



 Amazon发布了企业级关系数据库Aurora,它结合了高端商用数据库的高速度和高可用性特性以及开源数据库的简洁和低成本。Aurora性能可达MySQL数据库的五倍,且拥有可扩展性和安全性,成本仅为高端商用数据库的十分之一。
Amazon发布了企业级关系数据库Aurora,它结合了高端商用数据库的高速度和高可用性特性以及开源数据库的简洁和低成本。Aurora性能可达MySQL数据库的五倍,且拥有可扩展性和安全性,成本仅为高端商用数据库的十分之一。
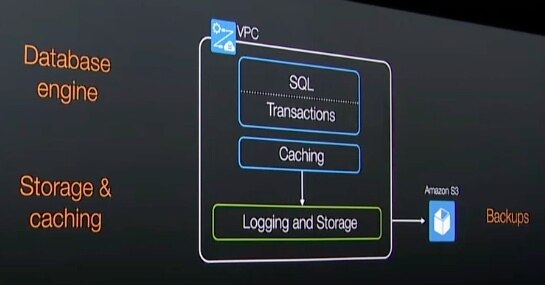
近日,在美国召开的AWS re:Invent云计算大会上,Amazon高级副总裁安迪·杰西发布了企业级关系数据库Aurora。Aurora是一个面向Amazon RDS(关系数据库服务)、兼容MySQL的数据库引擎,它结合了高端商用数据库的高速度和高可用性特性以及开源数据库的简洁和低成本。Aurora的性能可达MySQL数据库的五倍,且拥有可扩展性和安全性,但成本只是高端商用数据库的十分之一。Aurora具有自动拓展存储容量、自动复制数据、自动检测故障和恢复正常等功能。Aurora的架构如下图所示:
\\
Aurora主要特性如下:
\\- 兼容MySQL\\\t
Aurora完全兼容使用InnoDB存储引擎的MySQL 5.6,使得使用MySQL编写的大部分代码、应用、驱动等无需改变或者很少改变即可实现迁移到Aurora,反之依然。
\\t\\t - 快速\\t
Amazon通过紧密集成数据库引擎和基于SSD的虚拟化存储层(专为数据库工作负载而开发),其性能和可用性相较于MySQL有大幅提升,从而降低了存储系统的写入次数、尽量避免了锁定并消除了数据库处理线程带来的延迟。在相同硬件条件下,Aurora提供了相对于标准MySQL高达五倍的吞吐量,每分钟能完成600万的插入操作和3000万的查询操作。
\\t\\t - 高可用性和高耐久性\\t
Aurora能够在多个可用区上自动复制数据,并持续地把数据备份Amazon S3上,在不影响性能的情况下实现99.999999999%的耐久性。 Aurora提供了高于99.99%的可用性,可在60秒内自动检测大多数数据库故障并恢复正常,而不会出现崩溃恢复或需要重建数据库缓存的情况。Aurora还能够持续监测实例健康状况,如果出现故障,它会自动切换至只读副本而不会丢失数据。
\\t\\t - 高扩展性\\t
使用Amazon RDS服务扩展了Aurora的容量,还能够增加15个Aurora 副本,以及自动扩展存储容量而无需任何中断,从而避免停机或性能降低的情况。
\\t\\t - 高安全性\\t
Aurora运行在Amazon VPC里,它能够将Aurora限制在自己的虚拟网络里;在数据传输过程中自动加密数据。Amazon RDS为Aurora集成了AWS身份识别和访问管理(IAM)服务,该服务能够非常安全地控制用户对Amazon AWS服务和资源的访问权限。
\\t\\t - 非常廉价\\t
Aurora提供了同高端商用数据库同样的功能,但只有高端商用数据库产品成本的十分之一。用户无需前期投入,只需为自己所使用的每个Aurora数据库实例支付每小时的使用费,也没有最低承诺费用或预付费用。
\\t\
财务软件公司Intuit公有云部门总监Troy Otillio表示:“Intuit在建立和运营高端商用数据库中,进行了大量的投资来为我们的业务提供支持。实际上,为了获得足够的可靠性和性能来满足客户需求,一直以来我们别无选择。Aurora将会改变这个局面,它提供的性能和可用性能够与昂贵的自有数据库和SAN相媲美,并且价格要实惠得多。Aurora的RDS管理功能将让我们可以集中资源和精力处理最重要的事——提供更好的应用,让客户满意。”
\\在Reddit上关于Aurora的讨论中,用户 Kayjaywt 评论道:
\\\\\Aurora给人以非常深刻的印象,它在磁盘上的处理hotspots的方式、自动拓展存储容量、自动复制数据、服务宕掉或者重启时对缓存持久化的处理方式是极好的。
\
AWS推出8年以来,一直保持了非常快的增长速度。高速增长的背后,还有价格的持续下调和功能的完善,客户一直希望更轻松地以开源引擎的价格获得商用数据库的性能,于是就促使Amazon开发了Aurora。另外,在本次的云计算大会上,Amazon还发布了面向开发者的代码服务(CodeDeploy、CodePipeline和CodeCommit)以及新企业安全和管理服务(AWS Key Management Service、AWS Config、AWS Service Catalog)。更多Aurora的相关信息,请查看Aurora的官方详细介绍 以及有关Aurora的FAQ。
\\感谢崔康对本文的审校。
\\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ)或者腾讯微博(@InfoQ)关注我们,并与我们的编辑和其他读者朋友交流。

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









