




本文 的 原文 地址
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型 应用 架构师。接下来,尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
-
《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
-
《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
-
《Spring AI 学习圣经 和配套视频 》
-
《AI部署架构:A100、H100、A800、H800、H20的差异以及如何选型?开发、测试、生产环境如何进行部署架构?》
常用的向量数据库
向量数据库, 是一种专门用于存储和查询向量数据的数据库。
向量数据, 也就是embedding向量。
向量数据, 典型结构是一个 一维教组 ,教组 中的元素是数值(通常是浮点数)。
这些数值, 表示对象或数据 在多维空间中的 位置、特征或属性。
向量数据库的主要功能
- 管理:向量数据库以原始数据形式处理数据,能够有效地组织和管理数据,便于AI模型应用。
- 存储:能够存储向量数据,包括各种AI模型需要使用到的高维数据。
- 检索:向量数据库特别擅长高效地检索数据,这一个特点能够确保AI模型在需要的时候快速获得所需的数据。这也是向量数据库能够在一些推荐系统或者检索系统中得到应用的重要原因。
向量数据库的主要优点是,它允许基于数据的向量距离或相似性进行快速准确的相似性搜索和检索。
这意味着,可以使用向量数据库,根据其语义或上下文含义查找最相似或最相关的数据,而不是使用基于精确匹配或预定义标准 查询数据库 的传统方法。
向量数据库可以搜索非结构化数据,但也可以处理半结构化甚至结构化数据。例如,可以使用向量数据库执行以下操作,根据视觉内容和风格查找与给定图像相似的图像,根据主题和情感查找与给定文档相似的文档,以及根据功能和评级查找与给定产品相似的产品。
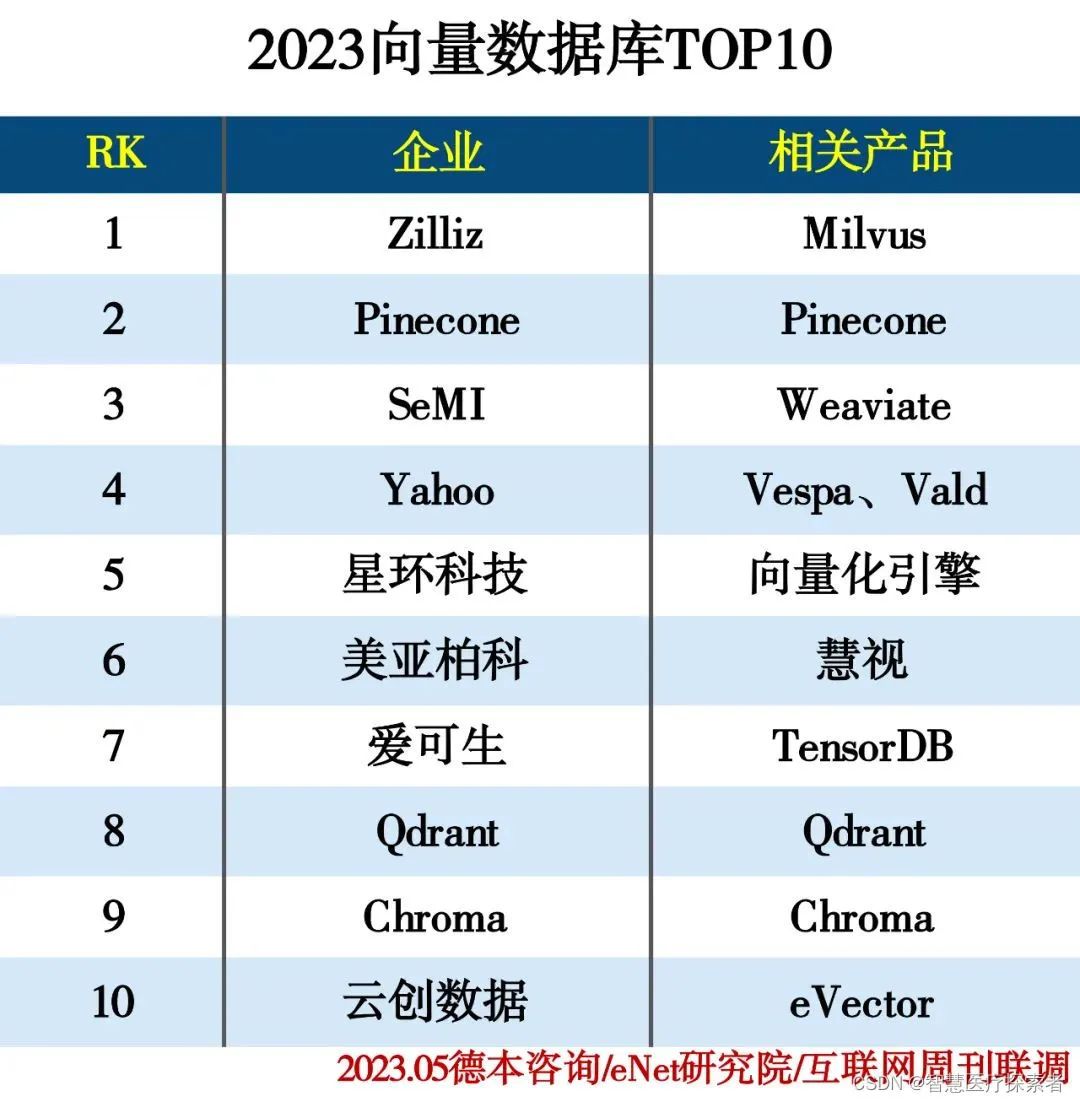
2023 向量数据排名
常用的向量数据库 对比
| 维度 | Elasticsearch | Milvus | Pinecone | FAISS | Chroma | PGVector | Weaviate | Qdrant |
|---|---|---|---|---|---|---|---|---|
| 架构 | 分布式,多节点 | 分布式,云原生 | 全托管 Serverless | 单机库 | 单机/轻量集群 | PostgreSQL 扩展 | 分布式(实验性) | 分布式,云原生 |
| 索引算法 | HNSW, IVF | IVF/HNSW/DiskANN | 自动优化 | IVF/PQ/HNSW | HNSW | IVFFlat, HNSW | HNSW, IVF | HNSW, DiskANN |
| 扩展性 | 高(分片与副本) | 极高(动态扩缩容) | 自动扩展 | 需手动分片 | 低 | 依赖 PostgreSQL | 中(分片支持) | 高(自动分片) |
| 部署复杂度 | 中等(需集群管理) | 高(需 K8s 运维) | 无需部署 | 低(仅库集成) | 极低 | 低(PG 扩展) | 中等(模块配置) | 中等(需 Rust 生态) |
| 查询性能 | 中等(百万级 ms 级) | 高(十亿级 <50ms) | 高(十亿级 <100ms) | 极高(无网络) | 低(百万级) | 中等(千万级) | 中高(多模态影响) | 极高(内存优化) |
| 多模态支持 | 强(文本+向量) | 中(需外部工具) | 中(稀疏+稠密向量) | 无 | 弱 | 中(SQL 扩展) | 强(内置模型) | 弱(需自定义) |
| 社区生态 | 极活跃(企业支持) | 活跃(开源+商业版) | 商业支持 | 活跃(Meta) | 小众(AI 社区) | PostgreSQL 生态 | 成长中(开发者驱动) | 新兴(Rust 社区) |
| 成本 | 中(自建集群) | 中(自建)或高(Zilliz) | 高(按需计费) | 低 | 极低 | 低(基于 PG) | 中(自建) | 低(开源) |
1 Elasticsearch
基于 Apache Lucene 的分布式搜索与分析引擎,支持 全文检索、结构化数据查询 和 实时分析。通过倒排索引、分片、副本机制实现高可用性和扩展性,广泛应用于日志分析、电商搜索、安全监控等领域。
基本功能:
- 全文检索:支持分词、模糊匹配、相关性评分(BM25)。
- 结构化查询:精确匹配、范围查询、布尔逻辑组合,基于 JSON 的复杂条件查询(如
age > 30 AND city = "Beijing") - 聚合分析:统计、分组、嵌套聚合。
- 向量检索:通过
dense_vector字段支持余弦/欧氏距离计算。
核心功能:
- 分布式架构:数据分片(Shard)与副本(Replica)实现水平扩展。
- 近实时搜索:数据写入后 1 秒内可检索。
- 混合查询:文本与向量联合检索(如电商商品搜索)。
技术特点:
- 底层引擎:基于 C++ 的高性能 Lucene 库,优化内存管理和查询速度。
- 倒排索引:快速定位关键词,支持动态更新,将文档内容拆分为词项(Term),反向映射到包含该词项的文档列表。
- 插件生态:支持中文 IK 分词器、英文语义分析(Word2Vec 等)、安全认证、机器学习扩展。
- RESTful API:通过 HTTP 接口与 Kibana 可视化集成。
- 跨平台支持:Docker/Kubernetes 部署,兼容 Windows/Linux/macOS。
性能分析:
- 写入吞吐:单节点 10k-50k docs/s(依赖文档大小)。
- 查询延迟:简单查询毫秒级,复杂聚合秒级。
- 向量检索:百万级向量延迟 10-50ms,性能弱于专用库。
应用场景:
- 电商搜索、日志管理(ELK 栈)、安全分析。
优缺点:
- 优点:生态完善、混合查询能力强、高可用。
- 缺点:资源消耗高、向量性能有限、运维复杂。
2 Milvus
开源分布式向量数据库,专为十亿级向量设计,高维向量相似度检索,支持多模态数据(图像、视频、文本),支持 GPU 加速,专注于适用于 AI 推荐系统、语义搜索、图像/视频检索等领域。
基本功能:
- 向量检索:支持欧氏距离、内积、余弦相似度。
- 标量过滤:结合数值/文本条件筛选结果。
核心功能:
- 多种索引:IVF_FLAT、HNSW、ANNOY、DiskANN(磁盘索引)。
- 分布式架构:支持水平扩展与动态扩缩容。
- 多模态扩展:需结合其他工具(如 Elasticsearch)实现文本检索。
技术特点:
- 计算分离:存储与计算节点分离,支持云原生部署。
- 数据版本化:支持时间旅行查询(Time Travel)。
- GPU 加速:基于 CUDA 的索引构建与查询优化。
性能分析:
- 十亿级向量:HNSW 索引下查询延迟 <50ms(SSD 环境)。
- 吞吐量:单节点支持 10k QPS(依赖索引类型)。
应用场景:
- 图像/视频检索、推荐系统、生物基因分析。
优缺点:
- 优点:高性能、扩展性强、开源社区活跃。
- 缺点:运维复杂、需额外处理元数据管理。
3 Pinecone
全托管云原生向量数据库,提供Serverless架构,支持实时向量相似性搜索和多模态数据处理,集成 OpenAI、Hugging Face 等工具链,无需管理基础设施,适合中小型企业快速部署。
基本功能:
- 向量检索:低延迟相似度搜索。
- 元数据过滤:结合键值对条件筛选结果。
核心功能:
- 自动索引优化:根据数据分布动态调整索引参数。
- Serverless 架构:按需扩展资源,无冷启动延迟。
技术特点:
- 混合向量:支持稀疏向量(如 BM25 编码)与稠密向量联合检索。
- 私有网络:数据加密与 VPC 隔离保障安全。
性能分析:
- 延迟:99% 查询 <100ms(十亿级数据)。
- 可用性:SLA 99.9%,自动容灾。
应用场景:
- 快速原型开发、中小规模推荐系统。
- 推荐系统:实时用户行为向量匹配(如短视频推荐)。
- RAG(检索增强生成):结合文档库和生成式模型提升问答质量。
- 多模态检索:图像+文本联合搜索(如电商商品图+描述)。
优缺点:
- 优点:免运维、低延迟、API 驱动。
- 缺点:闭源、成本高(0.1/GB/月+0.1/GB/月+0.01/次查询)。
4 FAISS
Facebook 开源的高效相似度搜索库,需自行处理持久化与分布式扩展。
基本功能:
- 近似最近邻搜索(ANN):支持多种距离度量(欧氏、余弦、内积)。
- 向量索引:提供倒排文件索引(IVF)、小世界网络构建多层次索引(HNSW)、LSH 等算法,适配稠密/稀疏向量。
- 聚类分析:通过 K-means、Faiss-CPU 实现向量分组。
- 量化压缩:减少内存占用(如 INT8 量化可将内存降低 4 倍)。
核心功能:
- GPU 加速:基于 CUDA 实现并行计算。
- 量化压缩:乘积量化(PQ)降低内存占用。
技术特点:
- 单机库:无分布式、事务、高可用等数据库功能。
- 轻量集成:可作为其他系统(如 Milvus)的底层引擎。
性能分析:
- 十亿级向量:GPU 加速下查询延迟 <10ms。
- 内存占用:PQ 压缩后内存减少 4-64 倍。
应用场景:
- 学术研究、小规模生产环境(需自建封装)。
优缺点:
- 优点:极致性能、轻量灵活。
- 缺点:无数据库功能、扩展性差。
5 Chroma
轻量级开源向量数据库,专注 AI 应用集成(如 LangChain、LlamaIndex)。
基本功能:
- 向量存储:支持本地或轻量云部署。
- 语义检索:与 NLP 模型集成(如 Sentence-BERT)。
- 混合查询:联合文本和向量条件检索(如
"apple" AND image_vector ≈ query_vector)。
核心功能:
- 简单 API:Python/JavaScript 客户端快速接入。
- AI 工具链集成:预置 LangChain 插件。
技术特点:
- 嵌入式模式:可内存运行,适合原型开发。
- 轻量持久化:基于 SQLite 或 ClickHouse 扩展。
性能分析:
- 规模限制:单机支持百万级向量,查询延迟 <100ms。
- 吞吐量:1k-5k QPS(依赖硬件)。
应用场景:
- 聊天机器人、小型知识库检索。
- 知识库问答:企业文档检索与智能问答。
- 语义搜索:新闻标题相似度匹配、学术论文查重。
优缺点:
- 优点:极简部署、AI 生态友好。
- 缺点:不支持分布式、功能单一。
6 PGVector
PostgreSQL 的向量检索扩展,支持 SQL 原生向量操作。
基本功能:
- 向量存储:将向量作为 PostgreSQL
vector类型存储,支持浮点数组。 - 相似度计算:支持点积、余弦相似度等计算(如
SELECT * FROM images WHERE dot_product(embedding, query_vector) > 0.5)。 - 混合查询:联合文本和向量条件(如
"cat" IN keywords AND embedding ∼ query_embedding)。
核心功能:
- SQL 集成:向量查询与关系型查询结合(如 JOIN 过滤)。
- 索引支持:IVFFlat、HNSW(PostgreSQL 16+)。
技术特点:
- 事务支持:ACID 兼容,适合复杂业务逻辑。
- 扩展性:依赖 PostgreSQL 集群(如 Citus 扩展)。
性能分析:
- 千万级向量:HNSW 索引下延迟 10-50ms。
- 十亿级挑战:需手动分库分表,性能下降显著。
应用场景:
- 已用 PostgreSQL 的企业扩展向量能力(如用户画像推荐)。
优缺点:
- 优点:SQL 生态无缝衔接、事务支持。
- 缺点:性能天花板低、调优复杂。
7 Weaviate
开源多模态向量数据库,内置 NLP/图像模型,支持语义检索与自动数据增强。
基本功能:
- 多模态检索:文本、图像、视频向量化与混合搜索。
- 语义理解:集成 BERT、CLIP 等模型生成向量。
核心功能:
- GraphQL API:灵活定义数据模式与查询逻辑。
- 自动分类:支持零样本分类(Zero-shot Learning)。
技术特点:
- 模块化设计:可插拔模型(如 OpenAI、HuggingFace)。
- 语义缓存:减少重复模型推理开销。
性能分析:
- 千万级向量:HNSW 索引延迟 20-100ms。
- 多模态扩展:图像+文本联合检索延迟增加 30-50%。
应用场景:
- 跨模态内容推荐、智能知识图谱。
优缺点:
- 优点:开箱即用多模态、模型集成灵活。
- 缺点:社区较小、分布式功能待完善。
8 Qdrant
开源高性能向量数据库,Rust 实现,专注低延迟与高吞吐。
基本功能:
- 向量检索:支持稀疏与稠密向量,基于 HNSW、IVF、Annoy 等算法实现毫秒级响应。。
- 条件过滤:结合 JSON 元数据筛选结果,通过标量条件缩小检索范围(如
price > 100 AND category = "electronics")。
核心功能:
- 分层存储:热数据内存缓存,冷数据磁盘存储。
- 动态负载均衡:自动分配分片与副本。
技术特点:
- Rust 高性能:无 GC 延迟,内存安全。
- 云原生设计:支持 Kubernetes 部署。
性能分析:
- 十亿级向量:磁盘索引(DiskANN)延迟 <100ms。
- 吞吐量:单节点 15k QPS(内存索引)。
应用场景:
- 广告推荐、实时反欺诈检测。
优缺点:
- 优点:极致性能、开源免费。
- 缺点:生态较新、多模态支持有限。
Milvus Docker compose安装部署
在安装Milvus之前,检查硬件和软件是否符合要求。
硬件要求
| 组件 | 要求 | 推荐配置 | 备注 |
|---|---|---|---|
| CPU | - Intel第二代酷睿CPU或更高 - Apple Silicon | - 单机:4核或更多 - 集群:8核或更多 | |
| CPU指令集 | - SSE4.2 - AVX - AVX2 - AVX-512 | - SSE4.2 - AVX - AVX2 - AVX-512 | Milvus内的向量相似度搜索和索引构建需要CPU支持的单指令多数据(SIMD)扩展集。确保CPU至少支持其中一种SIMD扩展。请参阅支持AVX的CPU了解更多信息。 |
| RAM | 单机:8G - 集群:32G | 单机:16G - 集群:128G | RAM的大小取决于数据量。 |
| 硬盘 | SATA 3.0 SSD或更高 | NVMe SSD或更高 | 硬盘的大小取决于数据量。 |
软件要求
| 操作系统 | 软件 | 备注 |
|---|---|---|
| macOS 10.14或更高 | Docker Desktop | 将Docker虚拟机(VM)设置为使用至少2个虚拟CPU(vCPU)和8GB的初始内存。否则,可能安装失败。有关更多信息,请参见在Mac上安装Docker Desktop。 |
| Linux平台 | - Docker 19.03或更高 - Docker Compose 1.25.1或更高 | 有关更多信息,请参见安装Docker Engine和安装Docker Compose。 |
| 启用了WSL 2的Windows | Docker Desktop | 我们建议将源代码和其他数据绑定挂载到Linux容器中的Linux文件系统而不是Windows文件系统中。有关更多信息,请参见在启用了WSL 2的Windows上安装Docker Desktop。 |
| 软件 | 版本 | 备注 |
|---|---|---|
| etcd | 3.5.0 | 查看附加磁盘要求。 |
| MinIO | RELEASE.2023-03-20T20-16-18Z | |
| Pulsar | 2.8.2 |
Milvus 作为分布式向量数据库,其核心功能(数据管理、向量搜索)依赖于 etcd 和 MinIO 等组件的协作。以下是它们的职责分工和协作流程:
| 组件 | 角色 | 核心功能 | 类比 |
|---|---|---|---|
| Milvus | 向量数据库 | 向量数据存储、索引构建、相似性搜索 | 数据库引擎(如MySQL) |
| etcd | 元数据存储 | 存储集合、分片、节点状态等元信息 | 数据库的“目录系统” |
| MinIO | 对象存储 | 存储原始向量数据、索引文件等大文件 | 数据库的“硬盘” |
附加磁盘要求
磁盘性能对于etcd至关重要。强烈建议您使用本地NVMe SSD。
较慢的磁盘响应可能导致频繁的集群选举,最终会降低etcd服务的性能。
下载YAML文件
手动下载milvus-standalone-docker-compose.yml将其保存为docke
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









