






 为应对游戏广告在小流量渠道的精准投放挑战,本文介绍了一种基于标签的精准投放算法-先知。该算法利用标签系统连接用户兴趣与广告素材,通过优化点击数据置信度、引入时间窗口加权、扩充数据维度及确定维度权重等方式,显著提高了广告点击率。
为应对游戏广告在小流量渠道的精准投放挑战,本文介绍了一种基于标签的精准投放算法-先知。该算法利用标签系统连接用户兴趣与广告素材,通过优化点击数据置信度、引入时间窗口加权、扩充数据维度及确定维度权重等方式,显著提高了广告点击率。
1 背景
\\1.1 为什么要有精准投放算法 - 先知
\\随着公司游戏业务的发展,传统的搜索技术已经不能满足用户对游戏发现的需求,原因有多种,首先用户很难用合适的关键词来描述想要玩的游戏,其次用户的兴趣和喜好在不断变化和更新,再者用户无法对自己未知而又可能感兴趣的游戏做出描述。推荐系统的出现可以帮用户获取更丰富,更符合个人兴趣的游戏。
\\在流量非常紧缺的互联网上,用户直面的并不是游戏本身,而是一条条广告素材,广告素材是经过美术定制加工在广告投放时播放的视频,Flash 或者展示的图片等。个性化推荐会根据用户兴趣和行为特点,向用户推荐所需的游戏素材,帮助用户在海量信息中快速发现真正所需的游戏,提高用户黏性,促进素材背后游戏的注册和收入。
\\在广告市场,以参与者划分可以分成平台方和买量方,与诸如淘宝直通车,腾讯广点通,微博粉丝通这类平台上广告系统不同,买量方做广告效果的优化存在以下特点:
\\(1)渠道流量小,特别渠道流量极小。公司的买量渠道种类众多,投放渠道近百个,流量大小不一,统计每天点击数在 100 以内的渠道广告计划量占比 65%。数据集的稀疏度应该在十万分之一或以下的量级,特征中有效信息(非 0 值)的维度很低,其中包含的噪声会对真实信息干扰很大.使得绝大部分基于关联分析的算法(譬如协同过滤)以及 CTR 预估效果都不好。这个问题本质上是无法完全克服的。因此对于这些极小量渠道的游戏广告精准投放算法需求十分迫切。
\\(2)买量方对于用户兴趣和行为特点的信息了解甚少,尽管与部分平台的合作能够拿到一定维度的属性数据,但是总体上大部分长尾渠道信息是非常少的,这样造成了用户属性的缺失,并且点击广告的很多均为新用户,考虑到冷启动问题。标签系统提供了解决冷启动问题的可能方案。因为标签既可以看作是素材内容的萃取,同时也反映了用户的个性化喜好。
\\综合以上实际情况的考虑:用于解决极小量渠道的,基于标签的精准投放算法 - 先知应运而生。
\\2 算法原理
\\2.1 算法概述
\\推荐系统的目的是联系用户的兴趣和素材,这种联系方式需要依赖不同的媒介。目前流行的推荐系统基本上是通过三种方式联系用户兴趣和物品:
\\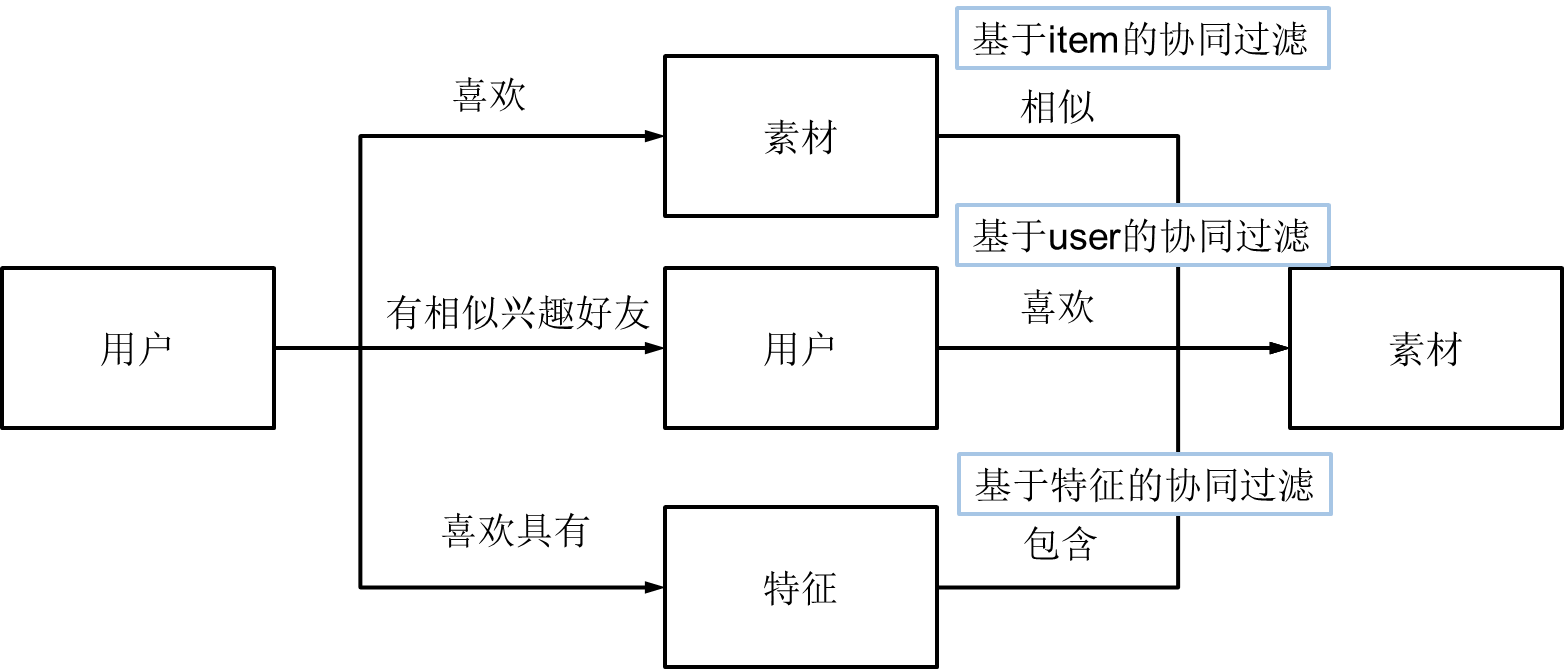
图 2-1 推荐系统联系用户和素材的几种途径
\\考虑到数据稀疏性,协同过滤方式效果不好。因此考虑第三种方式:通过一些特征联系用户和素材,给用户推荐那些具有用户喜欢的特征的素材,这里的特征有不同的表现形式,比如可以表现为物品的属性集合,也可以表现为隐语义向量,而下面我们要讨论的是一种重要的特征表现形式——标签。
\\2.2 什么是素材标签
\\在美术做完一个素材后,会给素材打上对应标签,标签内容如下:
\\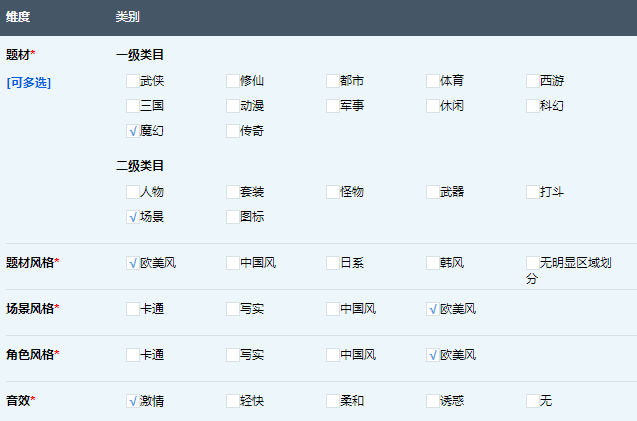
图 2-2 素材人工标签
\\经过标签层级处理,并且标签变量 0-1 处理后得到每个素材的标签:
\\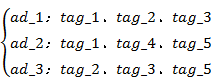
进行哑变量处理得到素材标签矩阵 T:
\\表2-1 哑变量处理后的素材标签矩阵
\\| \\t\t\t 素材ID \\t\t\t | \\t\t\t 标签1 \\t\t\t | \\t\t\t 标签2 \\t\t\t | \\t\t\t 标签3 \\t\t\t | \\t\t\t 标签4 \\t\t\t | \\t\t\t 标签5 \\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t 标签n \\t\t\t |
| \\t\t\t ad_1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t\\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t |
| \\t\t\t ad_2 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t\\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t |
| \\t\t\t ad_3 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t |
2.3 什么是用户标签
\\在用户请求广告数据时,我们可以通过请求时间以及用户 Cookie 得到用户属性数据,经过正则化解析后得到用户属性矩阵 A:
\\表2-2 用户标签矩阵
\\| \\t\t\t 用户ID \\t\t\t | \\t\t\t 时间 \\t\t\t | \\t\t\t 地区 \\t\t\t | \\t\t\t 浏览器 \\t\t\t | \\t\t\t 操作系统 \\t\t\t | \\t\t\t 关键词 \\t\t\t |
| \\t\t\t user_1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t\\t\t\t |
| \\t\t\t user_2 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t\\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t |
| \\t\t\t user_3 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t\\t\t\t | \\t\t\t 1 \\t\t\t |
2.4 如何生成标签点击率
\\模型根据历史数据中用户的请求,素材加载,素材点击等行为出发,最终定位用户的兴趣标签,考虑用户属性,时间衰减等因素,计算出每个属性下的标签点击率矩阵 C。流程如下所示:
\\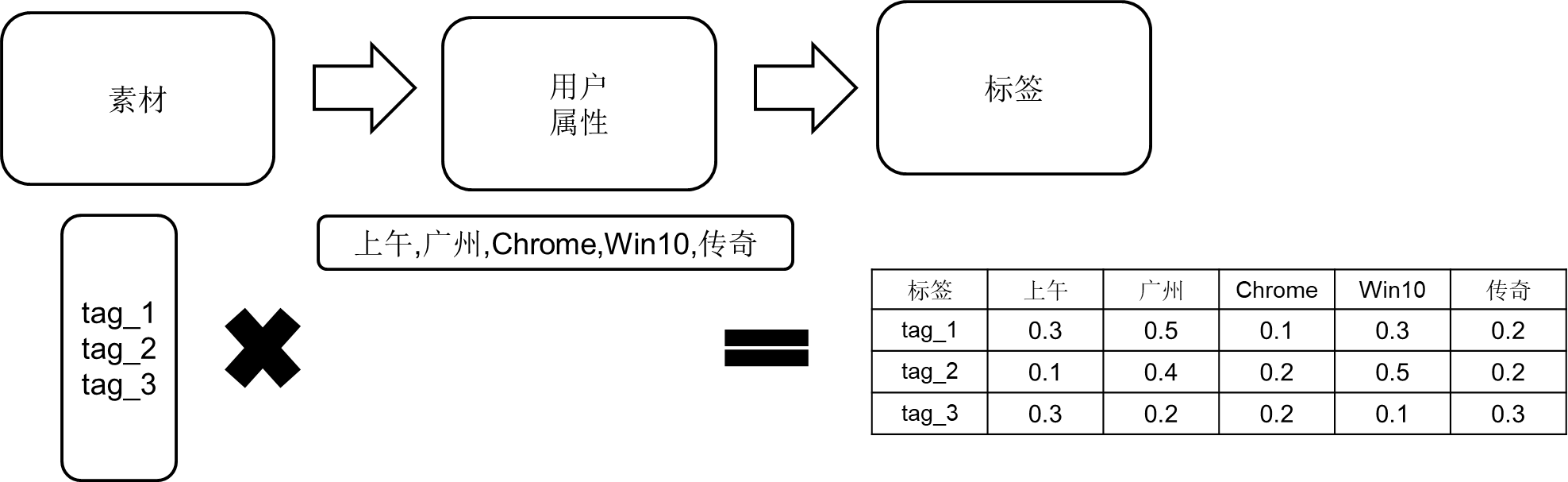
图 2-3 标签点击率生成流程图
\\2.5 如何根据标签点击率进行推荐
\\当一个用户发生广告请求时,该广告所在的计划有 M[C1,C2,,,Cm] 种素材,根据用户属性 A[time,local,browser,OS,UID],以及 2.3 生成的标签点击率矩阵 C,得到 M 个素材的推荐值:
\\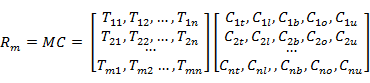
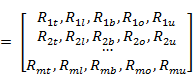
对该计划下 M 个素材的在各个属性的评分进行加权:
\\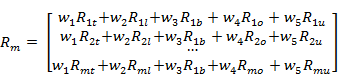
对该计划下属性 A 的用户的请求,推荐 M 个素材中 R_m 值最大的那个素材。
\\2.6 算法整体流程
\\整体流程图如下:
\\(1) 离线计算:根据广告请求 - 点击历史数据,对于每个渠道计划,每隔一小时离线计算每个属性下的标签点击率矩阵 C。
\\(2) 在线计算:在线引擎需要根据当前请求用户属性 A,去读取相应特征数据,进行计算得到每个素材推荐值矩阵 R_m。
\\(3) 广告投放引擎:广告投放引擎返回 R_m 排序后的最佳素材给 web 服务器,最后显示给用户。
\\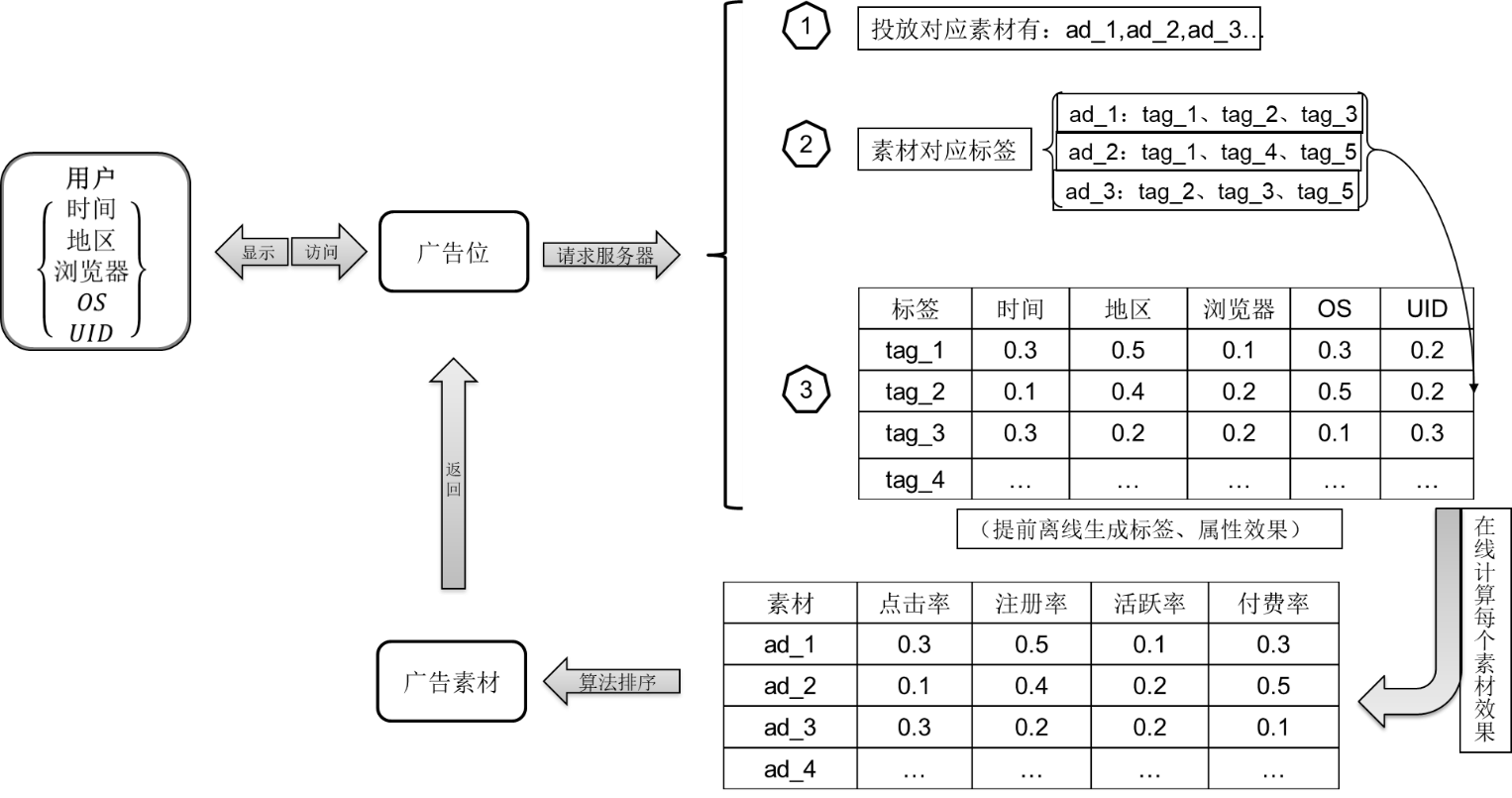
图 2-4 算法整体流程
\\3 算法优化
\\3.1 点击数据置信
\\由于渠道的流量小,会出现点击信息不可信的问题:首先在推荐系统中假设:
\\(1)每个用户的点击素材行为都是独立事件。
\\(2)用户只有两个选择,要么点击素材,标记为'1';要么未点击素材,标记为'0'。
\\(3)如果某个素材总请求数为 n,其中点击数为 k,那么点击率就等于 p = k/n。
\\假设两个素材,根据频率学派计算其注册率:
\\A 素材:2 个请求,2 个注册,注册率:100%
\\B 素材:100 个请求,99 个注册,注册率:99%
\\但是注意到:A 素材的请求样本数据远小于 B 素材。那么 A,B 素材的注册率,其实是不可信的。
\\由于素材的点击与否是一个二项分布, p 可以看作\"二项分布\"中某个事件的发生概率,因此可以计算出 p 的置信区间。二项分布的置信区间有多种计算公式,最常见的是\"正态区间\"。但是,它只适用于样本较多的情况(np \u0026gt; 5 且 n (1 − p) \u0026gt; 5),对于小样本,它的准确性很差。
\\而对于广告的点击样本,有些小渠道的样本往往是很少的。因此采用“威尔逊区间”,能够很好地解决小样本的准确性问题。计算公式如下:
\\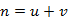
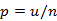
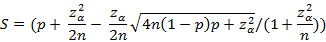
其中 u 表示正例数(点击),v 表示负例数(未点击),n 表示实例总数(总请求数),p 表示点击率,z 是正态分布的分位数(参数),S 表示最终的威尔逊得分。z 一般取值 2 即可,即 95% 的置信度。
\\根据威尔逊区间,上述 A 点击率修正为:33.33%,B 素材点击率修正为 94.40%。
\\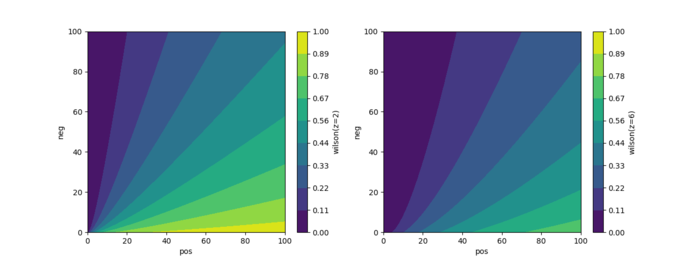
图 3-1 威尔逊区间修正图
\\将威尔逊区间用于素材推荐系统后,下图可以看到标签点击率的修正情况:
\\表3-1标签点击率修正表
\\| \\t\t\t 标签 \\t\t\t | \\t\t\t UID \\t\t\t | \\t\t\t 请求数 \\t\t\t | \\t\t\t 点击数 \\t\t\t | \\t\t\t 点击率 \\t\t\t | \\t\t\t 修正点击率 \\t\t\t |
| \\t\t\t 31 \\t\t\t | \\t\t\t 1222170 \\t\t\t | \\t\t\t 9 \\t\t\t | \\t\t\t 7 \\t\t\t | \\t\t\t 77.78% \\t\t\t | \\t\t\t 40.19% \\t\t\t |
| \\t\t\t 43 \\t\t\t | \\t\t\t 1253180 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 1 \\t\t\t | \\t\t\t 100% \\t\t\t | \\t\t\t 5.46% \\t\t\t |
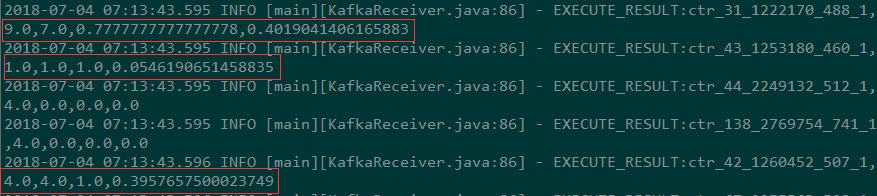
图 3-2 标签点击率修正日志数据
\\3.2 时间窗口加权
\\传统的推荐算法都是基于用户过去的偏好信息来预测用户当前的喜好信息, 这其中包含了一个假设, 即:用户的兴趣是不变的。而在现实生活中, 用户的兴趣很有可能会随着时间的推移而有所变化, 只有模拟了用户这种变化着的兴趣才能更准确地向用户推荐素材。因此需要考虑用户兴趣随时间变化,这里采用时间窗口加权法,即越靠近当前时间点的点击信息越重要。在计算素材标签的点击率时,从当前时间点往前取五个时间段的请求点击数据,并赋予时间衰减权重,如下表:
\\表3-2 时间衰减权重表
\\| \\t\t\t 时间份数 \\t\t\t | \\t\t\t T1 \\t\t\t | \\t\t\t T2 \\t\t\t | \\t\t\t T3 \\t\t\t | \\t\t\t T4 \\t\t\t | \\t\t\t T5 \\t\t\t |
| \\t\t\t 请求数 \\t\t\t | \\t\t\t R1 \\t\t\t | \\t\t\t R2 \\t\t\t | \\t\t\t R3 \\t\t\t | \\t\t\t R4 \\t\t\t | \\t\t\t R5 \\t\t\t |
| \\t\t\t 点击数 \\t\t\t | \\t\t\t C1 \\t\t\t | \\t\t\t C2 \\t\t\t | \\t\t\t C3 \\t\t\t | \\t\t\t C4 \\t\t\t | \\t\t\t C5 \\t\t\t |
| \\t\t\t 衰减权重 \\t\t\t | \\t\t\t W1 \\t\t\t | \\t\t\t W2 \\t\t\t | \\t\t\t W3 \\t\t\t | \\t\t\t W4 \\t\t\t | \\t\t\t W5 \\t\t\t |
那么素材标签的点击率为:
\\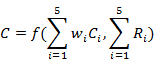
其中函数 f 为威尔逊区间函数。衰减参数为超参,需要根据实际情况进行调节。
\\3.3 维度数据扩充
\\即使使用了五份的时间窗口,发现在某些时间和地区维度,仍然存在没有广告请求数据。因此对时间维度和城市维度进行数据分析,根据分时段的请求数和点击数,将小时维度合并,1 天分为 4 个时间段;同时将城市维度合并为省份维度;通过 A/B 测试:发现数据维度的合并优化能够有效的解决数据稀疏性问题提高模型点击率。
\\统计每个属性下的标签的点击率矩阵 C 中请求个数的占比,如下图所示:时间地区维度扩充后,矩阵 C 中为 0 的占比有所下降,数据稀疏性有所缓解。
\\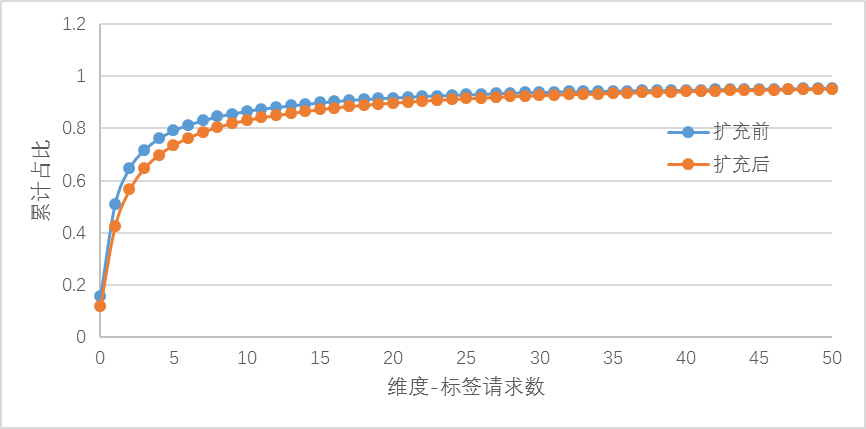
图 3-3 维度 - 标签请求数据分布图
\\3.4 维度权重确定
\\在上面我们提到会对计划下 M 个素材在各个属性的评分进行加权 W,推然后荐 M 个素材中 R_m 值最大的那个素材:
\\
权重是一个相对的概念,针对某一指标而言,某一指标的权重是指该指标在整体评价中的相对重要程度。权重的确定有两种方法:主观赋权法和客观赋权法。这里采用客观赋权法:根据指标的原始数据,通过数学或者统计方法处理后获得权重。 在客观赋权法中,采用标准差系数权重法:根据每个指标的变异程度大小来进行赋权,变异程度大的说明能够更好的区分各个指标,应赋予更高的权重,反之赋予较小的权重。步骤如下:
\\(1) 获取单个渠道下历史请求数据日志:
\\表3-3 请求数据日志矩阵
\\| \\t\t\t 请求ID \\t\t\t | \\t\t\t time \\t\t\t | \\t\t\t local \\t\t\t | \\t\t\t browser \\t\t\t | \\t\t\t OS \\t\t\t | \\t\t\t UID \\t\t\t |
| \\t\t\t 1 \\t\t\t | \\t\t\t t1 \\t\t\t | \\t\t\t l1 \\t\t\t | \\t\t\t b1 \\t\t\t | \\t\t\t o1 \\t\t\t | \\t\t\t u1 \\t\t\t |
| \\t\t\t 2 \\t\t\t | \\t\t\t t2 \\t\t\t | \\t\t\t l2 \\t\t\t | \\t\t\t b2 \\t\t\t | \\t\t\t o2 \\t\t\t | \\t\t\t u2 \\t\t\t |
| \\t\t\t 3 \\t\t\t | \\t\t\t t3 \\t\t\t | \\t\t\t l3 \\t\t\t | \\t\t\t b3 \\t\t\t | \\t\t\t o3 \\t\t\t | \\t\t\t u3 \\t\t\t |
| \\t\t\t 4 \\t\t\t | \\t\t\t t4 \\t\t\t | \\t\t\t l4 \\t\t\t | \\t\t\t b4 \\t\t\t | \\t\t\t o4 \\t\t\t | \\t\t\t u4 \\t\t\t |
| \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t | \\t\t\t … \\t\t\t |
(2) 计算单个渠道下各维度平均值:
\\
(3) 计算单个渠道下各维度标准差系数,也叫离散系数:
\\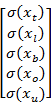
(4) 计算单个渠道下各维度权重:
\\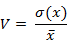
最后计算出每个计划的权重,比如某渠道的权重更新情况如下:
\\表3-4 渠道权重更新数据
\\| \\t\t\t 维度 \\t\t\t | \\t\t\t 标准差 \\t\t\t | \\t\t\t 平均值 \\t\t\t | \\t\t\t 权重 \\t\t\t |
| \\t\t\t time \\t\t\t | \\t\t\t 0.57 \\t\t\t | \\t\t\t 1.63 \\t\t\t | \\t\t\t 0.094 \\t\t\t |
| \\t\t\t local \\t\t\t | \\t\t\t 0.28 \\t\t\t | \\t\t\t 0.25 \\t\t\t | \\t\t\t 0.300 \\t\t\t |
| \\t\t\t browser \\t\t\t | \\t\t\t 0.58 \\t\t\t | \\t\t\t 1.31 \\t\t\t | \\t\t\t 0.118 \\t\t\t |
| \\t\t\t OS \\t\t\t | \\t\t\t 0.72 \\t\t\t | \\t\t\t 0.84 \\t\t\t | \\t\t\t 0.229 \\t\t\t |
| \\t\t\t UID \\t\t\t | \\t\t\t 0.61 \\t\t\t | \\t\t\t 0.63 \\t\t\t | \\t\t\t 0.259 \\t\t\t |
通过上表发现:往往关键词 UID 和浏览器 browser 的权重较高,符合实际业务逻辑,更新以后效果如下图,可以看到更新后,模型的点击率比人工点击率提升 9.7%。
\\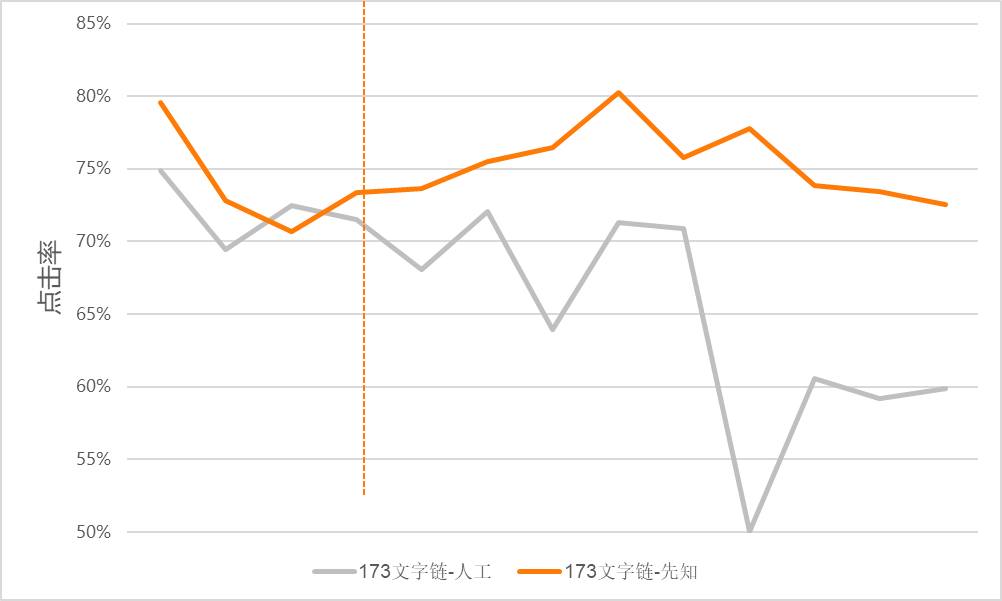
图 3-4 权重更新后 A/B 测试效果
\\3.5 标签的准确性
\\广告素材的人工标签主要由美术人员进行添加修改,因此会存在标签描述信息过少,标签的选取容易受到主观因素影响。反应到广告投放上会存在下述问题:
\\(1) 同一个广告计划下,存在两个不同素材具有一样的标签。这种情况会使得两个素材计算得到的推荐值 R_m 一样。
\\(2) 素材忘记打上标签。这种情况会使得素材计算得到的推荐值 R_m 为 0,素材不会被推荐。
\\(3) 人工标签不准确:风格内容差异较大的素材,人工标签很接近。这种情况会影响到算法推荐的准确性。反之亦然。
\\为了解决上述问题,需要一种全新的素材标签生成方法。考虑到素材对人的吸引程度主要是包括内容和风格两方面。经过技术方案调研,并且结合业务需求,对比传统计算机视觉和深度学习,最终采用了深度学习来生成素材的数字标签。详细见下篇《素材自动化标签》。
\\4 算法效果
\\使用上述算法优化后,进行人工和模型投放的 A/B 测试。虚线左侧为算法优化前,虚线右侧为算法优化后。可以很明显地发现优化后算法比人工投放的点击率高 10% 左右。
\\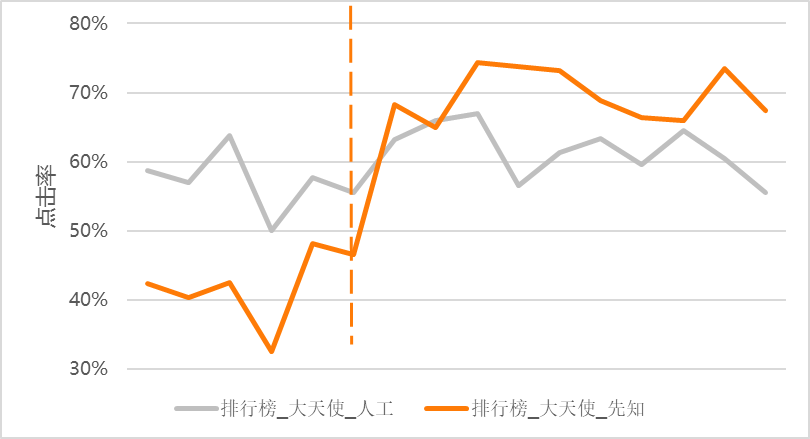
图 4-1 算法优化 A/B 测试效果
\\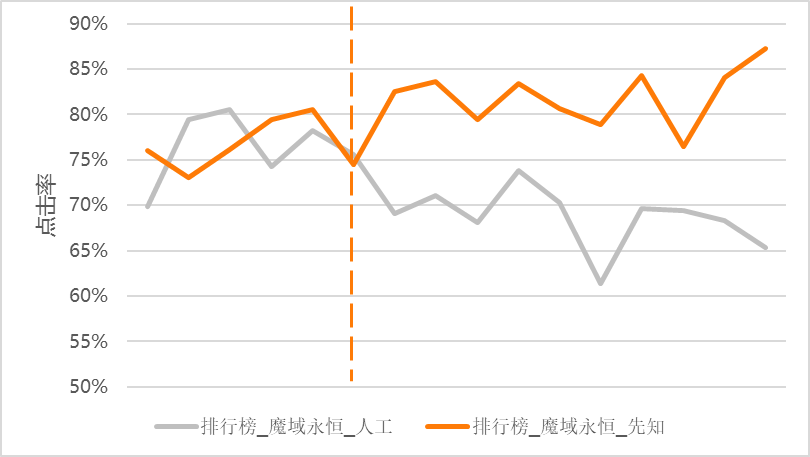
图 4-2 算法优化 A/B 测试效果
\\5 算法现状以及展望
\\5.1 算法的现状
\\广告推荐算法中还会存在一些问题对算法的建模和优化有所影响:
\\(1) 数据稀疏性
\\即使在为时间,地区维度数据合并后,某些冷门的用户属性还是会出现数据稀疏的现象,比如用户 UID-标签的请求数,约有 16.7% 的数据为 0。
\\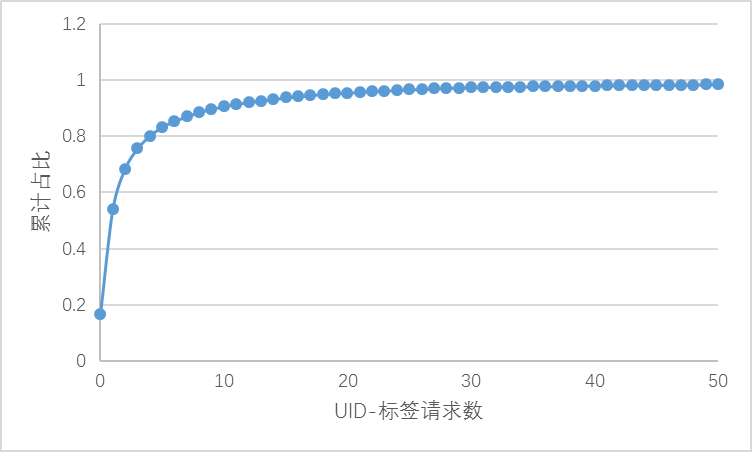
图 5-1 用户属性 UID-标签的请求数分布
\\(2) 量小渠道问题
\\由于推荐算法是以一个广告计划为单位建立的模型,那么必然会存在一些量小的渠道的数据极其稀疏,这个对于推荐的准确性会造成影响。
\\(3) 用户属性缺乏
\\由于网页游戏用户的特殊性质:流动性较大,Cookie 易清除等等。而用户属性的获取方式一般为 HTTP 请求报文以及 Cookie 解析。因此能够获取的网页请求用户属性极其有限,特别是新用户。同时推荐算法主要针对的群体是游戏新用户,用户属性的缺乏会一定程度影响推荐算法的准确性。
\\5.2 算法的展望
\\由于存在上面所述的一些问题,因此接下来算法的优化方向也在这三个方面:
\\(1) 用户属性的扩充
\\平台数据打通后,用户属性可以考虑结合整个平台的用户属性进行扩充。特别是对于平台的老用户,可以获取到老用户曾经点击过的素材,注册和付费过的游戏,而游戏和素材一样,同样可以通过标签数据关联起来。
\\(2) 渠道数据的扩充
\\同上,数据的稀疏性可以考虑渠道数据的向上聚合。每个渠道有着其特有的渠道用户。这些用户属性代表渠道性质,因此计算渠道两两之间的余弦相似性:
\\渠道 A 请求用户在时间属性分布:
\\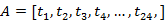
渠道 B 请求用户在时间属性分布
\\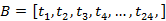
那么 A,B 渠道用户在时间属性上余弦相似性为:
\\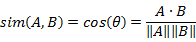
那么对于用户属性余弦相似性接近 1 的渠道,可以认为用户属性接近,可以进行渠道合并,解决部分数据稀疏性.
\\(3) 素材标签的扩充
\\目前人工标签存在着诸多问题,需要利用深度学习来进行素材标签的自动化生成。
\\作者简介
\\成鹏,三七互娱数据挖掘工程师,一直专注于机器学习、深度学习及其在互联网行业的应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









