



 本文讨论了GIS属性查找中的中文分词问题及基于词典库的Trie结构设计,包括文件头格式、检索原理、索引文件设计、单棵子树原理等关键点,解决性能问题。
本文讨论了GIS属性查找中的中文分词问题及基于词典库的Trie结构设计,包括文件头格式、检索原理、索引文件设计、单棵子树原理等关键点,解决性能问题。
GIS属性查找
陈玉进 李泉 南京跬步科技有限公司(http://www.creable.cn)
词是最小的具有独立活动的有意义的语言层份。(汉语中,词与词之间没有明显的分隔标记,而是连续的汉字串,为了让计算机更好地处理中文,首先需要从汉字串中分离出每个词,这就是所谓的“中文分词”,它是中文信息处理的基础。比如,“我是一名学生”,分解成词,“我”“是”“一名”“学生”。如何进行中文分词呢?目前主要有两种方式:一,基于词典库;二,基于词频统计。本文主要讲“词典库”文件结构的设计。
所谓词典库,也就是众多词的集合。在分词匹配搜索中,需要频繁访问词典库,词典库结构性能的好坏关系到整个系统运行的效率。本文采用Trie结构来组织词典。如下图:
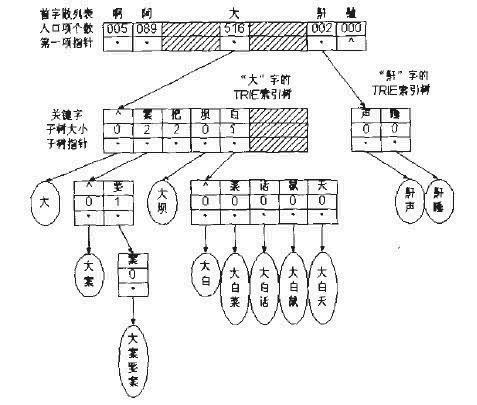
再比如,词表:啊,阿根廷,阿胶,阿拉伯,阿拉伯人,埃及
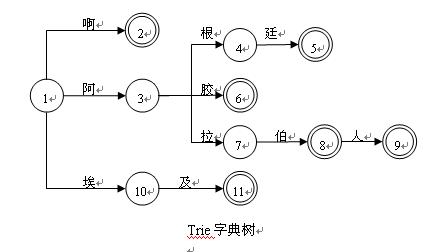
我们用TRIE字典树来组织词,根节点没有值,指向所有词的首个字,对树从根节点开始遍历,遇到单圆圈,表示不能形成词,遇到双圆圈,表示已经访问过的字,到此处可以形成一个词.
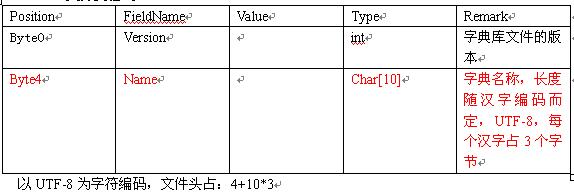
一、 文件头格式
一、 TRIE字典树检索原理
由于TRIE 根节点下的首字节点很多,为了有效地支持对首字子节点的查找,我们采用首字散列的方法,Hash函数的设计,可以用采用汉字内码来设计,非首字的子节点,按汉字内码排序,进行二分查找,当非首字子节点数量比较少的情况下,也可以不排序,直接遍历.
二、 TRIE字典树索引文件的设计
通过首字节点的散列来定位Trie子树的文件位置和子树大小,这是一个二维数组,第一维代表的长度是当前汉字编码总共搜集的汉字个数,第二维长度为2,即 汉字个数*2 的数组,第一维存储首字代表的子树文件地址,第二维存储子树跨越的字节长度。
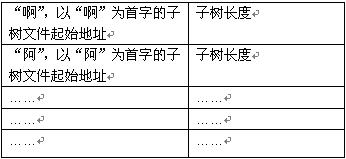
字典树的索引,在用户进行属性查找时,调入内存,直到用户退出属性查找界面,清除出内存。
TRIE字典树的索引,每个数组元素格式 (根据下一个树的偏移可以出该树的字节长度)

|
三、 TRIE字典库单棵子树原理 字典库单棵子树逻辑上是一棵树(见上图),物理上,我们采用广度优先遍历的顺序,把节点按序存储进数组,数组大小为这棵树的节点个数,同时生成一个相同长度的二维的索引数组,用来存储这棵树节点之间的关系。 以上面的首字“阿”的子树为例,广度优先遍历这棵子树
节点数组:0阿——1根——2胶——3拉——4廷——5伯——6人 (广度优先遍历顺序,前面的数字代表数组的位置),数组第一个元素为子树根节点。
总结 首字索引采用数组存储,首字的编码为该字的数组位置,非首字按编码排序,进行二分查找。以上设计解决了GIS属性模糊查找逐条记录匹配时所出现的性能问题,尤其是海量GIS属性数据的查找,值得注意的是,GIS属性分词库的建立,需要通过现有的分词软件或人工的方式进行分词。 作者:陈玉进 李泉 南京跬步科技有限公司(http://www.creable.cn) |



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









