




本文 原始 地址
文章目录
-
- 本文 原始 地址
- 尼恩:LLM大模型学习圣经PDF的起源
- Spring 整合 deepseek 模型 的三种方法
- DeepSeek是什么?
- 先看DeepSeek发展历程
- 再来看DeepSeek 产品
- DeepSeek 和 其他主流开源模型的对比
- 混合专家(MoE)架构 和 Transformer 的架构的区别
- Spring 整合 deepseek 模型 的三种方法
- 方法一:自定义 Client 集成DeepSeek
- 方法二:利用 spring-ai-openai 集成DeepSeek
- 方法三:用**Ollama** 实现本地化部署 DeepSeek, Spring AI 的 `spring-ai-ollama` 模块访问 DeepSeek
- **高级编程:通过chat API 接口 实现多轮对话**
- Spring AI、LangChain 、 LlamaIndex 三大框架对标
- 尼恩架构团队的大模型《LLM大模型学习圣经》
- **免费资料:小白 deepseek秒变高手!deepseek保姆级教程!**
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型 应用 架构师。接下来,尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
- 《Python学习圣经:从0到1精通Python,打好AI基础》
- 《LLM大模型学习圣经:从0到1吃透Transformer技术底座》
- 《LangChain学习圣经:从0到1精通LLM大模型应用开发的基础框架》
- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《SpringCloud + Python 混合微服务架构,打造AI分布式业务应用的技术底层》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
以上学习圣经 的 配套视频, 2025年 5月份之前发布。
Spring 整合 deepseek 模型 的三种方法
本文为 LLM大模型学习圣经PDF 系列文章中的一篇。

45岁老架构尼恩,由浅入深,给大家介绍一下 Spring如何整合 当前最为火热的 deepseek 模型,
分为三种方式:
- 方法一:自定义 Client 集成DeepSeek
- 方法二:利用 spring-ai-openai 集成DeepSeek
- 方法三:利用Ollama 实现本地化部署 DeepSeek, Spring AI 的
spring-ai-ollama模块访问 DeepSeek
DeepSeek是什么?
成立于2023年7月17日,由杭州知名量化资管巨头幻方量化创立,即深度求索,幻方量化为DeepSeek的技术研发提供了强大的硬件支持。
https://www.deepseek.com/
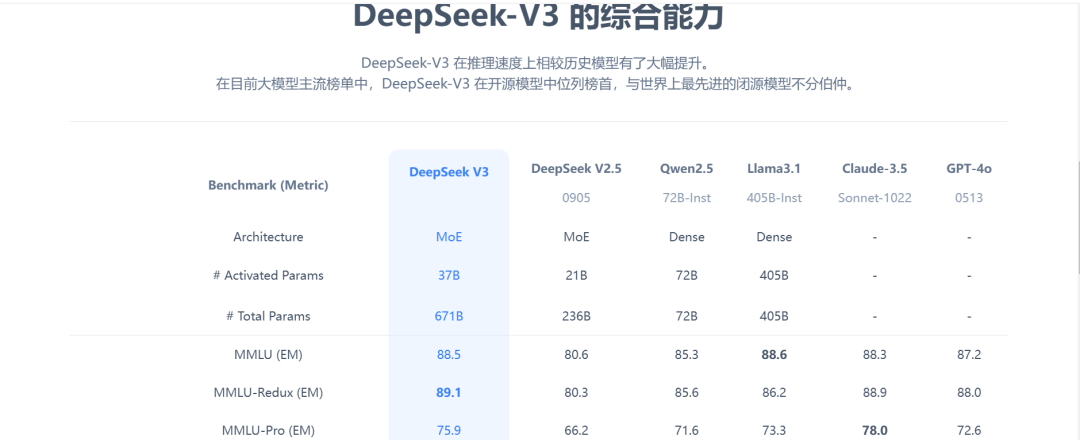
DeepSeek-V3 在推理速度上相较历史模型 有 大幅提升。 在目前大模型主流榜单中,DeepSeek-V3 在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。

先看DeepSeek发展历程
第一阶段:创立与核心技术突破(2023年)
2023年初,DeepSeek由多位来自中国顶尖高校和科技企业的AI专家联合创立。
创始团队认为,AGI的实现需要“更高效的模型架构”与“更低成本的训练方法”。
成立仅3个月后,团队即发布首个开源模型DeepSeek-R1,该模型在自然语言理解任务中以百亿参数量达到千亿级模型的性能,首次验证了“轻量化+高精度”技术路线的可行性。
这一突破迅速吸引投资机构关注,公司完成数亿元天使轮融资。
第二阶段:开源生态与行业落地(2024年)
2024年成为DeepSeek的生态扩张年。
公司推出DeepSeek-1.3B模型,首次在代码生成、多轮对话等复杂任务中超越同等规模的国际开源模型(如Meta的LLaMA),GitHub星标数突破3万。
同时,DeepSeek发布自研的分布式训练框架DeepSpeed-Lite,将大模型训练效率提升40%,并开源全套工具链。
这一阶段,DeepSeek与清华大学、上海人工智能实验室等机构建立联合实验室,推动学术与产业协同创新。
第三阶段:多模态与全球化布局(2025年至今)
2025年,DeepSeek发布全球首个千亿参数级多模态模型DeepSeek-Vision,支持文本、图像、视频的跨模态推理,在医疗影像分析、工业质检等领域实现商业化落地。
同年,公司与微软Azure达成战略合作,推出企业级AI平台DeepSeek Enterprise,服务金融、制造、教育等行业的500余家客户。
2026年,DeepSeek启动“全球开发者计划”,在硅谷、新加坡设立研发中心,模型下载量突破1000万次,成为GitHub最活跃的AI开源项目之一。

再来看DeepSeek 产品
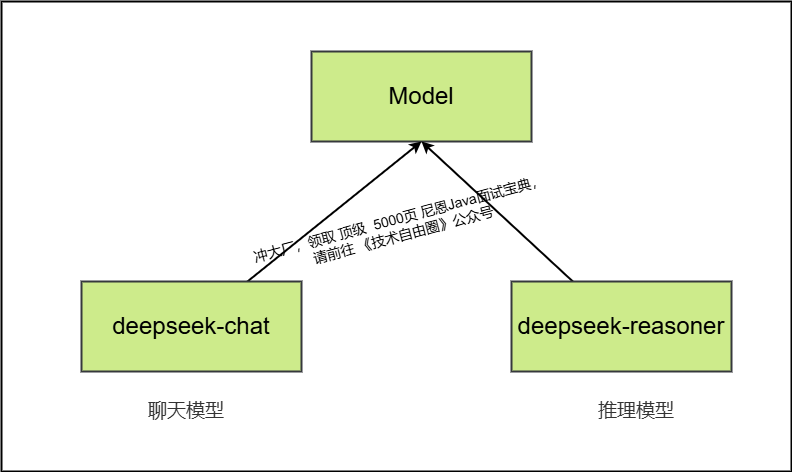
DeepSeek 的产品很多,大家听说过的,或者 常见的以下两种模型:
- deepseek-chat(V3):适用于聊天机器人、智能客服、内容生成等,能够理解和生成日常对话内容。
- deepseek-reasoner(R1):专为复杂推理任务设计,适合解决需要深度逻辑分析和推理的问题。
但是 DeepSeek 的模型还是很多的,尼恩给大家盘一下:
DeepSeek 语言模型类
DeepSeek LLM:
DeepSeek 发布的首个大模型,包含 670 亿参数,在 2 万亿 token 的中英文数据集上训练。开源了 DeepSeek LLM 7B/67B Base 和 DeepSeek LLM 7B/67B Chat。其中,DeepSeek LLM 67B Base 在推理、编码、数学和中文理解等方面超越了 Llama2 70B Base;DeepSeek LLM 67B Chat 在编码和数学方面表现出色,在匈牙利国家高中考试中取得 65 分,中文表现超越 GPT-3.5。
DeepSeek Coder:
由一系列代码语言模型组成,在 2 万亿 token 上训练,数据集含 87% 代码和 13% 中英文自然语言,模型尺寸从 1B 到 33B 版本不等。
通过在项目级代码语料库预训练,采用 16K 窗口大小和额外填空任务,支持项目级代码补全和填充,在多种编程语言和基准测试中达到开源代码模型先进性能。
DeepSeek 数学- 语言模型类
DeepSeekMath:
以 DeepSeek-Coder-v1.5 7B 为基础,在从 Common Crawl 中提取的数学相关 token 以及自然语言和代码数据上预训练,训练规模达 5000 亿 token。
DeepSeekMath 7B 在竞赛级 MATH 基准测试中取得 51.7% 的成绩,接近 Gemini-Ultra 和 GPT-4 的性能水平。
DeepSeek 视觉 - 语言模型类
DeepSeek-VL:
开源的视觉 - 语言(VL)模型,采用混合视觉编码器,能在固定 token 预算内高效处理高分辨率图像(1024x1024),保持较低计算开销。
DeepSeek-VL 系列(包括 1.3B 和 7B 模型)在相同模型尺寸下,在视觉 - 语言基准测试中性能先进或有竞争力。
DeepSeek-VL2:
先进的大型混合专家(MoE)视觉 - 语言模型系列,
有 DeepSeek-VL2-Tiny、DeepSeek-VL2-Small 和 DeepSeek-VL2 三个变体,分别具有 10 亿、28 亿和 45 亿激活参数。
在视觉问答、光学字符识别、文档 / 表格 / 图表理解以及视觉定位等多种任务中能力卓越,在相似或更少激活参数下性能具有竞争力或达最先进水平。
DeepSeek 其他模型
DeepSeek-V2:
拥有 2360 亿参数,每个 token 有 210 亿个活跃参数。
DeepSeek-V2 中文综合能力在众多开源模型中最强,超过 GPT-4,与 GPT-4-Turbo、文心 4.0 等闭源模型在评测中处于同一梯队;
DeepSeek-V2 英文综合能力与 LLaMA3-70B 处于同一梯队,超过最强 MoE 开源模型 Mixtral8x22B。
训练参数量达 8.1 万亿个 token,训练效率高。
DeepSeek-V3:
首个版本于 2024 年 12 月 26 日上线并开源,有 6710 亿参数,在 14.8 万亿 token 的数据集上训练,性能出色,在基准测试中超过 Llama 3.1 和 Qwen 2.5,与 GPT-4、Claude 3.5 Sonnet 相当。
DeepSeek-R1:
2025 年 1 月 20 日正式发布,在数学、代码、自然语言推理等任务上性能比肩 OpenAI o1 正式版。
1 月 24 日,在 Arena 上基准测试升至全类别大模型第三,在风格控制类模型分类中与 OpenAI o1 并列第一。
DeepSeek 和 其他主流开源模型的对比
DeepSeek 和Llama 3.1、Qwen 2.5、GPT-4、Claude 几大模型的对比如下:
主流开源 模型的 架构对比
- DeepSeek:
以 DeepSeek-V3 为例,采用混合专家(MoE)架构,总参数量达到 6710 亿,但每个输入仅激活约 5.5% 的参数(370 亿),还引入了多头潜在注意力(MLA)机制和无辅助损失的负载均衡策略。
- Qwen 2.5:
是典型的 Dense 模型,所有参数都用于每个任务,拥有 72B 的参数。
- Llama 3.1:
同样是 Dense 模型,参数规模达到 405B。
- Claude:
Claude的 架构独特,使其在处理复杂问题、生成结构化响应以及严格遵循输入提示方面有出色表现。
- GPT-4:
采用基于 Transformer 的架构,复杂程度和参数规模较前代有显著提升,可能极为庞大,还引入了多模态处理能力。
性能表现的对比
- 语言理解:
在 MMLU 测试中,
DeepSeek-V3 达到 88.5% 的准确率,在 MMLU-Redux 测试中提升至 89.1%;
Claude-3.5 也有较高水准;
GPT-4o 具有强大多语言能力;
Llama 3.1 凭借 405B 参数有较强的自然语言理解能力;
Qwen 2.5 在处理复杂任务时有一定优势。
- 推理能力:
在 DROP 测试中,DeepSeek-V3 以 91.6% 的 3-shot F1 得分领先;
Claude-3.5 在 IF-Eval 测试中以 86.5% 的成绩领先,在复杂问答和严格按指令执行场景中优势明显;
GPT-4o 整体推理能力也很强;
Llama 3.1 和 Qwen 2.5 在推理方面也有一定表现,但相对上述模型稍弱。
- 代码生成:
Qwen 2.5 在 HumanEval-Mul 测试中准确率达 77.3%,在 Aider-Edit 测试中代码编辑和调试准确率达 84.2%,表现最佳;
DeepSeek-V3 在 Codeforces 竞赛编程测试中以 51.6% 的百分位数得分突出;
Llama 3.1、GPT-4 和 Claude 也有一定代码生成能力,但不如 Qwen 2.5 和 DeepSeek-V3 有特点。
- 数学能力:
在 AIME 2024、MATH-500 和 CNMO 2024 等测试中,DeepSeek-V3 表现优异;
其他模型相比之下稍逊一筹。
训练成本的对比
- DeepSeek:以 DeepSeek-V3 为例,训练仅耗费 558 万美元,成本大幅降低至 Llama-3.1 的 1/11。
- Llama 3.1:Meta 训练投入 5 亿美元。
- GPT-42:训练成本高昂,使得许多团队望而却步。
应用场景的对比
- DeepSeek:
采用无限制商用协议的开源策略,在医疗、教育等领域都有广泛应用,开发者可基于此开发各种工具和平台。
- Qwen 2.5:
可用于多种自然语言处理场景,在阿里的一些产品和服务中发挥作用,如具备多模态功能,可帮助用户进行可视化开发等。
- Llama 3.1:
可用于自然语言处理的众多任务,如文本生成、问答系统等,很多研究机构和企业基于其进行二次开发。
- Claude:
在英语问答领域应用广泛,是许多英语 QA 应用的首选模型。
- GPT-4:
应用场景极为广泛,涵盖教育、医疗、零售、娱
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









