






本文最初发布于Spotify官方博客,原作者:David Xia。经授权由InfoQ中文站翻译并分享。阅读英文原文:Improving Critical Infrastructure Rollouts。
\\Spotify最初于2014年通过几个原型服务开始使用Docker。自那之后,我们进行了多次升级和配置,而几乎每次都遇到了一些难以检测并修复的问题。在通过Docker运行很少量后端服务时,这些问题的影响范围还较小。但随着Docker使用率增加,Docker中存在的错误造成的风险和影响也水涨船高,最终到了不可接受的程度。2016年10月,由于部署了一个错误的配置,甚至对用户体验产生了严重影响。
\\仔细思考后,我们意识到需要一种全新的解决方案,以更加细化并且受控的方式部署可能影响整个公司基础架构的变更。本文将介绍Spotify如何受到Docker运维工作的启发构建新服务,让我们更好地控制为包含数千台服务器的基础架构推送变更的过程。
\\1. 每次Docker升级都会遇到问题
\\每次升级Docker后,我们都会在Docker本身的变更以及其中运行的软件等方面遇到有关回归或不兼容的问题。更麻烦的是,这些问题往往很难排错,因此会造成更大影响。
\\在将Docker从1.0.0升级至1.3.1的过程中,曾遇到两个很好解决的Bug。Docker改变了设置容器主机名的方式,以及处理CMD和ENTRYPOINT设置的方式。在几天里,我们部署了针对这两个回归问题的修复措施。这些都不严重,只有少数团队的构建流程受到影响。但随后的一次升级就没那么幸运了。
\\2015年夏天,我们刚刚从1.3.1升级到1.6.2,感觉一切都很顺利。但很快发现这两个Docker版本的升级会导致产生“孤本(Orphaned)”容器,即无法由Docker守护进程管理的容器。这些容器依然会绑定原本使用的端口,导致我们的Docker编排工具Helios会将流量路由至错误的容器。通过反复升级和降级Docker,我们成功重现了这个问题。问题根源在于Docker没能正确关闭,进而导致产生孤本进程。我们开始监视孤本容器进程,并提交了一个补丁,以便为Docker提供更多时间,让它能够正确关闭。相比之前的两个Bug,这次的Bug更严重,同时也更难修复。
\\去年11月,我们完成了从1.6.2到1.12.1的升级。一周后,11月3日,我们发现1.12.1版有一个Bug会创建孤本的Docker代理进程,进而因为端口没能成功释放导致容器无法运行。我们很快解决了一些团队因为这个Bug无法部署服务的问题,同时帮助他们将实例升级到1.12.3版。与上次升级遇到的Bug类似,这次的问题也很严重并且难以修复。
\\2. Docker对Spotify后端重要性越来越高,Docker问题的风险和影响力也水涨船高
\\Spotify最初于2014年通过几个原型服务开始使用Docker,当时仅通过数百个Docker实例运行了少数几个服务。借此建立了信心后,我们升级了整个测试环境,一周后升级了生产环境。虽然遇到过几个Bug,但并不严重。
\\但2016年10月从1.6.2到1.12.1的升级,情况完全不同了。当时我们已经通过数千个Docker实例运行了几个关键业务服务,承担了用户登录、事件交付,以及客户端与后端的所有通信任务。升级Docker实例会导致该实例上运行的所有容器重启动,为避免大量服务同时重启动,只能循序渐进地升级。如果同时重启动访问点以及用户登录等重要服务,会导致用户体验严重受影响,甚至因为重启动之后的“重连接风暴”影响下游服务。
\\截止2017年2月,我们生产环境中80%的后端服务都在容器中运行。Docker已经从实验对象成功变身为Spotify后端基础架构的重要组成部分。我们团队负责运营维护横跨数千台主机的Docker守护进程,需要通过比以往更慎重的方式逐步进行升级。
\\3. 我们最终决定为整个基础架构创建一种循序渐进的发布解决方案
\\当时我们正着手向1.12.1版升级,并已完成30%。随后10月14日周五,在修复供应新Docker实例过程中遇到的一个罕见小问题时,我们犯了一个严重的错误。这次事件让我们意识到自己的Docker部署方式与影响整个公司的变更结合在一起到底会产生多大的影响力。最终我们集思广益开发了一个服务,帮助我们以更细化可控的方式发布基础架构变更。
\\这就是Tsunami
\\Tsunami使得我们可以通过无人值守的方式,循序渐进地将有关配置和基础架构组件的变更发布出去。我们可以让Tsunami“在两周内将Docker从版本A升级至版本B”。Tsunami从本质上可以作为一种服务以线性方式发挥作用,而拉长部署工作持续的时间段有助于提高可靠性。我们可以在只产生小范围影响时发现可能存在的问题。
\\Tsunami解决的问题
\\- 以我们Docker基础架构的规模和职责来说,所需的循序渐进升级机制。\\t
- 通过循序渐进升级限制Bug的影响范围,为工程师留出足够时间检测并上报问题。\\t
- 我们目前的环境,无法仅通过对自己的服务进行Docker升级,或对其他服务的实例进行测试的方式检测到升级过程中可能出现的全部问题。我们需要对真实的生产服务进行升级,这就必须针对所有后端服务以均匀分布的方式缓慢推进。\
“变量(Variable)”是Tsunami中的一个重要概念。每个变量都有自己的名字和配置,借此控制着变量可以提供的值,以及在一个较长时间段内的变化情况。我们的所有Docker实例会查询Tsunami以了解自己需要运行的Docker版本。Tsunami只需要返回一个代表所需状态的平坦(Flat)JSON对象即可,随后将由客户端自己决定如何实现所需的状态。
\\这样即可获得我们所需要的发布方式。
\\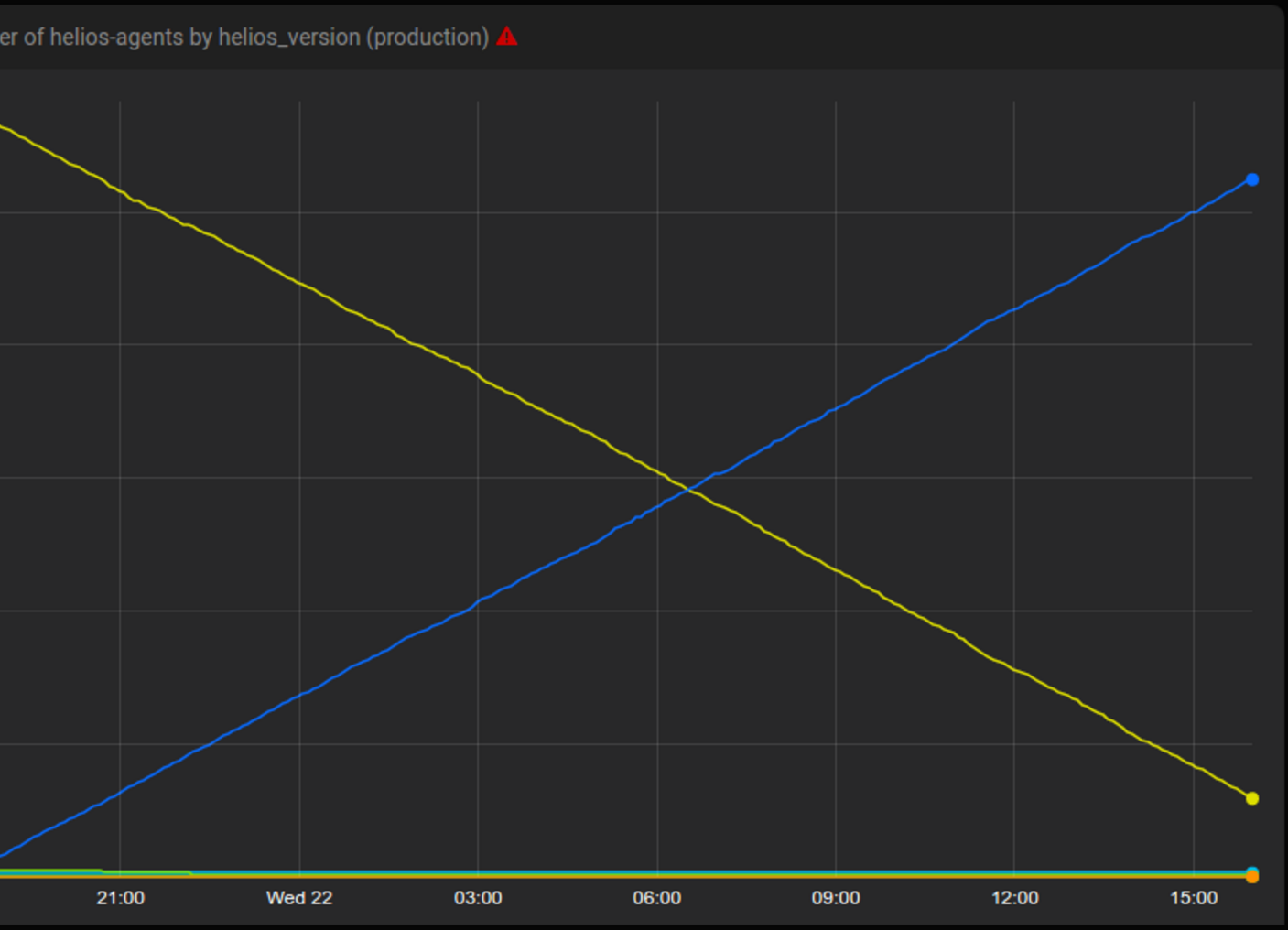
不同版本Helios代理的数量
\\Tsunami可在24小时内将新版Helios发布至上千台主机,黄线代表老版本,蓝线代表新版本。
\\通过一个集中化的服务控制发布过程,使得我们可以构建所有客户端都能“免费”获取的功能,包括:
\\- 通过审计日志查看某台主机在何时,出于什么原因需要运行某一特定版本的系统服务。\\t
- 对于特定角色中多大比例的主机会受到某个基础架构变更的影响,获得更细化的控制逻辑,并能设置上限和下限(例如角色中30%的主机,但至少一台主机)。\\t
- 监视计算机的服务级别目标,如果目标无法达到则自动终止发布。\
我们目前已经在使用Tsunami升级Helios、Docker和Puppet。Tsunami还帮助我们更好地对需要重启动服务的配置变更作出安排。希望在不远的将来能够将Tsunami开源给整个社区。
\\感谢郭蕾对本文的审校。
\\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。

















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









