



本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
本文作者:
- 第一作者 老架构师 肖恩(肖恩 是尼恩团队 高级架构师,负责写此文的第一稿,初稿 )
- 第二作者 老架构师 尼恩 (45岁老架构师, 负责 提升此文的 技术高度,让大家有一种 俯视 技术、俯瞰技术、 技术自由 的感觉)
服务 发现 该选 AP 还是 CP? 为什么?
说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如微博、阿里、汽车之家、极兔、有赞、希音、百度、网易、滴滴的面试资格,遇到一几个很重要的面试题:
服务注册发现,该选 AP 还是 CP? 为什么?
最近有小伙伴在面 阿里。
小伙伴没有系统的去梳理和总结,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V175版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取
题目很高频 ,小伙伴在网易也遇到了:
网易一面:Eureka怎么AP?Nacos既CP又AP,怎么实现的?
为什么要使用服务发现?
在云原生+微服务时代,服务实例是 云原生的,动态部署的,我们甚至 不知道这个服务运行在哪台服务器上,不知道它的 IP 地址和端口 。
所以,现在的云原生+微服务架构下,情况变得复杂了:
- 服务的地址不是固定的,每次启动都可能不一样。
- 服务可能会自动扩容、缩容、重启或升级,导致地址频繁变化。
这就带来一个问题:怎么让client 客户端始终找到正确的服务server?
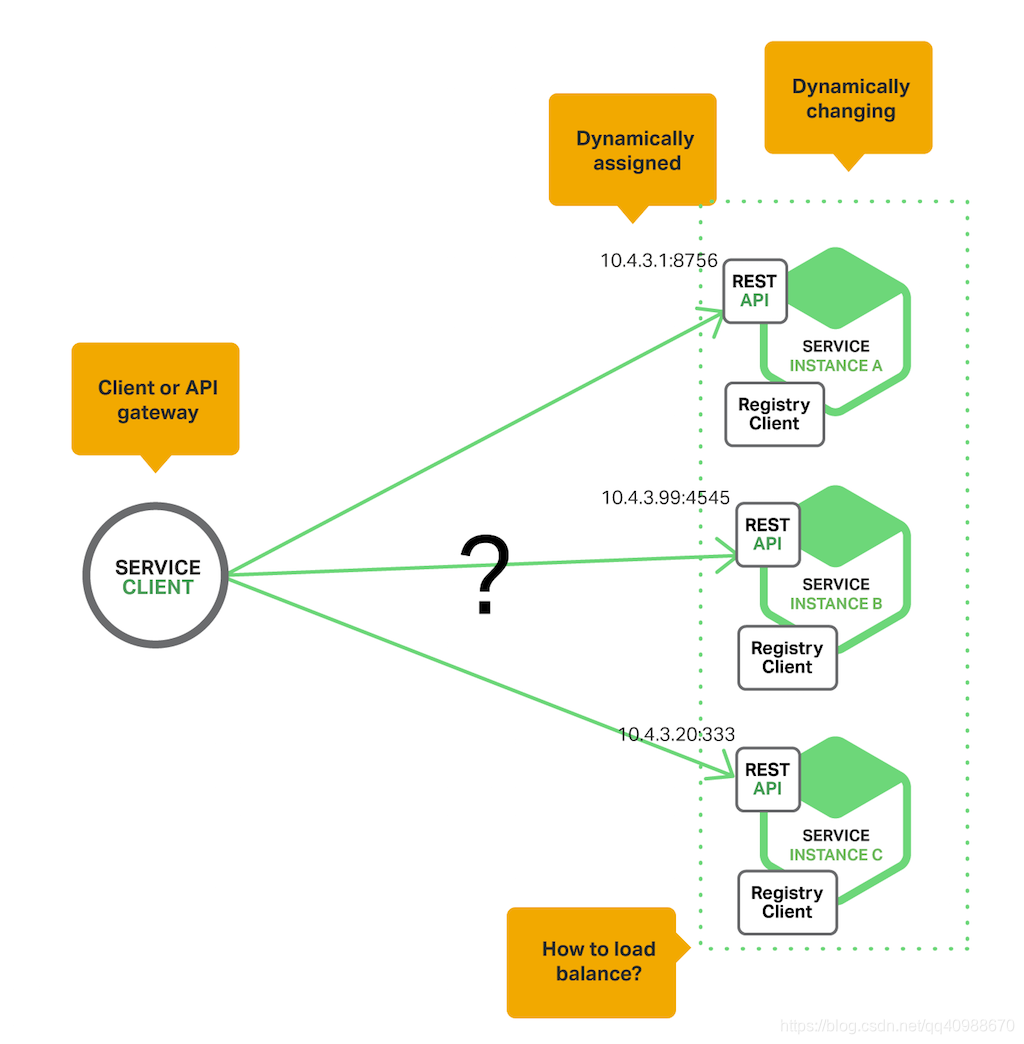
为了解决这个问题,引入了一个叫“服务发现”的机制。
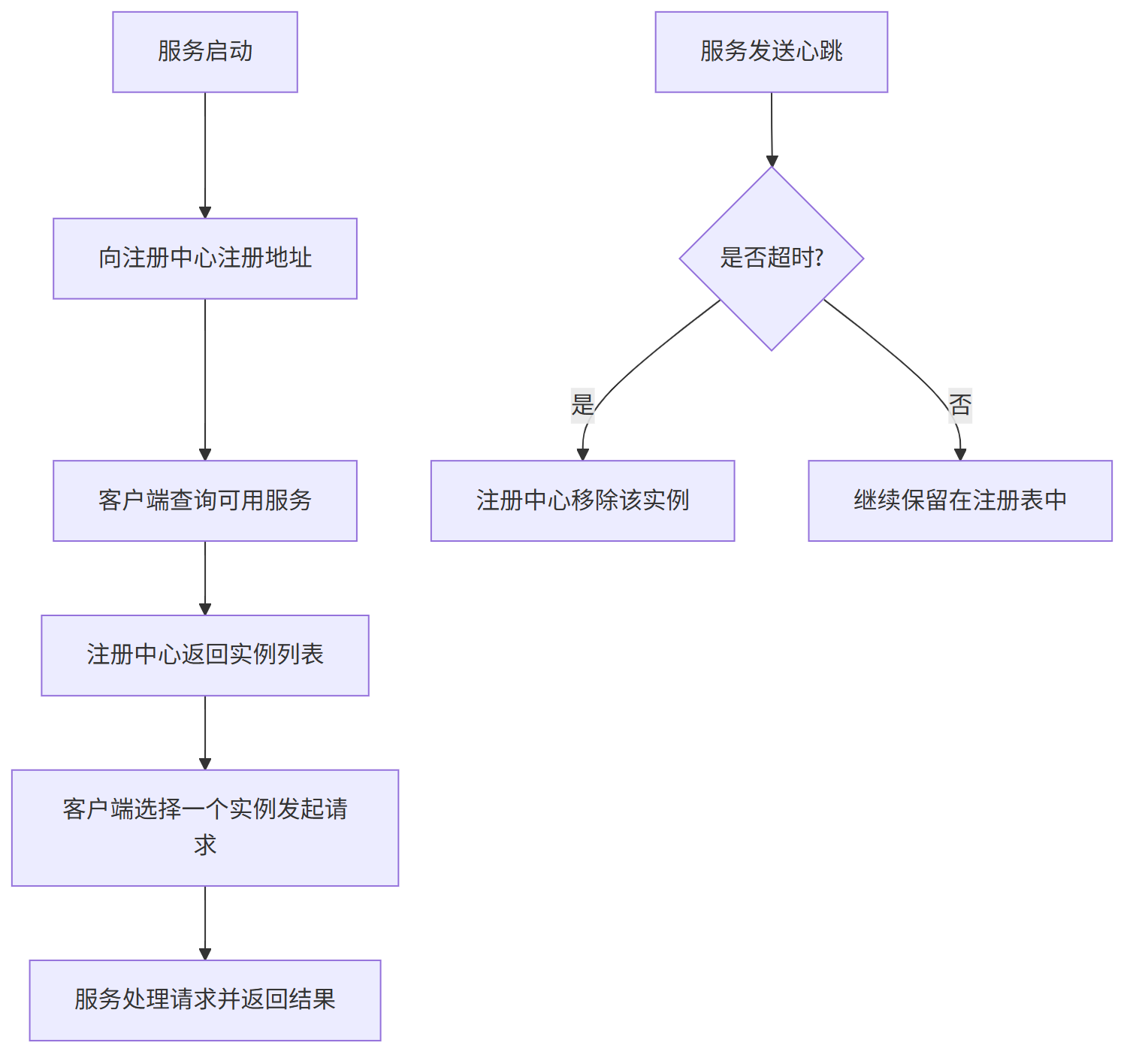
具体流程如下:
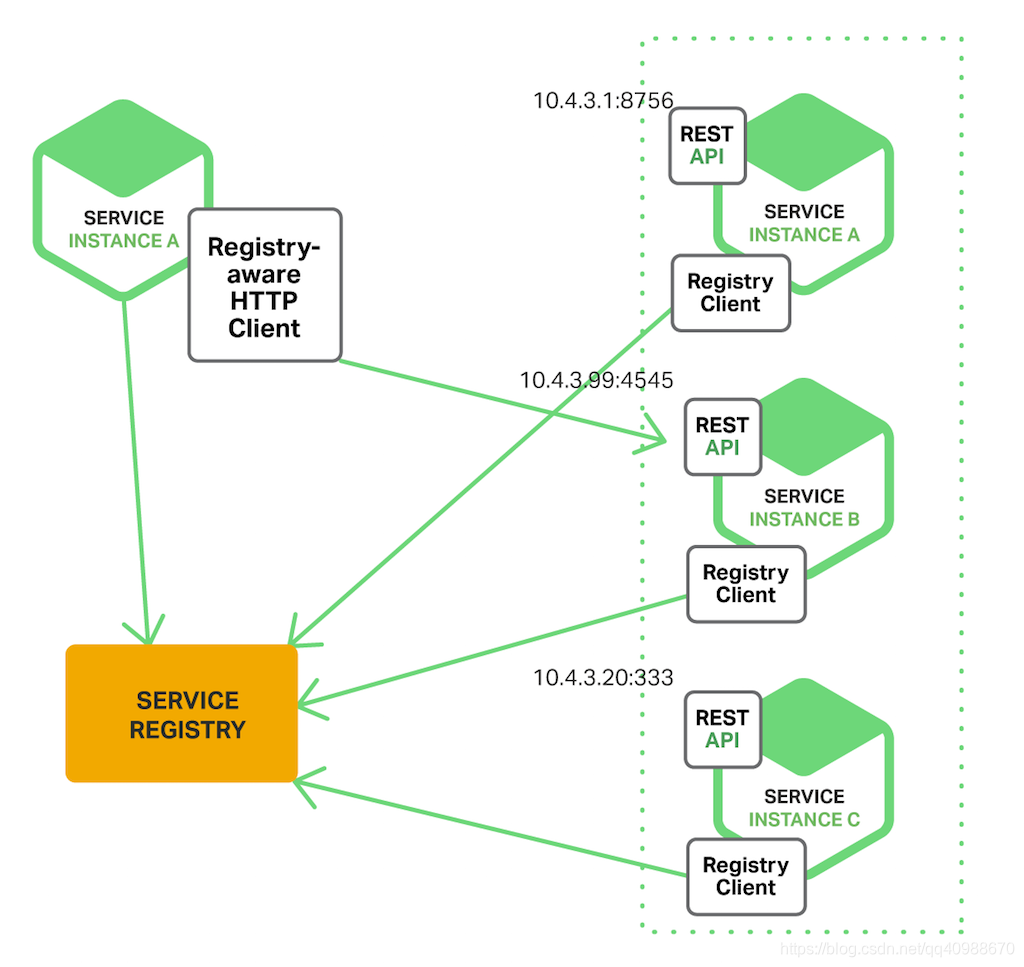
(1) 服务注册:每个服务启动后,会把自己的网络地址告诉一个叫“服务注册中心”的地方。
(2) 定期更新:服务会定时发送“心跳”来告诉注册中心自己还活着。
(3) 服务下线:如果服务停止或者出问题,注册中心会把它从列表中移除。
(4) 客户端查询:当其他服务想调用它时,先去注册中心获取可用的服务地址。
(5) 负载均衡:客户端从多个可用实例中选一个,发起请求。
这样即使服务地址经常变,也能保证请求能正确发到可用的服务上。
- 微服务环境下,服务地址不固定。
- 需要通过“服务注册中心”动态管理服务位置。
- 客户端通过查询注册中心 + 负载均衡,实现对服务的可靠调用。
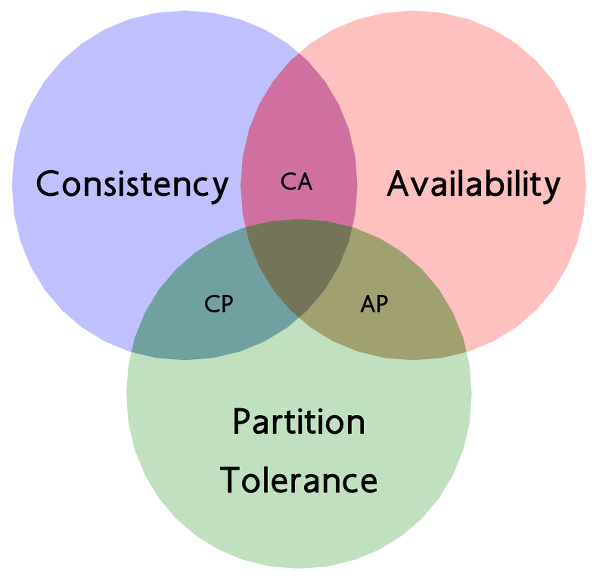
CAP 理论
CAP 理论是分布式系统中最基础、最重要的理论之一。
它最早由加州大学的 Eric Brewer 在 1998 年提出,后来在 2000 年他提出了一个猜想:一致性(C)、可用性(A)、分区容错性(P)这三项,在分布式系统中无法同时满足。
这个猜想在 2002 年被麻省理工的两位科学家 Seth Gilbert 和 Nancy Lynch 从理论上证明成立,从此被称为 CAP 定理。
CAP 是哪三个指标?
CAP 指的是:
- C(Consistency)一致性:所有节点看到的数据都是一样的。
- A(Availability)可用性:每次请求都能得到响应。
- P(Partition Tolerance)分区容错性:网络出问题时,系统还能继续工作。
它们不能三者兼得,只能选两个。
C:一致性是什么意思?
你刚写进去的数据,马上就能读出来。
比如你在 Node1 写入了 V1,别人访问 Node2 也能立刻读到 V1。
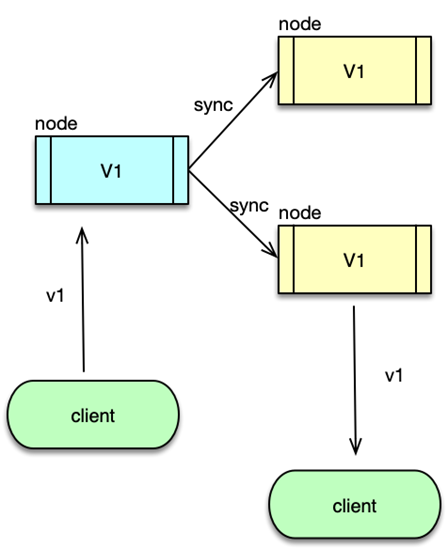
A:可用性是什么意思?
不管什么时候发请求,系统都会给你一个回应,哪怕不是最新的数据,也不能不回。
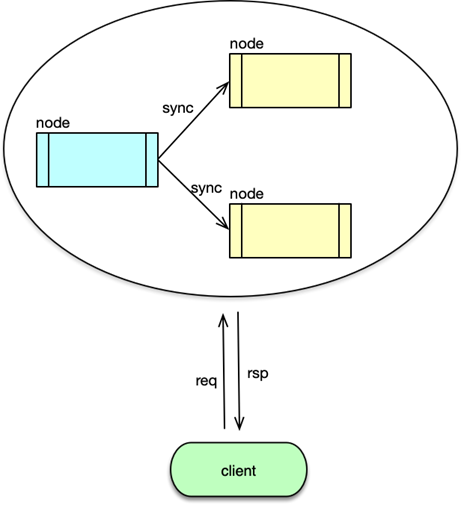
P:分区容错性是什么意思?
就是当网络断了、部分节点失联时,系统仍然能对外提供服务。
正常情况下的运行
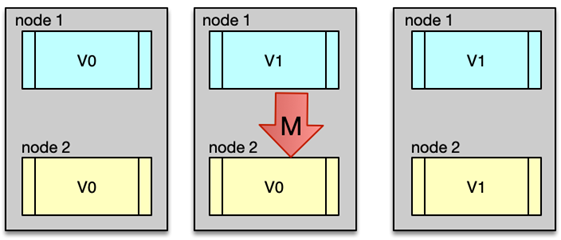
假设我们有两个节点 Node1 和 Node2,初始数据都是 V0。
- 用户向 Node1 更新为 V1;
- Node1 把更新同步给 Node2;
- Node2 成功更新为 V1;
- 这时候无论访问哪个节点,都能读到 V1。
这样就同时满足了 C、A、P。
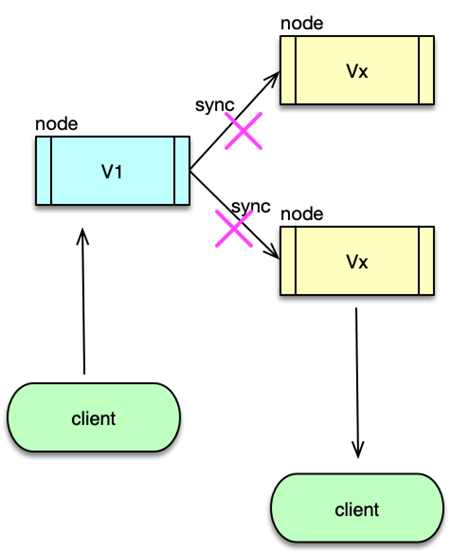
网络异常时的情况
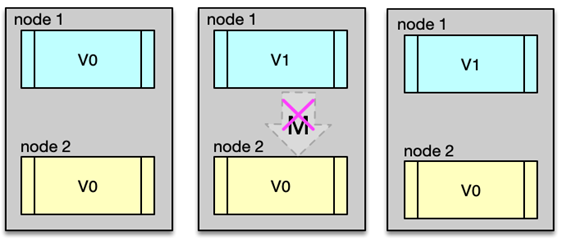
现在 Node1 和 Node2 之间的网络断开了。
用户向 Node1 写入 V1;
Node2 不知道这个变化,还是 V0;
如果用户访问 Node2:
- 要么返回旧数据 V0(牺牲一致性);
- 要么一直等直到恢复(牺牲可用性);
所以,只要支持分区容错(P),就必须在一致性和可用性之间做选择。
CAP 的三种组合方式
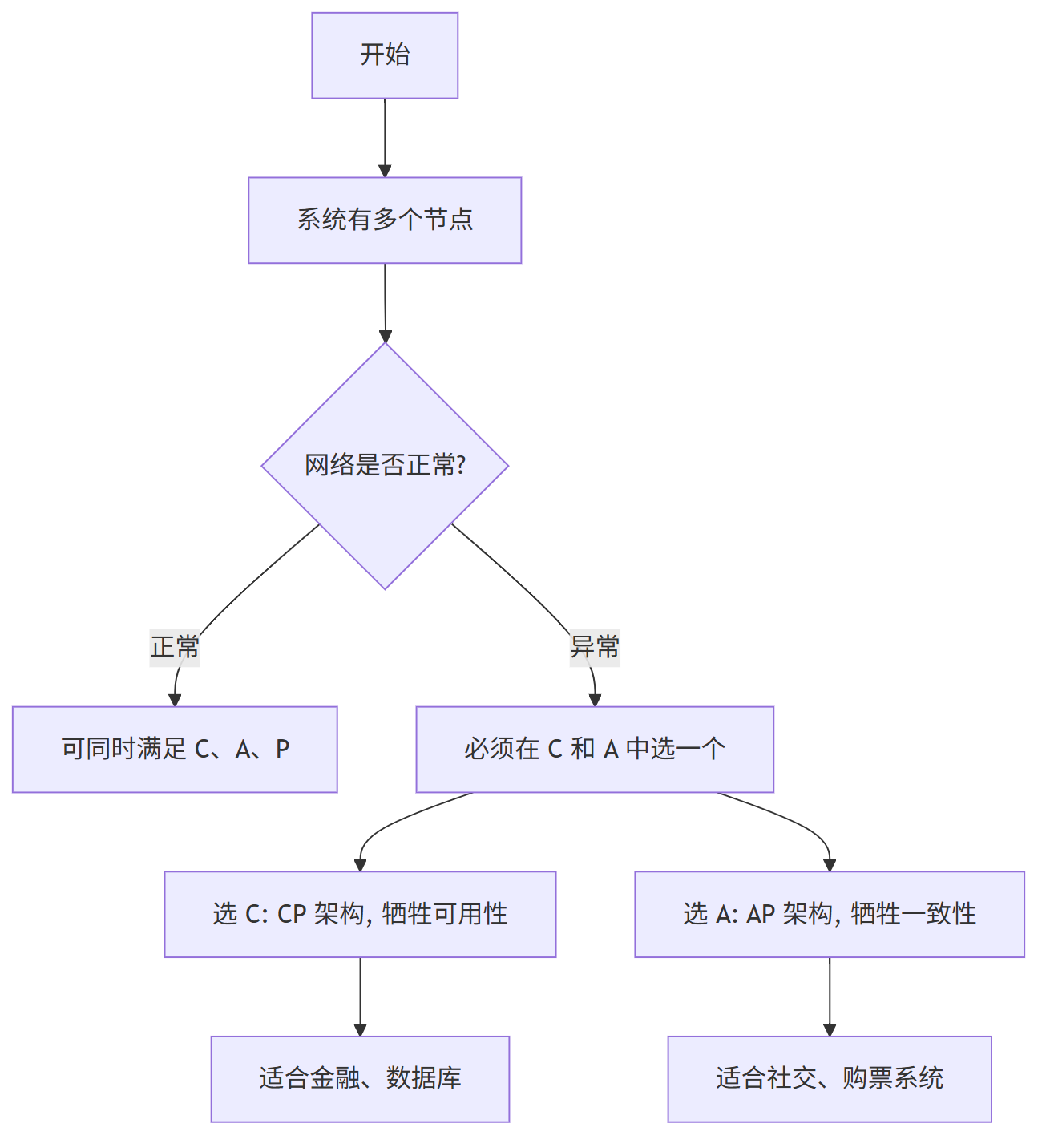
CA 架构(放弃 P)
- 系统只保证一致性和可用性;
- 前提是网络永远正常;
- 实际上很少用,因为网络不可能不出问题。
CP 架构(放弃 A)
- 遇到网络问题时,宁愿暂停服务也要保证数据一致;
- 常用于对数据准确性要求高的场景,如银行交易、数据库。
AP 架构(放弃 C)
- 遇到网络问题时,先保证服务能用,数据可以暂时不一致;
- 常见于社交平台、购票系统等对用户体验更敏感的场景。
CAP 的常见误解和实际应用
误区一:CAP 是非黑即白的选择
实际上,很多系统并不是完全选 C 或 A,而是根据业务阶段灵活调整。
例如:
- 查票时可以用 AP;
- 支付时必须用 CP。
误区二:没有考虑延迟和弱一致性
CAP 只讲了“是否满足”,但现实中有很多中间状态:
- 数据可以慢慢同步(最终一致性);
- 有些功能可用,有些不可用;
- 网络延迟也可以看作一种“轻度分区”。
误区三:CAP 不适用于所有场景
CAP 是理想模型,实际系统要考虑更多因素,比如性能、成本、业务逻辑等。
总结一句话:
在分布式系统中,网络出问题是常态,所以必须支持分区容错(P)。
这就意味着,只能在**一致性(C)和可用性(A)**之间做取舍,不能三者都要。
CP 型 服务发现 : ZooKeeper
ZooKeeper 服务发现 流程分析
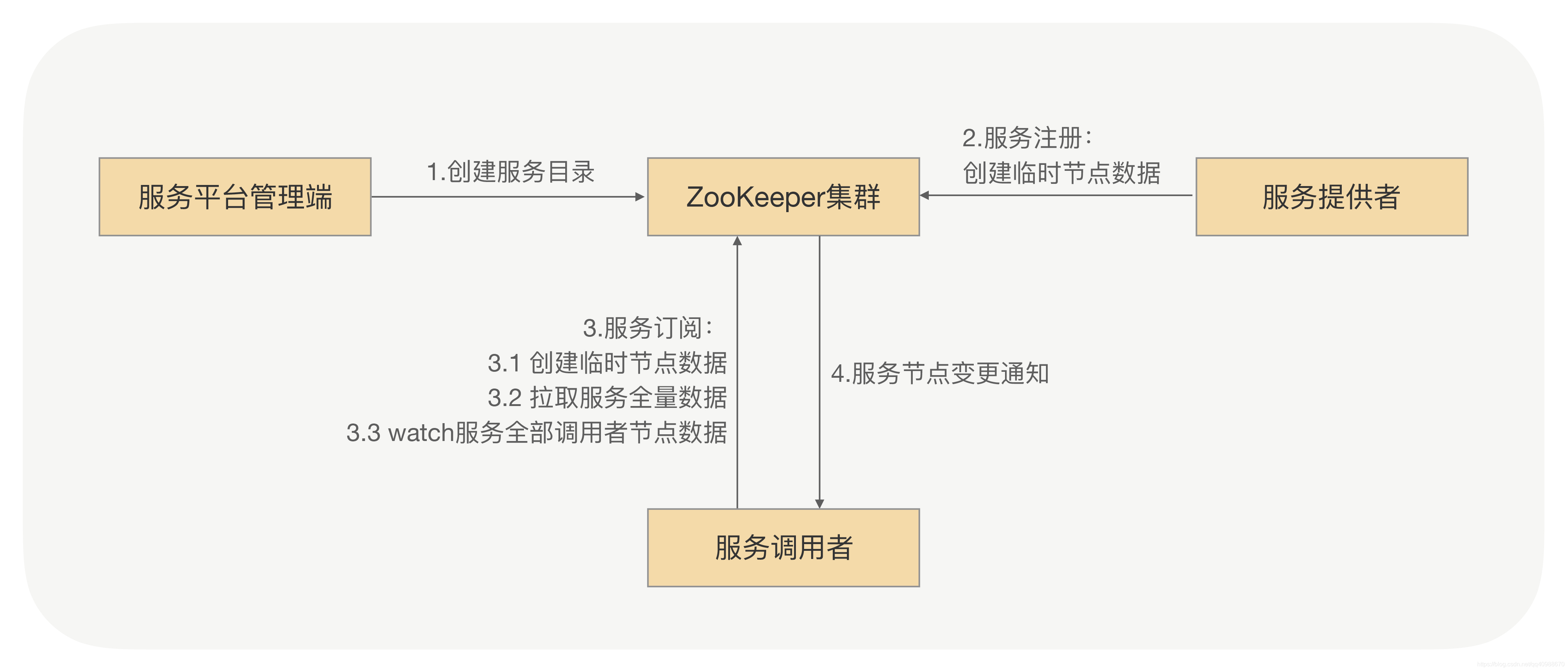
(1) 服务元数据znode
服务管理端先在 ZooKeeper 上建一个根目录,比如按接口名来命名:/dubbo/com.foo.BarService。
在这个目录下再建两个子目录:providers(放服务提供方信息)和 consumers(放服务调用方信息)。
2.服务注册
服务提供方注册时,会在 providers 目录下创建一个临时节点,里面记录自己的地址等信息。
用临时节点是因为如果服务挂了,ZooKeeper 会自动把这个节点删掉,表示这台服务不可用了。
(3) 服务订阅
服务调用方订阅服务时,会在 consumers 目录下创建一个临时节点,记录自己是谁。
同时它还会“监听”providers 目录下的所有节点变化。
(5) 服务通知
当有服务提供方上线或下线时,ZooKeeper 就会通知所有监听该服务的调用方,让它们知道最新的服务状态。
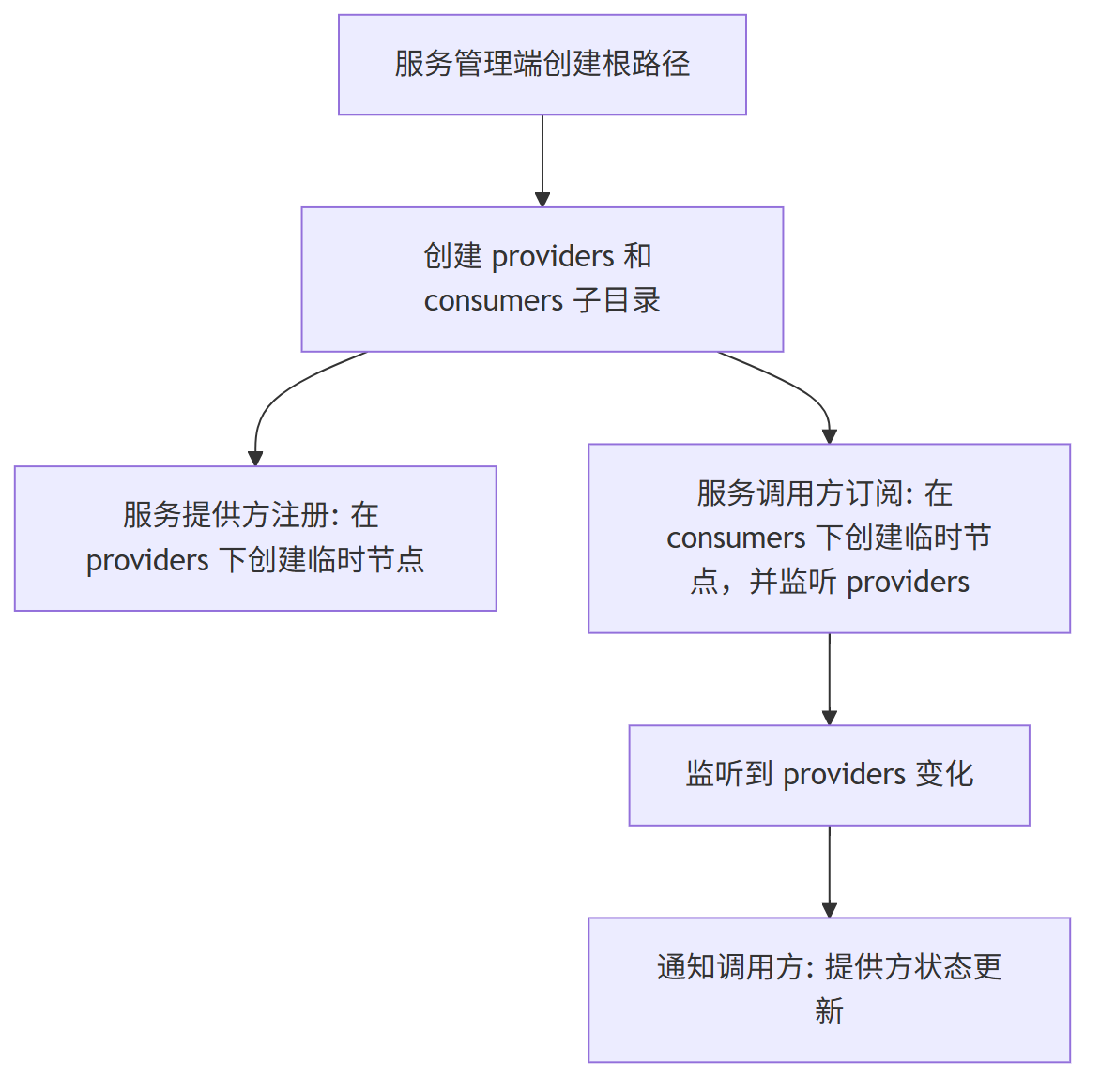
通过 ZooKeeper 的临时节点和监听机制,服务提供方和调用方可以自动感知彼此的状态变化,实现服务的注册与发现。
ZooKeeper 服务发现 存在的问题
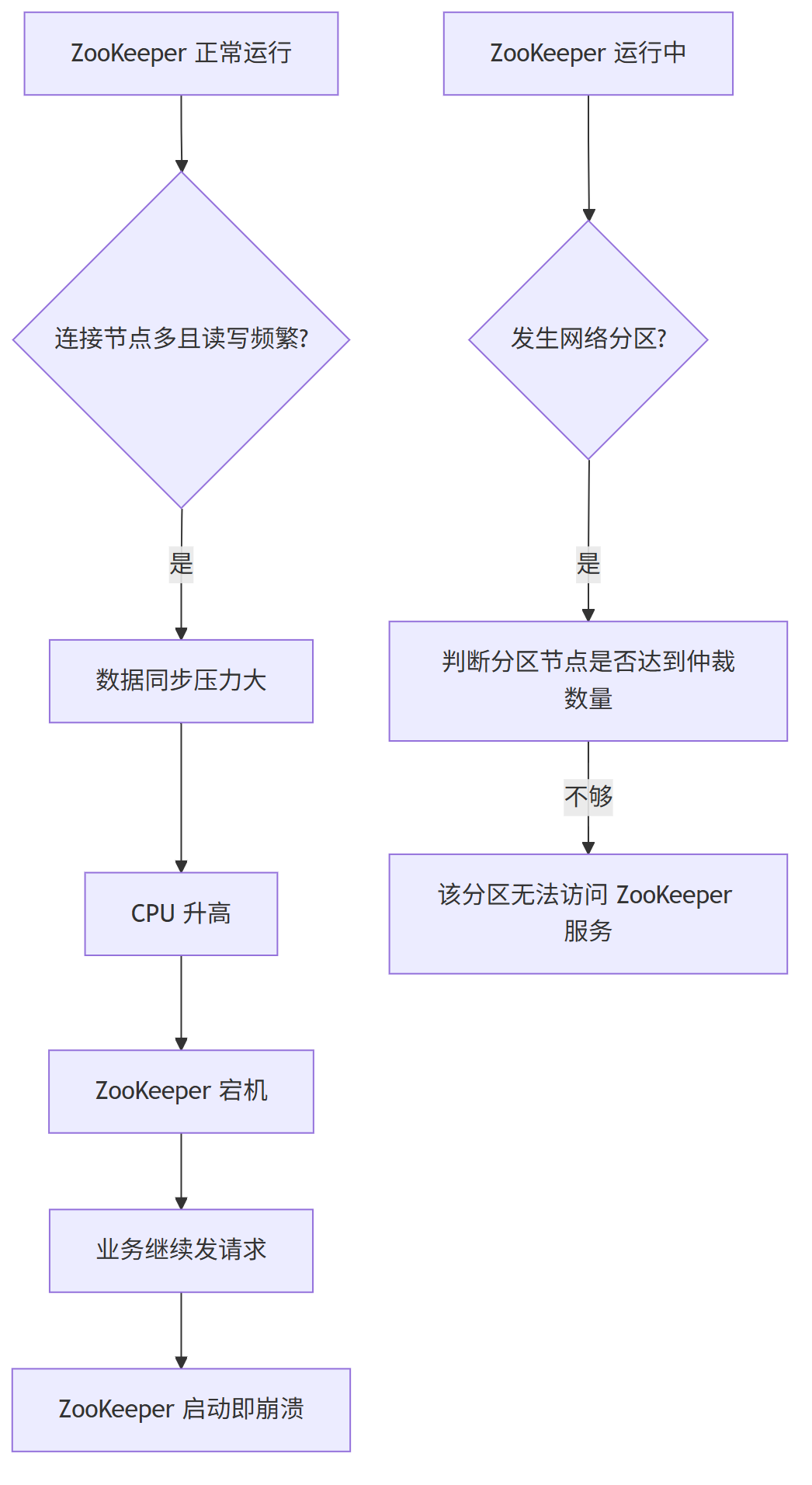
问题一:
ZooKeeper 的一个特点是数据强一致,也就是说,只要有一个节点更新了数据,所有其他节点都会同步更新。
但这也带来一个问题:当连接的节点很多、读写频繁,并且存储的数据目录太多时,ZooKeeper 会变得很吃力,CPU 使用率飙升,最终可能直接崩溃。
更麻烦的是,一旦 ZooKeeper 宕机重启,那些还在不断发送请求的业务系统会瞬间给它很大压力,导致刚启动就再次崩溃。
问题二:
ZooKeeper 在遇到网络分区时处理不好服务发现的问题。
如果某个区域内的 ZooKeeper 节点数量不够多(达不到半数以上),这个区域的客户端就完全无法使用 ZooKeeper 的服务发现功能。
基于 Eureka 的服务发现(AP)
Eureka 服务发现 流程分析
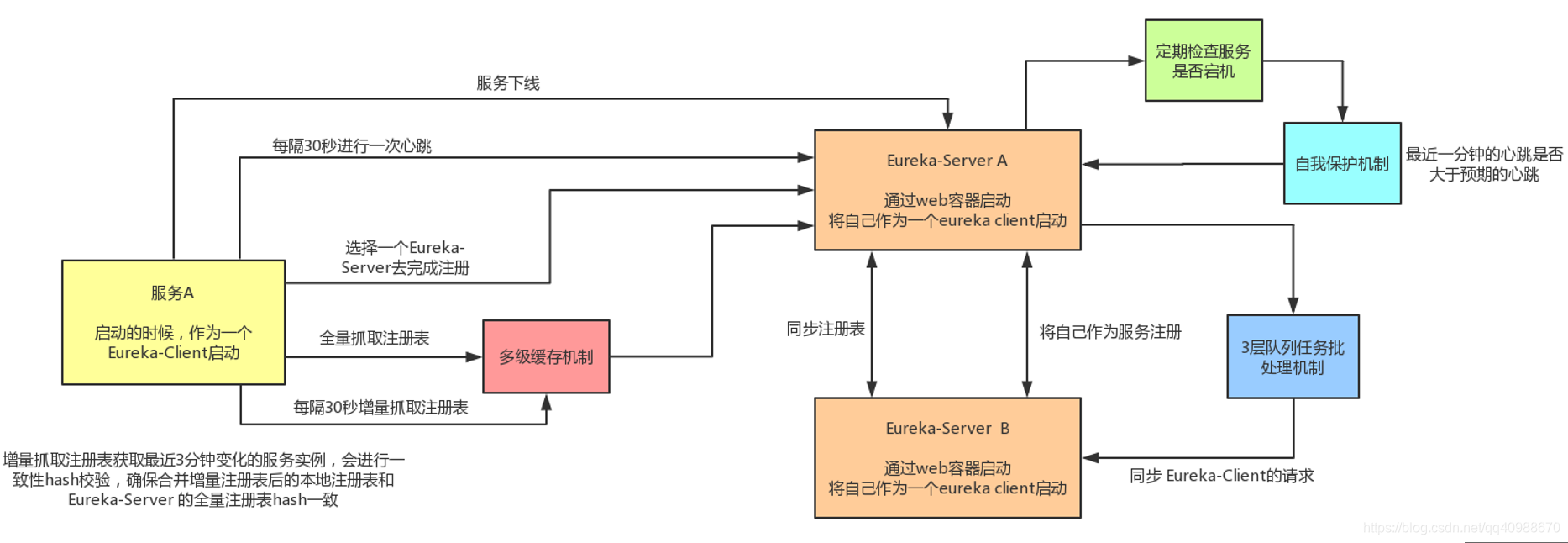
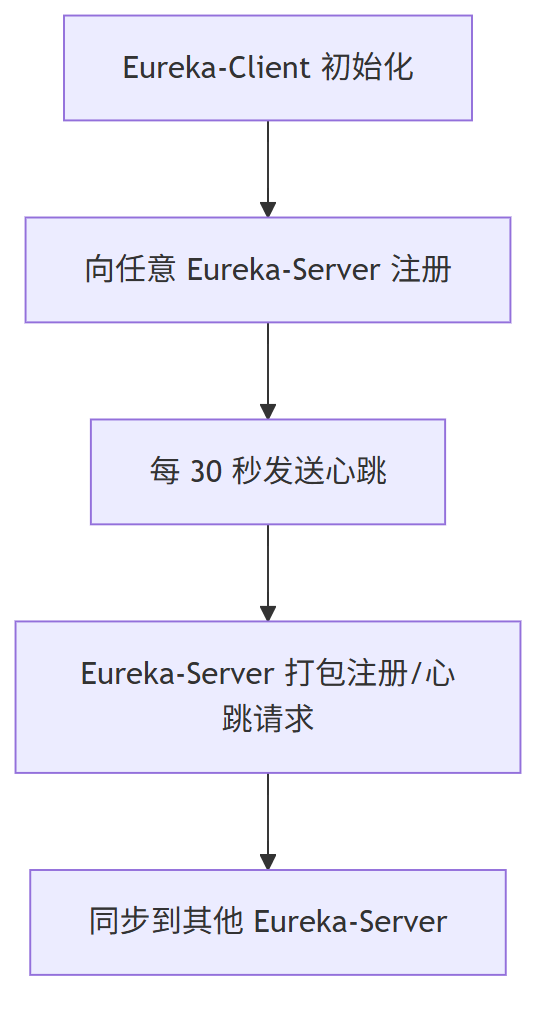
(1) Eureka-Client 启动时
会把自己注册到一个 Eureka-Server 上,并且每 30 秒发一次心跳,告诉服务器自己还活着。
(2) Eureka-Server 处理
(3) 接收到注册或心跳的 Eureka-Server 会把这些信息打包,统一同步给其他 Eureka-Server,保证所有服务器数据一致。
- Eureka-Client:就是你的服务应用。
- Eureka-Server:是服务的“登记处”,用来记录有哪些服务在运行。
- Client 会定时上报状态,Server 之间会互相通知更新,保持信息一致。
Eureka 服务发现 存在的问题
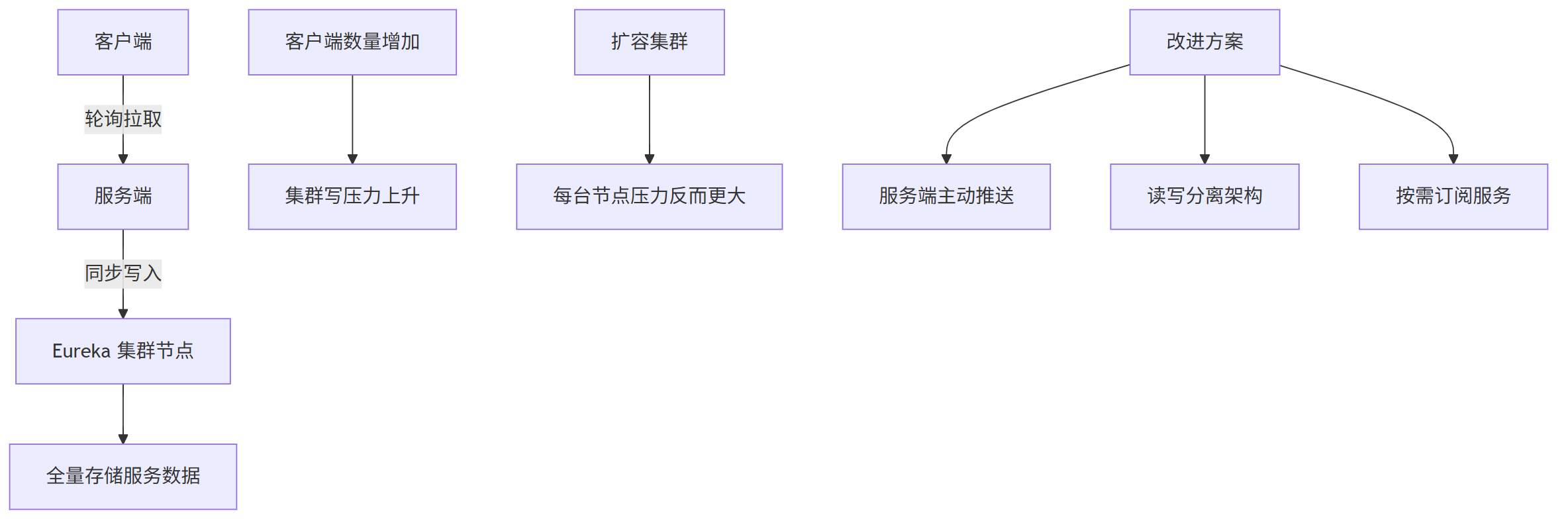
问题一:客户端拿到太多不需要的服务地址
客户端会拿到所有服务的地址列表,不管这些服务是不是自己需要的。
这会浪费很多内存资源,特别是在多个数据中心部署的情况下,本地客户端其实只需要访问本地的数据中心服务就够了。
问题二:客户端靠定时拉取更新数据,效率低
客户端是通过定时轮询的方式从服务端获取服务信息的。
这种方式有两个问题:
- 数据更新不及时,有延迟;
- 即使没有变化,也会不断拉取,浪费性能。
问题三:Eureka 集群一致性机制压力大
Eureka 集群中,每个节点都会把收到的写操作同步给其他所有节点(包括心跳信息)。
这种设计带来几个问题:
- 每个节点都要存全部数据,内存容易撑不住;
- 客户端越多,集群写压力越大,扩容效果差;
- 所有节点配置必须一致,只能靠升级硬件来应对增长。
扩展:Eureka 2.0 的改进方向
为了解决这些问题,Eureka 2.0 提出了以下优化:
- 数据推送从“客户端主动拉”改为“服务端主动推”,并支持按需订阅具体服务;
- 写操作集中在稳定的小集群处理,读操作可以单独扩容;
- 增加了日志审计和更强大的管理界面。
这套系统在早期设计上存在一些效率和扩展性上的问题,Eureka 2.0 就是在尝试解决这些痛点,让服务发现更高效、更灵活。
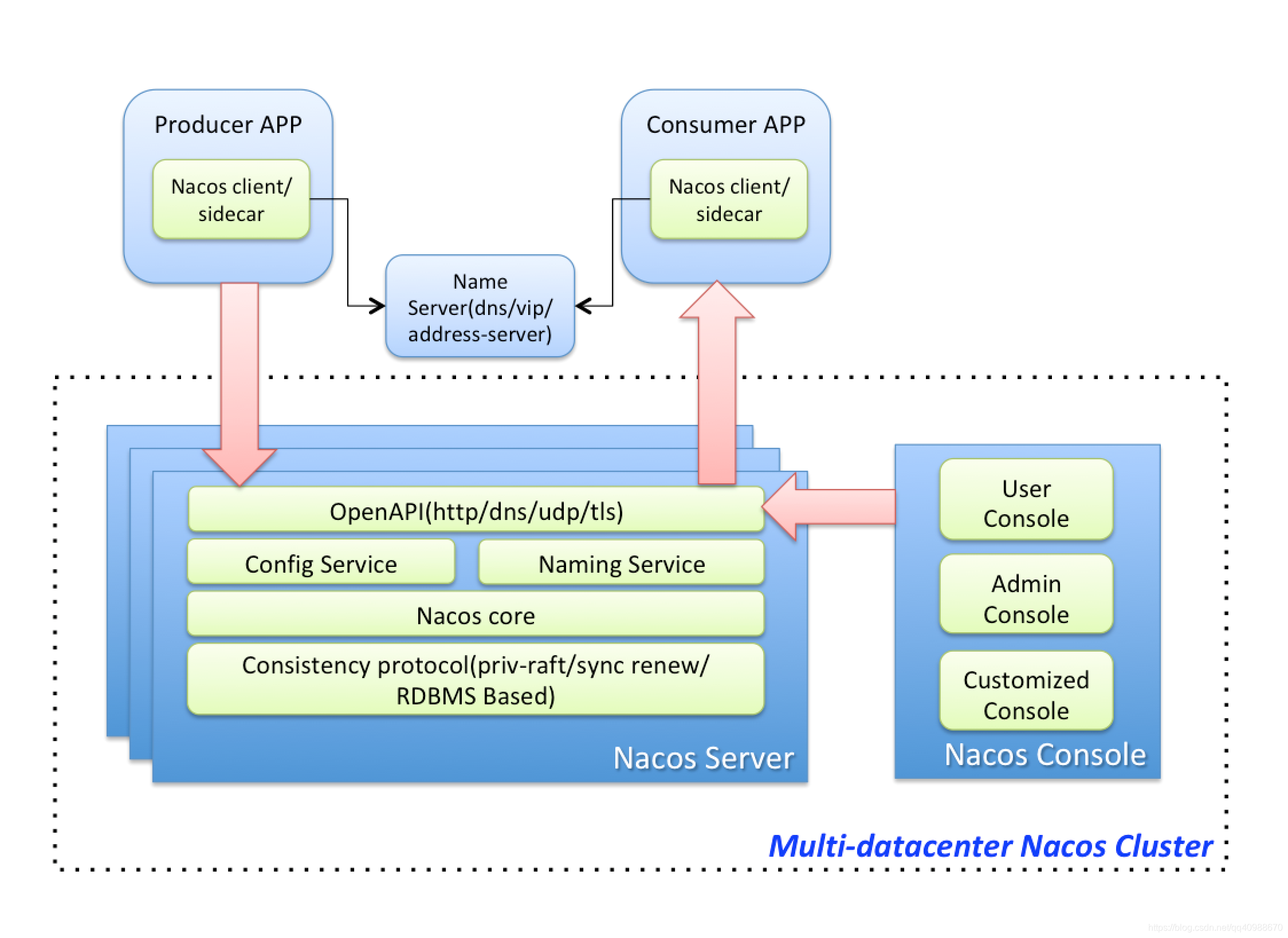
阿里 Nacos 的服务发现
和 Eureka 1.x 相比,Nacos 做了这些改进:
- 数据同步更高效:
不再一个一个同步数据,而是批量处理,通过长连接+定时更新来保持数据一致;
- 按需推送数据:
客户端只订阅自己关心的服务信息,服务端只推送这部分数据;
- 双集群结构:
把集群分成两部分,一部分接收注册信息(session 集群),另一部分做数据汇总和压缩(data 集群),然后把整理好的数据再推回 session 层缓存,客户端直接从这里获取数据。
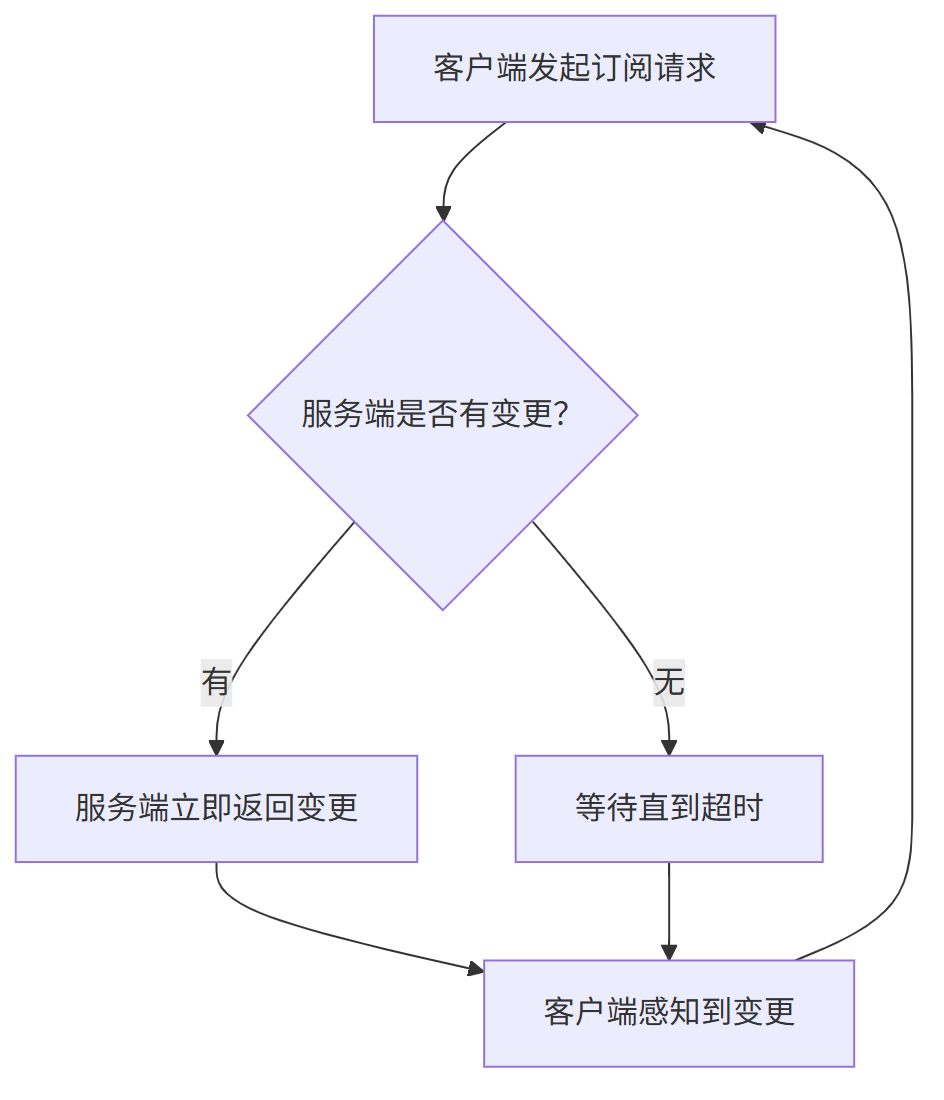
Nacos 的“推送”机制其实是“伪推送”:
虽然看起来像服务端主动推给客户端,其实还是客户端在不断拉取。
流程如下:
(1) 客户端每隔30秒请求一次服务端,看有没有配置变化;
(2) 如果有变化,服务端立刻返回结果;
(3) 客户端收到响应,就知道配置变了。
总结要点:
- 数据同步方式升级,效率更高;
- 客户端只关注自己需要的数据;
- 架构分层清晰,扩展性更强;
- 推送是假的,其实是客户端轮询拉取,但响应快,看起来像推送。
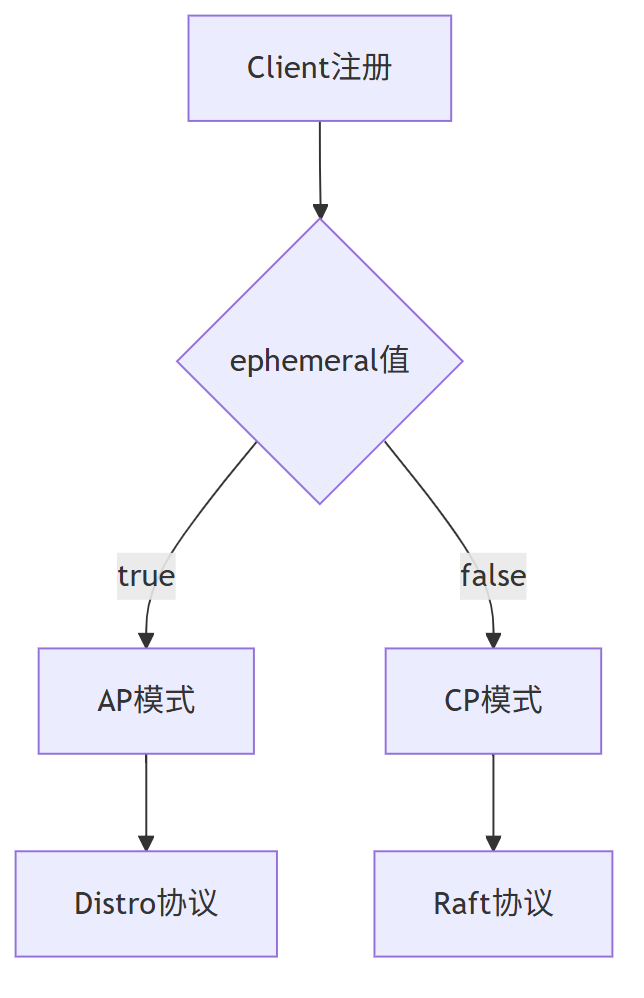
Nacos 满足AP,又满足CP
平台篇幅限制,原始的内容,请参考 本文 的 原文 地址
本文作者:
- 第一作者 老架构师 肖恩(肖恩 是尼恩团队 高级架构师,负责写此文的第一稿,初稿 )
- 第二作者 老架构师 尼恩 (45岁老架构师, 负责 提升此文的 技术高度,让大家有一种 俯视 技术、俯瞰技术、 技术自由 的感觉)

















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









