




文章目录
1. 消费者和消费者群组
Kafka引入了消费者群组的概念:
一是为了同时实现两种消息引擎模式:点对点的消息队列模式,和发布/订阅模式;
二是为了能够横向伸缩消费者消费能力;
三是为了构建高可用的消费者集群。
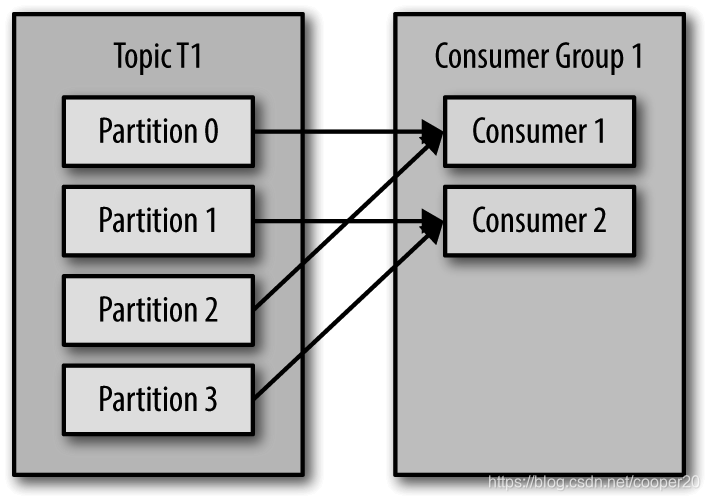
群组内的消费者订阅同一个主题,每个分区的所有权只能被一个消费者持有,多余的消费者会处于idle状态。
新版Kafka Customer采用了双线程设计:用户主线程和心跳线程,以解耦消息的处理逻辑和存活管理逻辑。
消费者的消费请求必须发送给首领副本,否则会收到“非分区首领”的错误,此时消费者需要再次发起Metadata元数据请求,获取集群信息。
2. 消费者核心配置参数
心跳超时时间 session.timeout.ms
如果消费者没有在指定时间内给群组协调器Broker发送心跳,会被群组协调器踢出群组,继而触发再均衡;
心跳发送频率 heartbeat.interval.ms
消费者向群组协调器发送心跳的时间间隔。由于群组协调器需要利用心跳响应来传递再均衡开启信息,较高的心跳发送频率能够使得群组更快地进入再均衡。心跳发送频率一般设置为心跳超时时间的1/3,保证在超时前,生产者可以发送三次心跳。
偏移量重置 auto.offset.reset
指定了消费者在读取一个没有偏移量或者偏移量无效(消费者长时间离线,偏移量对应的消息已经被删除)的情况下,应该如何处理。默认值是latest,表示从最新的消息开始消费。另一个取值是earliest。
最大轮询间隔 max.poll.interval.ms
若消费者消息处理时间过长,没能及时poll下一批消息,消费者会主动发起LeaveGroup请求,退出群组。
3. Reblance再均衡
在群组内重新分配分区所有权的过程称之为再均衡,其为消费者群组提供了高可用性和伸缩性。当群组内的消费者发生故障或者主题分区数量发生改变时,均会触发再均衡。再均衡会导致群组处于短暂的不可用状态(JVM术语:STW),对消费者的TPS影响很大。
再均衡主要涉及三个角色:群组协调器、群主()、普通群组成员。
群组协调器Group Coordinator:
为消费者群组服务的Broker,提供组成员管理及位移管理。群组协调器就是保存该群组位移主题分区的首领副本所在的Broker,由groupID.hashCode % 位移主题分区数 即可确定该群组位移主题分区。
群主:
第一个加入群组的消费者,负责实际的分区分配工作。将分区策略由Broker端转移到消费者端,这是新版消费者的改进之一,降低了分配策略迭代部署的难度。
3.1 触发与通知
触发条件:
- 组成员数量变化
- 分区数量变化
- 订阅的主题数量变化
通知机制:
群组协调器通过与消费者之间的心跳传递再均衡指令,在心跳响应中封装“REBALNCE_IN_PROCESS”来通知消费者加入再均衡。haertbeat.interval.ms的主要作用就是用于控制再均衡通知的频率。
3.2 过程
在接收到再均衡指令之后,群组内的所有消费者需要重新入组,主要涉及到两个请求:JoinGroup和SyncGroup,以及位移提交。
Step1:位移提交
收到再均衡指令后,协调者会给予消费者一个缓冲时间,用以上报位移信息。消费者可在再均衡监听器中完成改逻辑。此时群组处于PreparingRebalance状态。
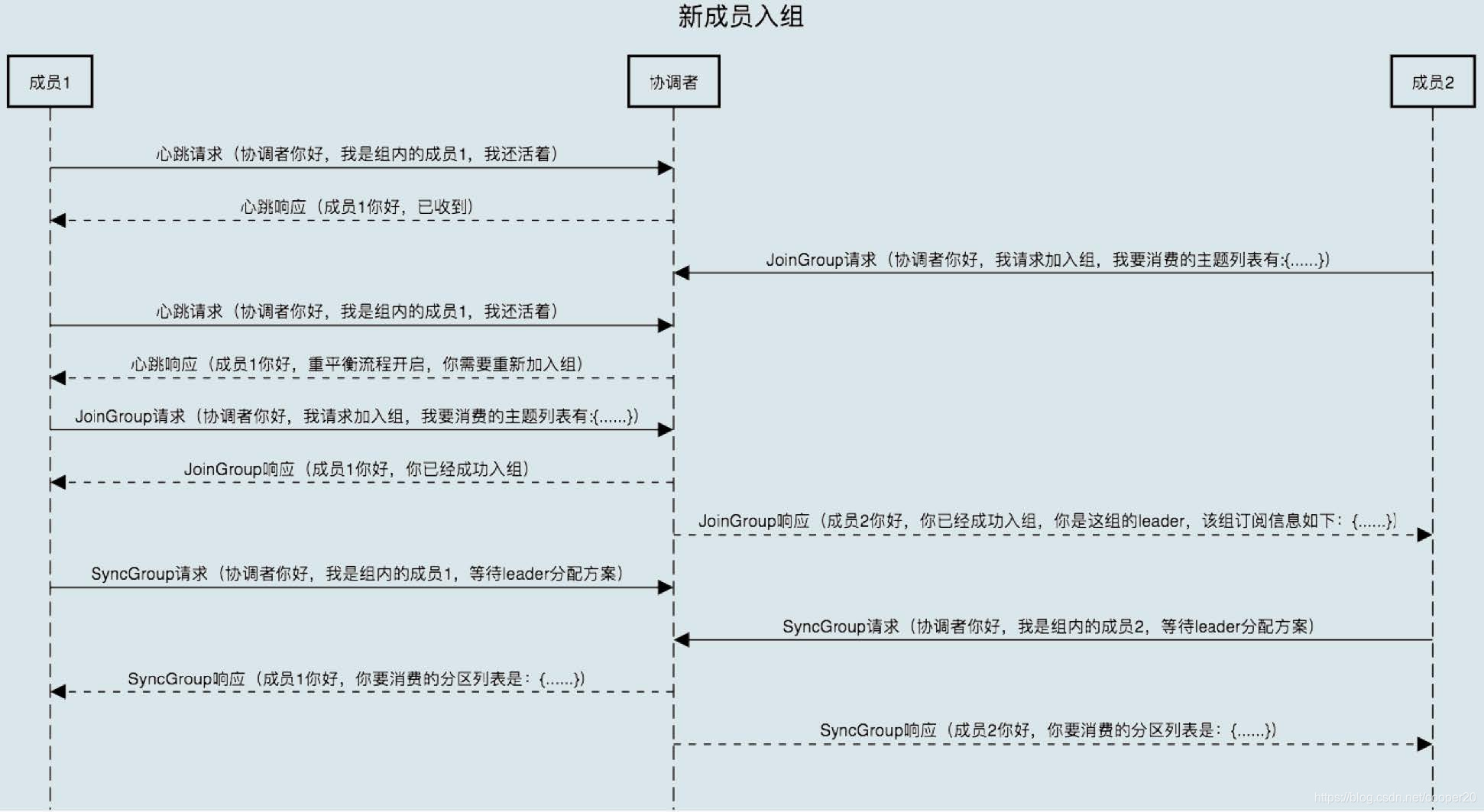
Step2:JoinGroup
消费者通过携带着订阅信息的JoinGroup请求申请加入群组,第一个发送请求的消费者将会称为群主。在所有成员加入后,群组处于CompletingRebalance状态。
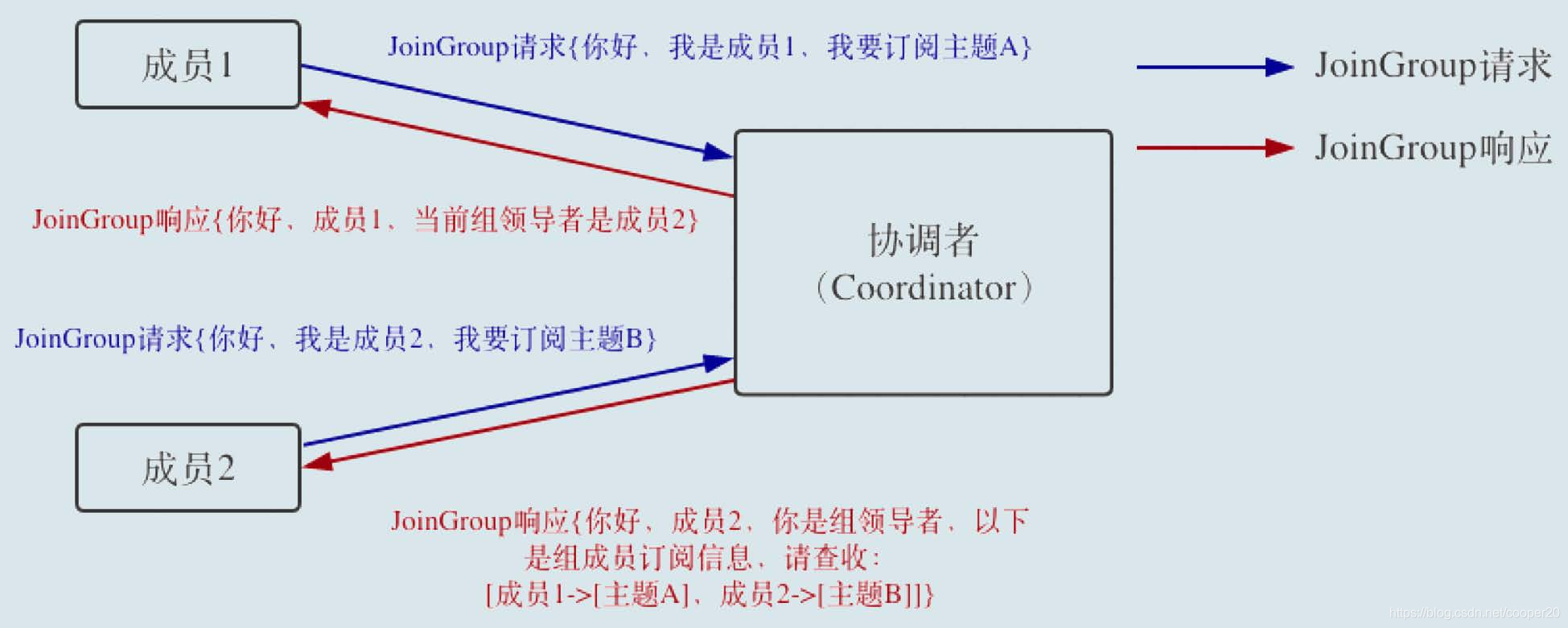
Step3:分区分配
协调者将将收集到的成员信息通过JoinGroup响应发送给群主,群主实现了PartitionAssignor接口,根据所有成员的订阅信息对分区所有权进行分配。
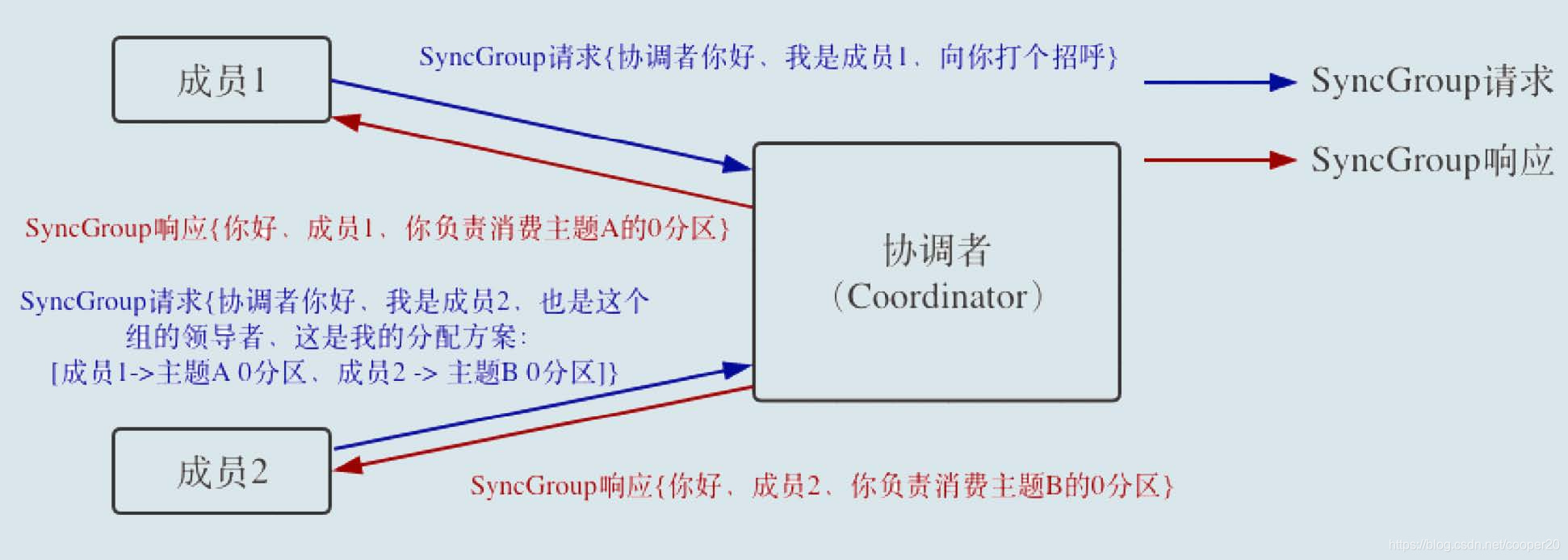
Step4:SyncGroup
群主通过SyncGroup请求将分区分配方案提交给群组协调器,其他成员也需要发起SyncGroup请求,协调器通过响应将分配方案分发给所有消费者。再均衡完成之后,群组处于Stable状态。
3.3 避免再均衡
3.3.1 再均衡的负面影响
再均衡对消费者群组的影响很大,具体体现在:
1. 再均衡期间对消费者的TPS影响很大,群组内的所有消费者均需要停止消费,类似于JVM中的STW;
2. 再均衡很慢,几百个消费者实例再均衡耗时在小时级别。
3. 再均衡效率不高,再均衡需要所有消费者参与进来,之前的分配方案不会被保留。
针对再均衡效率不高的问题,较好的做法是保持原有的分配方案不变,将空闲出的分区分配给存活的消费者。0.11版本推出了StickyAssignor,具有粘性的分区分配方案,该策略会尽可能地保留之前地分配方案。
针对再均衡很慢的问题:
- 适当地提高心跳发送频率,能使群组更快地进入到再均衡进程。
- 多线程处理消息,单线程拉取消息(Kafka消费者线程不安全),在减少群组成员数量的情况下,多线程处理消息,改善伸缩性。不过,这将加大偏移量都的处理难度,容易出现消息丢失、重复消费,也无法保证消费顺序。
3.3.2 如何避免
鉴于再均衡较大的负面影响,应尽量减少计划外的再均衡,这部分情况主要集中于群组成员的意外离线:
1. 未能及时发送心跳而被群组协调器踢出群组
这需要合理的设置心跳超时时间和心跳发送频率,使得在超时之前,消费者至少能够发送三次心跳。
2. 消费时间过长超出最大轮询间隔从而导致的主动退群
适当调高轮询间隔时间,缩短消息消费时间,减小每次获取的消息数量。或者多线程消费消息,此时无法保证消费顺序,且需要小心地处理位移提交。
3. GC
消费者频繁的Full GC导致长时间停顿,在实际场景中也很常见。
4. 位移
Kafka不会想其它消息引擎一样需要得到消费者的确认,而是利用位移主题_consumet_offset来管理消费者的位移数据,位移主题所在分区的首领副本即是当前群组的群组协调器。如果消费者一直正常运行,那么位移就没什么用处,位移提交主要是为了让消费者群组能够在再均衡(消费者发生崩溃或者有新的消费者加入)之后恢复之前的消费状态。
位移提交分为自动提交和手动提交,手动提交又分为同步提交和异步提交。自动提交和手工提交均不能规避重复消费(在不丢消息的情况下,及在处理完消息再提交位移),仅一次消费语义需要借助外部系统。
4.1 自动提交
enable.auto.commit设置为true,消费者每隔一段时间,在poll轮询中自动提交上一次轮询返回的偏移量。自动提交很可能出现重复消费,缩短提交间隔只能缩小重复消费的时间窗口,但不能完全消除它。
4.2 手动提交
同步提交commitSync和异步提交commitAsync会将poll返回的最新位移提交到位移主题,同时也支持提交指定位移数据。
- 同步提交
同步提交的问题在于存在阻塞,从而影响消费者的TPS。 - 异步提交
异步提交的问题在于不能自动重试,重试其实也是没有意义的,因为位移可能已经过期。
**如果需要重试异步提交,可维护一已提交位移变量,在发送前自增,在回调函数里,重试前比较。**PS:单线程时不需要考虑同步;单线程拉取,多线程消费需要同步,且无法使用一个变量表示当前的最新位移,因为消费是乱序的。
4.3 最佳实践
推荐使用手动提交,更加灵活、可控。要确保消息处理完成之后,在提交位移,否则容易出现消息丢失。在不同场景混用同步提交与异步提交:
1. 对于常规性的位移提交使用异步提交来避免程序阻塞,对于瞬时错误不进行重试问题不大;
2. 在关闭消费者前使用同步提交,来规避一些网络抖动、Broker GC等瞬时错误,确保在关闭前将位移正确的提交;
3. 如果单次处理的消息量较大,可在处理途中分批提交。
这样既不影响TPS,也改善了消费者的高可用性。
4.4 从特定位移处处理
Kafka seek()方法支持从特定的偏移量处开始进行消费。在需要保证仅一次消费语义时,可能需要将偏移量保存在外部系统,此时需要借助再均衡监听器,在开始消费前定位位移。另外,在Kafka Broker端会根据索引来快速定位消息位置。
4.5 CommitFailedException
顾名思义就是 Consumer 客户端在提交位移时出现了错误或异常,原因是消费者组已经开启了 Rebalance过程,并且将要提交位移的分区分配给了另一个消费者实例。出现这个情况的原因是,你的消费者实例连续两次调用 poll 方法的时间间隔超过了期望的max.poll.interval.ms 参数。这通常表明,你的消费者实例花费了太长的时间进行消息处理,耽误了调用 poll 方法。
5. 多线程开发消费者
KafakCustomer不是线程安全的,有两种多线程方案:
- 每个线程维护一个KafkaCustomer实例,等同于启动了多个消费者。
- 单线程轮询获取消息,异步多线程处理消息。
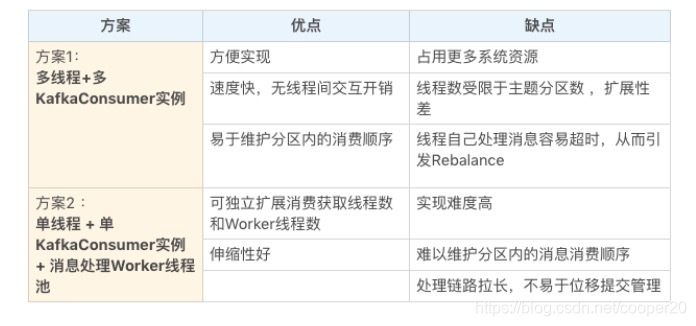
总体而言,方案二解耦了消息获取和消息处理逻辑,具有更好的伸缩性也不易产生再均衡问题。但是其无法保证消费顺序,位移提交也变得异常困难。
5.1 单线程轮询、多线程处理
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
...
private int workerNum = ...;
executors = new ThreadPoolExecutor(
workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
...
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (final ConsumerRecord record : records) {
executors.submit(new Worker(record));
}
}
..
位移提交
要确保消息处理完成之后,再提交位移,否则容易出现消息丢失。
至少一次消费时,维护一组同步变量表示当前已处理完成的位移,无法使用一个变量表示当前的最新位移,因为消费是乱序的,由主线程在poll中处理提交。
仅一次消费时,需要借助外部具有幂等写入的唯一键系统或者事务系统。(详见后续章节)
6. TCP连接 & 消费者启动流程
KafkaCustomer的TCP连接采用懒加载的方式,在调用poll时按需创建。消费者的启动流程如下:
- 发送Metadata元数据请求(任意Broker),获取集群信息(包括主题分区、分区副本、首领副本);
- 发送FindCoordinator请求(任意Broker),获取所在群组的群组协调器;
- 连接协调器,申请加入群组、触发再均衡:JoinGroup请求、SyncGroup请求;
- 连接分配分区的首领副本,开始消费,并与协调器维持心跳、提交位移。
7. 消费进度监控
消费者落后于生产者,可能导致消息已经不再位于页缓存中,引发马太效应,使得滞后程度Customer Lag越来越大。
参考
极客时间《Kafka核心技术与实战》
《Kafka权威指南》
https://blog.youkuaiyun.com/shenshouniu/article/details/84260665

















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









