



Large Language Models Are Zero-Shot Time Series Forecasters. NeurIPS 2023.
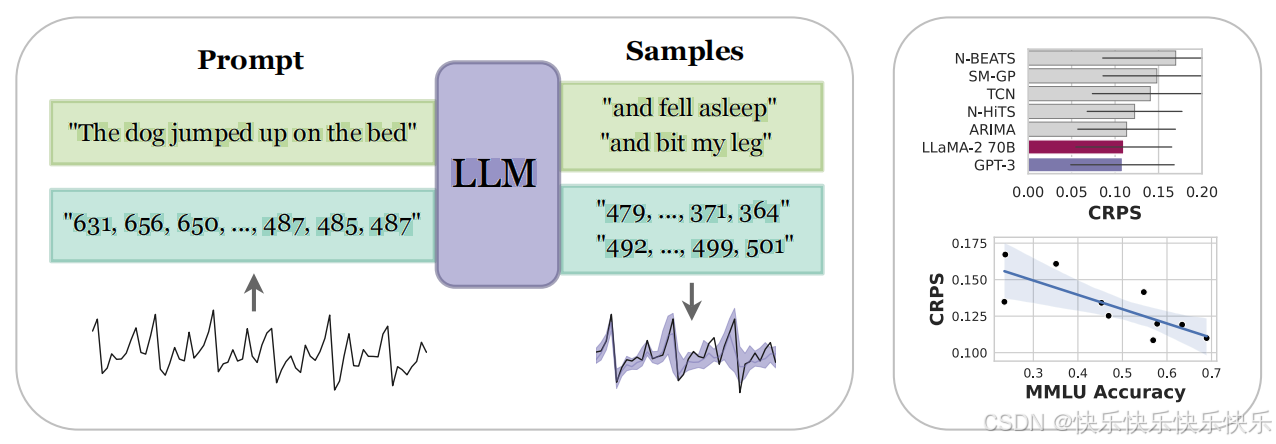
主要工作
本文的工作不同于利用LLM骨干的方法,是完全零样本的,并且不需要微调。
提出了有效的时间序列数据标记化方法,并将离散分布转换为连续值的灵活密度。
- 有效地将时间序列编码为数字字符串
- 适应LLMs的离散分布以连续密度形式进行建模,该连续密度可以表示复杂的多模态分布
方法
- Tokenization:用空格分开每个数字以强制每个数字进行单独标记,并使用逗号分隔时间序列中的每个时间步长。
- Rescaling:为了避免在输入非常大时浪费令牌,将值缩小到百分位数为1的重采样时间序列值。
- Sampling/Forecasting:从LLMs中抽取多个样本,并使用每个时间步的样本统计信息构建点估计或概率预测。
- Continuous likelihoods:通过在每个离散桶内放置均匀分布,将LLMs的离散分布转换为连续密度。
- Language models as flexible distributions:LLMs能够表达灵活的分布,这对于时间序列数据至关重要,因为它们可以捕捉多模态和重尾分布。
What is a Number, That a Large Language Model May Know It? arxiv 2025.2
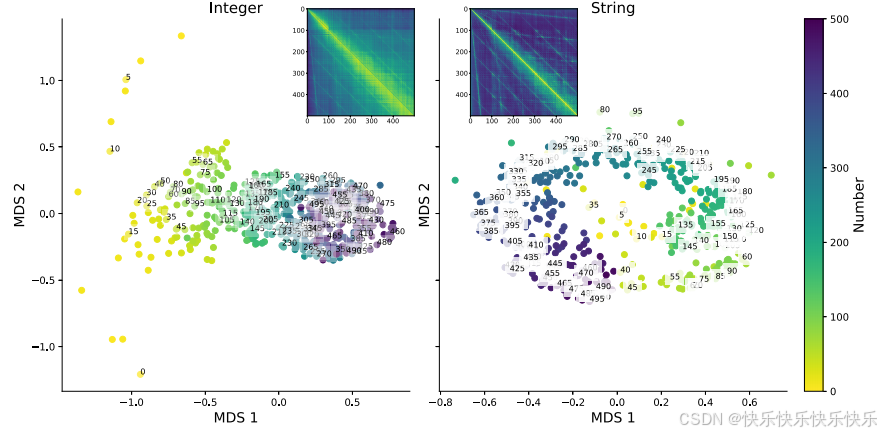
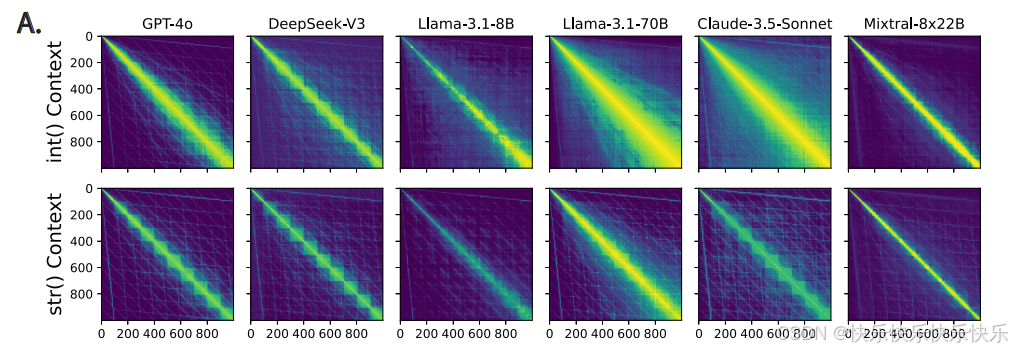
主要工作
相同的数字序列(例如“911”)可能被视为数字或字符串。本文探究了LLM对于数字的二元性的理解能力。
Injecting Numerical Reasoning Skills into Language Models. ACL 2020.
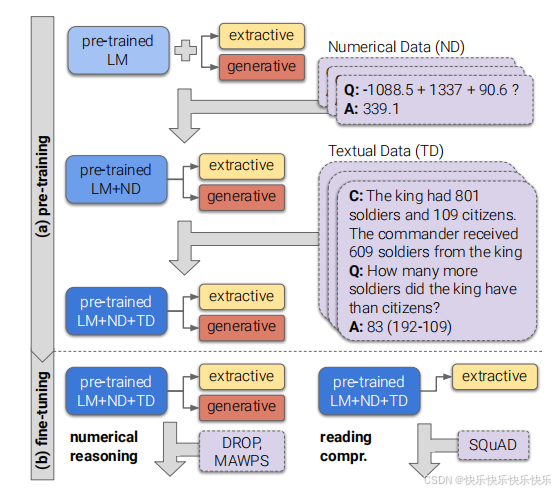
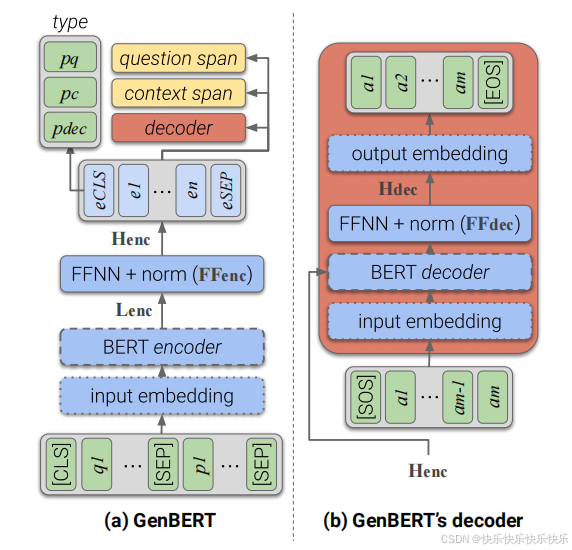
主要工作
(1)本文提出了一种通用方法,假设可以自动生成数据,则可以向LM注入其他技能。
(2)GENBERT和用于生成大量综合示例的简单框架应用于基于文本的数字推理任务, 实验证明了方法的有效性,表明GENBERT成功地学习了数值技能。
Do NLP Models Know Numbers? Probing Numeracy in Embeddings. EMNLP 2019.
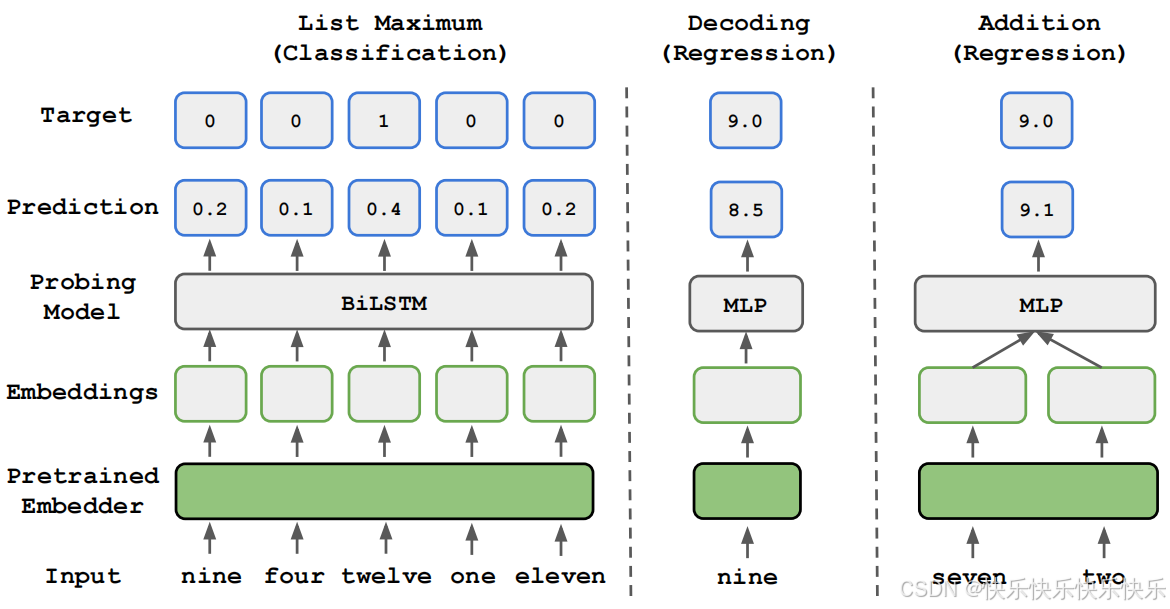
主要工作
为了探究LLMs是如何获得数字推理能力的,本文在最大值辨识(synthetic list maximum)、数字解码和加法任务上对 token 嵌入方法(如 BERT、GloVe 等)进行了分析。
Large language models are zero-shot reasoners. NeurIPS 2022.
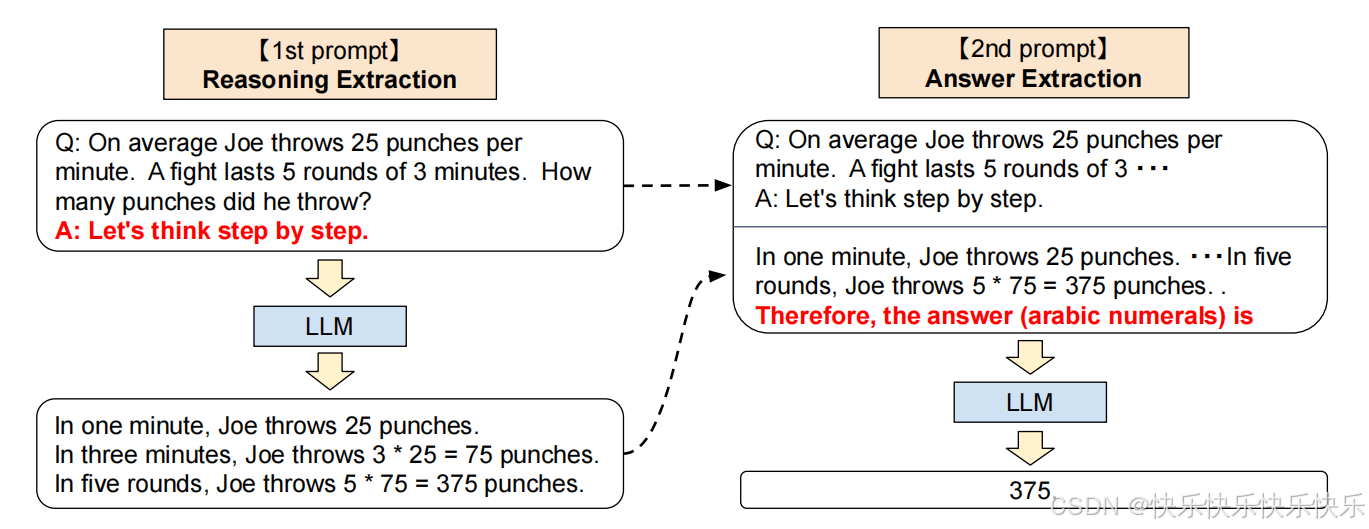

主要工作
本文探究了LLMs在基于chain of thought的零样本/少样本任务上的表现。
Representing Numbers in NLP: a Survey and a Vision. NAACL 2021.
Context information can be more important than reasoning for time series forecasting with a large language model. arXiv:2502
本文通过探索各种现有和提出的提示技术,研究了LLM在时间序列预测中的特性。推测在时间序列预测中,提供适当的上下文信息可能比特定推理提示更为关键。
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022.
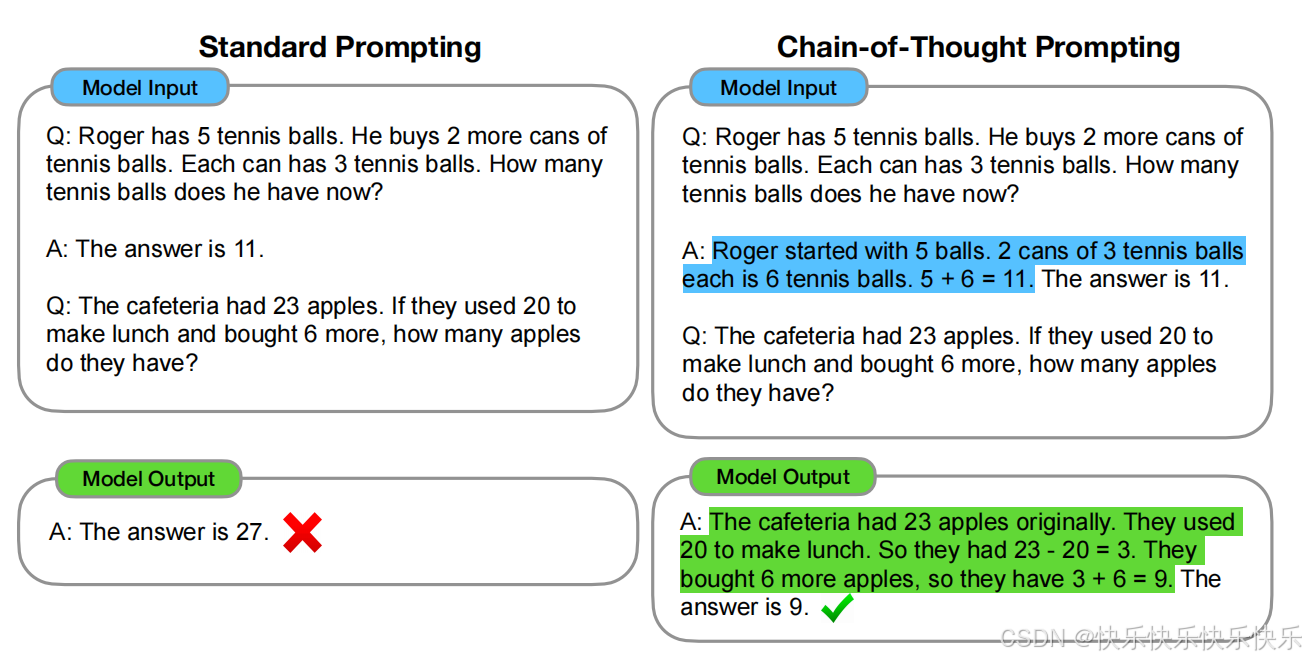
主要工作
研究了生成思维链(即一系列中间推理步骤)是如何显著增强大语言模型(LLM)处理复杂推理任务的能力。这种方法是指在提示词中加入一些作为示例的思维链。
Visual Instruction Tuning. NeurIPS 2023.
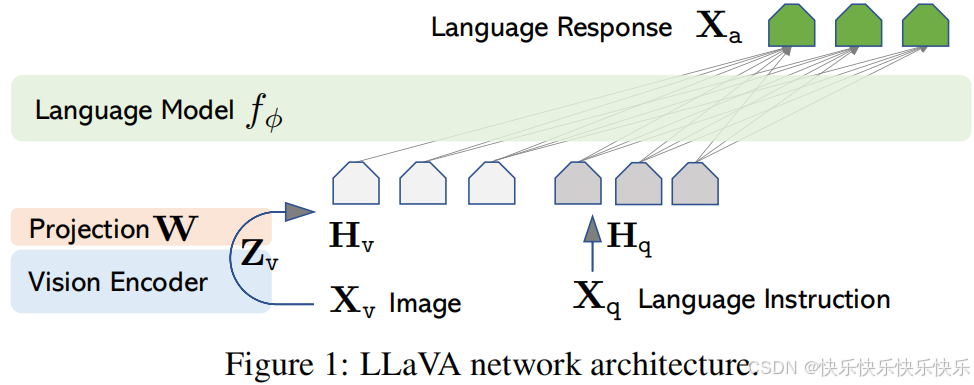
主要工作
- 本文建立了一套处理流程,将 image-text pairs 转换成了 instruction-following 形式,转换使用的是 chatgpt 和 GPT4。
- 构造了一个大的多模态模型 LMM,将 CLIP 作为 visual encoder,将 Vicuna 作为 language encoder,然后在生成的 instructional vision-language 数据上进行端到端的微调。

















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









