



 Uber发布Ludwig,一个基于TensorFlow的深度学习工具箱,无需编写代码即可训练模型,简化AI开发流程,支持多种数据类型及预训练模型。
Uber发布Ludwig,一个基于TensorFlow的深度学习工具箱,无需编写代码即可训练模型,简化AI开发流程,支持多种数据类型及预训练模型。

Uber 宣布开源 Ludwig,一个基于 TensorFlow 的工具箱,该工具箱特点是不用写代码就能够训练和测试深度学习模型。
Uber 官方表示,对于AI开发者来说,Ludwig 可以帮助他们更好地理解深度学习方面的能力,并能够推进模型快速迭代。另一方面,对于 AI 专家来说,Ludwig 可以简化原型设计和数据处理过程,从而让他们能够专注于开发深度学习模型架构。
Ludwig 提供了一套 AI 架构,可以组合起来,为给定的用例创建端到端的模型。开始模型训练,只需要一个表格数据文件(如 CSV)和一个 YAML 配置文件——用于指定数据文件中哪些列是输入特征,哪些列是输出目标变量。如果指定了多个输出变量,Ludwig 将学会同时预测所有输出。使用 Ludwig 训练模型,在模型定义中可以包含附加信息,比如数据集中每个特征的预处理数据和模型训练参数, 也能够保存下来,可以在日后加载,对新数据进行预测。
对于 Ludwig 支持的数据类型(文本、图像、类别等),其提供了一个将原始数据映射到张量的编码器,以及将张量映射到原始数据的解码器(张量是线性代数中使用的数据结构)。内置的组合器,能够自动将所有输入编码器的张量组合在一起,对它们进行处理,并将其返回给输入解码器。
Uber 表示,通过组合这些特定于数据类型的组件,用户可以将 Ludwig 用于各种任务。比如,组合文本编码器和类别解码器,就可以获得一个文本分类器。
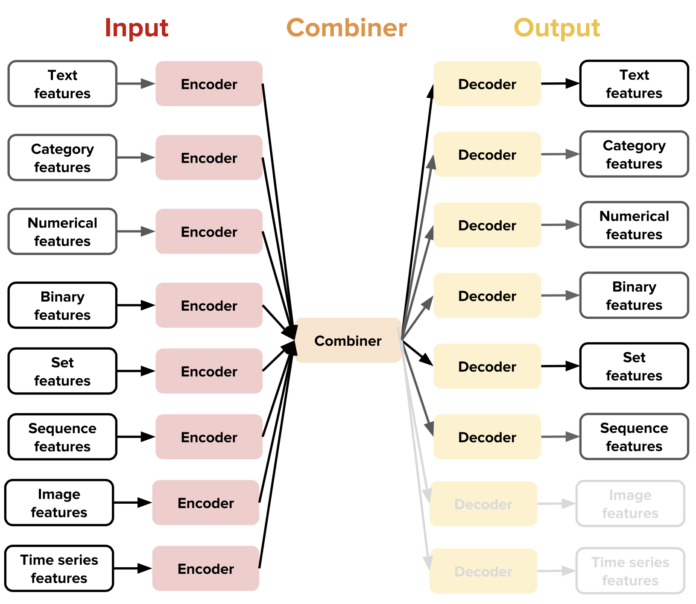
每种数据类型有多个编码器和解码器。例如,文本可以用卷积神经网络(CNN),循环神经网络(RNN)或其他编码器编码。用户可以直接在模型定义文件中指定要使用的参数和超参数,而无需编写单行代码。
Ludwig 采用的这种灵活的编码器-解码器架构,即使是经验较少的深度学习开发者,也能够轻松地为不同的任务训练模型。比如文本分类、目标分类、图像字幕、序列标签、回归、语言建模、机器翻译、时间序列预测和问答等等。
此外,Ludwig 还提供了各种工具,且能够使用开源分布式培训框架 Horovod。目前,Ludwig 有用于二进制值,浮点数,类别,离散序列,集合,袋(bag),图像,文本和时间序列的编码器和解码器,并且支持选定的预训练模型。未来将支持更多资料的种类。

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









