




文章目录
标准库
string
getlines(cin,s); //标准输入中读取一行读取的时候读取换行符,但是不会把换行符写入string对象
string::size_type; //该类型是size()的返回值类型,同时也是string对象下表索引中所需的类型(int会转换为该类型),该类型是unsigned
string s="vec";//s是字符串字面值的副本,不包括字符串最后的空字符
//cctype头文件中的一些函数
isalnum(c);//当c是字母或数字时为真没
isalpha(c);//c是字母为真
isdigit(c);//c是数字为真
ispunct(c);//c是标点为真
isspace(c);//c是空格为真
isupper(c);//
tolower(c);//
toupper(c);//
- 使用=初始化一个变量实际上执行的是拷贝初始化,不使用等号执行的是直接初始化
- 如果一条表达式中有size()应该避免使用int,混用int和unsigned可能会发生问题。
Vector
- vector表示对象的集合,所有对象的类型都要相同
- vector为显示初始化的对象会被默认初始化(包括内置对象,比如int,无论vector定义在函数体外还是函数体内,都会被默认初始化为0)。
- 注意vectro(“asdf”)是错误的初始化方法,不能用字符串字面值构建vector对象,可以用花括号,此时采用列表初始化的形式。可以使用字符串字面值初始化string
- push_back向vector中高效的添加元素,一般而言只有当所有的元素值都一样的时候,可以在初始化容器的时候给出值,否则定义一个空的vector对象,再添加值更高效。
- 注意:如果循环体内部包含向vector对象添加元素的语句,不能用范围for循环。范围for循环内不能随便更改比所遍历序列的大小。
- vector.size()返回的是vector::size_type类型。
- 不可以用下标向vector中添加元素。
迭代器

- string也支持迭代器,迭代器提供了对对象的间接访问。
- 获取迭代器需要通过有迭代器的类型的返回迭代器的成员函数。vec.begin(),vec.end(),指向的是最后一个元素的下一个位置,begin和end返回同一个值可以判断vec为空(string同理)。如果不需要通过迭代器修改对象的值,可以用vec.cbegin(),无论vector对象本身是否是常量返回的都是const_iterator类型(vector::const_iterator)
- 获取迭代器所指元素的值需要用到解引用符号,item->mem等价于(*item).mem
- 只有一些标准库类型有下标运算符,因此尽量避免,采用迭代器的方式。所有的标准容器的迭代器都提供了==和!=,但他们中的大多数都没定义<运算符。
- 因此在string和vector中,我们可以使用下标运算符,同时他们的迭代器也可以使用iter+n之类的操作,但是其他标准容器并不一定支持这种操作。但是所有的容器都支持迭代器的递增。
- string和vector迭代器支持迭代器-迭代器,返回的是一个有符号的类型(difference_type)
插入迭代器
back_inserterfront_inserterinserter插入后会自动移动迭代器的位置,向前插入
iostream迭代器
//从标准输入中读取数据,存放在vector中
istream_iterator<int> i_iter(cin);
istream_iterator<int> eof;
while(in_iter!=eof)
vec.push_back(*i_iter++)
//从文件中读取字符串
ifstream_iterator in("file");
istream_iterator<string> str_it(in);//从文件file中读取字符串
//从迭代器范围构造vec
istream_iterator<int> in_iter(cin),eof;
vector<int> vec(in_iter,eof);
//使用ostream_iterator来输出值的序列
ostream_iterator<ing> out_iter(cout," ");
for (auto e:vec)
*out_iter++=e;
cout<<endl;
- 输出流迭代器必须绑定一个流,不允许空。输出每个元素后都会打印第二个参数(第二个参数可以为空)
- 任何有输出和输出运算符的对象,我们对可以定义该对象的流迭代器。
反向迭代器
-
使用反向迭代器的base成员,将反向迭代器转换为正向迭代器。
rcomma=vec.crbegin(),rcomma=rcomma.base(),转换后的迭代器会向正方向移动一个位置。
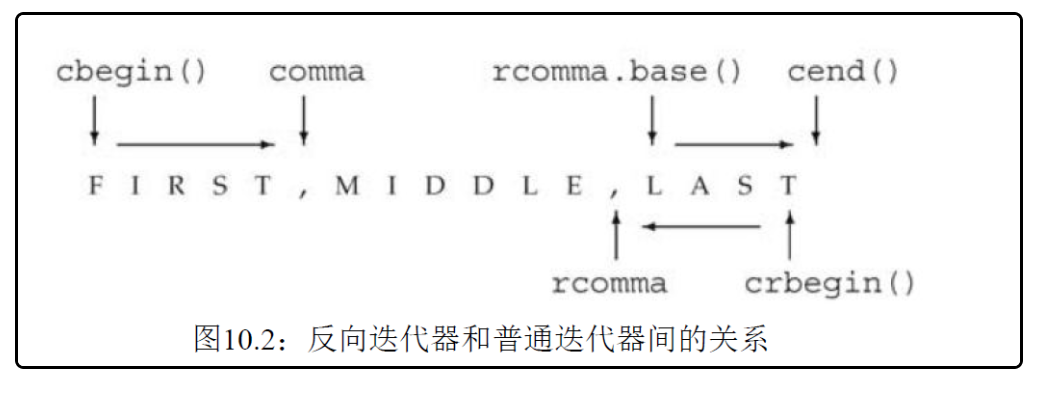
-
从技术上讲,普通迭代器与反向迭代器的关系反映了左闭合区间的特性。关键点在于[line.crbegin(),rcomma)和[rcomma.base(),line.cend())指向line中相同的元素范围。为了实现这一点,rcomma和rcomma.base()必须生成相邻位置而不是相同位置,crbegin()和cend()也是如此。
IO类
标准输入输出流
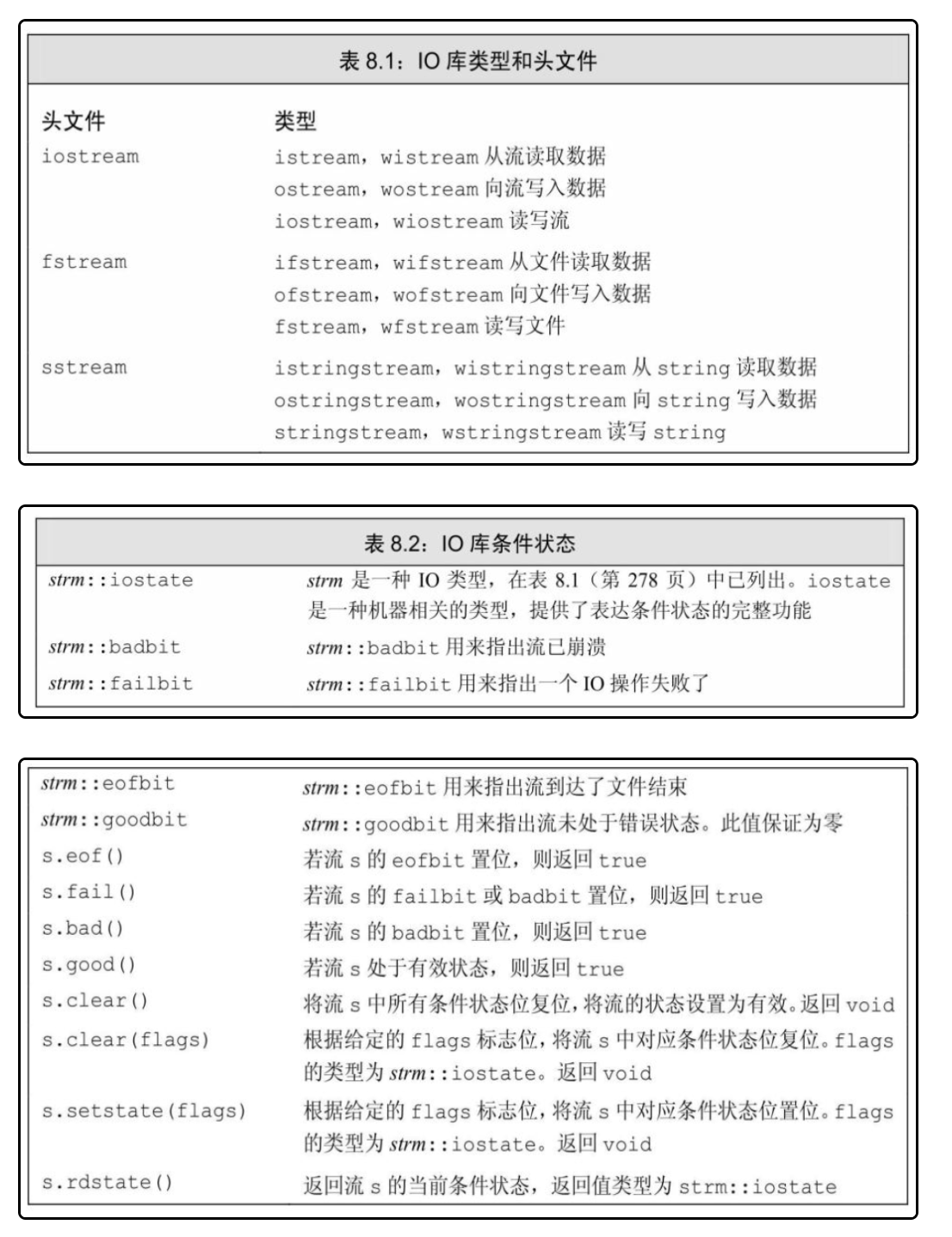
-
badbit被值位,流就无法使用了。badbit被值为,fail也会变为true,因此使用good或者fail确定流的总体状态是正确的方法。
auto old_state=cin.rdstate(); cin.clear(); //使cin有效,清空置位 process_input(cin); cin.setstate(old_state); cin.clear(cin.rdstate()&~cin.failbit&~cin.badbit)//复位failbit和badbit -
每个输出流都管理一个缓冲区,用来保存程序读写的数据。导致缓冲区刷新的原因如下:
- 正常结束,作为main函数return操作的一部分,缓冲区会刷新。
- 缓冲区满,需要刷新
- 使用操作符endl显式刷新缓冲区
- 在每个输出操作后,使用unitbuf设置流的内部状态来清空缓冲区,对cerr是设置unitbuf的,因此写到cerr的内容都是立即刷新的。
cout<<unitbuf;cout<<nounitbuf。设置后所有的输出操作都会被立即刷新 - 一个输出流可能被关联到另一个流。读写被关联时,关联到的流的输出缓冲区会被刷新。默认情况下,cin和cerr都关联到cout,因此读cin或者写cerr都会导致cout的缓冲区被刷新。
x.tie(&o), - flush和ends前者刷新缓冲区,后者添加一个空字符后刷新缓冲区。
- geline方法不会跳过前导空格。
文件输入输出
-
船舰文件流对象时可以提供文件名,open被自动调用
-
对一个已经打开的文件流调用open会失败,并且导致failit置位,必须先关闭关联的文件,在关联到另外的文件。
ifstream in(ifile); ofstream out; out.open(ifile+".copy"); in.close(); in.open(ifile+"2"); ofstream out("file1",ofstream::app) -
当一个函数接收io流时候传递一个文件或者字符串流也可以正常使用。
-
文件模式

-
只要tunc没设定,就可以设定app模式,在app模式下,即使没有显式指定cout模式,文件也总是以输出方式被打开。以为out模式打开文件会丢失数据(out隐士以trunc打开)。
string流
istringstream;
//从字符串中读取数据
while(getline(cin,line)){
PersonInfo info;
istringstream record(line);//接下来我们将一个istringstream与刚刚读取的文本行进行绑定,这样就可以在此istringstream上使用输入运算符来读取当前记录中的每个元素。我们首先读取人名,随后用一个while循环读取此人的电话号码。
record>>info.name;
while(record>>word) //读取字符串的时候以空格隔开
info.phones.push_nback(word);
pepople.push_back(info)
}
ostringstream;//将输入内容写道一个内存ostringstream中
ostringstream formatted,badNums;
//nums是一个字符串
badNums<<" "<<nums;
formatted<<" "<<format(nums);
badNum.str().empty;//判断badNums中的string对象是否为空。
//对于输入流,我们可以使用str重置流,设定新的文本并且清空流的状态
int main() {
using std::string;
string text = "askldf itnai vcasd iasdlfkjt aasdf";
string text2 = "651 891 7895 37 789";
std::istringstream line(text);
string word;
while (line >> word) {
std::cout << word << std::endl;
}
line.str(text2);
line.clear();
while (line >> word) {
std::cout << word << std::endl;
}
}
控制输出格式

- 当操纵符改变流的格式状态时,通常改变后的状态对所有后续IO都生效
//bool操纵夫
cout<<true<<endl;//1
cout<<boolalpha<<true<<endl;//true
//改变整数进制
cout<<oct<<20<<endl;//8
cout<<hex<<20<<endl;//16
cout<<dec<<20<<endl;//10
//打印进制规则
cout<<showbase;
<<20<<endl;//默认20
<<oct<<20<<endl;//8进制 024前导0表示八进制
<<hex<<20<<endl;// 16进制,0x小写前导
<<uppercase<<hex<<20<<endl;//大写16进制输出
<<dec<<20<<endl;
<<setbase(b)<<20<<endl;//以b进制输出
<<noshowbase;//回复流状态
//指定打印精度
cout<<cout.precision()<<endl;//输出当前精度
cout<<cout.precision(12)<<endl;//设置打印精度为12
cout<<setprecision(3)<<endl;//设置打印精度为3.
//浮点数输出
cout<<scientific<<endl;//科学技术法输出
<<fixed<<endl;//定点10进制输出
<<hexfloat<<endl;//16进制浮点数输出
<<defaultfloat<<endl;//默认输出
<<showpoint<<endl;//强制打印小数点,默认情况下浮点值小数部分为0时不显示小数点。
//按列打印数据
cout<<setw(12)<<endl;//输出数字或者字符串的最小空间,默认右对齐
<<left<<endl;//左对齐
<<right<<endl;
<<internal<<endl;//用空格补充间隙,默认负号在最前面
<<setfill("#")<<endl;//用#填充
//控制输入格式 默认情况下,输入运算符会忽略空白符(空格,制表,换行,回车)
cin>>noskipws;//读取空白,如果读char则【a b】会读入三个字符a、空格和b
- 在执行scientific、fixed或hexfloat后,精度值控制的是小数点后面的数字位数,而默认情况下精度值指定的是数字的总位数——既包括小数点之后的数字也包括小数点之前的数字。使用fixed或scientific令我们可以按列打印数值,因为小数点距小数部分的距离是固定的:
未格式化操作–读取单个字节:
这些操作允许我们将一个流当作一个无解释的字节序列来处理。它们会读取而不是忽略空白符。

- 返回int的函数将它们要返回的字符先转换为unsigned char,然后再将结果提升到int。即使字符集中有字符映射到负值,这些操作返回的int也是正值。而标准库使用负值表示文件尾
- 头文件cstdio定义了一个名为EOF的const,我们可以用它来检测从get返回的值是否是文件尾,而不必记忆表示文件尾的实际数值。
int ch;
while((ch=cin.get())!=EOF);//get的返回值是int
cout.put(ch);
未格式化操作–读取多个字节

- 我们可以调用gcount获取最后一个未格式化输入运算符读取了多少个字节。如果在调用gcount之前调用了peek、unget或putback,则gcount的返回值为0。
**流随机访问:**我们可以重定位流,使之跳过一些数据,首先读取最后一行,然后读取第一行,依此类推。标准库提供了一对函数,来定位(seek)到流中给定的位置,以及告诉(tell)我们当前位置。
由于istream和ostream类型通常不支持随机访问,所以下面内容只适用于fstream和sstream类型。
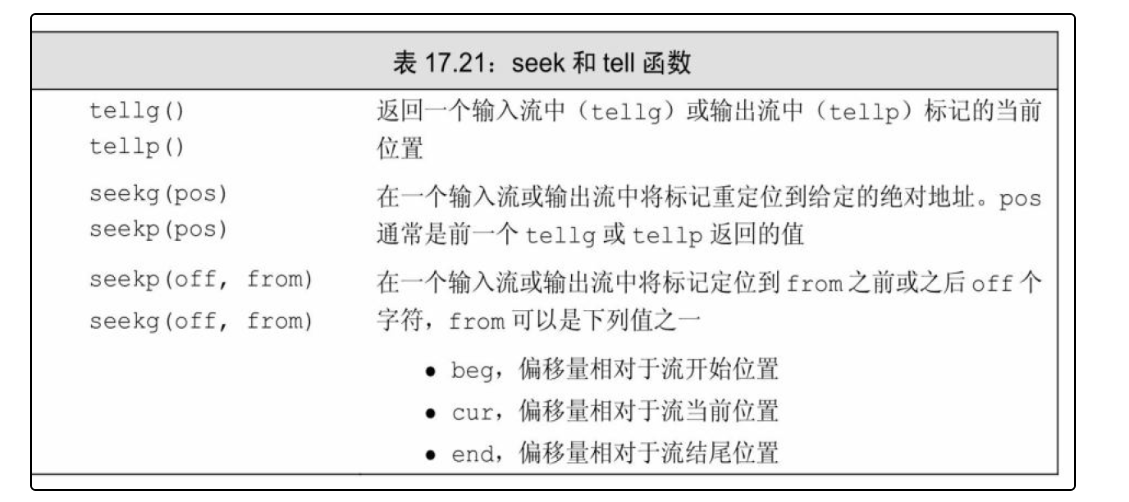
- 由于只有单一的标记,因此只要我们在读写操作间切换,就必须进行seek操作来重定位标记。
- 参数new_position和offset的类型分别是pos_type和off_type,这两个类型都是机器相关的,它们定义在头文件istream和ostream中。
//在文件末尾增加新的一行,保存每一行的起始位置,不保存第一行,最后保存新增的一行的起始位置。
int main()
{
fstream inOut("copyOut",fstream::ate|fstream::in|fstream::out);
if(!inOut){
cerr<<"无法打开文件"<<endl;
return EXIT_FALLURE;
}
auto end_mark=inOut.tellg();//记住文件末尾位置
inOut.seekg(0,fstream::beg);//重新定位到文件开始
size_t cnt=0;//字节数累加器
string line;//保存输入中的每行
while(inOut &&inOut.tellg()!=end_mark &&getline(inOut,line)){//文件成功打开,并且可以获取一行输入
cnt+=line.size()+1;//line.size表示改行的字节数,+1表示换行符
auto mark=inOut.tellg();//记住读取位置
inOut.seekp(0,fstream::end);//将写入光标移动到文件末尾
inOut<<cnt;
if(mark!=end_mark) inOut<<" ";//如果不是最后一行,打印一个分隔符
inOut.seekg(mark);//回复读光标位置
}
inOut.seekp(0,fstream::end);//定位到文件末尾
inOut<<"\n";
//我们读取第一行的时候写入的是第二行的开始位置,我们读取到倒数第二行的时候写入的是最后一行的开始位置,此时inOut.tellg()!=end_mark。当读入最后一行时,inOut.tellg()==end_mark所以会退出循环。因此我们最后一个输出值后面也有一个空格。
return 0;
}
顺序容器
容器库通用操作

-
vector追加数据后用sort排序很高效。
-
如果必须中间插入元素,考虑输入阶段用list,输入完成将list内容拷贝到一个vector中
-
string和vector将元素保存在连续的内存空间中
-
forward_list迭代器不支持递减运算符。string,vector,deque,array的迭代器支持一定的算术运算
-
begin和end有两个重载的版本,根据对象类型确定是否返回const的迭代器。

-
除了array外,其他容器的默认构造函数都会创建一个指定类型的空容器。
-
使用拷贝初始化时必须保证元素类型相同,但使用迭代器拷贝时候,只需保证元素类型可以转换即可。
-
与容器大小相关的构造函数,如果元素类型是内置类型或者具有默认构造函数的类类型,可以只为构造函数提供一个容器大小参数,否则需要显式指定一个元素初始值。
-
array<int,42>,array容器的大小必须定义。
-
array不同于内置数组,他允许拷贝,但必须具有相同的元素类型和大小,大小也是array类型的一部分。

-
赋值运算使得赋值后容器的大小与右边容器的大小相同。array必须保证元素大小相同。
-
array只有在初始化的时候允许{}中的数据可以和容器大小不同(此时只初始化前面的数据)。拷贝赋值的时候不允许使用{}。其他容器则可以使用{}
-
除array外,交换两个容器内容的操作保证会很快——元素本身并未交换,swap只是交换了两个容器的内部数据结构
-
swap会使得string和array的迭代器失效
-
非成员版本的swap在泛型编程中是非常重要的。统一使用非成员版本的swap是一个好习惯。
-
除了无序容器外,所有的容器都支持关系运算。相等运算符实际上通过元素的==来实现的,关系运算符是通过元素的<来实现的。
顺序容器操作
添加元素:

- push_back也可以作用于string类型
- 如果我们传递给insert一对迭代器,它们不能指向需要添加元素的目标容器。
- 在新标准下,接受元素个数或范围的insert版本返回指向第一个新加入元素的迭代器。
- 我们调用一个emplace成员函数时,则是将参数传递给元素类型的构造函数。emplace成员使用这些参数在容器管理的内存空间中直接构造元素。push_back的必须是元素的对象,emplace的可以是构成元素对象的数据,会用这些数据自动调用元素的构造函数,并且是在元素管理的内存中直接创建,而不是创建后在压入容器管理的内存(push_back(Sales_data(,),先创建临时对象,在压入容器)。
访问元素:
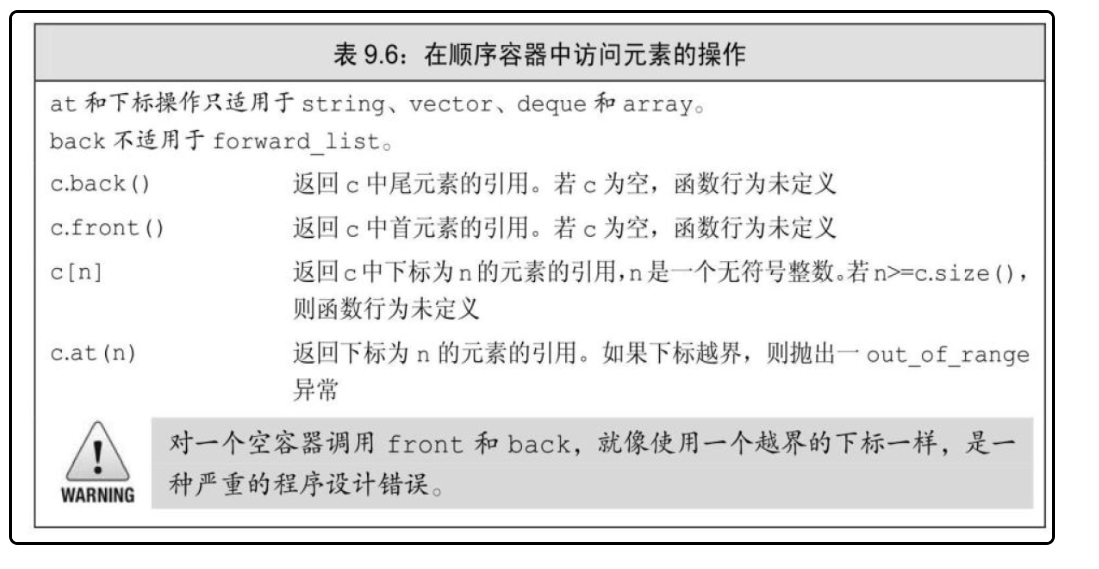
- 如果容器中没有元素,访问的结果是未定义的
- 包括array在内的每个顺序容器都有一个front成员函数,而除forward_list之外的所有顺序容器都有一个back成员函数。
- 容器中访问元素的成员函数返回的都是引用。(back ,front,[],和at)
删除元素:

特殊的forward_list
-
forward_list中添加或删除元素的操作都是通过改变给定元素之后的元素来完成的。
-
forward_list中定义了insert_after,emplace_after,erase_after操作,为了操作element3,我们需要给出element2的迭代器

更改容器的大小:
- resize(n),resize(n,t),调整c的大小为n个元素,任何新添加的元素都被初始为t
- 如果resize缩小容器,指向被删除元素的迭代器,引用和指针都会失效。
容器操作可能使得迭代器失效:
- 容器是string和vector,添加元素后。且存储空间被重新分配,则指向容器的迭代器、指针和引用都会失效。如果存储空间未重新分配,指向插入位置之前的元素的迭代器、指针和引用仍有效,但指向插入位置之后元素的迭代器、指针和引用将会失效。
- 对于deque,插入到除首尾位置之外的任何位置都会导致迭代器、指针和引用失效。如果在首尾位置添加元素,迭代器会失效,但指向存在的元素的引用和指针不会失效。
- 对于list和forward_list,指向容器的迭代器(包括尾后迭代器和首前迭代器)、指针和引用仍有效。
- 对于deque,如果在首尾之外的任何位置删除元素,那么指向被删除元素外其他元素的迭代器、引用或指针也会失效。如果是删除deque的尾元素,则尾后迭代器也会失效,但其他迭代器、引用和指针不受影响;如果是删除首元素,这些也不会受影响。
- 对于vector和string,指向被删元素之前元素的迭代器、引用和指针仍有效。注意:当我们删除元素时,尾后迭代器总是会失效。
- 如果在一个循环中插入/删除deque、string或vector中的元素,不要缓存end返回的迭代器。必须在每次插入操作后重新调用end()
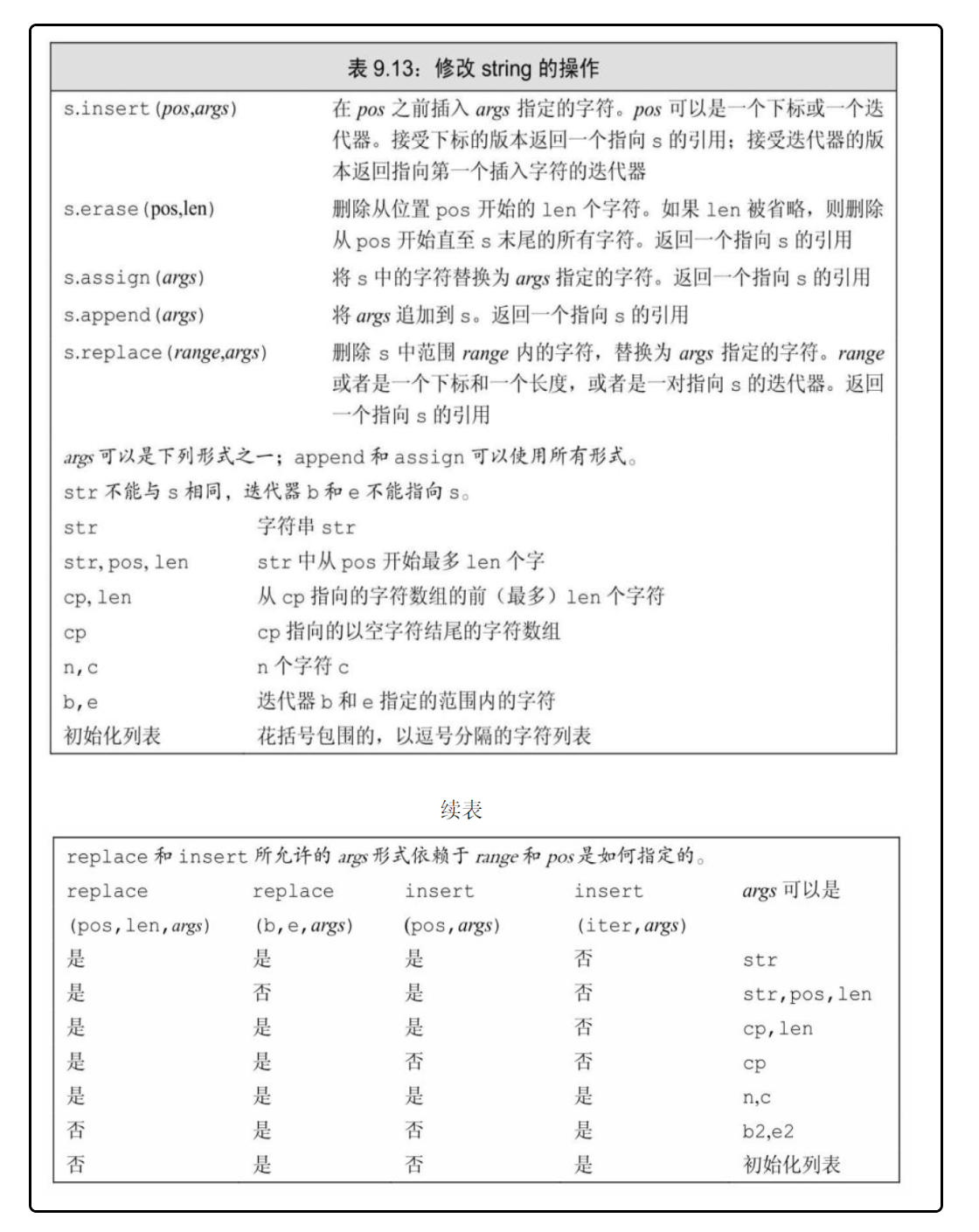
额外的String操作
额外的增删改操作:
-
通常当我们从一个 const char*创建string时,指针指向的数组必须以空字符结尾,拷贝操作遇到空字符时停止。如果传递了一个计数值,则不需要以空字符为结尾。
string s1=s.substr(12); //原始数组的一个字串 s.insert(s.size,5,'!');//支持下标版的insert和erase //insert还支持c风格的字符串, s.insert(s.size,cp+7); s.assign(cp,7); //也可以指定来自其他string或者字符串的字符插入到当前string中。 s.insert(0,s2); s.insert(0,s2,0,s2.size());//在s[0]之前插入s2中从s2[0]开始的s2.size()个字符。 // s2.replace(11,3,"123");//在位置11开始,删除后面3个字符,并且用“123”替代 -
append和replace函数。append在string末尾插入,replace是erase和insert的一种缩写形式。
-
replace函数提供了两种指定删除元素范围的方式。可以通过一个位置和一个长度来指定范围,也可以通过一个迭代器范围来指定。其他顺序容器的erase需要给出一个迭代器指出的范围进行范围删除。
string搜索操作:
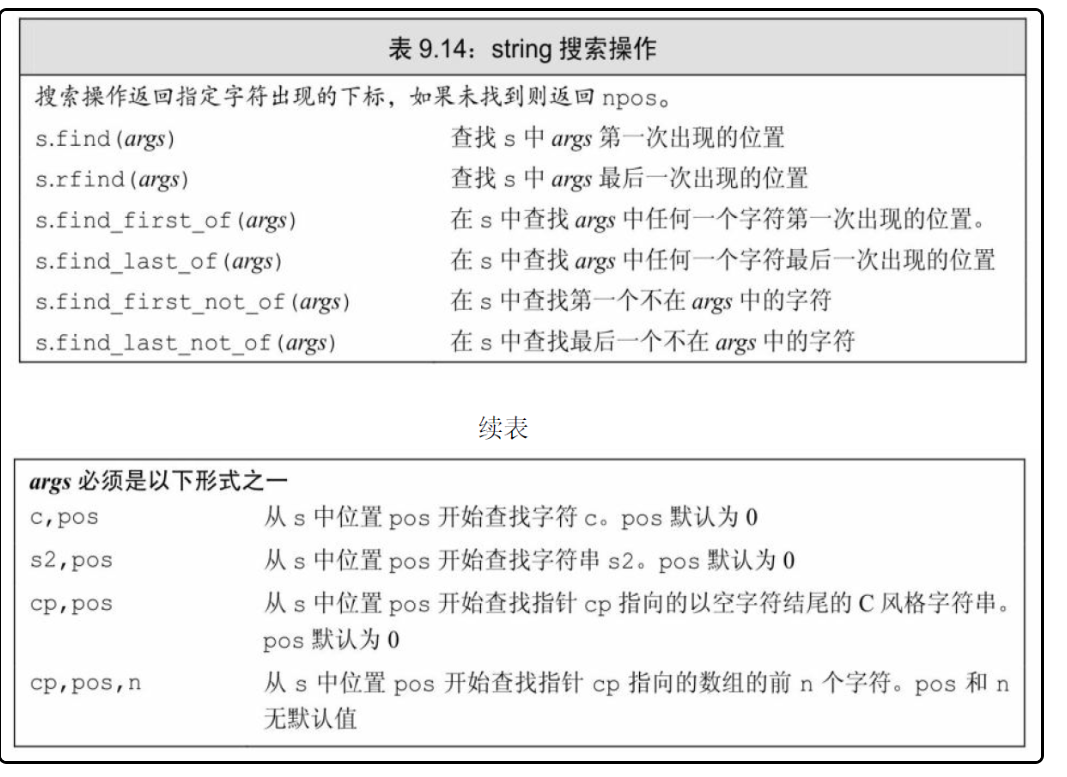
- 如果搜索失败,则返回一个名为string::npos的static成员(参见7.6节,第268页)。标准库将npos定义为一个const string::size_type类型,并初始化为值-1。由于npos是一个unsigned类型,此初始值意味着npos等于任何string最大的可能大小。
//find_first_of的应用
string number("0123456789"), name("e2x2");
auto pos=name.find_first_of(numbers);//查找name中第一次出现的数字
auto pos=name.find_first_not_of(numbers);//查找第一个不是数字的下标
**compare函数:**可以用于string和c风格字符串比较。

数值转换:

int i=43;
string s=to_string(i);
double d =stod(s);//字符串转换为浮点数,
容器适配器
-
stack queue和priority_queue是容器适配器。
-
适配器(adaptor)是标准库中的一个通用概念。容器、迭代器和函数都有适配器。本质上,一个适配器是一种机制,能使某种事物的行为看起来像另外一种事物一样。一个容器适配器接受一种已有的容器类型,使其行为看起来像一种不同的类型。例如,stack适配器接受一个顺序容器(除array或forward_list外),并使其操作起来像一个stack一样
-
所有容器适配器都支持的操作如下:

-
默认情况下,stack和queue是基于deque实现的,priority_queue是在vector之上实现的。
-
stack:可以使用除array和forward_list之外的所有任何容器类型来构造stack。。queue需要访问头元素,可以构造list和deque之上,不能基于vector构造。。priority_queue除了front_push_back和pop_back还要随机访问能力,可以构造vector和deque之上。
-
每个容器适配器都基于底层容器类型的操作定义了自己的特殊操作。我们只可以使用适配器操作,而不能使用底层容器类型的操作。
Stack:

queue

泛型算法
- 迭代器令算法不依赖于容器,比如find,只需要比较迭代器所指的值和目标值即可。
- 泛型算法本身不会执行容器的操作,它们只会运行于迭代器之上,执行迭代器的操作
- 标准库算法大多都一个范围内的元素进行操作
只读容器的算法:
int a=find(v.begin(),v.end(),1)返回指向找到元素的迭代器。
auto a=find_if(v.begin(),v.end(),fun),fun是一个一元谓词,find_if返回第一个使谓词返回非0值的元素,如果不存在,返回尾迭代器。
int sum=accumulate(v.begin(),v.end(),0);求和,要求容器元素要能和第三个参数类型匹配或可以转换。求和要求有定义在第三个参数上的+操作
equal(v.cbegin(),v.cend(),v2.cbegin())v2中元素数目应该和v1一样多。调用==号比较元素类型,类型可以不必相等,只要可以比较即可。比如string和const char*。
和equal类似那些只接受一个单一迭代器来表示第二个序列的算法,都假定第二个序列至少与第一个序列一样长。
写容器的算法
fill(v.begin,v.end(),0)把迭代器给定范围内的值修改为0
fill(v.begin(),vec.size(),0)
fill_n(back_inserter(vec),10,0)使用插入迭代器的一种安全写法。每次都会在vec末尾添加一个0的元素。
auto ret=copy(begin(a1),end(a1),a2)把a2拷贝给a1,尤其注意a1和a2大小相同。ret返回的是拷贝完后的最后一个元素的下一个位置的迭代器。
replace(vec.begin(),vec.end(),0,42)把0都替换为42
replace_copy(vec.begin(),vec.end(),back_inserter(iver),0,42)不改变list的值,把结果拷贝到iver中(用插入迭代器)
重排元素的算法:
sort(v.begin(),v.end())默认升序,可以使用反向迭代器来降序排列
unique(v.begin(),v.end()使得v中不重复的元素出现在vector的开始部分,返回最后一个不重复元素的下一个元素的迭代器。消除重复单词,先排序在调用unique,最后手动调用容器的erase操作删除重复元素
sort(v.begin(),b.end(),isShorter)按照isshorter定义的操作进行排序,如果isShorter参数是两个string,返回值是s1.size()<s2.size(),则sort将按照字符串长度升序排列。
stable_sort(v.begin(),b.end(),isShorter)如果二元谓词isShorter无法区别两个元素,则按照默认的排序规则排序。
定制操作:
for_each(wc,words.end(),[](const string &s){cout<<s<<" ";};对迭代器指向的每个元素都调用lambda表达式进行处理。
transform(v.begin(),v.end(),fun)接受一个函数,从起点开始,对每个元素进行函数操作,并把结果写回该函数。
特定容器算法

- 采用splice移动元素的时候默认移动到p位置前面,splice_after移动到p位置后面(forward_list)
- 链表类型list和forward_list定义了几个成员函数形式的算法,特别是,它们定义了独有的sort、merge、remove、reverse和unique
关联容器

- 范围for循环遍历map,得到的是一个pair类型的对象,用该对象的.first成员获得字典的key,用该对象的second成员获得字典的value
- set的基本用法,
set<string> exclude={};a=exclude.find(word);如果没找到a返回指向set末尾后一个元素的迭代器。 - 有序容器对关键字类型有可比较的限制,如果自定义类型没有实现“<”,我们可以在创建容器的时候显示给出比较方法,该方法被视作是容器类型的一部分。
multiset<Sales_data,decltype(compareIsBn)*> bookstore(compareIsBn)。其中compareIsBn是一个比较函数,该函数的指针作为multiset类型的一部分,multiset的构造函数接受这个比较函数。 - pair对象很简单,
pair<string,size_t> word_count。可以用列表初始化,拷贝初始化,pair中的两个成员都是public的。
关联容器的操作
插入

-
解引用关联容器的迭代器时,得到的是一个类型为容器的value_type类型的值的引用。
-
map中共无法改变key_type的值,value_type是一个pair类型,其中pair的first成员是一个底层const。
-
set的迭代器是const的,无法修改迭代器所指向的元素的值。
-
对关联容器使用算法一般而言,要么作为一个原序列(copy算法将元素从关联容器中拷贝到另一个序列)要么作为一个目的位置(inserter将一个插入器绑定到关联容器)
-
关联容器的insert成员:向容器中插入一个已存在的元素对容器没有任何影响(仅限于非multi关联容器)
-
向map中插入元素时,可以在insert的参数列表中创建一个pair。
m.insert({word,1});m.insert(make_pair(word,1));m.insert(pair<const string,size_t>(word,1));m.insert(map<string,size_t>::value_type(word,1)) -
insert的返回值是一个pair,第一个成员是一个迭代器,指向给定的关键字,second成员是一个bool值。
-
对于multi容器,insert返回的是一个指向新元素的迭代器。
删除元素

访问元素

- 对map迭代器进行解引用得到的是value_type,而对map进行下标操作,得到的是mapped_type
- 下标操作如果不存在key则会创建一个新的key,并初始化value。如果我们给定了值,会把value设置为我们给定的值。下标运算符可能会插入一个新的元素,因此我们只可以对非const的map使用下标操作
- lower_bound和upper_bound这两个操作接受一个关键字,返回一个迭代器,如果关键字再容器中,lower_bound返回迭代器将指向第一个具有给定关键字的元素。upper_bound返回的迭代器指向最后一个匹配给关键字元素之后的位置。如果元素不在容器中,都会返回相等的迭代器–指向一个不影响排序的关键字插入位置。
- equal_range函数:此函数接收一个关键字,返回迭代器pair。关键字存在,第一个迭代器指向第一个关键字元素,第二个迭代器指向最后一个关键字元素的下一个位置。如果关键字不存在,两个迭代器都指向可插入位置。
无序关联容器

-
这些容器不适用比较运算符来组织元素,而是使用一个哈希函数和关键字类型的==运算符。
-
无序容器在存储上组织为一组桶,每个桶保存零个或多个元素。无序容器使用一个哈希函数将元素映射到桶
-
无序容器使用hash<key_type>类型的对象来为每个元素生成哈希值,标准库为内置类型提供了hash模板。
-
类似的,我们需要对自定义类型实现hash函数和==,才可以创建自定义类型的无序容器。此外,我们也可以通过在创建容器中,传入hash函数和判断函数来创建无序字典。
size_t hasher(const Sales_data &sd) { return hash<string>()(sd.ibsn()); } bool eqOp(const Sales_data &lhs,const Sales_data &rhs) { return lhs.isbn()==rsh.isbn(); } using SD_multiset=unordered_multiset<Salse_data,decltype(hasher)*,decltype(eqOp)*>; SD_multiset bookstore(42,hasher,eqOp);
tuple类型
tuple是类似pari的模板。不同tuple类型的成员类型可以不同,但一个tuple可以有任意数量的成员。

-
tuple的这个构造函数是explicit的(参见7.5.4节,第265页),因此我们必须使用直接初始化语法
-
要访问一个tuple的成员,就要使用一个名为get的标准库函数模板。
auto book=get<0>(item)返回item的第一个成员的引用。 -
如果不知道一个tuple准确的类型细节信息,可以用两个辅助类模板来查询tuple成员的数量和类型
typedef decltype(item) trans; size_t sz=tuple_size<trans>::value;//返回item的元素个数 tuple_element<1,trans>::type cnt=get<1>(item);//返回trans第一个元素的类型(元素从0开始) -
tuple可以作为函数的返回值使用,例如函数有三个返回值,第一个返回值是索引,后两个返回值分别是数据起始位置和结束位置。
枚举类型
枚举属于字面值常量类。我们可以定义限定作用域(class)和不限定作用域的枚举类型。默认情况下,枚举从0开始,依次+1,也可自定义。枚举成员是const。只要enum有名字,我们就能定义并初始化该类型的成员。想要初始化enum对象或者为emun对象赋值,必须使用该类型的一个枚举成员或者该类型的一个对象;
一个不限定作用域的枚举类型的对象或枚举成员自动地转换成整型。尽管每个enum都定义了唯一的类型,但实际上enum是由某种整数类型表示的。在C++11新标准中,我们可以在enum的名字后加上冒号以及我们想在该enum中使用的类型
如果我们没有指定enum的潜在类型,则默认情况下限定作用域的enum成员类型是int。对于不限定作用域的枚举类型来说,其枚举成员不存在默认类型,我们只知道成员的潜在类型足够大,肯定能够容纳枚举值。
我们可以提前声明enum,不限定作用域必须声名成员大小,限定作用域可以用默认成员类型(int)
enum color{red,yello,green};//不限定作用域
enum class color{red,yello,green};//限定作用域
enum class intTypes{
charTyp=8,shortTyp=16,intTyp=16
};
open_models om=2;//2不是枚举类型成员
open_model om=open_models::input;//input是枚举成员。

union:一种节省空间的类型
联合(union)是一种特殊的类。一个union可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当我们给union的某个成员赋值之后,该union的其他成员就变成未定义的状态了。
union不能包含引用类型的成员。union可以为成员指定public、protected和private等保护标记。默认情况下为public。可以定义包含构造函数和析构函数在内的成员函数,但是不能继承自其他类,也不能作为基类使用,不能有虚函数。
在匿名union的定义所在的作用域内该union的成员都是可以直接访问的。
union Token{
char cval;
}
//匿名union
union{
char cval;
int ival;
double val;
}
含有类类型成员的union
当union包含的是内置类型的成员时,我们可以使用普通的赋值语句改变union保存的值
于union来说,要想构造或销毁类类型的成员必须执行非常复杂的操作,因此我们通常把含有类类型成员的union内嵌在另一个类当中。这个类可以管理并控制与union的类类型成员有关的状态转换。
为了追踪union中到底存储了什么类型的值,我们通常会定义一个独立的对象,该对象称为union的判别式(discriminant)。我们可以使用判别式辨认union存储的值。为了保持union与其判别式同步,我们将判别式也作为Token的成员。我们的类将定义一个枚举类型的成员来追踪其union成员的状态。

对string对象的复制略微复杂,如果是string对象可以直接赋值,如果不是string对象,sval实际上没有值是未定义的,我们必须用定位new表达式在内存中sval构造一个string,然后用实参初始化新的string。

拷贝构造函数与拷贝复制有些不同,拷贝赋值需要考虑原本是string类型的情景

bitset类型

-
当我们使用一个整型值来初始化bitset时,此值会被转换为unsigned longlong类型并被当作位模式来处理。bitset中的二进制位将是此模式的一个副本。如果bitset大小大于unsigned long long 中的二进制位数,剩余高位被置为0。如果bitset的位数小于unsigned long long 中的二进制数,则只使用给定值中的低位。
-
我们可以使用string或者字符数组来初始化bitset。高位置零或舍弃。注意,string低位在左面,bitset中低位在右面
bitset<32> bitvec4("1100"); string str("0101110010101101010"); bitset<32> bitvec5(str,5,4);//从str[5]开始的4个二进制位0010,bitset中第三位到第0位分别为0010【保持字面顺序不变,但是bitset中的索引顺序从右往左】 bitset<32> bitvec6(str,str.size()-4);//使用最后4个字符
bitset支持的操作:

bitset中的IO运算符:
- 输入运算符作用与bitset时,输入运算符从一个输入流读取字符,保存到一个临时的string对象中。直到读取的字符数达到对应bitset的大小时,或是遇到不是1或0的字符时,或是遇到文件尾或输入错误时,读取过程才停止。随即用临时string对象来初始化bitset。如果读取的符数小于bitset的大小,则与往常一样,高位将被置为0。
正则表达式

-
正则表达式是在运行时,当一个regex对象被初始化或被赋予一个新模式时,才被“编译”的。需要意识到的非常重要的一点是,一个正则表达式的语法是否正确是在运行时解析的。
-
正则表达式的编译很费时,应避免创建不需要的正则表达式。特别是,如果在循环中使用正则表达式,应该在循环外创建而不是每步迭代时都编译它。
-
匹配结果类的声明:==如果我们匹配字符串数组类型,就不能用smatch来保存匹配结果。

Regex迭代器类型: regex迭代器是一种迭代器适配器。

string pattern();
pattern=...;
regex r(pattern,regex::icase);
for (srgex_iterator it(file.begin,file.end(),r),end_it;it!=end_it;++it)
cout<<it->str()<<endl;

打印额外信息:

子表达式:匹配对象除了提供匹配整体的相关信息外,还提供访问模式中每个子表达式的能力。子匹配是按位置来访问的。第一个子匹配位置为0,表示整个模式对应的匹配,随后是每个子表达式对应的匹配。因此,本例模式中第一个子表达式,即表示文件名的子表达式,其位置为1,而文件扩展名对应的子表达式位置为2。
例如,如果文件名为foo.cpp,则results.str(0)将保存foo.cpp;results.str(1)将保存foo;而results.str(2)将保存cpp。在此程中,我们想要点之前的那部分名字,即第一个子表达式,因此我们打印results.str(1)。、
子表达式的一个常见用途是验证必须匹配特定格式的数据。
我们可以采用下标索引的方式获得smatch(cmatch等类型)类型的子匹配结果类型(ssub_match等类型)

匹配并替换
- 我们可以用一个符号$后跟子表达式的索引来表示一个特定的子表达式

匹配标志:
- 标准库还定义了用来在替换过程中控制匹配或格式的标志。

随机数
**引擎:**类型,生成随机unsigned整数序列
**分布:**类型,使用引擎返回服从特定概率分布的随机数。类似引擎类型,分布类型也是函数对象类。分布类型定义了一个调用运算符,它接受一个随机数引擎作为参数。
C++程序不应该使用库函数rand,而应使用default_random_engine类和恰当的分布类对象。
随机数引擎操作:

使用随机数分布类
uniform_int_distribution<unsigned> u(0,9);
default_random_engine e;
for (size_t i=0;i<10;i++)
cout<<u(e)<<" ";
序列不变性:
- 编写序列变化的函数的正确方法是将引擎和关联的分布对象定义为static的,这样函数每次生成的数值序列都是不相同的
- 由于e和u是static的,因此它们在函数调用之间会保持住状态。第一次调用会使用u(e)生成的序列中的前100个随机数,第二次调用会获得接下来100个,依此类推。
vector<unsigned> good_randVec()
{
static default_random_engine e;
static uniform_int_distribution<unsigned> u(0,9);
vector<unsigned> ret;
for (size_t i=0;i<100;++i)
ret.push_back(u(e));
return ret;
}
随机数种子:
随机数发生器会生成相同的随机数序列这一特性在调试中很有用(因为他们都使用了默认的种子)。但是,一旦我们的程序调试完毕,我们通常希望每次运行程序都会生成不同的随机结果,可以通过提供一个种子(seed)来达到这一目的。
default_random_engine e1(time(0))
由于time返回以秒计的时间,因此这种方式只适用于生成种子的间隔为秒级或更长的应用。如果程序作为一个自动过程的一部分反复运行,将time的返回值作为种子的方式就无效了;它可能多次使用的都是相同的种子。

其他随机数分布
uniform_real_distribution<double> u(0,1),生成均匀分布的浮点数- 每个分布模板都有一个默认模板实参,我们可以使用空尖括号来使用默认模板实参。
normal_distribution<> n(4,1.5)生成均值为4,标准差为1.5的浮点数
最后注意:由于引擎返回相同的随机数序列,所以我们必须在循环外声明引擎对象(如果希望每次运行都生成不同的序列,我们还需要把引擎和分布声明为static)。否则,每步循环都会创建一个新引擎,从而每步循环都会生成相同的值。类似的,分布对象也要保持状态,因此也应该在循环外定义。
Functional
- 函数绑定,类似于python中的partial函数,可以固定可调用对象中的某些参数值。二元谓词固定一个参数后,得到的是一元谓词,可以和泛型算法一起使用。
auto check=bind(check_size,_1,6),_1代表的是传递给check的第一个参数,6表示传递给check的第二个参数为固定值6。- 用bind可以从新排列参数顺序,bind中第二个参数后续的所有参数代表这些参数在原函数中的位置。如果参数是_n形式的,则代表该参数是调用new_check函数时传递的参数。
- bind会拷贝参数,我们可以用ref参数让bind引用
bind(pring,ref(os),_1,' ')
根据调用形式组织函数
-
下面三个可调用对象都用共同的调用形式int(int,int),但是他们的类型不一致,如果我们想要用一个map实现一个类似计算器的功能,则我们无法把不同类型的值存储在一起。

-
我们可以用function类型来解决上述问题。function是一个模板,我们需要提供调用形式,可以把拥有不同类型但拥有相同调用形式的可调用对象组合在一起。
-
我们不能(直接)将重载的函数放入function类型的对象中,因为我们无法通过名字区别重载的函数。我们可以用指向重载函数的指针来消除二义性
function<int(int,int)> f1=add;//add是一个普通函数
function<int(int,int)> f2=devide();//devide是一个函数类型
function<int(int,int)> f3=l; //l是一个lambda表达式
cout<<f1(1,2)<<endl;//打印3
//我们可以把f1,f2,f3放在一个map中
map<string,function<int(int,int)>> binops={
{"+",add},//add是一个函数,所以用函数指针
{"-",std::minus<int>()},
{"/",divide()},//divide是一个函数类型,所以要创建类型对象。
{"*",[](int i,int j){return i*j;}},
{"%",mod}//mod是一个lambda对象,编译器隐士创建一个未命名函数类型dui'xiang
};


















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









