



 Oracle最近推出了一款大数据设备,内置OracleNoSQLDatabase,具备十亿行级存储、TB级B-树存储、ACID事务等功能。同时,Oracle曾发表白皮书质疑NoSQL数据库的成熟度,但现在通过此设备重新加入了NoSQL阵营。
Oracle最近推出了一款大数据设备,内置OracleNoSQLDatabase,具备十亿行级存储、TB级B-树存储、ACID事务等功能。同时,Oracle曾发表白皮书质疑NoSQL数据库的成熟度,但现在通过此设备重新加入了NoSQL阵营。
Oracle最近发布了一种大数据设备,其中运行有Oracle NoSQL Database,它是基于Oracle Berkeley DB Java Edition的新键-值存储系统。该系统的特性包括:十亿行级的记录存储能力、TB级的B-树存储能力、ACID事务、CRUD、分片(sharding)、无单点故障、通过数据中心间复制进行灾难恢复等等。
\Oracle是关系型数据库的标准,它在2011年5月发布了白皮书“揭穿NoSQL的不实宣传”。Oracle试图在其中证明NoSQL数据存储存在很多问题,包括没有标准API、能源利用效率低、只在诸如Google这样的大公司才可行、缺少安全性等等,这篇文章得出下述结论:
\\\人们普遍认为,目前NoSQL数据库与关系型数据库相比尚未成熟。它们[NoSQL]的功能仍很初级。一般来说只在数据量不是非常大或性能压力不大的情况下才部署NoSQL数据库。部署的NoSQL数据库数量比较小。基于NoSQL数据库的应用程序开发模型也面临挑战,因为它增加了实现的复杂性。而系统的高可用性和SLAs仍有待评估。
\我们应使用经验证可靠的方法。而不要冒险将数据存储于NoSQL数据库。
\
有趣的是,这份文档已经从Oracle的网站上撤下,但还可以从因特网上找到。撤销这份文档的原因与这次发布的大数据设备有关,根据OpenWorld 2011大会上的一份主题讲演,该设备是“一种为获取、组织和加载非结构化数据而优化的工程系统”,基于新的Oracle NoSQL Databse,可伴随Apache Hadoop、Oracle Data Integrator with Application Adapter for Handoop、Oracle Loader for Hadoop和开源分布式统计语言R一起使用。
\Oracle NoSQL Database是一种键-值数据存储,设计时考虑到了高扩展性和高可用性,并可部署于多个互相复制的节点上,以便进行快速故障切换及负载均衡。我们可以通过Java API提供的Get、Put和Delete操作访问数据,这些API都打包在一个独立的JAR文件中。 其它特性包括:
\- \
由纯Java编写
\ \ - \
容量:十亿条的记录存储能力和TB级B-树存储能力
\ \ - \
自动的、基于hash函数的分区和数据分布
\ \ - \
ACID事务
\ \ - \ \
完整的CRUD操作和可调整的持久性保证
\ \ - \
无单点故障
\ \ - \
支持分片
\ \ - \
单一和多存储节点的故障容错性
\ \ - \
通过数据中心间的复制进行灾难恢复
\ \ - \
支持数千个节点
\ \ - \
节点级的备份/回复
\ \
Oracle NoSQL Database(在一份PDF官方文档中也被称为Oracle NoSQL Database 11g,这有些容易引起误会)基于开源的Oracle Berkeley DB Java Edition存储引擎构建,并通过Data Integrator与Oracle Database 11g集成,通过In-Database Map-Reduce与Hadoop集成,如下图描述:
\\\\
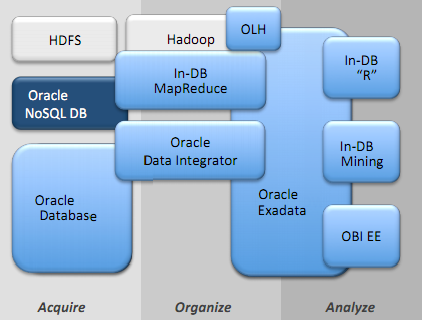
如果过去Oracle认为关系型数据库可以存储任何数据,现如今它已经认识到,处理大容量、实时数据对于关系型数据库来说是“不可能完成的任务”,正如他们在一份关于Oracle NoSQL Database更加详细的技术白皮书(PDF)中承认:
\\\分析像网站点击流之类的大容量、实时数据时,利用非结构化和半结构化的数据源会提供显著的业务优势,创造更多的业务价值。传统的关系型数据库无法完成上述任务,因此企业会基于十年来对分布式哈希表(DHTs)与传统关系型数据库系统或嵌入式键/值存储——比如Oracle的Berkeley DB来构建,以开发出高可用性的分布式键-值存储系统。
\
Oracle将会为NoSQL Database提供完整的商业支持。
\ 查看英文原文: Oracle Joins the NoSQL Club
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









