




 本文详细介绍了如何在Spark集群环境下,通过改造和自定义UserProvider解决Elasticsearch的Kerberos认证问题,包括暴力登录解决方案和优雅的自定义UserProvider配置。
本文详细介绍了如何在Spark集群环境下,通过改造和自定义UserProvider解决Elasticsearch的Kerberos认证问题,包括暴力登录解决方案和优雅的自定义UserProvider配置。
最近由于公司开启了kde集群下所有组件的kerberos认证。所以需改造原有的spark同步组件,读写数据源的时候需先做kerberos认证。以下是spark写入elasticsearch源的认证过程。
首先上网查下资料,发现没有什么有效信息。于是开始撸elasticsearch-hadoop的源码。发现最新的6.7版本是有支持kerberos认证的,相关实现如下:
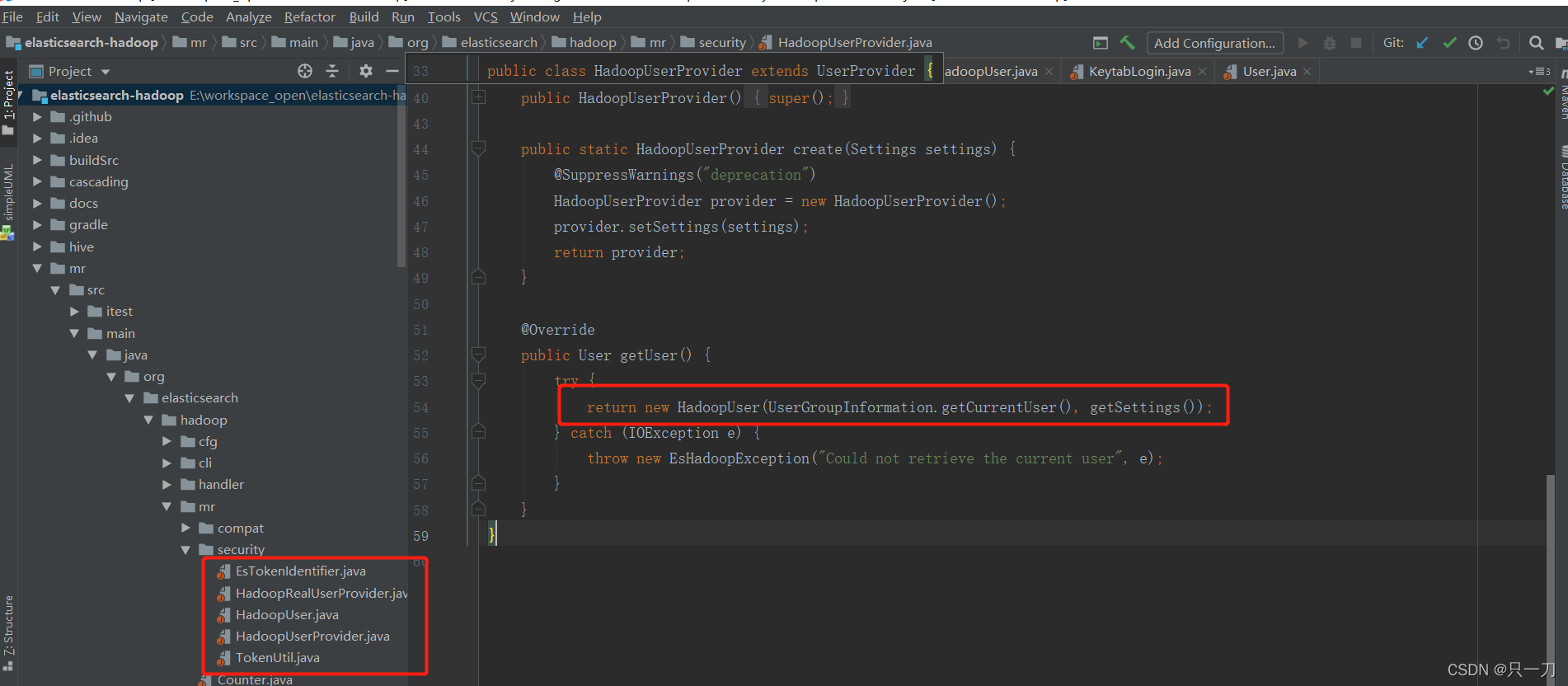
代码中,通过当前已登录的UserGroupInformation 信息去创建一个hadoopUser,提供认证相关信息。但奇怪的是jar包源码中找不到任何地方有做UserGroupInformation.loginUserFromKeytab等相关操作。导致这个方法实际无法获取有效的ugi用户。不知道jar包为什么这么设计,我认为是一个bug。不过由于UserGroupInformation的获取登录用户的方法是单例模式(UserGroupInformation.getCurrentUser()),所以只要找个合适的地方做下登录,就可以让
HadoopUserProvider获取到一个有效登录的用户。于是第一个方案就来了:
//遍历所有执行机,进行ugi登录
dataframe.foreachPartition(item => {
//todo 判断UserGroupInformation是否登录,否则进行登录
if(UserGroupInformation){
//注意此处需通过spark.addFile 将 keytab文件分发到各个执行机上
UserGroupInf 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5136
5136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









