




提升图像识别精度的秘密武器:数据增强与TensorFlow的完美结合
在计算机视觉领域,深度学习模型的成功应用往往依赖于训练数据的质量与多样性。对于农业病害识别等实际应用场景,拍摄角度、光线变化等环境因素,常常会直接影响图像的质量,进而影响模型的识别效果。如何在这种复杂多变的环境中提升模型的鲁棒性和精度,成为了深度学习应用中的一大挑战。
计算机人工智sci/ei会议/ccf/核心,擅长机器学习,深度学习,神经网络,语义分割等计算机视觉,精通大小论文润色修改,代码复现,创新点改进等等。文末有方式
挑战:环境因素对模型识别精度的影响
在实际的应用中,农民或者设备用户通常在田间地头拍摄病害图像,而拍摄时的环境光线、角度、背景杂乱等因素都会对图像质量产生影响。例如,拍摄角度过大或过小、强烈的背光、不同的光照强度,都可能导致图像特征丢失或失真,使得深度学习模型难以准确地识别病害。对于一个训练较少的模型来说,面对这种多变的场景,很容易出现识别错误。
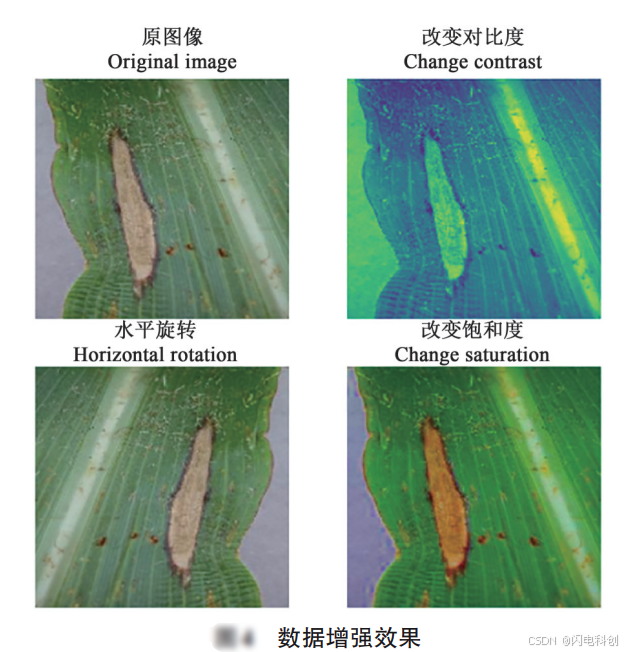
为了解决这个问题,数据增强成为提升模型表现的重要手段。通过在训练数据集上进行一系列变换操作,增加图像的多样性和复杂性,模型能够学到更多关于图像的特征,从而在面对不同的环境变化时,依然能够做出准确的预测。
数据增强:提升鲁棒性与识别精度
数据增强是指通过对原始图像进行各种变换(如平移、旋转、缩放等)来生成新的图像数据。这不仅能有效避免模型过拟合,还能增加数据集的多样性,使模型能够更好地适应实际应用中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











