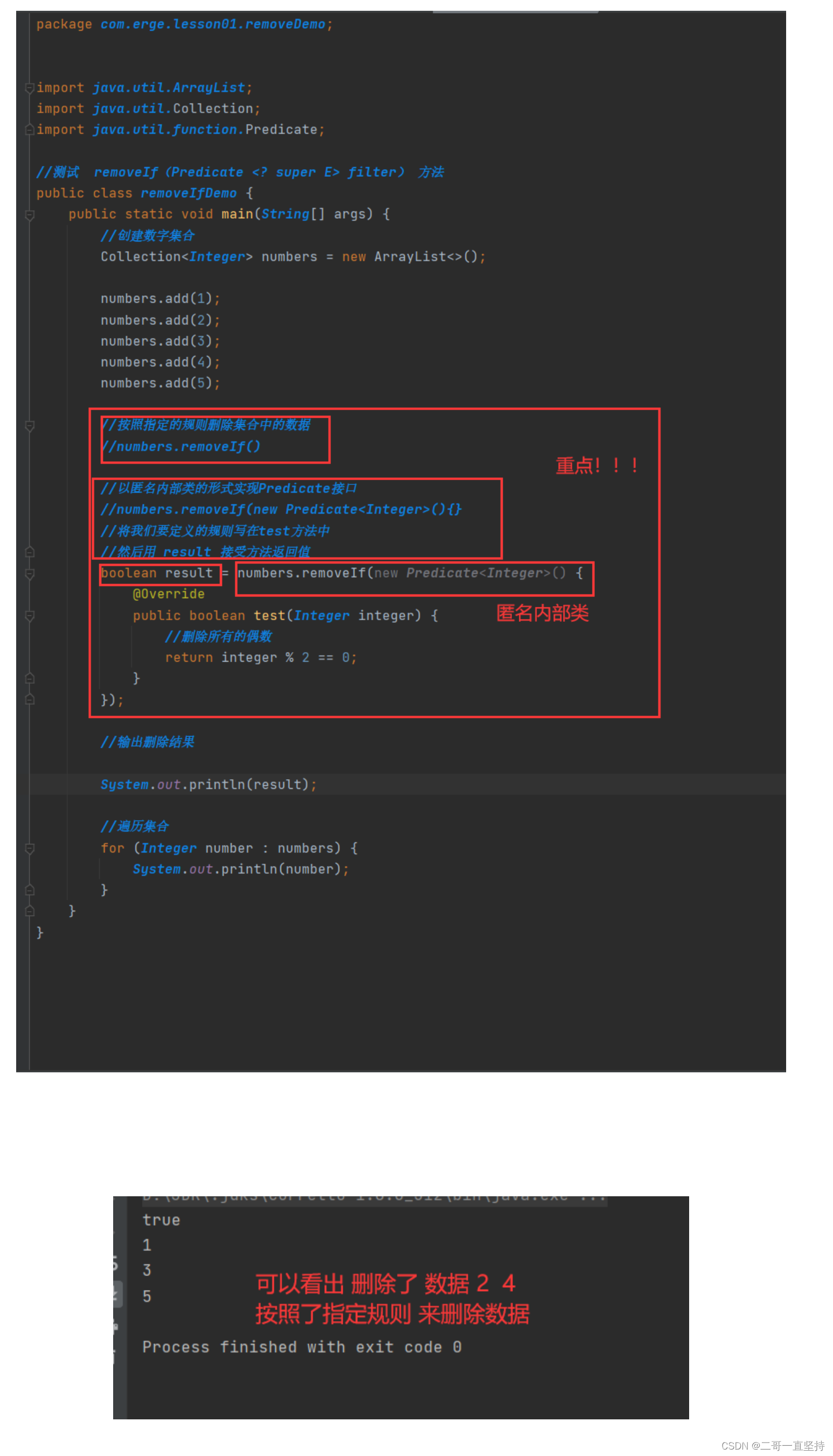
removeIf(Predicate <? super E> filter) 方法
按照指定规则删除数据
filter 为指定删除的规则
只要有一个匹配成功 就会返回true 否则返回false

规则 :删除原理
为 遍历集合 依次检查迭代器返回的每一个数据
以查看它是否满足规则
如果满足规则
则使用迭代器 的remove方法将它从这个集合中删除

练习
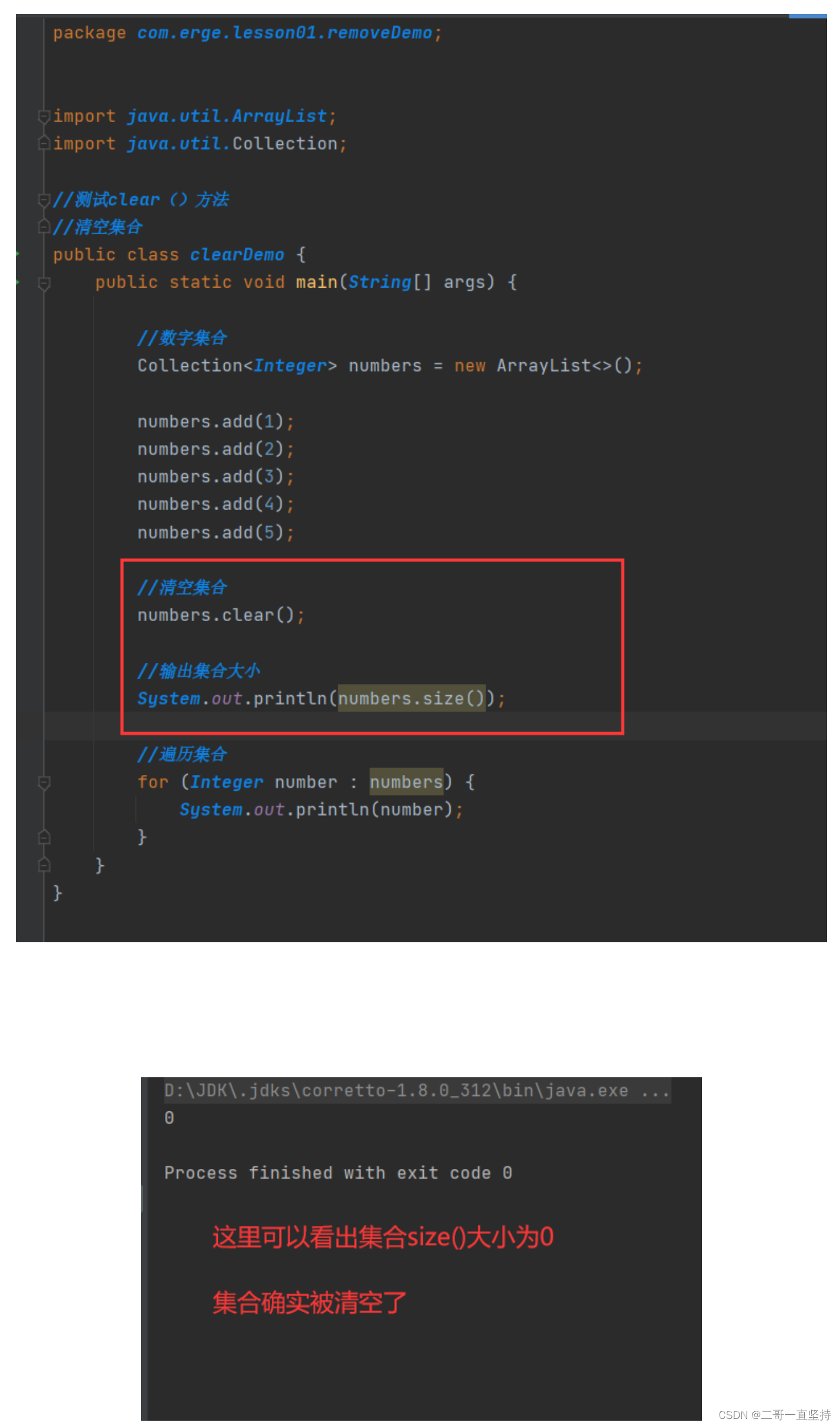
clear()方法
清空集合

代码原理
清空集合
通过遍历集合 依次调用迭代器的remove方法
删除集合中每一个数据

练习
总结上面内容

学习ArrayLIst

介绍ArrayLIst
Array 数组
List 列表
ArrayList 数组列表
所以可以看出 ArrayList 是一个基于数组的集合
ArrayList 内部就是用数组来存储数据的

而数组的特点就是
一 有序 : 元素存入集合的顺序和取出的顺序一致
二 可重复 :它里面可以存储重复的元素
三 可存null : 它里面可以存储 null元素
ArrayList
的优点: 查询快 (只要知道索引 一瞬间就查到了)
ArrayLIst是所有容器中 查询速度最快的一个
缺点 :增删慢
原因:因为数组存满后要扩容 而扩容的过程 是先
创建一个是原来容量1.5倍的数组 然后再把原来的元素拷贝到新数组中 这样导致添加元素的效率就大大的降低了
(所以 在增删过程中 ArrayList集合 数据越多 增删数据就慢 删除也是一样的)

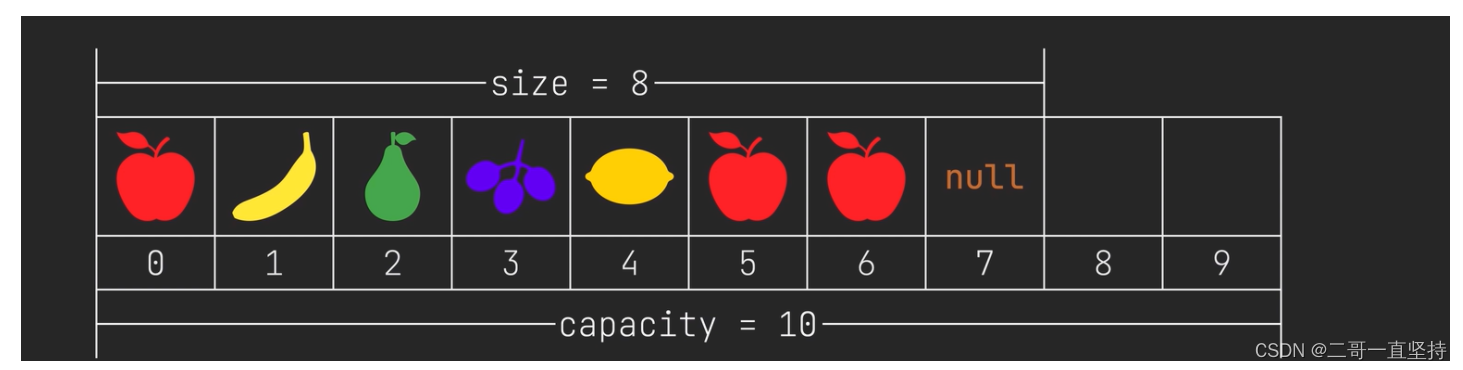
什么是大小(size):
大小就是元素的个数
什么是容量(capacity): 就是数组的长度
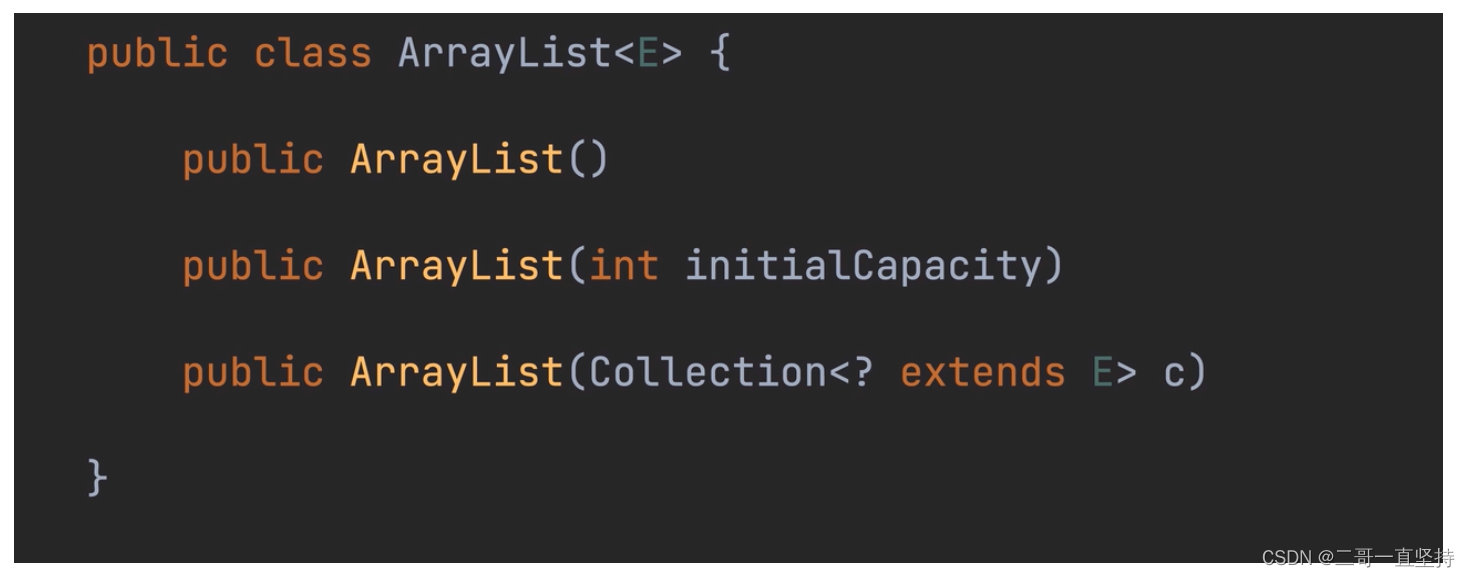
ArrayList的创建方式:
它一共有三个构造方法
无参的构造方法创建:public ArrayList(); 数组默认初始容量为10
pulic ArrayList(int initialCapacity) ; initialCapacity可以指定数组的初始容量
public ArrayList (Collection<? extends E> c); :该构造方法 可以将另一个集合中的元素 插入到ArrayList集合中 c为待插入的集合
数组的初始容量就是集合的大小
ArrayList的常用方法
Collection集合框架结构体系图
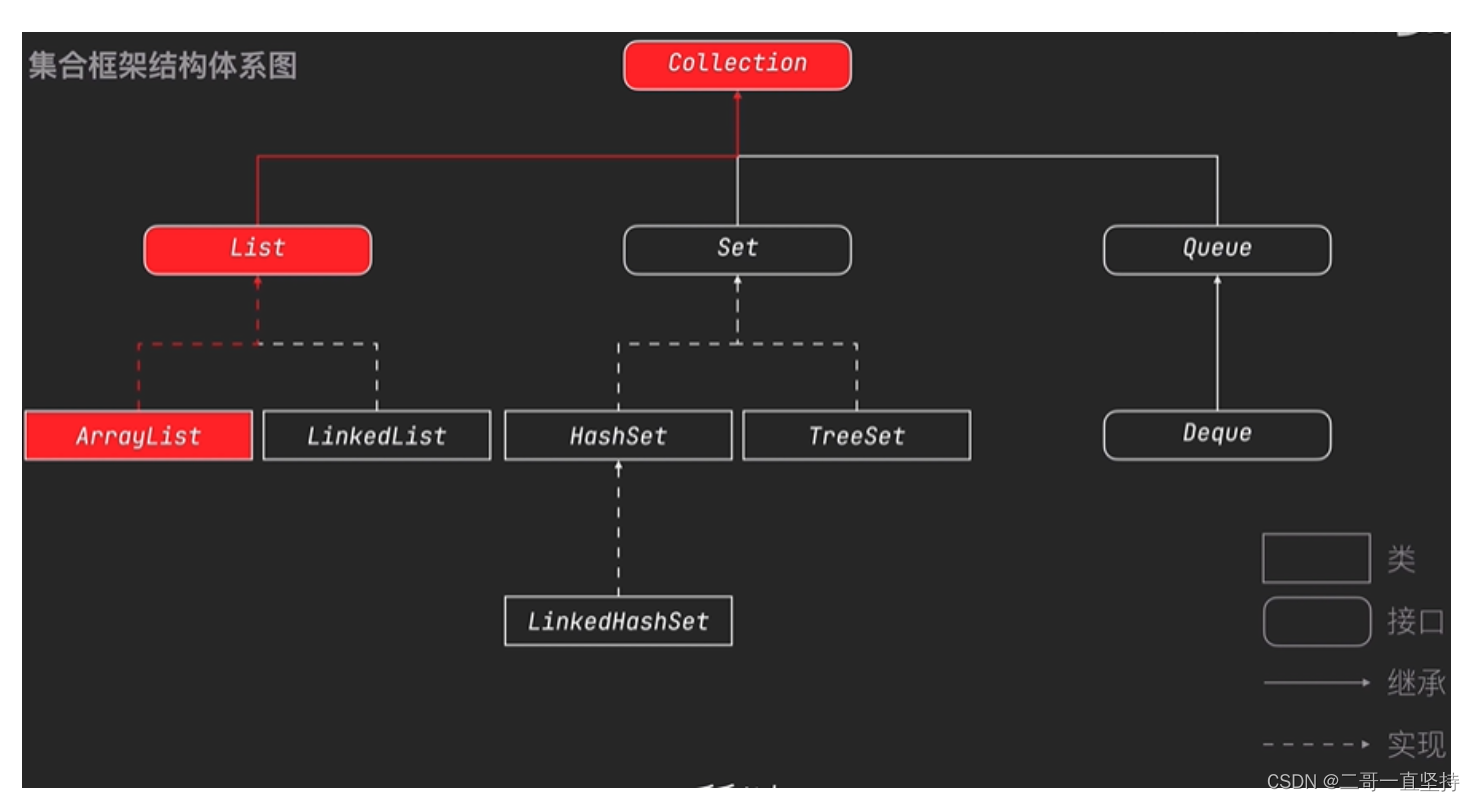
ArrayList作为List旗下的一员 而 List 又作为Collection旗下的一员
所以 ArrayList不但拥有Collection里面所有的方法 而且它还拥有
List里面所有的方法
但是:在这些方法中 它只有十个是常用的方法
Collection集合里面的所有方法

List集合里面的所有方法

所以 ArrayList 常用方法分类
一 查询操作:
有五个方法:涉及到根据索引获取元素 根据元素获取对应的索引
以及迭代器等操作
二 修改操作:
有三个方法: 涉及到添加元素 和 覆盖指定位置的元素 以为删除指定位置的元素
三 批量操作:
有两个方法 :清空集合和为集合创建流

总结:
介绍了ArrayList的特点和优缺点
在实际开发中 它是用得最频繁的容器

LinkedList
Collection集合框架结构体系图

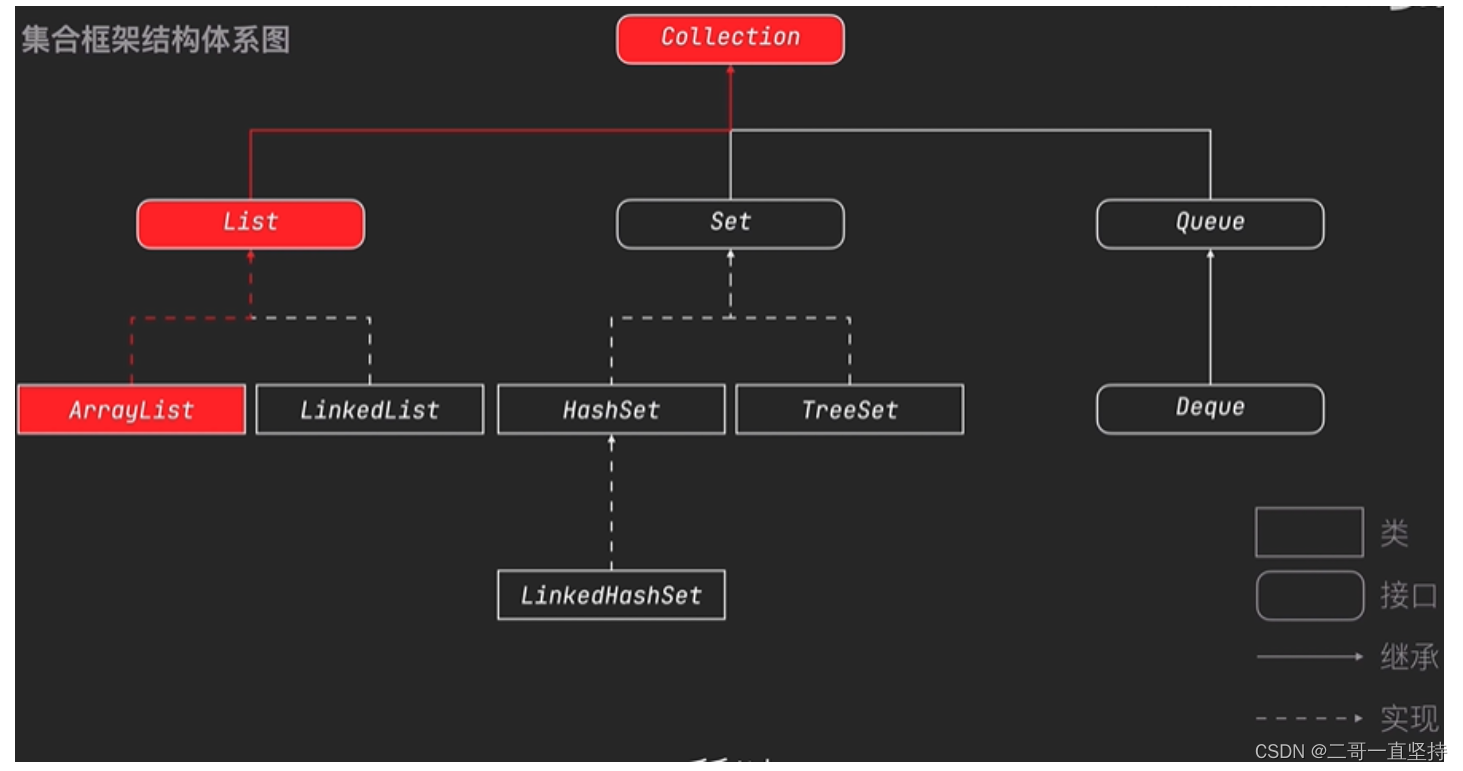
介绍 LinkedList
LInked 链式
list 列表
LinkedList 链式列表 简称列表
可以看出 它是基于链表实现的
而且还是双向的
Node< E > next;
Node< E > prev;
所以LinkedList又称 双向链表
E item:用来存放数据的地方
next用于记录前一个节点
prev(previous)属性用于记录前一个节点
这就是双向的意思
如果单向的话 就没有prev属性 只有next属性
练习
下面演示一个节点
数据就放在item中
此时prev属性的值为null
说明它前面没有节点
next属性的值也为null
说明它后面也没有节点
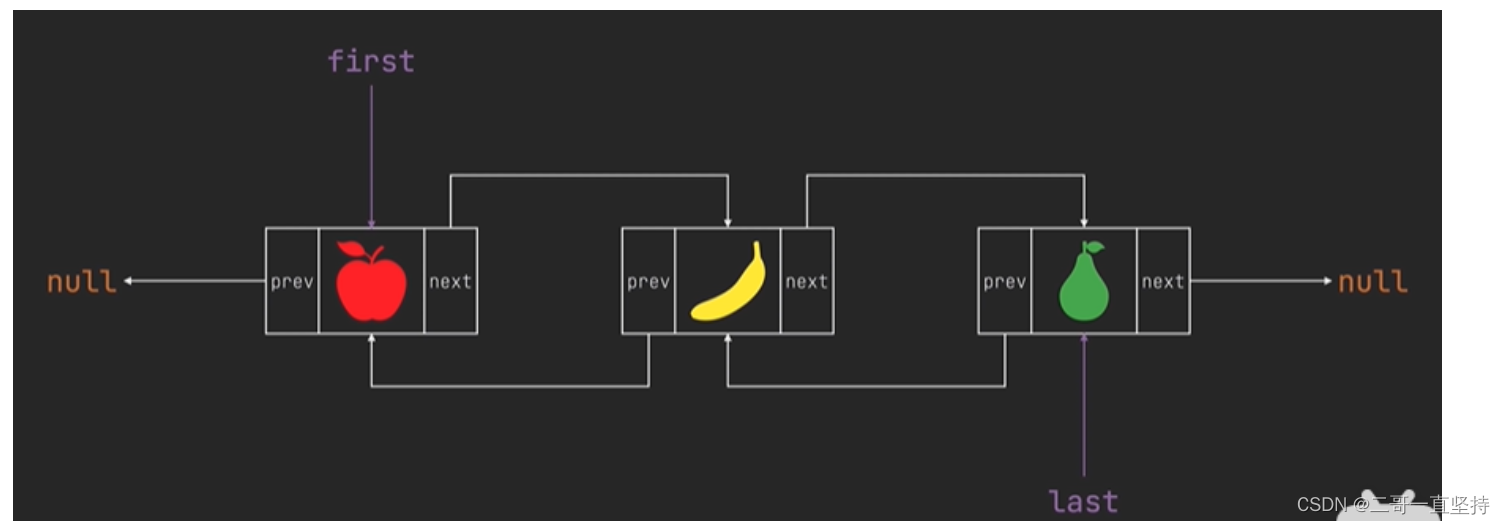
在LinkedList集合中
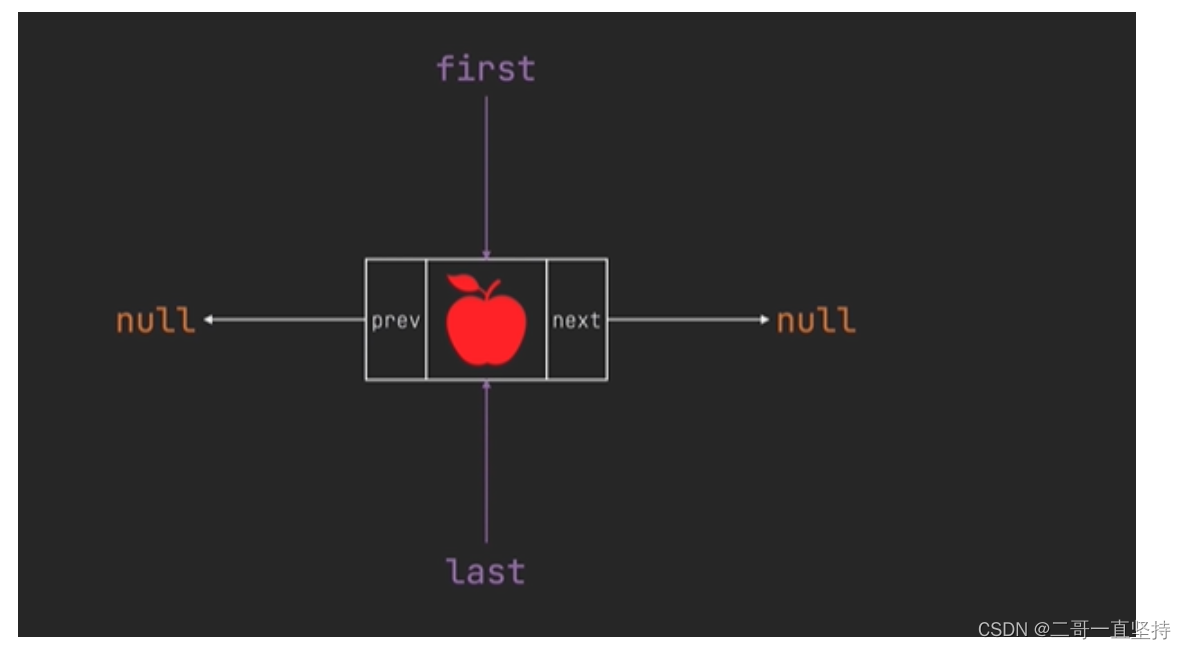
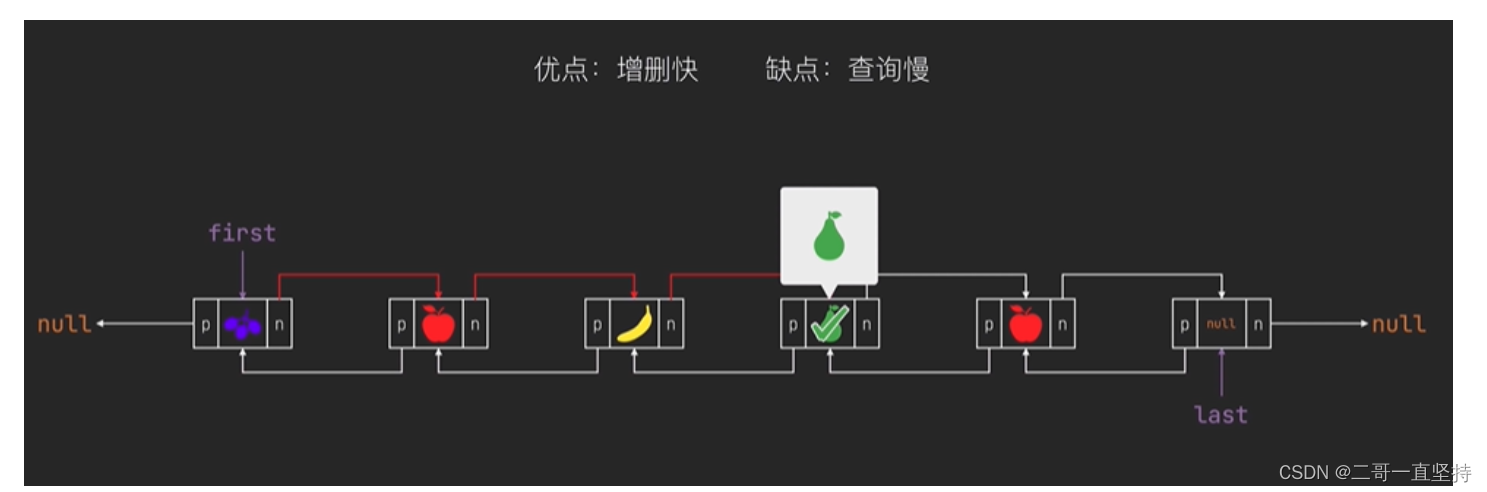
用first属性来记录第一个元素
first 为头节点
而 last属性来记录最后一个元素 为尾节点
当只有一个元素时
当有三个元素时
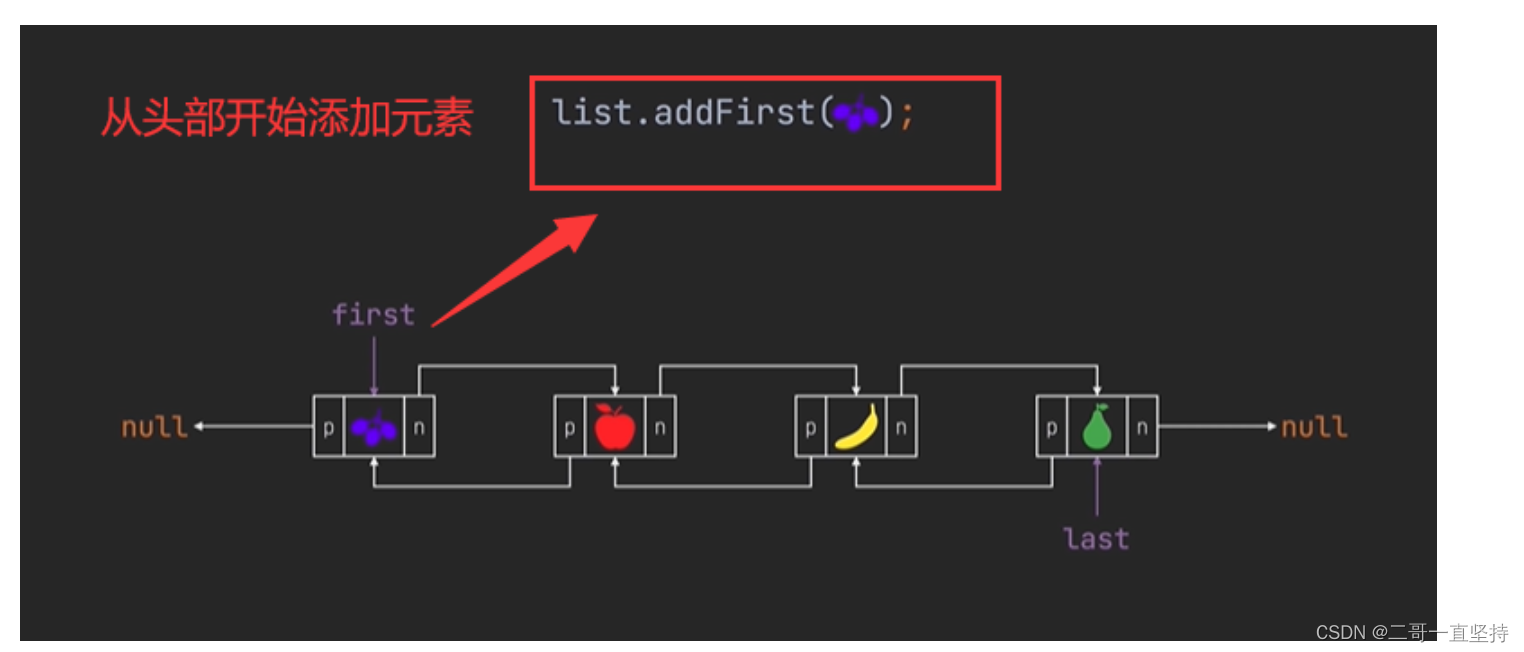
LInkedList集合默认是从尾部开始添加元素的
但是你也可以调用 addFirst方法
从头部开始添加元素
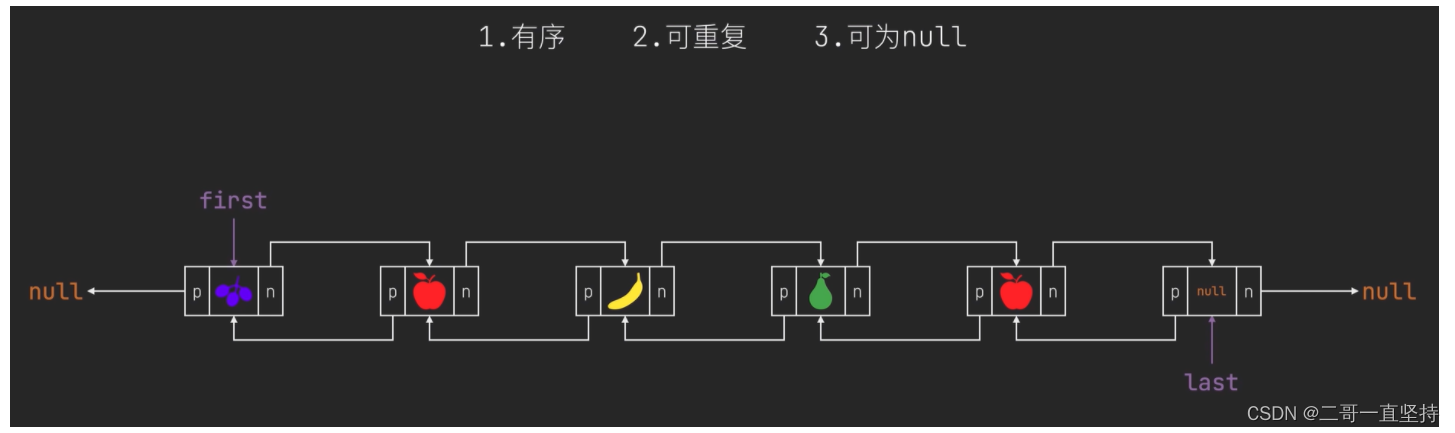
LinkedList集合的特点
LinkedList的三个特点
一: 有序 元素存入的顺序和取出的顺序一致
二 : 可重复 它里面可以存储重复的元素
三 : 可为null 它里面可以存储null元素
优点 :
一: 增删快
当增加元素时:只需记录前后的节点是谁 不需要像ArrayList那样 还要调整数组大小
当删除元素时:只需要调整前后节点的记录 效率非常的快

缺点:
一: 查询慢
即便是知道索引也要从头部或者是从尾部 开始一个接一个的查
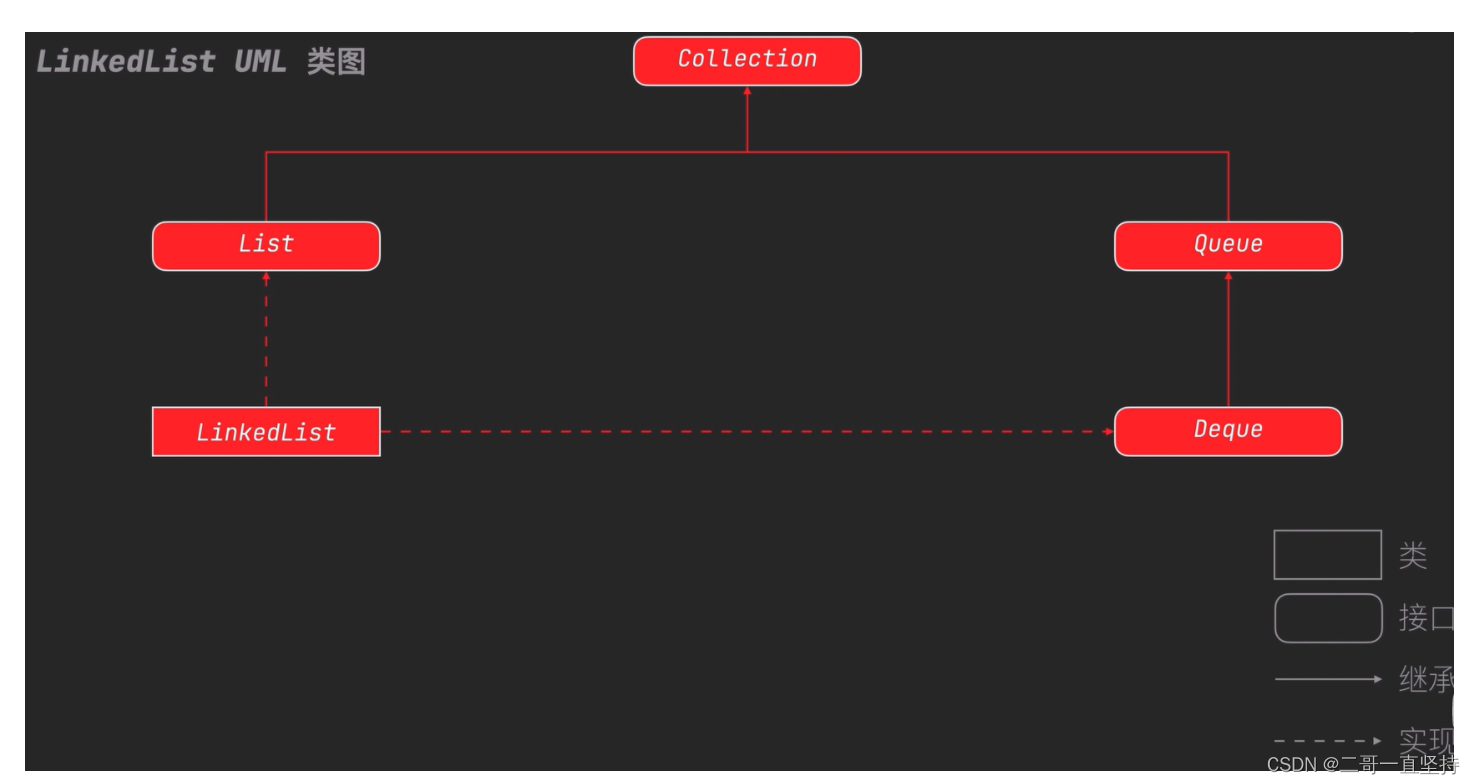
LinkedList的常用方法
LinkedList既实现了List接口
又实现了Deque接口
而Deque又继承Queue
List和 Queue又继承 Collection
所以它拥有的方法特别的多
LinkedList UML 类图(重点)
它拥有Collection里面的所有方法
List 里面的所有方法
Queue里面的所有方法
也有Deque里面的所有方法
但是在这些方法里
它只有九个方法是常用的
这九个方法中缺少删除数据的方法、
Collection方法分类 List方法分类 Queue方法分类 Deque方法分类 LinkedList 常用方法分类

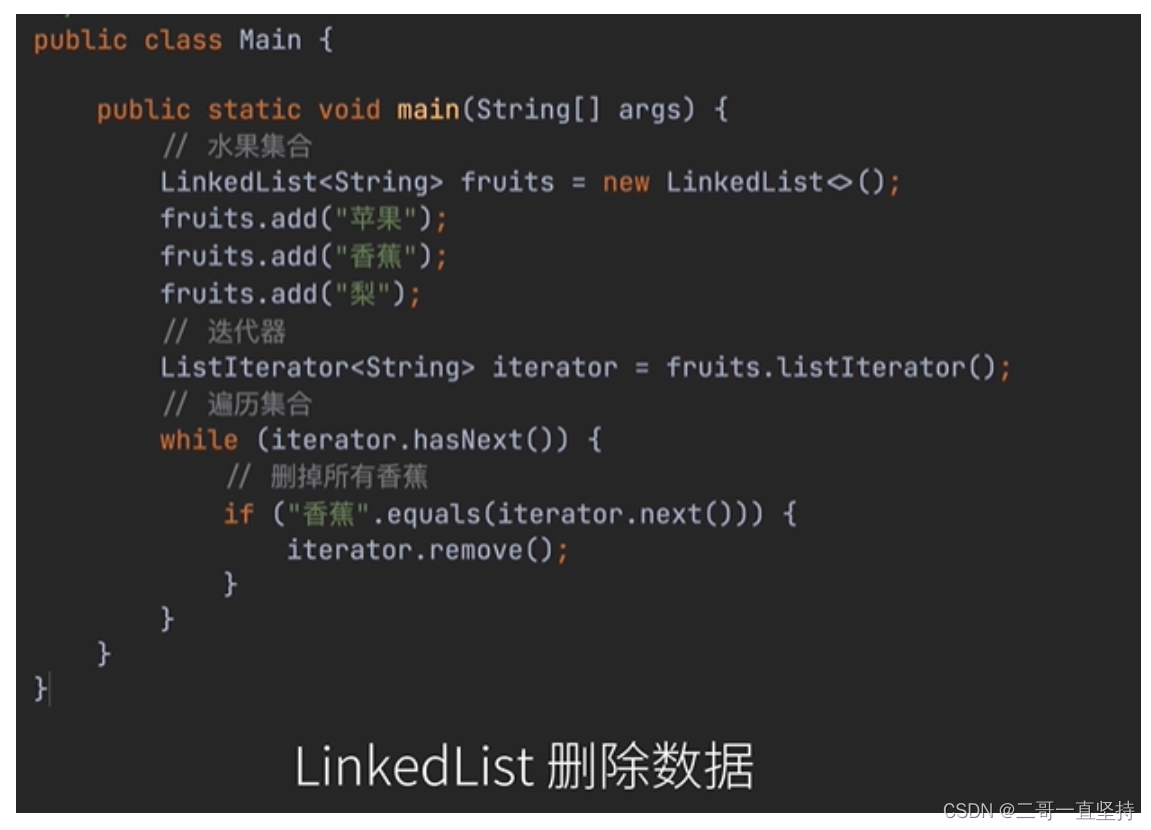
LinkedList删除数据
在LinkedList删除数据
—般是找到匹配项以后
使用迭代器的remove方法
进行删除
LinkedList 与 ArrayList 的区别
它俩的区别主要来自于数据结构的不同
ArrayList是基于数组实现的
LinkedList是基于链表实现的
因为数组是基于索引 (index)的数据结构
所以它查询数据的速度是很快的
相对于ArrayList
LinkedList查询数据的速度是很慢的
因为需要在双向链表中
一个接一个地找
但是在增删数据中
LinkedList要比ArrayList快得多
因为它不需要频繁地调整数组大小
只需要记录前一个元素
和后一个元素是谁
就可以了
正是因为这样
LinkedList需要更多的内存
而ArrayList 不需要花费额外的内存
来记录前后都是谁
所以综上所述
ArrayList多用于查询较多的应用场景
而LinkedList多用于增删较多的应用场景

总结:

HashMap

什么是HashMap
Hash:“散列”或“哈希”的意思
Map:”映射“的意思
HashMap:哈希映射

Map集合框架结构体系图
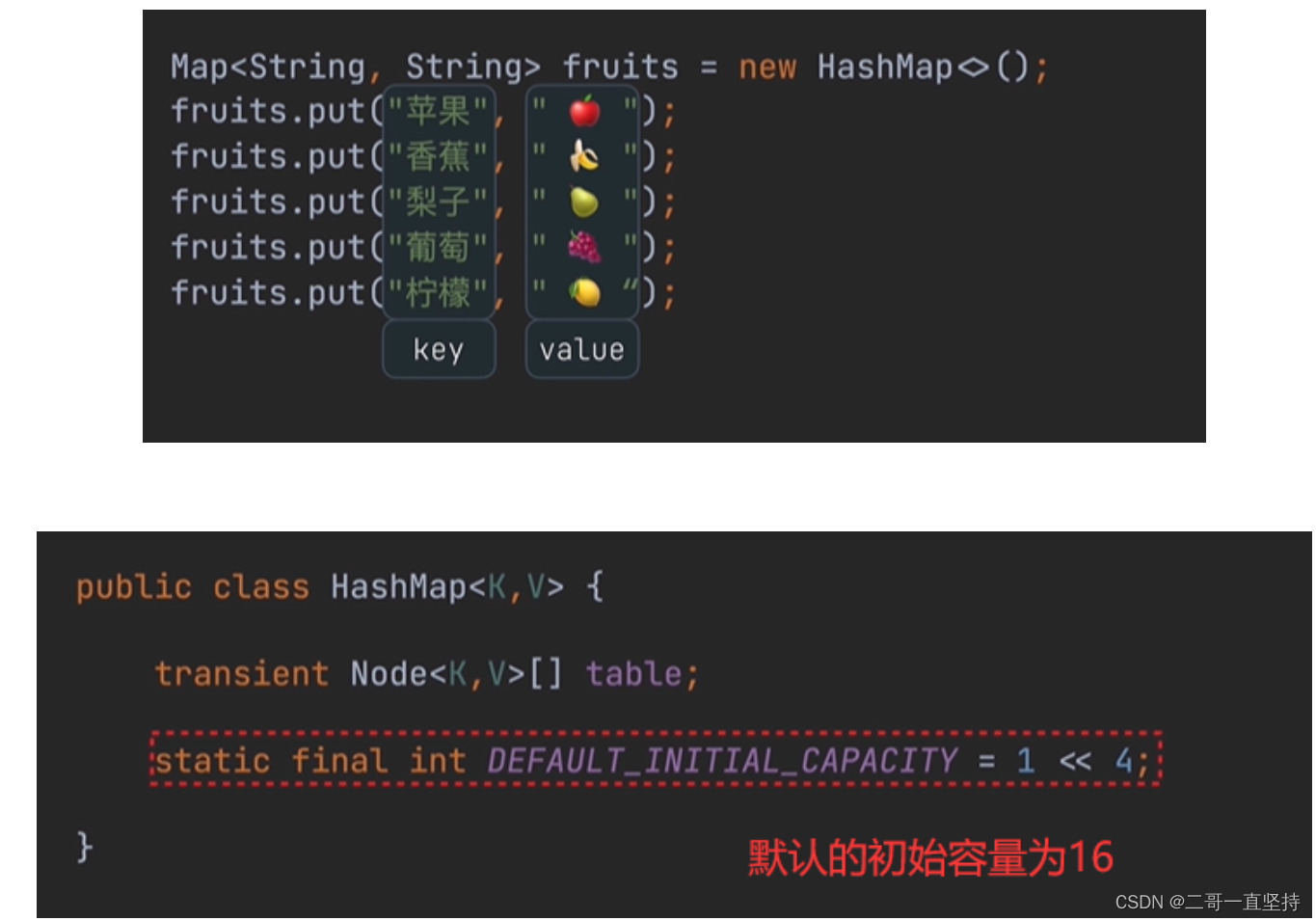
所以可以看出
它是以key-value(键值对)形式存储数据的
而且这些数据保存在数组中
默认的初始容量为16
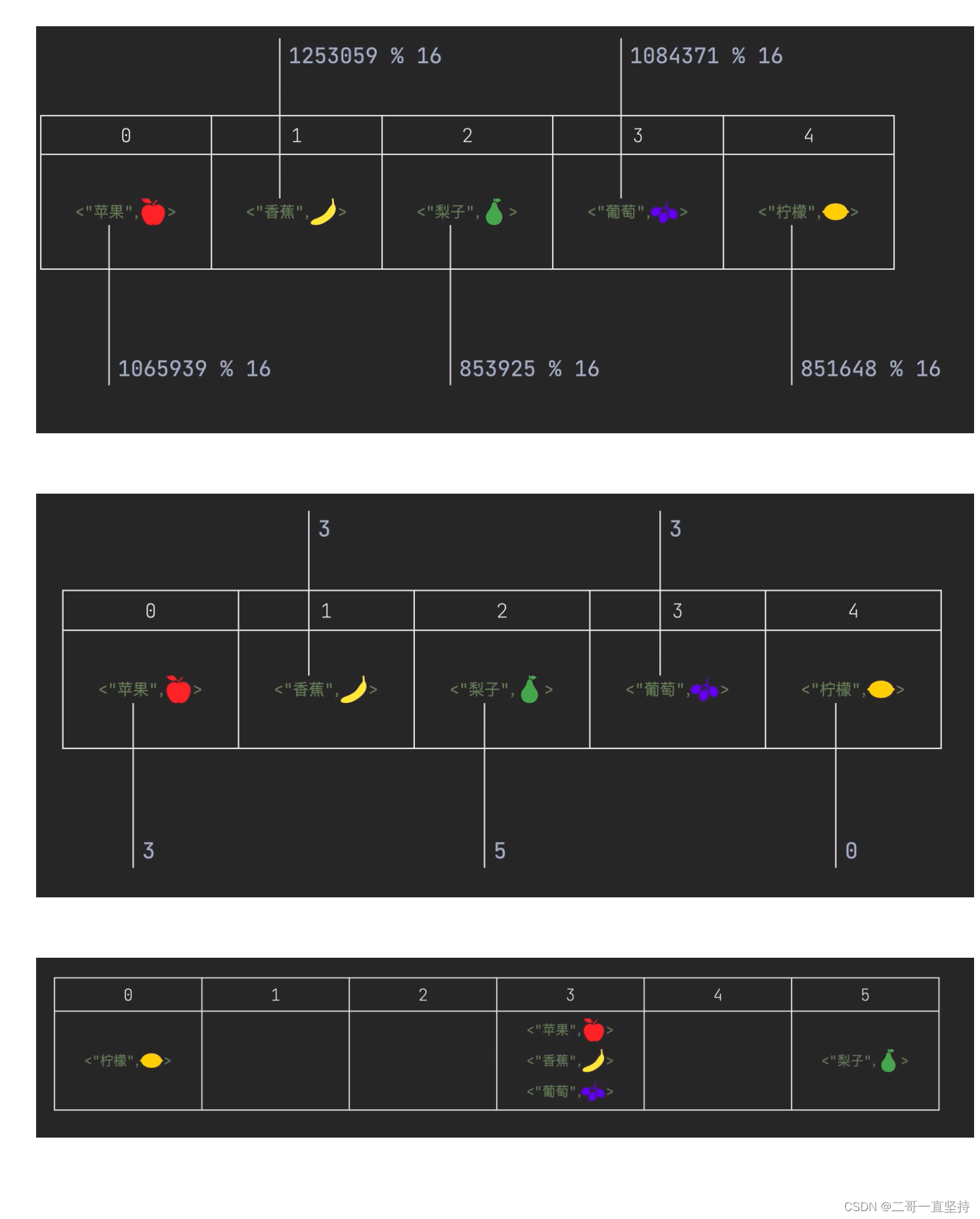
数组的特点是有序
但 HashMap里面的元素
并不是按顺序存放的
而是先根据key计算出
元素的哈希值
再&(与上)(数组容量-1)

这个操作等同于
与数组容量取余
得到的余数
就是元素的位置
如此以来
势必会有多个元素
被分配到同一个位置上
那该怎么办呢
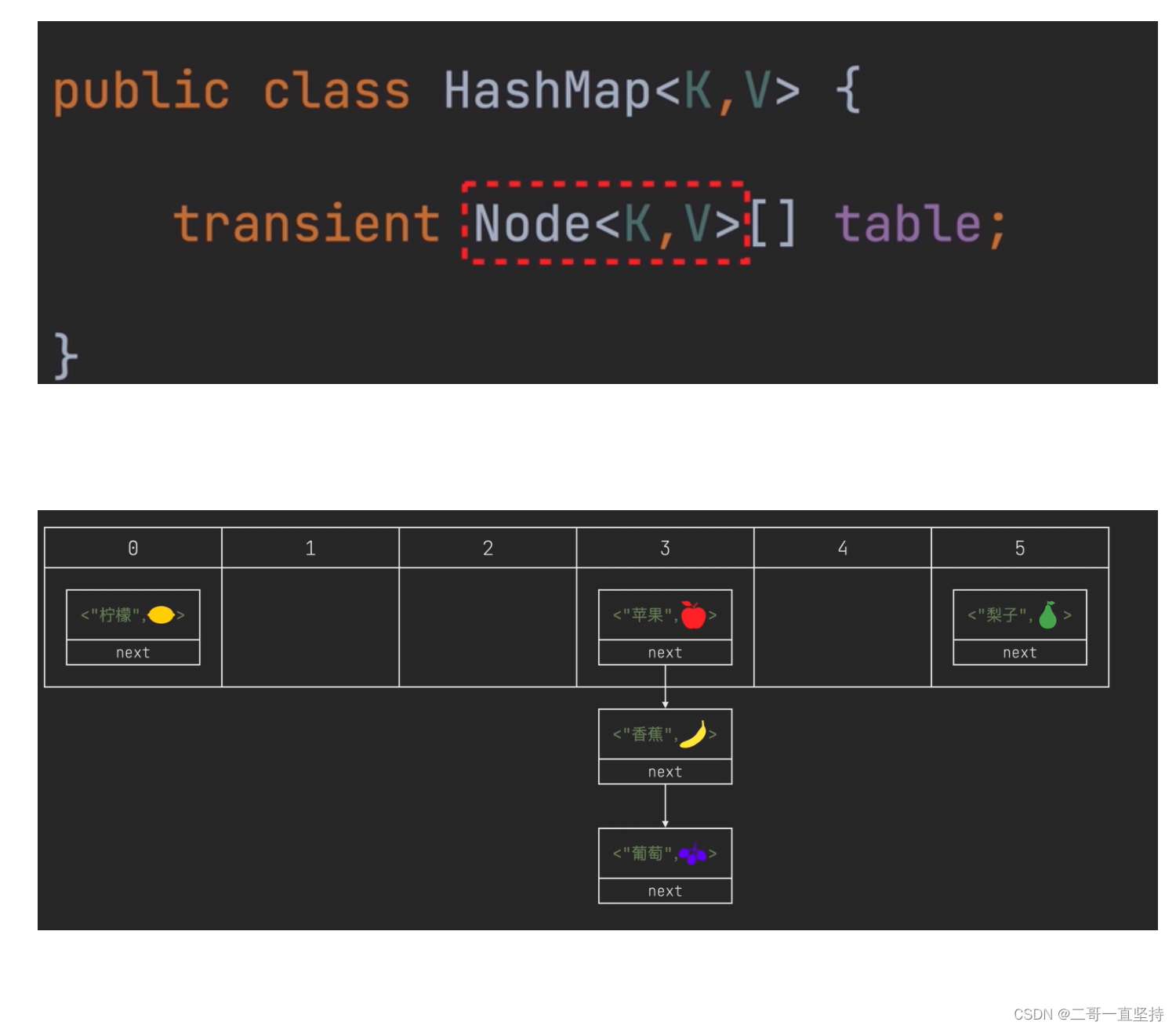
HashMap
用链表将这些元素
单向的连接起来
这样解决了多个元素位置冲突的问题
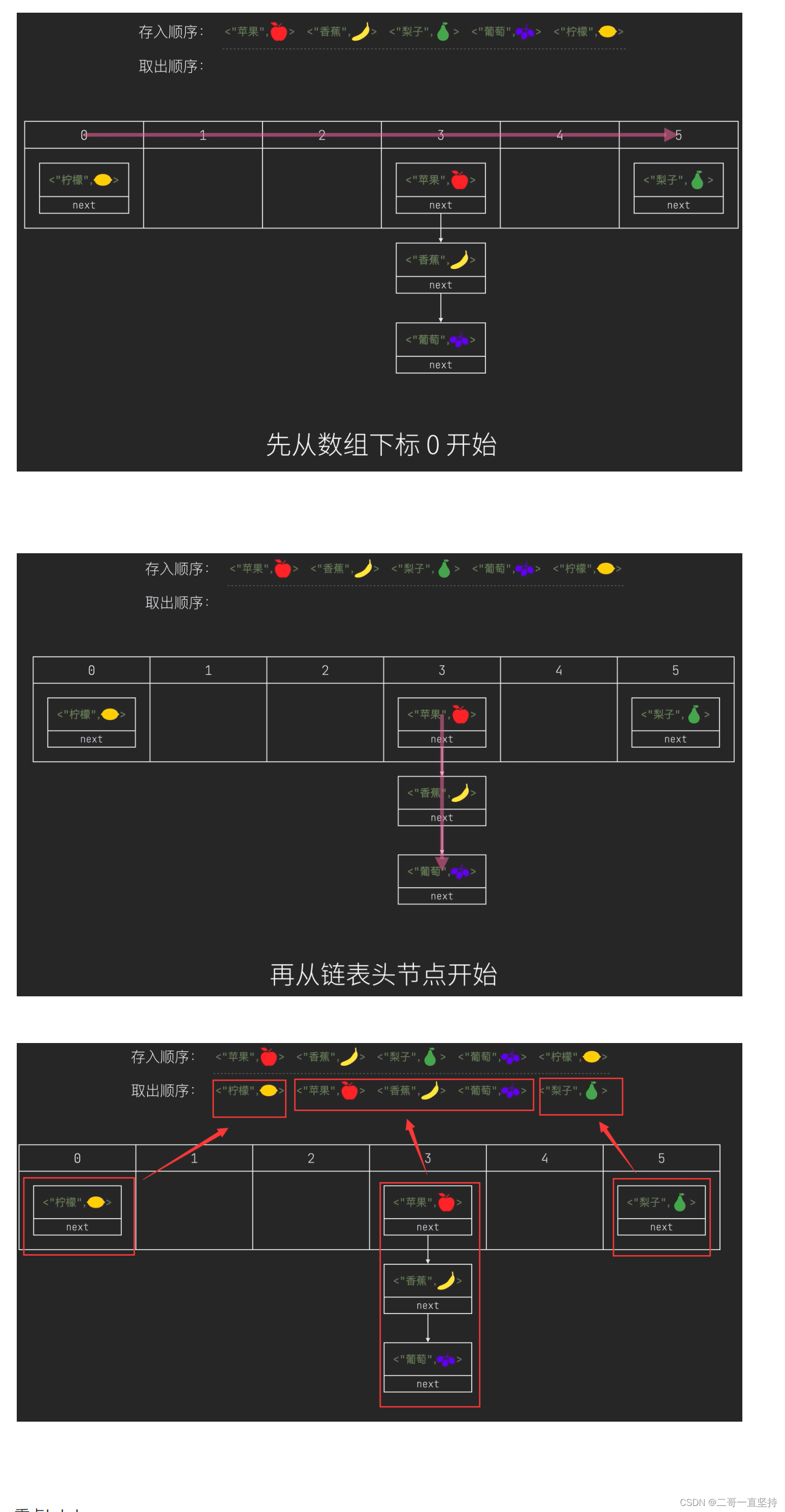
但是这样存了以后 该怎么取呢
取出的顺序:先从数组下标0开始
再从链表头节点开始
重点!!!
所以 依次是 柠檬 苹果香蕉 葡萄 梨子
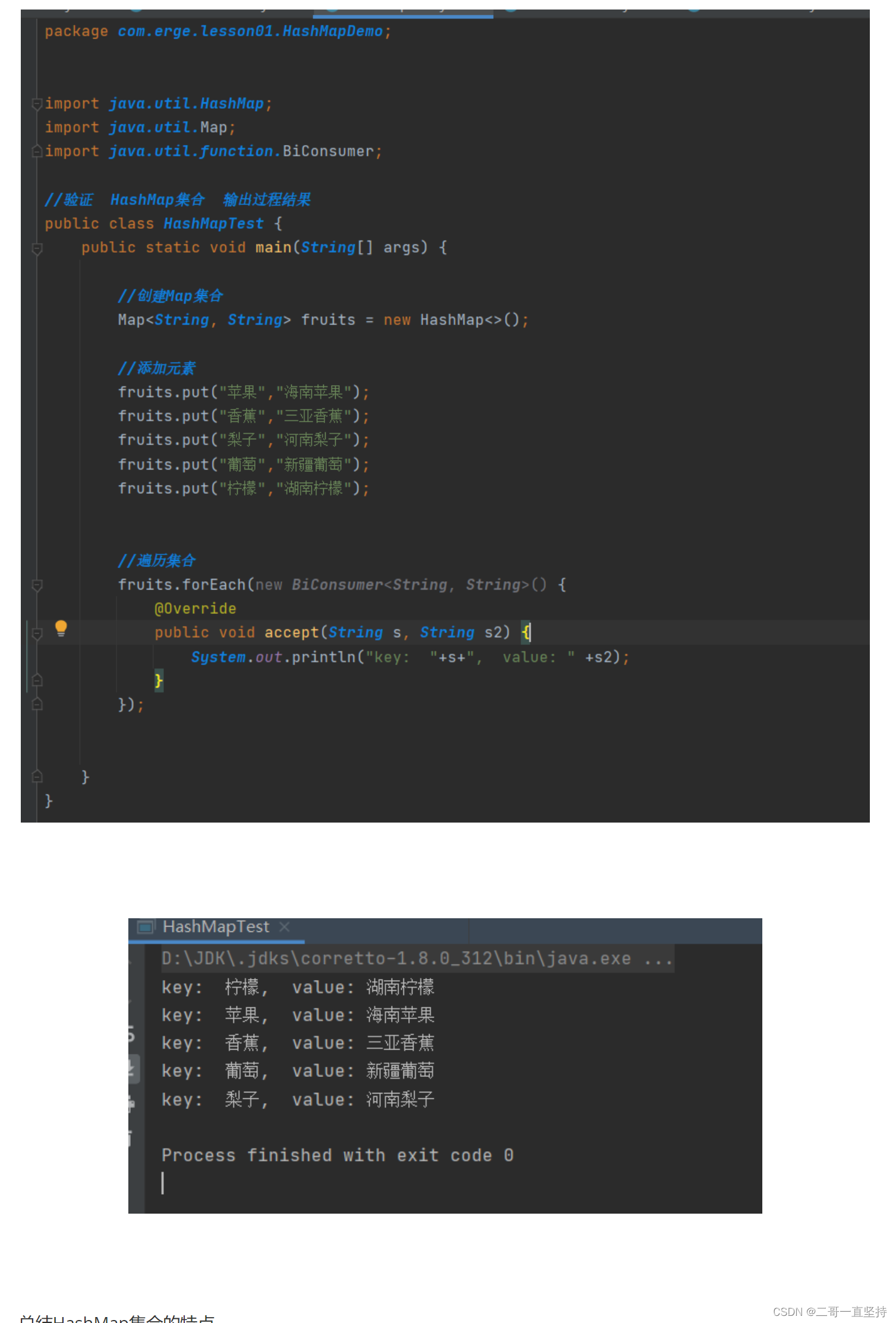
练习
重点!!!
程序验证 是不是这个顺序取出的
总结HashMap集合的特点
总结HashMap集合的特点
重点:
第一 无序: 元素存入的顺序和取出的顺序不一致
同时 这也是它唯一的缺点

HashMap的第二个特点: key可以为null
我们在计算元素哈希值的地方
发现了key 还可以为null
并且还给它分配了哈希值是 0
下面为三元运算符:
/X ? y : z
//如果x== true则结果为y否则结果为z
例如 :key==null 的时候结果为0
所以可以总结出
HashMap的第二个特点
key可以为null
并且哈希值为0
HashMap的第三个特点 : key不可以重复
因为通过前面的知识
我们可以知道
key相同
哈希值就一定相同
位置也就相同
出现这种情况
新值会覆盖旧值
由此我们可以总结出:
key不可以重复
重复的key
新值会覆盖旧值
什么是哈希冲突
它是两个不相同的key
产生了相同的哈希值
我们把这种情况称之为 哈希冲突
也叫 哈希碰撞
发生碰撞的本质
还是取值范围的问题
比如 一个二进制位
它的取值范围是0-1
若在它里面取哈希值的话
要么是0
要么是1
此时发生碰撞的概率是1/2
也就是说
如果有三个key时
就一定会发生碰撞
但是 如果我们将哈希值的长度
扩大到16个二进制位
那么它的取值范围就会越大
发生碰撞的概率就会越小

在HashMap中
哈希值是int类型
(final int hash;)
四个字节
长度是32个二进制位
碰撞的概率是1/4294967296
更长的哈希值
意味着发生碰撞的概率更低
但是也需要更大的储存空间
和更多的计算
我们需要在性能和成本之间做好权衡
HashMap的特点: 链化<==>树化
什么是链化
什么是树化
“树化”是当链表长度大于8
且数组容量大于等于64时
将链表转换为红黑树
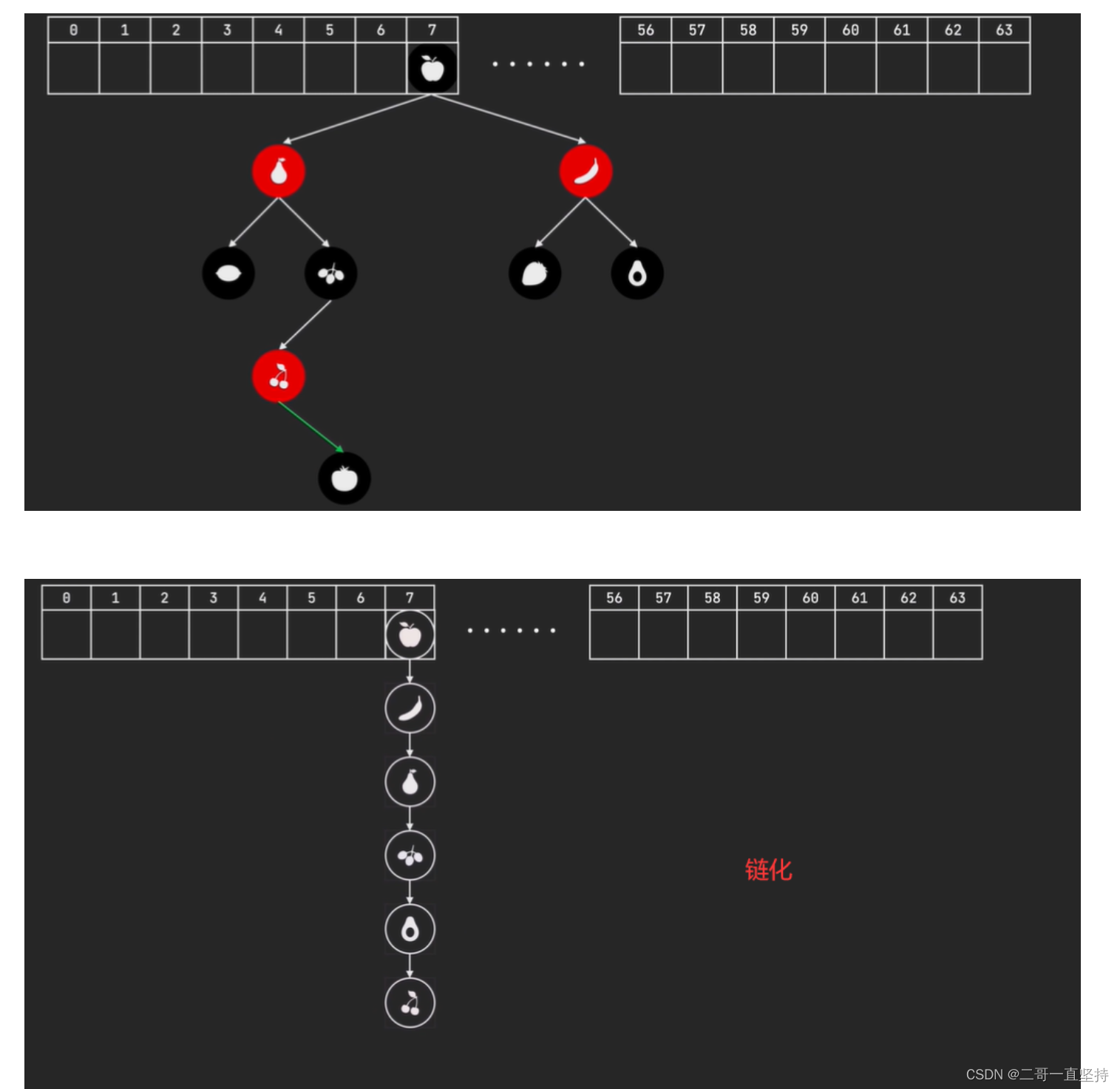
红黑树是一种自平衡的二叉树
这样做的目的
是为了提高查询速度
因为链表一旦长了以后
查询就会变得很慢
另外
红黑树也会变回链表
当红黑树中的节点小于等于6时
红黑树将转换为链表
这个过程称之为"链化"
此时的节点数很少
链表与红黑树的查询速度不相上下
而且
在新增元素的时候
链表不用计算节点的位置
直接插在尾部
但红黑树还要计算节点的位置
因此
它们两个互相转换
可以形成很好的互补
注意点:
HashMap在JDK1.8中
才引入的红黑树
以前采用的是数组+链表这种形式

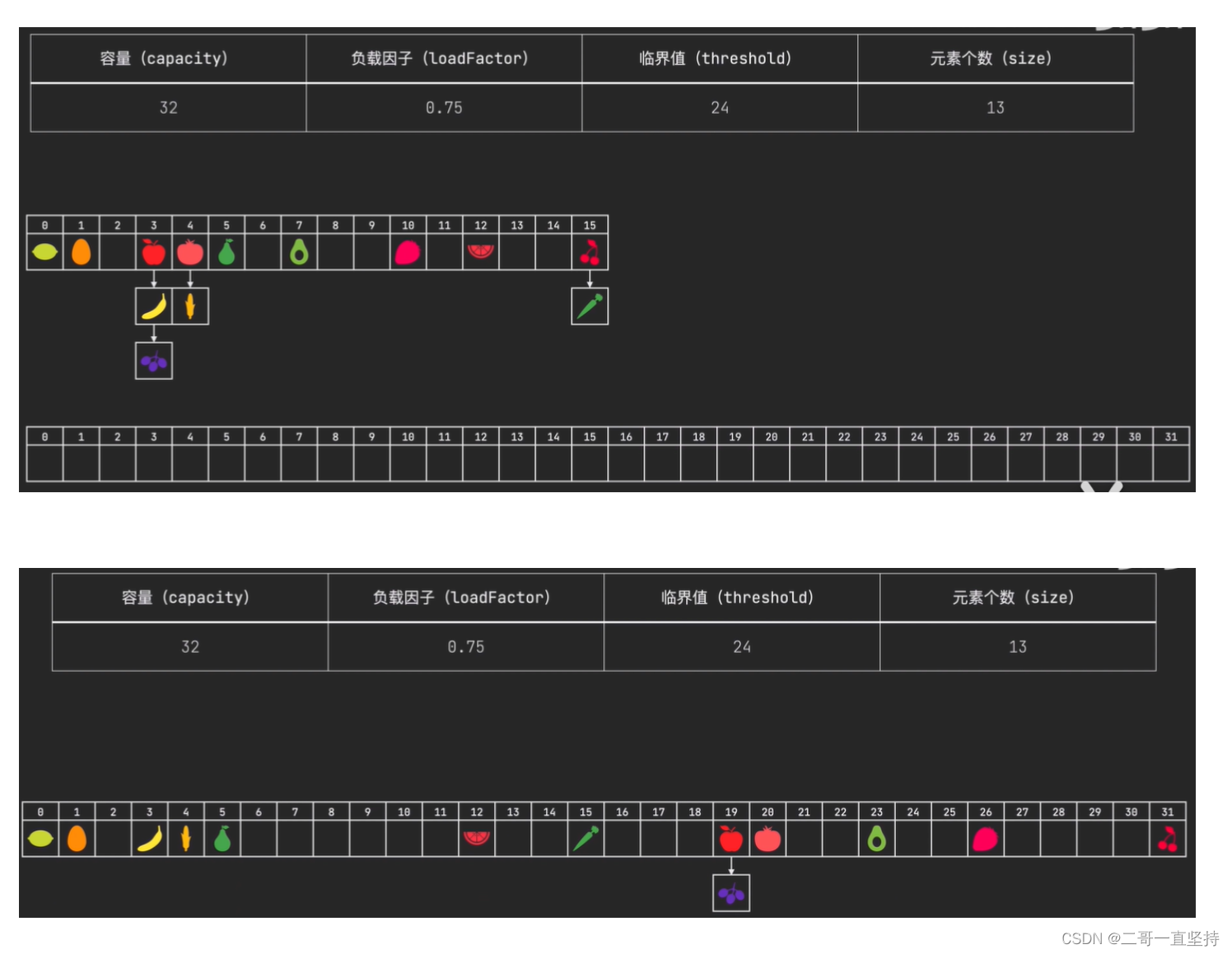
HashMap的特点:扩容
当元素个数超过临界值时
HashMap就需要扩容
临界值=容量 * 负载因子
扩容后的容量是之前的两倍
频繁扩容很影响HashMap 性能
所以
设置合适的初始容量与负载因子至关重要

HashMap的常用方法
HashMap 实现了Map接口
拥有Map 里面的所有方法
但是在这些方法里面
它只是有8个方法是常用的
重点:!
其中 put和get方法用得最频繁
Map方法分类和HashMap常用方法分类

总结HashMap集合
本节介绍了哈希映射 hashMap
它的优缺点和特点
在实际开发中
它是用得最频繁的容器之一
多用于缓存数据


















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









